






1【背景】
这个在网络上也叫“敏感词过滤”,比如一些论坛、贴吧,涉及政治类词、骂爹骂娘的词,就得过滤掉。
我是闲着无聊,就看了下。
一开始想着用好几个replace不就好了吗,后来网上说这种效率太低了。
查了下,发现这一块还是比较深,最后我找了2种方法(方法是别人写的,从网上找的),都是精确匹配脏词的。效率如何不怎么关心,反正是有点意思的,所以想发一下。
(精确匹配脏词)这种方法得有个脏词库,目的就是将X文本出现的脏词替换掉。(还有人推荐了一种用贝叶斯公式替换脏词的,这种是靠概率,不是精确替换。有兴趣的可以了解下)
2【算法评论】
2.1叫它byte方法,也不知道有没有名字。代码里面对应——BadWordsFilter。
该算法的亮点是fastCheck,它代表某个脏字,在所有脏词里,曾出现的位置,比较机巧。因为它是位置信息,在检测脏词的时候有优势,可以减少判断。
缺点是fastCheck里有很多无用位置,并且因为它是byte,导致脏词长度最多只能有8位。
因为这些缺点,我试着改了下——BadWordsFilter2。改了以后好像变慢了许多。
2.2Tire(前缀树)方法
亮点就是前缀树结构了,不了解该结构的可以去百度下。
还有就是这个方法简单、好写。比上一个方法要好写。
3【结果评价】
哪个方法更好就不说了,实现的东西都不同,没有可比性。
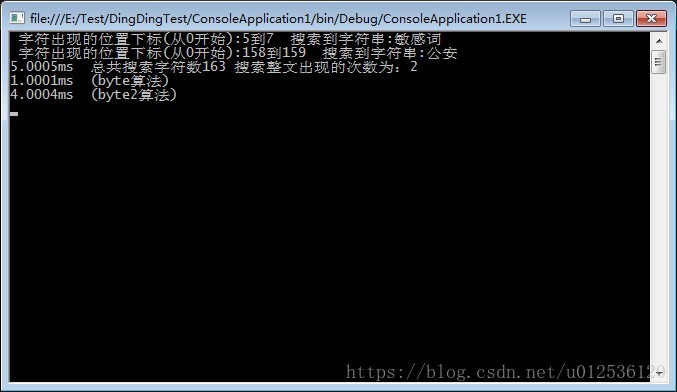
但是为什么我的BadWordsFilter2会比原版的慢那么多?一个是4.0001ms,一个是1.0001ms。
从我开始写代码,就不怎么会测效率问题。还是机巧的方法更能激起我的兴趣。
这种byte表示位的思想,以前有遇到过,比如:5个数里取3个。可以写成单循环(2^6-1次),像10110,有3个1的就可以取。
4【代码】
using System;
using System.Collections.Generic;
using System.Collections;
namespace ConsoleApplication1
{
class Program
{
static void Main(string[] args)
{
DateTime dt1 = DateTime.Now;
string[] keywords = new string[] { "林*", "敏感词", "过滤", "公安" };
var text = @"手机版| 敏感词收藏本站
网站首页
政务公开
网上办事
互动交流
专题专栏
帮助中心
我要咨询
常见问题
站点地图
手机门户
关于我们
联系我们
评比统计
导航链接
收藏本站收藏本站|关于我们|联系我们|站点地图|评比统计|手机门户
闽ICP备号 公安备案号";
#region 叉树算法部分
Trie trie = new Trie();
foreach (string keyword in keywords) trie.Add(keyword);
int size = 0;
int researchCount = 0;//总共搜索到的次数
size += text.Length;
string foundKeyword = null;
for (int i = 0; i < text.Length ; i++)
{
object token = null;
for (int j = i; j < text.Length; j++)
{
char charChild = text[j];
if (trie.Exist(charChild, ref token))//trie.Exist这个是关键函数了
{
foundKeyword = text.Substring(i, j - i + 1);
Console.WriteLine(" 字符出现的位置下标(从0开始):" + i + "到" + j + " 搜索到字符串:" + foundKeyword);
researchCount++;
i = j;//跳过中间的j-i个位置
break;
}
if (token == null) break;
}
}
DateTime dt2 = DateTime.Now;
TimeSpan ts = dt2 - dt1;
Console.WriteLine(ts.TotalMilliseconds + "ms 总共搜索字符数" + size + " 搜索整文出现的次数为:" + researchCount);
#endregion 叉树算法部分
#region byte算法
dt1 = DateTime.Now;
BadWordsFilter WFilter = new BadWordsFilter();
foreach (string keyword in keywords) WFilter.AddKey(keyword);
string str1 = WFilter.ReplaceBadWord(text);
//Console.WriteLine(str1);
dt2 = DateTime.Now;
Console.WriteLine((dt2 - dt1).TotalMilliseconds + "ms (byte算法)");
#endregion
#region byte2算法
dt1 = DateTime.Now;
BadWordsFilter2 BWFilter = new BadWordsFilter2();
foreach (string keyword in keywords) BWFilter.AddKey(keyword);
string str2 = BWFilter.ReplaceBadWord(text);
//Console.WriteLine(str2);
dt2 = DateTime.Now;
Console.WriteLine((dt2 - dt1).TotalMilliseconds + "ms (byte2算法)");
#endregion
Console.ReadLine();
}
}
//前缀树 结构
public class Trie
{
TrieNode root = new TrieNode((char)0);
public bool HasCount()
{
TrieNode node = root;
return root.HasChild();
}
public void Add(string word)
{
TrieNode node = root;
foreach (char c in word)
{
node = node.AddChild(c);
}
node.AddChild((char)0);
}
public void Delete(string word)
{
TrieNode node = root;
foreach (char c in word)
{
node.DeleteChild(c);
}
node.DeleteChild((char)0);
}
public bool Exist(string word)
{
TrieNode node = root;
foreach (char c in word)
{
node = node.GetChild(c);
if (node == null) return false;
}
return node.GetChild((char)0) != null;
}
public bool Exist(char c, ref object token)
{
TrieNode node = (token as TrieNode ?? this.root).GetChild(c);
token = node;
return node != null && node.Terminated;
}
class TrieNode
{
private char value;
private SortedList<char, TrieNode> childNodes = new SortedList<char, TrieNode>();
public TrieNode(char c)
{
this.value = c;
}
public bool HasChild()
{
return this.childNodes.Count > 0 ? true : false;
}
public TrieNode GetChild(char c)
{
TrieNode node = null;
childNodes.TryGetValue(c, out node);
return node;
}
public TrieNode AddChild(char c)
{
TrieNode node = GetChild(c);
