







刚开始工作时有个研发大哥告诉,看源码时,首先要了解各部分的数据结构设计,搞清楚数据结构的设计对于理解代码很有帮助,我一直将这句话记在心里。此前因为工作需要,需要对kudu-client 的部分代码进行修改,以实现数据加解密。因此,我仔细研究了一下kudu java client 中对于kudu row的数据结构设计和数据的读写流程,这里我将row的设计思路捋一下,并做一个笔记。
数据写入–PartialRow
Kudu clien中对于一行数据(Row)的数据结构设计如下:
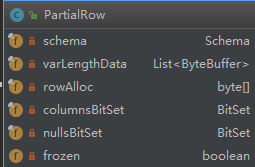
结构整体是比较简单的:
schama :保存了字段的信息
varLengthData:用于存储变长数据,如string, binary这种类型数据
rowAlloc:用于存储数值类型这种定长数据
两个bitset用于记录字段是否set了值, froze用于控制row是否可修改
上述数据结构初始化工作如下:
/**
* This is not a stable API, prefer using {@link Schema#newPartialRow()}
* to create a new partial row.
* @param schema the schema to use for this row
*/
public PartialRow(Schema schema) {
this.schema = schema;
this.columnsBitSet = new BitSet(this.schema.getColumnCount());
this.nullsBitSet = schema.hasNullableColumns() ?
new BitSet(this.schema.getColumnCount()) : null;
this.rowAlloc = new byte[schema.getRowSize()];
// Pre-fill the array with nulls. We'll only replace cells that have varlen values.
this.varLengthData = Arrays.asList(new ByteBuffer[this.schema.getColumnCount()]);
}
上面对varLengthData 进行了初始化,并且计算了rowAlloc 的size,这里我们重点看下如何计算rowAlloc 数据大小的:
/**
* Gives the size in bytes for a single row given the specified schema
* @param columns the row's columns
* @return row size in bytes
*/
private int getRowSize(List<ColumnSchema> columns) {
int totalSize = 0;
boolean hasNullables = false;
Set<Integer> encryptedColIndices = getEncryptedColumnIdsToAlgortithms().keySet();
int size = columns.size();
for (int i = 0; i < size; i++) {
totalSize += columns.get(i).getTypeSize(encryptedColIndices.contains(i));
hasNullables |= columns.get(i).isNullable();
}
if (hasNullables) {
totalSize += Bytes.getBitSetSize(columns.size());
}
return totalSize;
}
上面的代码对每个字段进行遍历,计算数据长度。我们再看下每个数据类型到底占了多大的长度:
/**
* Gives the size in bytes for a given DataType, as per the pb specification
* @param type pb type
* @return size in bytes
*/
private static int getTypeSize(DataType type) {
switch (type) {
case STRING:
case BINARY:
return 8 + 8; // offset then string length
case BOOL:
case INT8:
case IS_DELETED:
return 1;
case INT16:
return Shorts.BYTES;
case INT32:
case FLOAT:
return Ints.BYTES;
case INT64:
case DOUBLE:
case UNIXTIME_MICROS:
return Longs.BYTES;
default: throw new IllegalArgumentException("The provided data type doesn't map" +
" to know any known one.");
}
}
这里给string 和binary分配了16个字节用于记录数据的offset和数据的实际长度(8+8),其余的数据根据当前的情况分配固定的长度。
PartialRow 数据写入
这里写入就是调用其addXX方法,我们以分别为定长数据和变长数据举一个set数据的例子。
定长数据以int数据为例:
/**
* Add an int for the specified column.
* @param columnIndex the column's index in the schema
* @param val value to add
* @throws IllegalArgumentException if the value doesn't match the column's type
* @throws IllegalStateException if the row was already applied
* @throws IndexOutOfBoundsException if the column doesn't exist
*/
public void addInt(int columnIndex, int val) {
checkNotFrozen();
checkColumn(schema.getColumnByIndex(columnIndex), Type.INT32);
Bytes.setInt(rowAlloc, val, getPositionInRowAllocAndSetBitSet(columnIndex));
这里非常简单,就是直接把值set到rowAlloc 字节数组里面,并且将改字段标记为已set值,重要的是如何拿到数据应该存放的位置,即getPositionInRowAllocAndSetBitSet
/**
* Sets the column bit set for the column index, and returns the column's offset.
