






上篇文章: Qwen1.5大语言模型微调实践_qwen1.5 7b微调-CSDN博客
我们介绍了Qwen1.5 大语言模型使用LLaMA-Factory 来微调,这篇文章我们介绍一下微调后模型的导出、部署。
一、模型导出
在webui 界面训练好模型之后点击“Export”选项卡,然后,在“模型路径”中输入原始模型路径,然后在“检查点路径(适配器路径)”中选择自己微调得到的 adapter 路径,然后在“最大分块大小(GB)”中设置为4,同时设置一下导出目录,最后点击“开始导出”,就可以看到输出的模型了。

导出的模型:

二、模型部署
这里我使用 llama.cpp 来本地部署, llama.cpp 可以使用纯 c/c++ 来进行推理,不需要依赖库或者其他的部署框架。
1.部署环境搭建
克隆仓库到本地,并编译:
git clone https://github.com/ggerganov/llama.cpp.gitcd llama.cpp
make安装一下模型转换为gguf所需的依赖环境:
pip install -r requirements.txt2.把自己训练好的模型转换为gguf模型
先把自己训练好导出的 qwen2-7b模型文件夹 拷贝到 llama.cpp/models 目录下,然后再使用以下命令转换为gguf 格式的模型:
# [Optional] for models using BPE tokenizers
python convert-hf-to-gguf.py models/qwen2_7b在该目录下就会生成 ggml-model-f16.gguf 文件
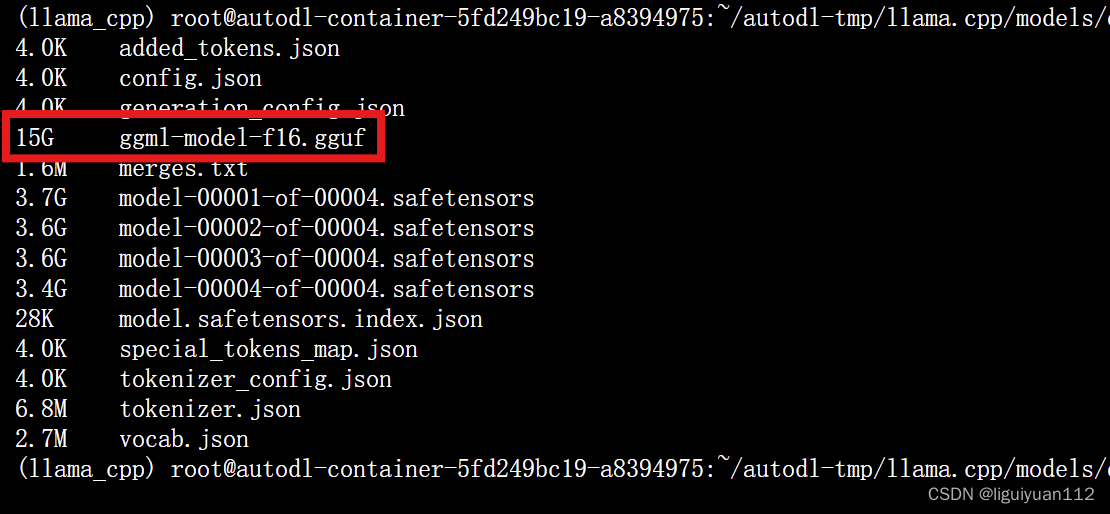
3.对gguf-f16 模型进行量化
# quantize the model to 4-bits (using Q4_K_M method)
./llama-quantize ./models/qwen2-7b/ggml-model-f16.gguf ./models/qwen2-7b/ggml-model-Q4_K_M.gguf Q4_K_M生成量化后的Q4 模型 ggml-model-Q4_K_M.gguf
4.运行gguf模型
./llama-cli -m ./models/qwen2-7b/ggml-model-Q4_K_M.gguf -n 256 --repeat_penalty 1.0 --color -i -r "User:" -f prompts/chat-with-bob.txt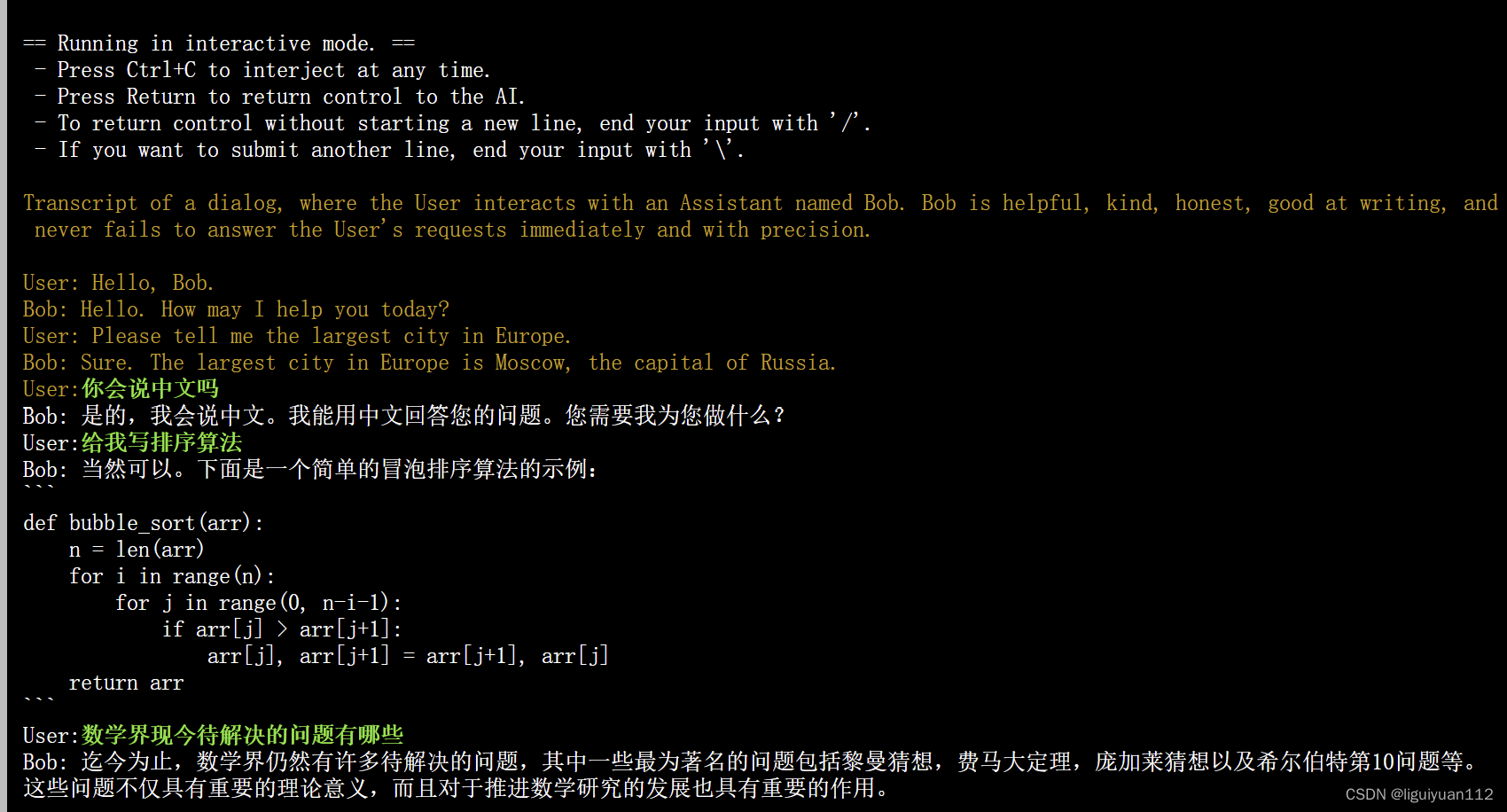
这样我们就可以把模型部署好了,同时也可以使用服务器模块把整个部署为服务端,方便不同的设备通过网络进行访问调用。
















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











