







当业务繁忙的服务器里,我们常常发现系统在非常大的内存压力情况下,触发了OOM Killer机制,OOM Killer机制是内存管理中在资源极端缺乏情况下一种迫不得已的进程终止机制,OOM Killer机制会根据算法选择并终止占用内存资源较多的进程,以便释放内存资源。本章的主要内容是了解OOM Killer是如何运转的。
1 触发过程
根据内存回收的流程,在慢速路径__alloc_pages_slowpath中,当反复尝试reclaim和compact后仍不成功,就会调用__alloc_pages_may_oom进行内存释放,在该接口中最终会调用到out_of_memory

其整个流程如下:
__alloc_pages //内存分配时调用
|–>__alloc_pages_nodemask __
|–> __alloc_pages_slowpath __
|–> __alloc_pages_may_oom
| --> out_of_memory //触发

- 布尔型变量
oom_killer_disabled定义在文件mm/oom_kill.c中,提供外部接口更改此值,但是在内核中此值默认为0,表示打开OOM-kill。 - blocking_notifier_call_chain通知系统中注册了oom_notify_list的模块释放一些内存,如果从这些模块中释放出了一些内存,那么皆大欢喜,直接结束oom killer流程,回收失败, 那只有进入下一步开始oom_killer了
- 触发OOM killer通常是由当前进程进行内存分配所导致的,而当前进程已经挂起了一个SIG_KILL信号,那么直接选中当前进程,否则进入下一步
- check_panic_on_oom检查系统管理员的态度,看oom时是进行oom killer还是直接panic掉,如果进行oom killer,则进入下一步;
- 如果系统管理员规定,谁引起oom,杀掉谁,那就杀掉正在尝试分配内存的进程,oom killer结束,否则进入下一步
- 调用select_bad_process选中合适进程,然后调用oom_kill_process杀死选中进程,如果不幸select_bad_process没有选出任何进程,那么内核走投无路,只有panic了。
2 选择一个“最坏的”进程
kill掉进程的过程就是这样,我们再来看下select_bad_process函数是如何选择要被kill掉进程的:

