







说明
- NP: NGINX Plus
- AG: Admin Guide
- 会话: session
- 上游: upstream
- 流量:traffic
- 后端:backend
- 区域:zone
- 切片:slices
- 位置:location
- 根:root
- 终端:termination
- 端点:endpoint
1.在本地部署中对NGINX Plus的高可用性支持
介绍了如何使用基于keepalived的解决方案在本地部署中配置NGINX Plus实例的高可用性。
注意:此解决方案旨在在可以通过标准操作系统调用控制IP地址的环境中工作,而在通过与云基础架构接口控制IP地址的云环境中通常不起作用。 有关使NGINX Plus在云环境中高度可用的信息,请参阅《部署指南》。
1.1.基于keepalived的高可用性支持
NGINX Plus R6及更高版本支持一种基于keepalived的主动-被动(active‑passive)高可用性(HA)设置中的NGINX Plus快速,轻松配置的解决方案。
keepalived 开源项目包括三个组件:
- 适用于Linux服务器的
keepalived守护程序。 - 虚拟路由器冗余协议(VRRP)的实现,用于管理虚拟路由器(虚拟IP地址或VIP)。
VRRP确保始终存在一个主节点。 备用节点监听来自主节点的VRRP通告数据包。 如果它在超过配置的通告间隔的三倍的时间内未收到通告包,则备用节点将作为主节点并为其分配分配的VIP。
- 一种运行状况检查工具,用于确定服务(例如,Web服务器,PHP后端或数据库服务器)是否已启动并且可以运行。
如果主节点上的服务未通过配置的运行状况检查次数,则keepalived 会将虚拟IP地址从主节点重新分配给备份(被动)节点。
1.2.配置高可用性
以root用户身份在两个节点上运行nginx-ha-setup脚本(该脚本分发在nginx-ha-keepalived软件包中,该软件包必须与基本NGINX Plus软件包一起安装)。 该脚本配置了一对高可用的NGINX Plus环境,其中一对主动-被动(active‑passive)节点分别充当主节点和备份节点。 它提示输入以下数据:
- 本地和远程节点的IP地址(其中一个将被配置为主节点,另一个将被配置为备份节点)
- 一个额外的免费IP地址用作集群端点的(浮动)VIP
keepalived守护程序的配置记录在/etc/keepalived/keepalived.conf中。 配置块文件控制通知设置,要管理的VIP和用于检查依赖VIP的服务的运行状况检查。 以下是由CentOS 7机器上的nginx-ha-setup脚本创建的配置文件。 请注意,这不是NGINX Plus配置文件,因此语法不同(例如,不使用分号分隔指令)。
global_defs {
vrrp_version 3
}
vrrp_script chk_manual_failover {
script "/usr/libexec/keepalived/nginx-ha-manual-failover"
interval 10
weight 50
}
vrrp_script chk_nginx_service {
script "/usr/libexec/keepalived/nginx-ha-check"
interval 3
weight 50
}
vrrp_instance VI_1 {
interface eth0
priority 101
virtual_router_id 51
advert_int 1
accept
garp_master_refresh 5
garp_master_refresh_repeat 1
unicast_src_ip 192.168.100.100
unicast_peer {
192.168.100.101
}
virtual_ipaddress {
192.168.100.150
}
track_script {
chk_nginx_service
chk_manual_failover
}
notify "/usr/libexec/keepalived/nginx-ha-notify"
}描述整个配置不在本文讨论范围之内,但有几点值得注意:
- 高可用性设置中的每个节点都需要拥有自己的配置文件副本,并具有与该节点的角色(主角色或备份角色)相对应的
priority,unicast_src_ip,unicast_peer指令值。 priority指令控制哪个主机成为主要主机,如下一节所述。notify指令为分发中包含的通知脚本命名,当状态转换或故障发生时,可用于生成系统日志消息(或其他通知)。vrrp_instance VI_1块中的virtual_router_id指令的值51是样本值; 根据需要进行更改,使其在环境中具有唯一性。- 如果在本地网络中运行多对
keepalived的实例(或其他VRRP实例),请为每个实例创建一个vrrp_instance块,并使用唯一的名称(例如示例中的VI_1)和virtual_router_id编号。
1.3.使用运行状况检查脚本来控制哪个服务器为主服务器
keepalived中没有防护机制。 如果一对中的两个节点互不了解,则每个节点都假定它是主要节点,并为其分配VIP。 为避免这种情况,配置文件定义了一种称为chk_nginx_service 的脚本执行机制,该机制定期运行脚本以检查NGINX Plus是否可运行,并根据脚本的返回码调整本地节点的优先级。 代码0(零)表示操作正确,代码1(或任何非零代码)表示错误。
在脚本的示例配置中,weight指令设置为50,这意味着当检查脚本成功执行(并暗示返回代码0)时:
- 第一个节点的优先级(基本优先级为101)设置为151。
- 第二个节点(基本优先级为100)的优先级设置为150。
第一个节点具有更高的优先级(在这种情况下为151),并成为主节点。
interval指令指定检查脚本执行的频率,以秒为单位(在示例配置文件中为3秒)。 请注意,如果达到超时,检查将失败(默认情况下,超时与检查间隔相同)。
