







hive数据仓库可以存储各种数据,txt,图片,csv等等,下文中若和sql不一样的地方会标注,一样的地方不再标注
增删改查
1.创建数据库
create database hive;2.创建表
创建内部表,这个是http://localhost:50070/explorer.html 页面里的在/user/hive/warehouse/hive.db/下面可以看到刚创建的内部表。
--创建普通表
create table sample_data
> (sid int,
> sname string,
> sex string,
> score_chinese int,
> score_math int,
> score_english int);
--创建指定路径的表:加上location
create table t2(tid int,tname string,age int)
location ‘/mytable/hive/t2’; #创建了一个在/mytable/hive/下名为t2的表
--创建一个分隔符为','即为csv格式的数据,加上row format delimited fields terminated by ‘,’;
create table t3(tid int,tname string,age int)
row format delimited fields terminated by ‘,’;
进入http://localhost:50070/explorer.html#/user/hive/warehouse/hive.db/sample_data页面下载下来的数据是用逗号分开的
类似于:1,tom,F,80,70,60创建外部表(external table):必须指明location
外部表定义
--指向已经在HDFS中存在的数据,可以创建Partition
--它和内部表在元数据的组织上是相同的,而实际数据的存储则有较大的差异
--外部表只有一个过程,加载数据和创建表同时完成,并不会移动到数据仓库目录中,只是与外部数据建立一个链接,故必指明location。而当删除一个外部表时,仅删除该链接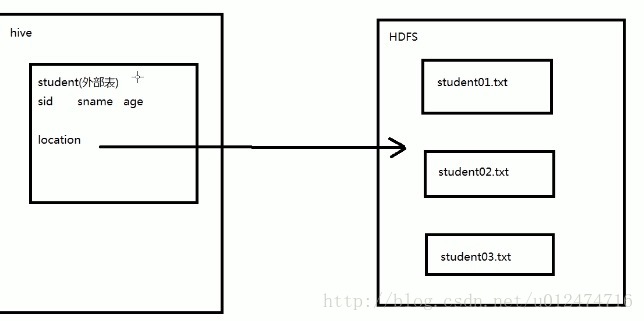
先用hadoop hdfs命令查看文件数据内容
hadoop fs -ls /Users/mac/Desktop/student0*
more /Users/mac/Desktop/student01.txt
#将文件上传到hdfs的/input文件夹下面
hdfs dfs -put /Users/mac/Desktop/student01.txt /input
hdfs dfs -put /Users/mac/Desktop/student02.txt /input
hdfs dfs -put /Users/mac/Desktop/student03.txt /input#创建外部表
create external table external_student
(sid int,sname string,age int)
row format delimited fields terminated by ','
location '/input'; #创建好外部表即与/input目录下的student01.txt student02.txt student03.txt建立了链接
#再像内部表一样查询即可
select * from external_student; #可以查看到input目录下的三个文件的所有数据
#若删除外部表只是删除连接,要删除数据还得在Hadoop中把文件移除
hdfs dfs -rm /input/student03.txt
再次查看外部表的数据,就已经没有student03.txt的数据了3.hive的数据类型有如下,下面3种类型在oracle和mysql等中是没有的。
除了int,float,int,vchar,char,double,boolean等基本类型之外,还有下面的复杂数据类型
--Array:数据类型 ,由一系列相同数据类型的元素组成
create table student(sid int,sname string,grade array<float>);
表中的数据类似于: (1,’Tom’,[80,90,75])--Map:集合类型,包括key-value键值对,可以通过key来访问元素,和python中的字典类似
eg: create table student (sid int,sname string,grade map<string,float>
表中的数据类似于: (1,’Tom’,<‘大学语文’,85>)--Struct:结构类型,可以包含不同数据类型的元素。这些元素可以通过“点语法”的方式来得到所需要的元素。
**struct里面的数据可以不同,但是array里的数据类型必须一致的。即array里的数据如果是数字型的,必须全是数字型的。**
eg: create table student(sid int,sname string,grades array<map<string,float>>)
表中的数据类似于:(1,’Tom’,[<‘大学语文’,85>,<‘高等数学’,80>,<‘英语’,90>])4.时间数据类型
hive的时间数据类型有下面两种:Date,Timestamp
Date:年月日表示具体的时候
Timestamp:时间戳,它是一个偏移量
select unix_timestamp(); #hive中查看当前时间戳进入mysql:mysql -uroot -proot