* @param columnIndex the index of the column to get the position for and mark as set
* @return the offset in rowAlloc for the column
*/
private int getPositionInRowAllocAndSetBitSet(int columnIndex) {
columnsBitSet.set(columnIndex);
return schema.getColumnOffset(columnIndex);
}
变长,以string数据为例,非常简单,直接放到addVarLengthData里面就可以了。
/**
* Add a String for the specified value, encoded as UTF8.
* Note that the provided value must not be mutated after this.
* @param columnIndex the column's index in the schema
* @param val value to add
* @throws IllegalArgumentException if the value doesn't match the column's type
* @throws IllegalStateException if the row was already applied
* @throws IndexOutOfBoundsException if the column doesn't exist
*/
public void addStringUtf8(int columnIndex, byte[] val) {
// TODO: use Utf8.isWellFormed from Guava 16 to verify that.
// the user isn't putting in any garbage data.
checkNotFrozen();
checkColumn(schema.getColumnByIndex(columnIndex), Type.STRING);
addVarLengthData(columnIndex, val);
}
数据读取–RowResult
注释中写道:RowResult represents one row from a scanner. 也就是代表读取kudu数据后返回的行。其结构如下:
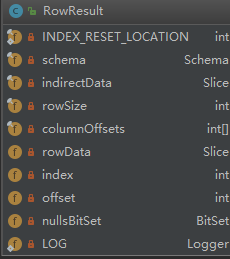
其中, rowData存储定长数据,indirectData存储string和binary的变长数据。我们以long和string为例看看如何读取数据:
之所以要以long类型举例是因为这里有个特殊的地方, 还记得PartialRow中在rowAlloc中也为string和binary申请了空间,这个空间是用于存储变长数据的offset和length的,一共16个字节,8字节用于offset,8字节用于length。
/**
* Get the specified column's long
*
* If this is a UNIXTIME_MICROS column, the long value corresponds to a number of microseconds
* since midnight, January 1, 1970 UTC.
*
* @param columnIndex Column index in the schema
* @return a positive long
* @throws IllegalArgumentException if the column is null
* @throws IndexOutOfBoundsException if the column doesn't exist
*/
public long getLong(int columnIndex) {
checkValidColumn(columnIndex);
checkNull(columnIndex);
checkType(columnIndex, Type.INT64, Type.UNIXTIME_MICROS);
return getLongOrOffset(columnIndex);
}
/**
* Returns the long column value if the column type is INT64 or UNIXTIME_MICROS.
* Returns the column's offset into the indirectData if the column type is BINARY or STRING.
* @param columnIndex Column index in the schema
* @return a long value for the column
*/
long getLongOrOffset(int columnIndex) {
return Bytes.getLong(this.rowData.getRawArray(),
this.rowData.getRawOffset() +
getCurrentRowDataOffsetForColumn(columnIndex));
}
对于string数据,先是获取了offset,然后计算了再读取offset紧接着的8个字节数据长度,然后根据offset和length,以及基础的数据offset读取到数据。这里数据的最大长度为Integer.MAX_VALUE
/**
* Get the specified column's string.
* @param columnIndex Column index in the schema
* @return a string
* @throws IllegalArgumentException if the column is null
* or if the type doesn't match the column's type
* @throws IndexOutOfBoundsException if the column doesn't exist
*/
public String getString(int columnIndex) {
checkValidColumn(columnIndex);
checkNull(columnIndex);
checkType(columnIndex, Type.STRING);
// C++ puts a Slice in rowData which is 16 bytes long for simplicity, but we only support ints.
long offset = getLongOrOffset(columnIndex);
long length = rowData.getLong(getCurrentRowDataOffsetForColumn(columnIndex) + 8);
assert offset < Integer.MAX_VALUE;
assert length < Integer.MAX_VALUE;
return Bytes.getString(indirectData.getRawArray(),
indirectData.getRawOffset() + (int)offset,
(int)length);
}
总结
以上就是kudu client中对于数据写入和读取的数据结构及读写逻辑的一个笔记。如有不当,欢迎指出。















 217
217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