在该函数中,会遍历系统中的所有进程,然后使用oom_evaluate_task这个函数,对各个进程进行评估
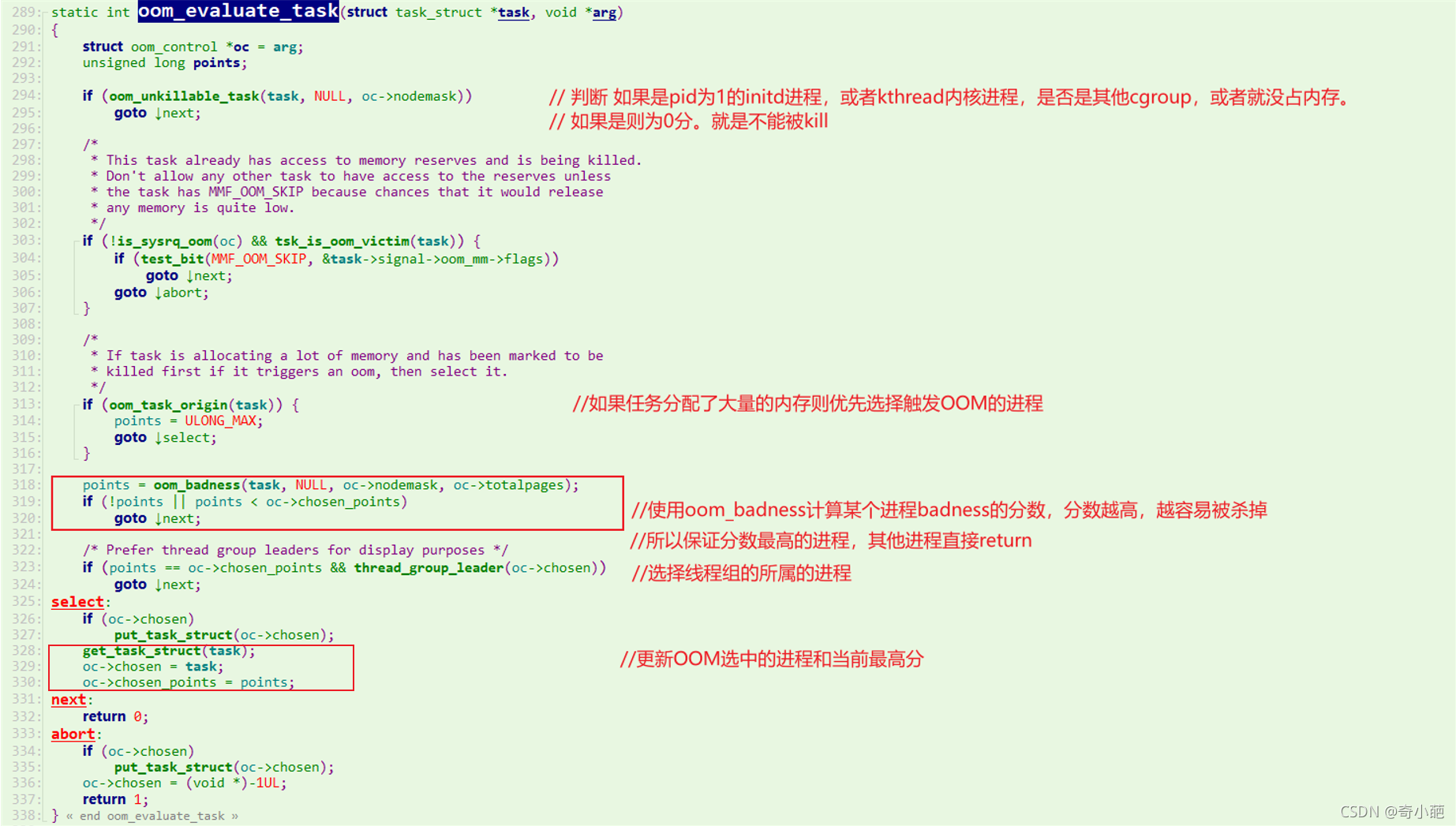
- 首先会跳过不可以被杀死的内核进程
- 如果一个进程是否分配了大量内存空间就直接返回优先杀死该进程并且不用往下走去评分
- 走通过oom_badness函数评分后返回,每次返回的分数和OC结构体的分数比较好后把较大的分数和其进程保存在OC中。oom_badness()是给进程打分的函数,可以说是核心中的核心、
- 如果badness的点数是负值,则直接跳过该进程,即该进程不会成为被kill掉的对象,如果badness点数小于之前选择进程的badness点数,同样也跳过该进程,即被kill掉的进程badness点数要是最大的。
- 遍历中选择的进程,及其badness的点数,会被赋值到oc->chosen和oc->chosen_points里,oc->chosen最终指向的进程,就是上面oom_kill_process里kill掉的进程。
我们再来看下badness点数是如何计算的,slect_bad_process从系统中选择一个适合被杀死的进程,对于系统关键进程(如init进程、内核线程等)是不能被杀死的,其它进程则通过oom_badness进行打分(0~1000),分数最高者被选中
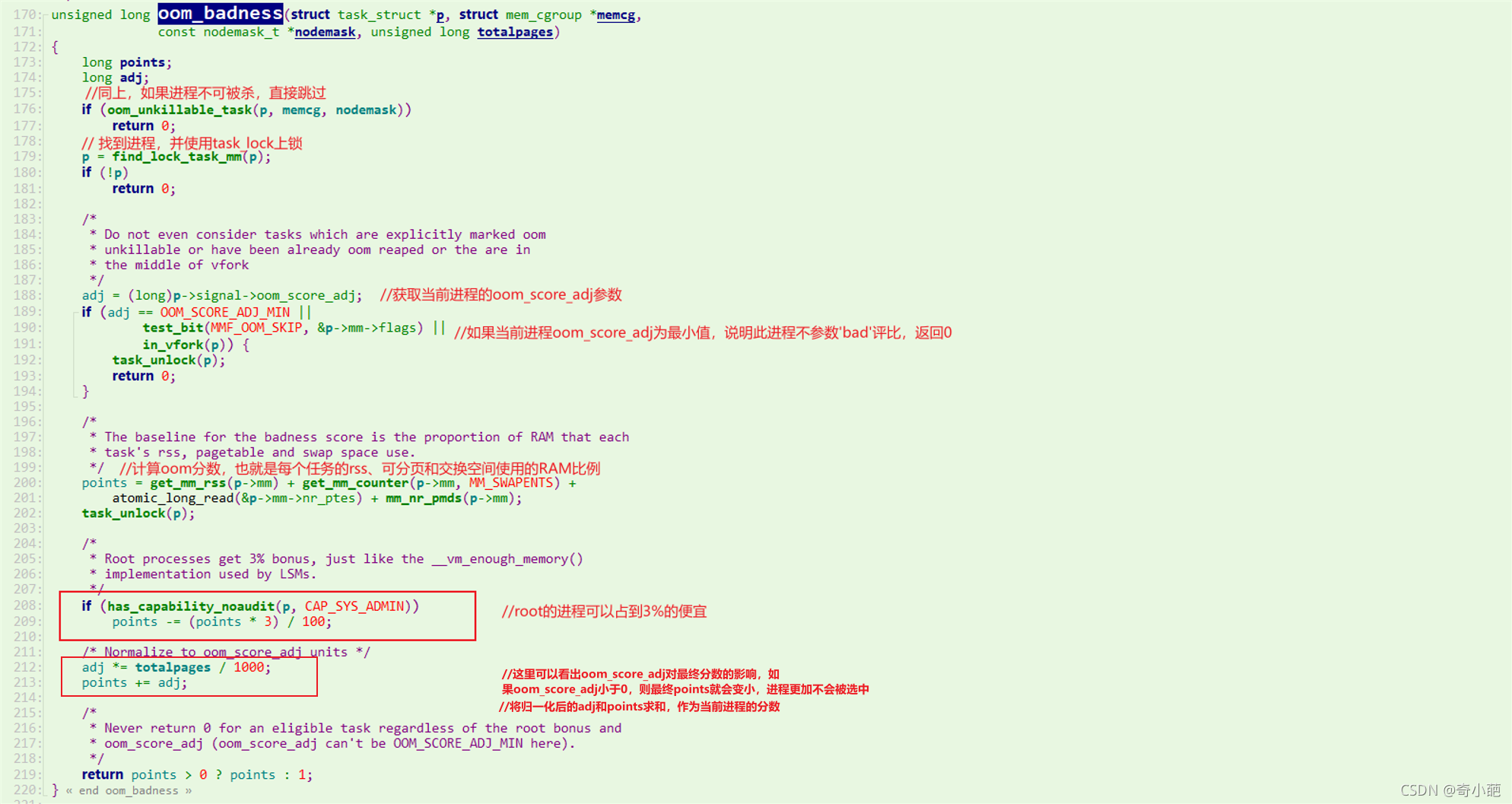
-
不会被kill掉的情况,这些情况包括,oom_score_adj的值为OOM_SCORE_ADJ_MIN,即-1000,或者该进程已经在被kill的过程中了,或者该进程在vfork过程中。
-
