







- 冒泡排序
- 归并排序
- 快速排序
冒泡排序
这应该是初学者最熟悉的排序,就是
相邻两数比较,若逆序则交换。n - 1 趟之后数组有序。
运行的过程上看,就像一个大泡泡逐渐浮出水面。
冒泡的时间复杂度
最好境况下,数组正序,比较一趟 ,
O(n)
最坏情况下,数组逆序,比较
时间复杂度 O(n2)
平均情况下也是 O(n2)
归并排序
使用分治法的一种异地排序。
原理如下
将一个大数组,分解成两个子数组,分别排序,在合并两个有序数组。
递归进行,直到数组长度为1
如图
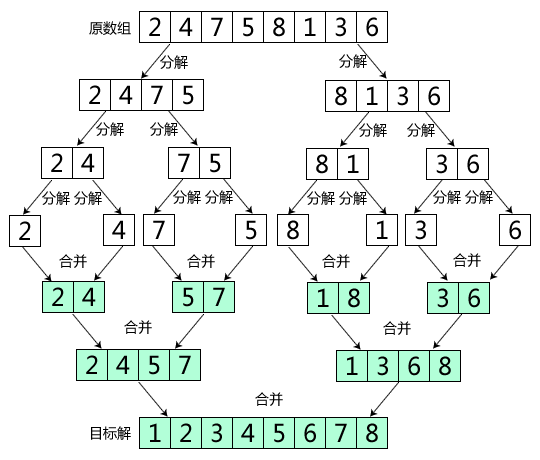
归并的时间复杂度
递归的时间复杂分析
1)分解 直接分解, 时间为常数级
2)治之 对两个数组排序, 时间为
2T(n/2)
3)合并 扫描一遍数组,时间为线性级
整体的时间为
T(n)=2T(n/2)+O(n)
由递归表达式得
T(n)=O(nlogn)
,线性指数级
分析一下可以得出,正序或逆序对归并排序的影响并不大,不管是否有序,他都会走完全程,可能在合并的时候有一点优势,但时间复杂度仍然没变。
我的代码如下
public static void sort(int[] data, int p, int r){
if(p < r){
int q = (p+r) / 2;
sort(data,p,q);
sort(data,q+1,r);
merge(data,p,q,r);
}
}
/**
* 合并两个有序数组
* @param data 原数组
* @param p 起点索引
* @param q 中点索引
* @param r 终点索引
*/
public static void merge(int[] data, int p,int q,int r){
int n = q-p + 1;
int m = r-q;
int i,j;
int[] A = new int[n+1];
int[] B = new int[m+1];
for(i = 0; i < n; i ++){
A[i] = data[p+i];
}
for(i = 0; i < m; i ++){
B[i] = data[q+i+1];
}
B[m] = Integer.MAX_VALUE;
A[n] = Integer.MAX_VALUE;
i = 0; j = 0;
for(int k = p; k <= r; k ++){
if(A[i] <= B[j]){
data[k] = A[i];
i ++;
}else{
data[k] = B[j];
j ++;
}
}
}快速排序
分析冒泡排序,每一趟都要和 n - i 个数比较,而归并排序,将数组分成两部分,就可以减少比较,
那如果每一趟不是找到最大的“泡泡”,而是到一个中间的位置,(分界点)
而将数组分成两部分,一边都比这个“泡泡”小,一边比这个“泡泡”大,然后递归下去,也能达到有序。
这就是快速排序的思想。我的代码
public void sort(int[] data,int p, int r){
int q;
if(p < r){
q = partition(data,p,r); // 分解过程
sort(data,p,q-1);
sort(data,q+1,r);
}
}与归并的不同
归并和快速都采用了分治法,将数组分成两部分,分别排序而两者有什么不同呢
从代码就可以看出
归并排序 是先递归后合并 分解不需成本 (先享受后付出代价)
快速排序 是先分解后递归 合并不需成本 (先付出后收获成果)
分解过程
分解过程我了解了三个版本。
第一种快速排序的分解过程 (分界点为第一个元素)
数组 A 排序第 p 到 r 个元素
选择一个分界点“泡泡”(这里选择第一个元素), 其值记为 x
设置两个游标 i =p,j = p+1
进入循环 若A[j] <= x , i ++ , 交换 A[i] <=>A[j]
否则 j ++, 直到 j = r
最后交换 A[p] <=>A[i]
图解:
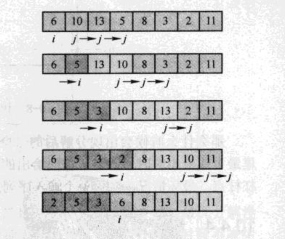
第二种快速排序的分解过程 (分界点为最后一个元素)
数组 A 排序第 p 到 r 个元素
选择一个分界点“泡泡”(这里选择最后一个元素), 其值记为 x
设置两个游标 i =p-1,j = p
进入循环 若A[j] <= x , i ++ , 交换 A[i] <=>A[j]
否则 j ++, 直到 j = r
最后交换 A[r] <=>A[i+1]
图解:
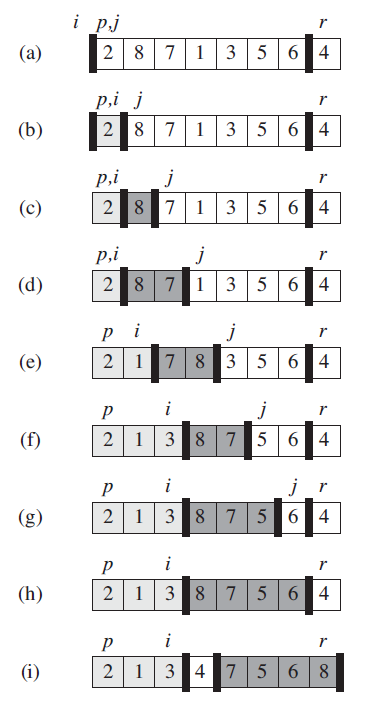
这两种方法大同小异,循环过程一样,就是两个游标的初值,和循环的终止条件差一个位置
我的代码
public static int partition(int[] data,int p, int r){
int x = data[r];
int i = p-1;
int temp = 0;
for(int j = p; j < r; j ++){
if(data[j] <= x){
i = i + 1;
temp = data[i];
data[i] = data[j];
data[j] = temp;
}
}
temp = data[i+1];
data[i+1] = data[r];
data[r] = temp;
return i + 1;
}第三种快速排序的分解过程 (从两边向中间)
数组 A 排序第 p 到 r 个元素
选择一个分界点“泡泡”(这里选择第一个元素), 其值记为 pivotkey
设置两个游标 i =p,j = r
进入循环
先从后向前扫描 (j–) ,直到 A[j] < pivotkey , 令 A[i] =A[j]
再从后向前扫描(i++),直到 A[i] > pivotkey , 令A[i] =A[j]
当 i >= j 时循环结束
最后交换 A[i] =pivotkey
在此过程中不用交换 A[i] 、 A[j] ,因为 A[i] 、 A[j]中的一个值是分界点,而分界点的值已被记录 (pivotkey),所以不需要再数组中多余复值,最后一步到位就可以了。而上面两个过程并没有这个特点。
图解:

