







垃圾收集器需要解决三个问题:
1.回收收集哪里的内存垃圾?
2.怎么判断是否是内存垃圾。
3.怎么回收?
上一篇Java虚拟机面试准备(一)运行时数据区中我们明白运行时数据区有分线程共享和线程隔离。线程隔离的数据区随线程的生命周期创建和回收,所以不过多考虑内存回收。内存的回收主要是再线程共享的区域,即垃圾回收主要考虑Java堆和方法区。
那怎么判断对象是否需要回收呢?
对象存活判断两种方式:
1.引用计数算法:
给对象添加一个计数器,初始值为0,每引用一次+1,引用失效就-1,最终为0就是不被引用了。
缺点:不能解决循环引用问题。早期才用这种算法,线程垃圾收集器基本不用这种算法了。
2.可达性分析
设置一组对象作为“GC Roots”,由GC Roots向下搜索,不能到达的就是非存活对象。
Java语言中,可以作为GC Roots的对象包括四种:
1.虚拟机栈(栈帧中的本地变量表)中引用的对象
2.方法区中类静态属性引用的对象
3.方法区中常量引用的对象
4.本地方法栈中引用的对象
垃圾回收算法:
回收算法有三种:
1.标记-清除算法(mark-and-sweep):最基础的算法,复制算法和标记整理基于此算法。分两步,标记和清除。
缺点:效率不高,产生内存碎片
2.复制算法:将内存分两块,每次只使用其中一块,将存货的对象复制到另一块,并清理原有空间。
优点:效率高,没有碎片。缺点:浪费了一半内存
3.标记整理算法(mark-and-compact):分两步,标记和整理,整理时将存活对象往一端移动,然后清理掉边界外的其余对象
4.分代收集算法:
把Java堆分成新生代和老年代。新生代用复制算法,老年代用标记清除或者标记整理算法。
| 算法/条目 | 算法简介 | 优缺点 | 适合场景 |
| 标记清除算法 | 最基础算法。分为标记和清除两步 | 优点:简单 缺点:效率低,产生碎片 | 老年代 |
| 复制算法 | 划分两块区域,只使用其中一块,将存活的移到另一块中 | 优点:效率高,没有碎片 缺点:浪费一半内存,当存活对象占比高时,效率低 | 新生代 |
| 标记整理算法 | 分标记和整理(包括移动对象和更新指针)两步 | 优点:效率高,没有碎片 缺点:当存活对象占比高时,效率低 | 老年代 |
| 分代收集算法 | 分为新生代和老年代,分别用不同的算法实现。 新生代用复制算法,老年代用标记清除和标记整理。 | 优点:分代收集,效率高 | 当前商业都采用分代收集算法 |
标记清除算法mark-and-sweep,参考自:深入浅出垃圾回收(一)简介篇
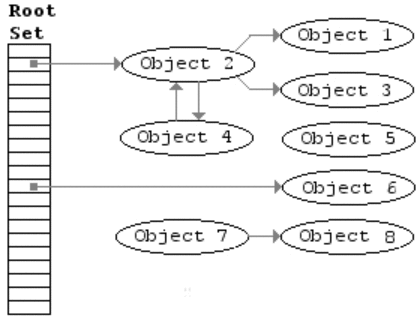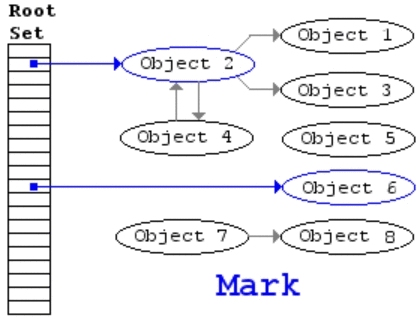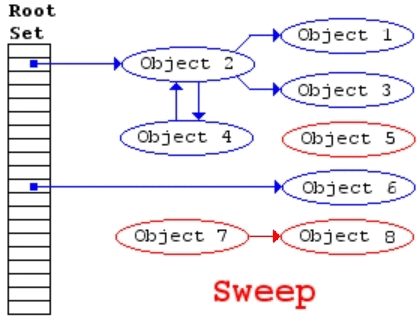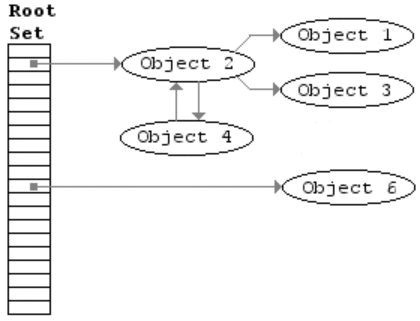
Mark-and-Sweep 过程图示
该算法主要包括两步,
- mark,从 root 开始进行树遍历,每个访问的对象标注为「使用中」
- sweep,扫描整个内存区域,对于标注为「使用中」的对象去掉该标志,对于没有该标注的对象直接回收掉
标记整理算法mark-and-compact,参考自深入浅出垃圾回收(二)Mark-Sweep 详析及其优化
该算法主要包括三步,
- mark,从 root 开始进行树遍历,每个访问的对象标注为「使用中」
- 重新安排(relocate)可到达对象
- 更新指向可到达对象的指针
移动对象,并更新指针,所以MC相对MS要更耗时,这在 heap 较大时更为明显。
这里比较有名的是 Edward 的 Two-pointer 压缩算法。大致过程如下:
- 在 heap 两端各准备一指针,由外向内 scan 寻找可压缩的对象
- 自顶向下的指针寻找可到达对象,自底向上的指针寻找 heap 中的“洞”来存放可到达对象
垃圾收集器:
1)七种垃圾收集器:
- Serial(串行GC)-复制
- ParNew(并行GC)-复制
- Parallel Scavenge(并行回收GC)-复制
- Serial Old(MSC)(串行GC)-标记-整理
- CMS(并发GC,JDK1.5开始,JDK1.9已经废弃)-标记-清除
- Parallel Old(并行GC)--标记-整理
- G1(JDK1.7update14才可以正式商用)
说明:
- 1~3用于年轻代垃圾回收:年轻代的垃圾回收称为minor GC
- 4~6用于老年代垃圾回收(当然也可以用于方法区的回收):老年代的垃圾回收称为full GC
- G1独立完成"分代垃圾回收"
- 除了标记-清除算法不需要copy对象外,复制算法和标记整理算法都需要copy操作.
- 所有的垃圾收集器都会stop the world,其中单线程是全程stop the world,CMS和G1在"标记"和"重新标记"或者"最后标记"阶段也是stop the world的
Java1.7和Java1.8默认垃圾收集器Parallel Scavenge(新生代)+Parallel Old(老年代)
Java1.9和Java10默认采用G1垃圾收集器
按能否并发分:
单线程:Serial收集器,Serial Old收集器
多线程:ParNew收集器(Serial收集器的多线程版本),Parallel Scavenge收集器,Parallel Old收集器(Parallel Scavenge收集器的老年代版本),CMS收集器,G1收集器
按分代分:新生代都是采用了复制算法.老年代除了CMS垃圾收集器,都是采用了标记-整理算法。
新生代:Serial收集器,ParNew收集器(Serial收集器的多线程版本),Parallel Scavenge收集器(多线程,吞吐量优先)
老年代:Serial Old收集器,Parallel Old收集器(Parallel Scavenge收集器的老年代版本),CMS收集器(基于标记-清除算法,多线程)
兼容:G1收集器(采用标记-整理算法,多线程)
这里有一个各个垃圾收集器的搭配使用图:其中G1能用于新生代和老年代