另外一部分就是计算进程的badness点数,其大致的计算规则为:
points = 该进程占用的物理内存总数 + 总物理内存 * oom_score_adj值的千分比
oom_score_adj的值,是进程独有的,是可以通过写 /proc/[pid]/oom_score_adj 的方式调整的,取值范围为 -1000 到 1000。
- 该值越大,进程总的badness点数就会越大,进程也就越容易被kill掉。
- 该值越小,进程总的badness点数就会越小,该进程也就越不容易被kill掉。
上面我们还提到oom_score_adj有一个特殊值为OOM_SCORE_ADJ_MIN,即-1000,表示该进程不能被kill掉。各进程的oom_score_adj的值默认为0。
综上可知,linux内核中oom killer选择被kill进程的方式,就是看各进程badness点数的大小。默认情况下,因为各进程的oom_score_adj的值都为0,所以进程占用的物理内存越大,其badness点数也就越大,其也就越容易被kill掉。
oom_badness给进程打分,系统可以通过/proc/<PID>/oom_score_adj或/proc/<PID>/oom_adj影响oom killer对进程的打分,子进程也会继承该权值:
- /proc//oom_adj:(-1715):取值范围:-1615 值越小,越不容易被选中,禁止OOM killer选中此时为-17
- /proc//oom_score_adj:(-1000~1000),取值越小进程越不容易被选中,禁止oom killer选中此时为-1000
3 杀掉进程
对于进程,杀死该进程下面得分最高的线程,而对于共享线程,也会成为牺牲品,一同被杀死。


