






jobserver主要运行3种类型的作业:sql、jar、python,下面分别概述这3种作业的运行原理。
yarn端接收任务的rest接口为/sparkDriver/runSparkJob,传入的参数为:
jobType:作业类型(sql/jar/python)
jobCode: 作业实例code
userId: 用户id
command: 作业命令
一 sql类型作业
sql分析是大数据平台上主要的数据分析方式,这里基于spark-sql完成对用户sql的执行。当用户执行查询sql操作时,由于select语句不会触发action,需要调用dataFrame的collect方法,将查询的结果拉取到本地dirver端,再在前端页面上展示结果。
对sql进行权限校验是server的一个重要功能,平台对用户的操作媒介主要是hive表,因此当用户尝试取读写某一张hive表,需要校验用户是否具有操作该表的权限,spark执行sql的入口是SparkSession.sql(String sql),这里首先基于aspect拦截该方法,获取传入的sql:
public pointcut sparkSqlMethod(String sql): execution(public org.apache.spark.sql.Dataset sql(java.lang.String)) && args(sql) ;
DataSet around(String sql): sparkSqlMethod(sql){
//校验sql权限
checkAuthority(sql);
return proceed(sql);
}
二 jar类型作业
jar类型的作业可以使用户编写基于spark的数据分析程序,相对于sql作业而言提供了更大的灵活性。用户编写的程序需要遵循平台的规范,具体来说我们定义了一个接口:
public interface SparkJob {
public void runJob(SparkSession sparkSession, SparkJobLogger logger, String[] args) throws Exception;
}用户的作业需要继承该接口,并且在runJob方法中实现相应的逻辑,其中sparkSession参数为server中已经初始化好的spark入口,logger为日志记录接口,args为用户自定义的参数。编写好程序后,打成jar包并上传至HDFS上,此时约定command的格式如下:
jar包路径 类名 [传入参数] 例如: /user/test/tmp/testJob.jar cn.fraudmetrix.spark.TestJob arg1 arg2
server首先基于URLClassLoader加载HDFS上的jar包,在此我们封装了类加载器:
public class SparkClassLoader extends URLClassLoader{
static {
try {
Installer.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
}catch (Exception e){
e.printStackTrace();
}
}
private SparkClassLoader(URL[] urls, ClassLoader parent){
super(urls, parent);
}
public static SparkClassLoader getSparkClassLoader() {
ClassLoader classLoader = Thread.currentThread().getContextClassLoader();
SparkClassLoader loader = new SparkClassLoader(new URL[]{}, classLoader);
return loader;
}
public void addJar(String jar) throws Exception{
this.addURL(new URL(jar));
}
}由于默认的URLClassLoader不能识别以hdfs://开头的路径,在初始化类加载器时加上Installer.setURLStreamHandlerFactor
-y(new FsUrlStreamHandlerFactory())。这里存在一个问题,jobserver是基于springboot的,其中已经设置了TomcatURLStrea-
mHandlerFactory,一个JVM只能调用一次setURLStreamHandlerFactory方法,再次调用会抛出异常,采用apache commons
jnet解决这个问题,具体代码参看http://svn.apache.org/repos/asf/commons/sandbox/jnet/trunk/
public class Installer {
public static void setURLStreamHandlerFactory(URLStreamHandlerFactory factory) throws Exception{
try {
URL.setURLStreamHandlerFactory(factory);
}catch (Error e){
final Field[] fields = URL.class.getDeclaredFields();
int index = 0;
Field factoryField = null;
while (factoryField == null && index<fields.length){
final Field current = fields[index];
if ( Modifier.isStatic(current.getModifiers()) &&
current.getType().equals( URLStreamHandlerFactory.class)){
factoryField = current;
factoryField.setAccessible(true);
}else{
index++;
}
}
if (factoryField==null){
throw new Exception("Unable to detect static field in the URL class for the URLStreamHandlerFactory");
}
try{
URLStreamHandlerFactory oldFactory = (URLStreamHandlerFactory)factoryField.get(null);
if (factory instanceof ParentAwareURLStreamHandlerFactory){
((ParentAwareURLStreamHandlerFactory)factory).setParentFactory(oldFactory);
}
factoryField.set(null, factory);
}catch (Exception e1){
throw new Exception("Unable to set url stream handler factory " + factory);
}
}
}
}加载完用户的jar包后,通过反射方式获取用户自定义的类,并且执行用户逻辑。
三 python作业
jobserver同样支持python作业的分析方式,当前的python作业是离线作业,类似于jar作业,这里也提供了一个入口:
def main(sparkSession):
用户在main函数中完成自己的业务逻辑,其中sparkSession是已经初始化好的spark入口。
jobserver运行python脚本的原理是首先将用户的python代码段嵌套在模板中,server本身会启动一个gateway端口,在执行main函数之前,首先通过py4j去连接gateway端口并获取sparkSession,再执行main函数,基本架构如下所示:
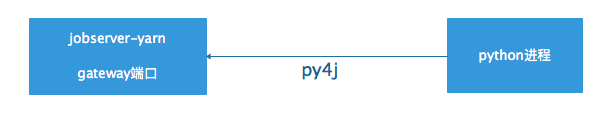
python模板中初始化sparksession的代码如下:
from py4j.java_gateway import JavaGateway, java_import, GatewayClient
from pyspark import *
from pyspark.sql import *
from pyspark.sql.types import *
##PYTHON_TEMPLE##
if __name__ == "__main__":
reload(sys)
port = int(sys.argv[1])
gateway = JavaGateway(GatewayClient(port=port), auto_convert=True)
java_import(gateway.jvm, "org.apache.spark.SparkConf")
java_import(gateway.jvm, "org.apache.spark.api.java.*")
java_import(gateway.jvm, "org.apache.spark.api.python.*")
java_import(gateway.jvm, "scala.Tuple2")
java_import(gateway.jvm, "org.apache.spark.SparkContext")
java_import(gateway.jvm, "org.apache.spark.sql.SQLContext")
java_import(gateway.jvm, "org.apache.spark.sql.UDFRegistration")
java_import(gateway.jvm, "org.apache.spark.sql.hive.HiveContext")
java_import(gateway.jvm, "org.apache.spark.sql.*")
java_import(gateway.jvm, "org.apache.spark.sql.hive.*")
java_import(gateway.jvm, "org.apache.spark.ml.python.*")
java_import(gateway.jvm, "org.apache.spark.mllib.api.python.*")
Config.entry_point = gateway.entry_point
jspark_conf = Config.entry_point.getSparkConf()
spark_conf = SparkConf(_jconf=jspark_conf)
sc = SparkContext(gateway=gateway, jsc=jsparkContext, conf=spark_conf)
sparkSession = SparkSession(sc, jsparkSesssion)
main(sparkSession)pyspark中需要设定python路径,在spark安装目录中的spark-env.sh中添加以下命令:
export PYSPARK_PYTHON=/usr/local/anaconda2/bin/python
同时在spark-submit通过spark.executorEnv.PYTHONPATH设定相关的python路径。















 6951
6951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