这里有一篇解释串行垃圾收集器的原理文章,简单易懂.【理解HotSpot虚拟机】串行垃圾收集器Serial和Serial Old原理
CMS收集器与G1收集器步骤类似类似.
CMS收集器的4个步骤:1.初始标记2.并发标记3.重新标记4.并发清除
G1收集器的4个步骤:1.初始标记2.并发标记3.最终标记4.筛选回收
CMS和G1各个步骤区别:
第一步:标记GC Roots能直接关联到的对象,都需要STW。G1还要修改TAMS(下一步开始标记)
第二步:可达性分析,可以与用户线程并行。
第三步:修正第二步期间产生的对象变化,都需要STW。G1还会记录到Remembered Set Log中,并且把数据合并到Remembered Set中。
第四步:并发清除。G1会根据需要制定计划清除。
优缺点:
优点是:并发效率高,低停顿。其中G1能建立可预测的停顿时间模型。
缺点是:CMS基于标记-清除算法,产生垃圾碎片,只能等下一次清除。资源敏感,占用CPU资源;G1实现复杂。
资源:
JVM官方文档:https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/
JVM规范:https://docs.oracle.com/javase/specs/index.html
JVM参数设置:https://www.oracle.com/java/technologies/javase/vmoptions-jsp.html
















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