4 内核信息打印
select_bad_process调挑选最’bad‘的进程讲完了,现在说说dump_header如何打印OOM信息

5 OOM参数
不过对于kernel而言,当面对OOM的时候,咱们也不能慌乱,要根据OOM参数来进行相应的处理
5.1 panic_on_oom
通过配置echo 1 > /proc/sys/vm/panic_on_oom

当kernel遇到OOM的时候,可以有两种选择:
- 产生kernel panic(就是死给你看)
- 积极面对人生,选择一个或者几个最“适合”的进程,启动OOM killer,干掉那些选中的进程,释放内存,让系统勇敢的活下去

所以对于panic_on_oom取值为
- 当该参数等于0的时候,表示选择积极面对人生,启动OOM killer
- 当该参数等于2的时候,表示无论是哪一种情况,都强制进入kernel panic。
- panic_on_oom等于其他值的时候,表示要区分具体的情况,对于某些情况可以panic,有些情况启动OOM killer
enum oom_constraint 就是一个进一步描述OOM状态的参数。系统遇到OOM总是有各种各样的情况的,kernel中定义如下:

对于UMA而言, oom_constraint永远都是CONSTRAINT_NONE,表示系统并没有什么约束就出现了OOM,不要想太多了,就是内存不足了。在NUMA的情况下,有可能附加了其他的约束导致了系统遇到OOM状态,实际上,系统中还有充足的内存。这些约束包括:
- CONSTRAINT_CPUSET: cpusets是kernel中的一种机制,通过该机制可以把一组cpu和memory node资源分配给特定的一组进程。这时候,如果出现OOM,仅仅说明该进程能分配memory的那个node出现状况了,整个系统有很多的memory node,其他的node可能有充足的memory资源。
- CONSTRAINT_MEMORY_POLICY: memory policy是NUMA系统中如何控制分配各个memory node资源的策略模块。用户空间程序(NUMA-aware的程序)可以通过memory policy的API,针对整个系统、针对一个特定的进程,针对一个特定进程的特定的VMA来制定策略。产生了OOM也有可能是因为附加了memory policy的约束导致的,在这种情况下,如果导致整个系统panic似乎有点不太合适吧。
- CONSTRAINT_MEMCG: MEMCG就是memory control group,Cgroup这东西太复杂,这里不适合多说,Cgroup中的memory子系统就是控制系统memory资源分配的控制器,通俗的将就是把一组进程的内存使用限定在一个范围内。当这一组的内存使用超过上限就会OOM,在这种情况下的OOM就是CONSTRAINT_MEMCG类型的OOM。
5.2 oom_kill_allocating_task
当系统选择了启动OOM killer,试图杀死某些进程的时候,又会遇到这样的问题:干掉哪个,哪一个才是“合适”的哪那个进程?系统可以有下面的选择:
- 谁触发了OOM就干掉谁
- 谁最“坏”就干掉谁
oom_kill_allocating_task这个参数就是控制这个选择路径的,当该参数等于0的时候选择(2),否则选择(1)。具体的代码可以在参考__out_of_memory函数,具体如下:


当然也不能说杀就杀,还是要考虑是否用户空间进程(不能杀内核线程)、是否unkillable task(例如init进程就不能杀),用户空间是否通过设定参数(oom_score_adj)阻止kill该task。如果万事俱备,那么就调用oom_kill_process干掉当前进程。
5.3 oom_dump_tasks
当系统的内存出现OOM状况,无论是panic还是启动OOM killer,做为程序员,你都是想保留下线索,找到OOM的root cause,例如dump系统中所有的用户空间进程关于内存方面的一些信息,包括:进程标识信息、该进程使用的total virtual memory信息、该进程实际使用物理内存(我们又称之为RSS,Resident Set Size,不仅仅是自己程序使用的物理内存,也包含共享库占用的内存),该进程的页表信息等等。拿到这些信息后,有助于了解现象(出现OOM)之后的真相。
当设定为0的时候,上一段描述的各种进程们的内存信息都不会打印出来。在大型的系统中,有几千个进程,逐一打印每一个task的内存信息有可能会导致性能问题(要知道当时已经是OOM了)。当设定为非0值的时候,在下面三种情况会调用dump_tasks来打印系统中所有task的内存状况:
- 由于OOM导致kernel panic
- 没有找到适合的“bad”process
- 找适合的并将其干掉的时候