if (node == null)
{
this.childNodes.Add(c, node = new TrieNode(c));
}
return node;
}
public bool DeleteChild(char c)
{
bool bol = false;
TrieNode node = GetChild(c);
if (node != null)
{
bol = this.childNodes.Remove(c);
}
return bol;
}
public bool Terminated { get { return this.childNodes.ContainsKey((char)0); } }
}
}
//这个是网上抄的,写法比较经典
public class BadWordsFilter
{
//保存脏字的字典
private List<string> KeyWordDictionary = new List<string>();
private byte[] fastCheck = new byte[char.MaxValue];
private BitArray charCheck = new BitArray(char.MaxValue);
private int maxWordLength = 0;
private int minWordLength = int.MaxValue;
private string _replaceString = "*";
/// <summary>
/// 从文本生成字典
/// </summary>
/// <param name="word"></param>
public void AddKey(string word)
{
maxWordLength = Math.Max(maxWordLength, word.Length);
minWordLength = Math.Min(minWordLength, word.Length);
for (int i = 0; i < 8 && i < word.Length; i++)
{
fastCheck[word[i]] |= (byte)(1 << i);
}
if (word.Length == 1)
{
charCheck[word[0]] = true;
}
else
{
KeyWordDictionary.Add(word);
}
}
/// <summary>
/// 脏词替换
/// </summary>
/// <param name="text"></param>
/// <returns></returns>
public string ReplaceBadWord(string text)
{
for (int index = 0; index < text.Length; index++)
{
if ((fastCheck[text[index]] & 1) == 0)
{
while (index < text.Length - 1 && (fastCheck[text[++index]] & 1) == 0) ;
}
//单字节检测
if (minWordLength == 1 && charCheck[text[index]])
{
text = text.Replace(text[index], _replaceString[0]);
continue;
}
//多字节检测
for (int j = 1; j <= Math.Min(maxWordLength, text.Length - index - 1); j++)
{
//快速排除
if ((fastCheck[text[index + j]] & (1 << Math.Min(j, 8))) == 0) break;
if (j + 1 >= minWordLength)
{
string sub = text.Substring(index, j + 1);
if (KeyWordDictionary.Contains(sub))
{
//替换字符操作
char cc = _replaceString[0];
string rp = _replaceString.PadRight((j + 1), cc);
text = text.Replace(sub, rp);
//记录新位置
index += j;
break;
}
}
}
}
return text;
}
}
//这个是根据BadWordsFilter改的
public class BadWordsFilter2
{
private List<string> KeyWordDictionary = new List<string>();//保存脏词的字典
//代表某个脏字,在所有脏词里,曾出现的位置(这个变量是核心)
//比如0101,代表在位置1,3处曾出现过该脏词。它是从1开始,从后往前数
private Dictionary<char, int> fastCheck = new Dictionary<char, int>();
private int maxWordLength = 0;//脏词最大长度
private int minWordLength = int.MaxValue;
private string _replaceString = "*";//替换成*
/// <summary>
/// 添加脏词典
/// </summary>
/// <param name="word"></param>
public void AddKey(string word)
{
maxWordLength = Math.Max(maxWordLength, word.Length);
minWordLength = Math.Min(minWordLength, word.Length);
for (int i = 0; i < 31 && i < word.Length; i++)//int是32位,有一位符号位
fastCheck.Add(word[i], word[i] | (byte)(1 << i));
KeyWordDictionary.Add(word);
}
/// <summary>
/// 脏词替换
/// </summary>
/// <param name="text"></param>
/// <returns></returns>
public string ReplaceBadWord(string text)
{
for (int index = 0; index < text.Length; index++)
{
//找出第一个脏字检测位置
while (index < text.Length - 1 && (!fastCheck.ContainsKey(text[index]) || (fastCheck[text[index]] & 1) == 0))
index++;
//单字符
if (KeyWordDictionary.Contains(text[index].ToString()))
{
text = text.Replace(text[index].ToString(), _replaceString);
continue;
}
//多字符
for (int j = 1; j <= Math.Min(maxWordLength, text.Length - index - 1); j++)
{
//快速排除
if (!fastCheck.ContainsKey(text[index + j])) break;
if ((fastCheck[text[index + j]] & (1 << Math.Min(j, 31))) == 0) break;
if (j + 1 >= minWordLength)
{
string sub = text.Substring(index, j + 1);
if (KeyWordDictionary.Contains(sub))
{
//替换字符操作
char cc = _replaceString[0];
string rp = _replaceString.PadRight((j + 1), cc);
text = text.Replace(sub, rp);
//记录新位置
index += j;
break;
}
}
}
}
return text;
}
}
}5【结果】














 1477
1477











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