我的代码
public static int partition2(int[] data,int p, int r){
int x = data[p];
int i = p;
int j = r;
while(i < j){
while(i<j && data[j] >= x) j --;
data[i] = data[j];
while(i<j && data[i] <= x) i ++;
data[j] = data[i];
}
data[i] = x;
return i;
}效率测试
我用一百万条数据在java上的检测表明
前两种方法的平均时间为 115 毫秒
第三种方法的平均时间为 130 毫秒
我也觉得很奇怪,理论上第三种方法减少了很多赋值操作为什么还会慢呢。
进一步的测试
三种方法的data 与 x 的比较次数差不多。
第三种方法比前两种的 逆序情况少 (即方法一需要交换,方法三需要赋值)(一百万条数据时平均少了 2000000 次)。
这个结果更加是我奇怪,逆序情况少说明算法更优呀!
分析一下程序
第三种方法中有循环的嵌套,而且比较 i < j 的次数多了很多。(一百万条数据时平均多了 5000000 次)。
只能说算法是好的,但实现的时候并不一定是好的。可能这个问题还有关内存的查询,缓存的命中等等。
时间复杂度
和归并排序中有序或无序对时间没有太大影响,那对快速排序呢。
设想当数组有序(无论正序逆序),我们每次选出的“分界线”(第一或最后的元素)就是最大或最小的,这样就不能将数组分成两部分,那这个“分界线”其实就是冒泡排序中最大的“泡泡”。
当数组有序时,快速排序退化成冒泡排序,就是最坏情况
(而且由于是递归效率效果很差,在10万条数据时我的JVN直接“内存溢出”,因为递归太深)
那最好情况是什么呢,就是我们想让
选出的“分界线”能刚好平分数组
好的结论就是
最坏的时间复杂度:
O(n2)
平均的时间复杂度:
O(nlogn)
改进(随机化)
由上面的分析,“分界点”的选择会影响算法的时间。那为了避免最坏情况的发生,或者说避免敌人(黑客知道了你的算法你就完了)的攻击,我们在选择“分界点”时要进行随机化,除非你的运气太差,每次随机到最值,不然效率就是好的。
文献参考
[1] 严蔚敏,吴伟民 . 数据结构(C语言版)
[2] 邹恒明. 算法之道
[3] 算法导论















 200
200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