注:u指用户后面跟用户名,-p是指密码后面跟前面用户的密码
在mysql中输入下面的语句也显示当前系统的时间戳
select unix_timestamp();oracle中的时间to_date,to_timestamp将字符串转换成时间
而mysql是用STR_TO_DATE或者date_format
date_formate—>oracle中的to_char 是以指定格式输出
str_to_date–>oracle中的to_date
create table T
(C1 DATE,C2 TIMESTAMP(9));
#oracle和mysql都要以用下面的date,timestamp插入时间数据
insert into t(c1,c2) values(date'2010-2-12',timestamp'2010-2-12 13:24:52.234123211');mysql与oracle插入数据不同:
--oracle中插入date和timestamp数据
insert into t(c1,c2) values(
to_date('2010-2-12 10:20:30','YYYY-MM-DD HH24:MI:SS'),
to_timestamp('2010-2-12 13:24:52.123456','YYYY-MM-DD HH24:MI:SS.FF6'));--mysql中插入date和timestamp数据
insert into test00(c1,c2) values(
str_to_date('2010-2-12 10:20:30','%Y-%c-%d %H:%i:%S'),
date_format('2010-2-12 13:24:52','%Y-%c-%d %H:%i:%S'));hive中创建时间日期类型
--创建表,hive中的timestamp不能加指小数点后面的数字,例如:前面sql中用的timestamp(5)-->'2012-2-12 13:24:52.11113'.而hive中用c2 timestamp(5)会报错,用下面的才正确。
create table test00
(C1 DATE,C2 TIMESTAMP);
--插入数据,直接插入,若加上date,timestamp会报错
insert into test00(c1,c2) values('2010-02-12','2010-2-12 13:24:52.234123211');5.插入数据
--插入单条数据
insert into sample_data values(10,'James','M',77,80,94);
--将其它表的数据插入到新表中
create table student(sid,sname,sex) as select sid,sname,sex from sample_date;
create table t4 as
select * from sample_data;可以在hadoop下查看表数据t4,000000_0文件名是从Browse Directory网页中查看到的
hdfs dfs -cat /user/hive/warehouse/t4/000000_06.创建分区表
分区表其实也是表,只是把它按分区的条件创建一张表,有利于查询提速等
--按gender分区,且数据之间用,隔开
hive> create table partiton_table
> (sid int,sname string)
> partitioned by (gender string)
> row format delimited fields terminated by ',';
desc partion_table;
--分别插入gender='F'和gender='M'的数据
insert into table partion_table partiton(gender='M')
select sid,sname from sample_data where gender='M';7.桶表
桶表是将hash运算的值一样的放在同一个桶中:clustered by(sname)是以sname为hash运算,into 5 buckets并将运算值放入5个桶中。
create table bucket_table
(sid int,sname string,age int)
clustered by(sname) into 5 buckets;8.视图
视图是虚表,它是一个逻辑概念。数据是存储在物理表中,视图也是表,操作视图和操作表是一样的。
–视图是一个逻辑概念,可以跨越多张表
–视图建立在已有表的基础上,视图赖以建立的这些表称为基表
–视图可以简化复杂的查询
创建一个视图
--查询员工信息:员工号,姓名,月薪,年薪,部门名称
create view empinfo
as
select e.empno,e.name,e.sal,e.sal*12 annlsal,d.dname
from emp e,dept d
where e.deptno=d.deptno;
#查看视图的结构
desc empinfo;
#查看视图的信息
select * from empinfo;9.explain 执行计划
可以查看该语句的性能,查看该语句执行了多少条数据。在sql语句前加上explain即可。
explain select * from empinfo;














 1666
1666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









