






sparkjobserver的设计初衷即"spark as service",将spark作为一个long running服务并且对外提供rest接口,用户在不用关心底层配置细节的情况下提交作业至jobserver上运行。目前,jobserver这块已经承担了公司大数据平台后台的作业运行,进过几次迭代开发,性能与稳定性已经明显提升。
sparkjobserver的特性如下:
1) long running服务,对外提供rest接口;
2) 支持sql、job、python等不同的运行任务;
3) 可以同时提交到不同的yarn集群;
4) 作业日志记录执行进度、完善的任务监控;
5) 支持企业级的Kerberos认证。
jobserver整体的架构如下所示:
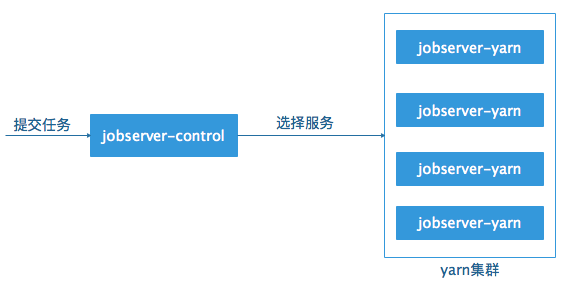
jobserver整体分为两个部分:control端和yarn端,yarn端是真正用于运行服务的地方,spark提交采用cluster模式,yarn端服务随机运行于不同的节点上,提高了服务的容错性以及可扩展性;control端接收用户的任务请求并且选择可用的yarn服务。
jobserver的设计采用了资源池的概念,当一个yarn端服务启动之后,会被自动加入到资源池中以供下一次作业运行选择,这样,一个server在运行完作业可以接着运行下一个作业,具体的提交流程如下:
1) 用户调用rest接口提交作业至control端,提交的参数包括:作业类型、作业id、用户id、集群code、作业内容;
2) control端根据集群code查询当前code对应的server列表中是否有空闲的server,如果有,返回该server对应的地址端口;
3) 如果当前code对应的列表中没有可用的server,则会重新提交一个server至yarn中,并且将该server的信息记录到数据库中;
4) 如果提交过程中报错,则返回错误信息给用户。
jobserver-control可以提交yarn程序至不同的yarn集群中,具体的实现方式是,首先需要准备待提交yarn集群的配置文件,包括hdfs-site.xml、yarn-site.xml、hive-site.xml等,将这些配置文件存放于某个文件夹下、启动spark-submit之前,指定HADOOP_CONF_DIR和YARN_CONF_DIR为该文件夹对应的路径即可。
yarn端是基于springboot的微服框架,主要接收control发出的请求,在启动时,会初始化好sparkcontext,该context具有全局唯一性,在任何时候,yarn端只能运行一个用户的一个作业,运行完成后,状态变成空闲,可以再次接收作业请求。
下图所示为jobserver yarn端的监控页面:
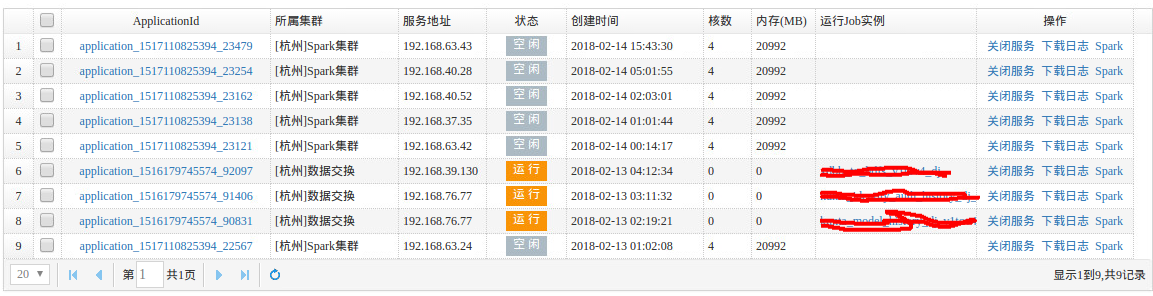
可以看见,每个server在同一时刻只会运行一个作业实例,空闲状态的server可以接收新的任务请求。
默认的server配置为driver端为5g内存,executor为10g内存,采用动态分配机制(spark.dynamicAllocation.enabled设置为true),当server处于空闲状态时,自动移除空闲的executor以减少资源占用。
为了支持企业级的部署需求,jobserver添加了Kerberos认证功能、当集群开启Kerberos时,用户需要提供krb5和keytab配置文件以及登陆用户名完成Kerberos认证,核心代码如下:
String krb5Conf = getKrb5ConfPath(dir);
String keyTab = getKeyTabPath(dir);
if(StringUtils.isEmpty(krb5Conf) || StringUtils.isEmpty(keyTab)){
throw new RuntimeException("can not get krb5conf or keytab file");
}
System.setProperty("java.security.krb5.conf", krb5Conf);
System.setProperty("zookeeper.server.principal", "zookeeper/hadoop.hadoop.com");
Configuration conf = getConfByCode(code);
if(conf!=null){
UserGroupInformation.setConfiguration(conf);
}
UserGroupInformation.loginUserFromKeytab(kerberosUser+"@HADOOP.COM", keyTab);

















 993
993

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









