







车牌识别系统识别部分采用了SVM分类器,训练一定数量的样本,构建了一个SVM分类器,实现车牌汉字和字母,以及数字的识别。
<1> SVM
SVM是支持向量机(Support Vector Machine)的简称,对于解决小样本、非线性、高维的模式识别问题有很多特有的优势。
简单地讲呢,SVM分类算法的实质就是在样本的特征空间中找到一个最优的超平面,使这个超平面离所有的类的样本的距离最小者最大化。
如下图所示,总共有两类,每类的样本数为五,最优超平面即为可以将两类分开,且两类中离分类面最近的样本与分类面的距离最大。
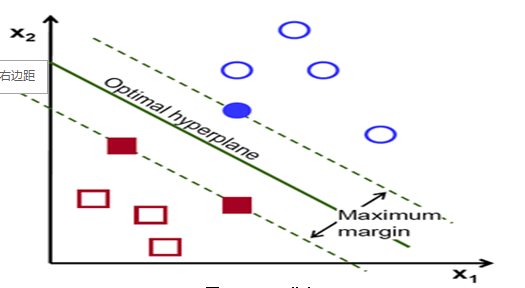
对于只有两类的SVM分类器,SVM分类器就是一个线性分类器。
opencv已经帮我们封装好了SVM算法,我们所要做的就是使用opencv中的SVM类,调用其load载入保存了特征向量的文件,再调用SVM类的识别函数即可。
<2>构建SVM分类器
车牌字符包括汉字和字母和数字,车牌的第一个字符一定为汉字,第二个字符一定为字母,其余五个可能为数字和也有可能是数字和字母的混合。由此实验中训练了三个分类器,分别进行汉字分类、字母分类、数字和字母分类,其中汉字分类器每类的样本只有一个,但在汉字处理较清晰的情况下,可以准确识别。字母分类器和数字与字母混合分类器的每个类的样本有20个。
要训练分类器首先必须提取每个样本的特征,将样本的特征数据保存起来(实验保存特征数据的文件格式为.xml文件)。
对每个样本都得提取特征,所以必须编写特定的样本提取程序来完成这项工作。将每类的样本的储存地址和编号保存到txt 文件中,偶数行保存样本地址,奇数行保存样本的编号,编写程序依次提取样本的特征,并保存到相应的.xml文件中(本实验生成的三个.xml文件:HOG_SVM_DATA、HOG_SVM_DATA_CHAR、HOG_SVM_DATA_CHARACTER)。
其中训练的样本汉字部分是我通过截图,在图像处理获得的,每个汉字只有一份,数字和字母部分是好像是从网上下载下来的,具体哪个链接不记得了,不过还是非常感谢资料的原创提供者!
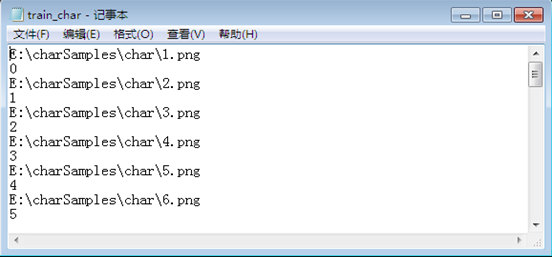
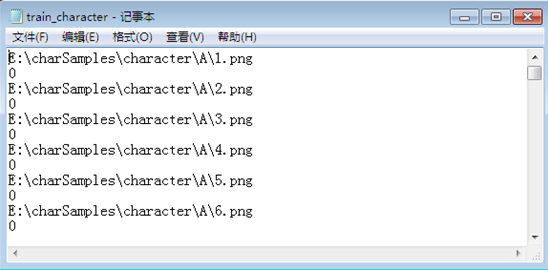
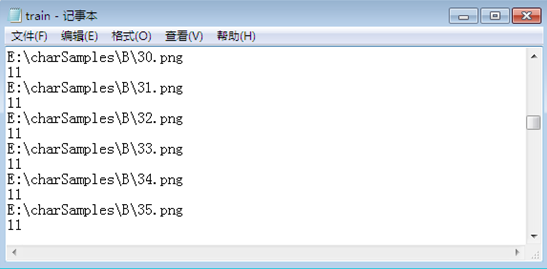
实验中我是分别将汉字、数字、字母的保存路径和编号记录在三个不同的txt文件中,如下图所示:
汉字样本txt文件
字母样本txt文件
数字样本txt文件
在根据上一篇文章中介绍的提取HOG特征,并将其以.xml的文件格式保存。
代码找了半天没找到,只能用我报告上的图片了:

其中参数(28,28)表示移动窗口大小,不过在对图片进行特征提取时已经将图片的尺寸改为(28,28),(14,14)表示块大小,(7,7)表示单步移动尺寸,块每移动一步的大小为7个像素,每个块包括四个小区域(CELL),所以每个小区域的大小亦设置为(7,7),参数9表示每个小区域生产9个方向的梯度直方图,这样每个小区域就有9维特征,共有16个小区域,就可以生成16*9维的特征向量。
识别是只需调用opencv中SVM类中的load函数载入保存特征向量的文件,在调用SVM类中的识别函数即可。
<3>使用已经构建好的SVM实现识别
对已经分割好的字符图片,要进行一定的处理,使其与之前训练的样本图片具有相同性质,继而提取分类器所需要的特征,按一定的顺序逐个识别。调用分类器识别字符时,只需调用SVM类中laod函数加载训练好的数据,再调用SVM分类器的.predict函数进行识别。
识别部分代码如下:
CvSVM svm = CvSVM(); //数字和字母混合识别
svm.load("HOG_SVM_DATA.xml");
CvSVM svm_character = CvSVM(); //单独识别字母
svm_character.load("HOG_SVM_DATA_CHARACTER.xml"); 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8661
8661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