5.4 oom_adj、oom_score_adj和oom_score
到底干掉哪一个呢?内核的算法倒是非常简单,那就是打分(oom_score,注意,该参数是read only的),找到分数最高的就OK了。那么怎么来算分数呢?可以参考内核中的oom_badness函数:
- 用户可以调整oom_score,具体如何操作呢?oom_score_adj的取值范围是-1000~1000,0表示用户不调整oom_score,负值表示要在实际打分值上减去一个折扣,正值表示要惩罚该task,也就是增加该进程的oom_score。在实际操作中,需要根据本次内存分配时候可分配内存来计算(如果没有内存分配约束,那么就是系统中的所有可用内存,如果系统支持cpuset,那么这里的可分配内存就是该cpuset的实际额度值)。
- oom_badness函数有一个传入参数totalpages,该参数就是当时的可分配的内存上限值。实际的分数值(points)要根据oom_score_adj进行调整,例如如果oom_score_adj设定-500,那么表示实际分数要打五折(基数是totalpages),也就是说该任务实际使用的内存要减去可分配的内存上限值的一半。
了解了oom_score_adj和oom_score之后,应该是尘埃落定了,oom_adj是一个旧的接口参数,其功能类似oom_score_adj,为了兼容,目前仍然保留这个参数,当操作这个参数的时候,kernel实际上是会换算成oom_score_adj,有兴趣的同学可以自行了解,这里不再细述了。
5.5 overcommit_memory
实际的物理内存页的分配发生在使用的瞬间而非分配的瞬间,如果某个进程申请了200M的内存,但是实际上只使用了100M,未使用的100M根本没有分配物理内存页。当进程需要内存时,进程从内核得到的只是虚拟地址的使用权,而不是实际的物理地址,实际的物理地址只有当进程真正去访问新获取的虚拟地址产生缺页异常,从而进入分配实际的物理地址。所以当分配了太多的虚拟内存,导致物理内存不够,就会发生OOM,这种允许超额commit的机制就是overcommit。

overcommit即操作系统在应用申请内存空间时不去检查是否超出当前可用量,随意满足申请要求,应用也不管实际是否有足够多的内存可使用,认为我申请了2G,OS肯定就给我2G使用。最后,随着内存越用越多,OS发现内存不够用了,必须要收回一些内存才行,就触发了上述的OOM Killer机制回收内存。
Linux根据参数 vm.overcommit_memory设置overcommit:
- 0 - 操作系统自行决定进程是否过载使用内存,通常这是默认值, 内核将检查是否有足够的可用内存供应用进程使用;如果有足够的可用内存,内存申请允许;否则,内存申请失败,并把错误返回给应用进程
- 1 - 强制过载使用内存, 表示内核允许分配所有的物理内存,而不管当前的内存状态如何,这样配置会有导致内核进程内存不足的风险 ,适用于某些内存必须分配成功的科学计算场景
- 2 - 不允许过载使用内存,表示内核允许分配超过所有物理内存和交换空间总和的内存,意味着系统分配的内存不会超过总内存乘以
overcmmit_ratio(/proc/sys/vm/overcommit_ratio,默认50%),这是最安全的配置。
6 总结
oom_killer(out of memory killer)是Linux内核的一种内存管理机制,在系统可用内存较少的情况下,内核为保证系统还能够继续运行下去,会选择杀掉一些进程释放掉一些内存。通常oom_killer的触发流程是:
进程A想要分配物理内存(通常是当进程真正去读写一块内核已经“分配”给它的内存)->触发缺页异常->内核去分配物理内存->物理内存不够了,触发OOM
对于OOM Killer的机制,大致分为以下步骤:
-
检查可用内存: 如果这些内存空间加起来能够满足申请分配的数量,Linux会执行回收并分配内存的动作,不会触发OOM处理
-
判断OOM状态: 当系统内存不足,并且向磁盘交换并回收旧页帧(page frames)也无法释放足够的内存时,Linux会调用
out_of_memory()来决策是否要杀死进程。 -
选择牺牲者进程: 到了这一阶段,OOM Killer会从一众程序中按照一定规则计算和选取一个进程杀死并释放内存, 以保证系统能够继续运行。选择进程时会遵循如下原则
- 尽量选择内存占用较多的进程(通常容易命中我们的服务进程)
- 尽量通过杀死最少的进程来达到目标
- 尽量不杀死系统和内核运行需要的进程
- 如果有进程处于
SIGKILL或者退出动作中,优先选择以加快内存释放OOM Killer通过一套尽心设计的算法计算每个进程的oom_score,按照分数高低选择应该杀死哪个进程。
-
杀死牺牲者: 选出牺牲者进程后,OOM Killer会发送``信号杀死牺牲者,即使这个程序本身没有任何问题。
如果内存依然不足,OOM Killer会重复上面的步骤,继续选择并杀死新的进程,直到释放足够的内存位置, 颇有为了拯救世界宁愿杀尽天下人。














 997
997











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