rise和fall指令(在示例配置文件中未使用)指定在执行操作之前脚本必须成功或失败的次数。
nginx-ha-keepalive软件包随附的nginx-ha-check脚本检查NGINX Plus是否已启动。 我们建议根据本地设置创建其他脚本。
1.4.显示节点状态
要查看当前哪个节点是给定VIP的主要节点,请在定义VRRP实例的接口上运行ip addr show 命令(在以下命令中,节点centos7-1和centos7-2上的eth0接口):
centos7-1 $ ip addr show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state
UP qlen 1000
link/ether 52:54:00:33:a5:a5 brd ff:ff:ff:ff:ff:ff
inet 192.168.100.100/24 brd 192.168.122.255 scope global dynamic eth0
valid_lft 3071sec preferred_lft 3071sec
inet 192.168.100.150/32 scope global eth0
valid_lft forever preferred_lft forevercentos7-2 $ ip addr show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state
UP qlen 1000
link/ether 52:54:00:33:a5:87 brd ff:ff:ff:ff:ff:ff
inet 192.168.100.101/24 brd 192.168.122.255 scope global eth0
valid_lft forever preferred_lft forever在此输出中,centos7-1的第二个inet行表明它是主要的-已为其分配了已定义的VIP(192.168.100.150)。 其他inet行显示主节点的真实IP地址(192.168.100.100)和备份节点的IP地址(192.168.100.101)。
节点的当前状态记录在本地/var/run/nginx-ha-keepalived.state文件中。 可以使用cat命令显示它:
centos7-1 $ cat /var/run/nginx-ha-keepalived.state
STATE=MASTER
centos7-2 $ cat /var/run/nginx-ha-keepalived.state
STATE=BACKUP在nginx-ha-keepalived软件包的1.1版和更高版本中,可以使用以下命令将VRRP扩展的统计信息和数据转储到文件系统中:
centos7-1 $ service keepalived dump此命令将信号发送到正在运行的keepalived进程,以将当前状态写入/tmp/keepalived.stats和/tmp/keepalived.data。
1.5.强制状态变更
要强制主节点成为备份节点,请在其上运行以下命令:
$ service keepalived stop关闭时,keepalived将优先级为0的VRRP数据包发送到备份节点,这导致备份节点接管VIP。
如果集群使用的是nginx-ha-keepalived软件包的1.1版,这是强制更改状态的更简单方法:
$ touch /var/run/keepalived-manual-failover此命令创建一个文件,该文件由vrrp_script chk_manual_failover块中定义的脚本检查。 如果文件存在,则keepalived会降低主节点的优先级,这将导致备份节点接管VIP。
1.6.添加更多虚拟IP地址
由nginx-ha-setup脚本创建的配置非常基础,并使单个IP地址具有高可用性。
要使多个IP地址高度可用:
1.将每个新IP地址添加到两个节点上的/etc/keepalived/keepalived.conf文件中的virtual_ipaddress块中:
virtual_ipaddress {
192.168.100.150
192.168.100.200
}virtual_ipaddress块中的语法复制了ip实用程序的语法。
2.在两个节点上运行service keepalived reload命令以重新加载keepalived服务:
centos7-1 $ service keepalived reload
centos7-2 $ service keepalived reload1.7.IPv4和IPv6的双栈(Dual-Stack)配置
在keepalived1.2.20和更高版本(以及nginx-ha-keepalived软件包的1.1和更高版本)中,keepalived 不再支持在一个VRRP实例(virtual_ipaddress 块)中混合IPv4和IPv6地址,因为这违反了VRRP标准。
使用VRRP配置双堆栈(dual‑stack)HA的方法有两种:
- 添加带有一个系列地址的
virtual_ipaddress_excluded块。
vrrp_instance VI_1 {
...
unicast_src_ip 192.168.100.100
unicast_peer {
192.168.100.101
}
virtual_ipaddress {
192.168.100.150
}
...
virtual_ipaddress_excluded {
1234:5678:9abc:def::1
}
...
}地址从VRRP通告中排除,但在状态更改时仍由keepalived管理并添加或删除。
- 为IPv6地址添加另一个VRRP实例。
主节点上IPv6地址的VRRP配置为:
vrrp_instance VI_2 {
interface eth0
priority 101
virtual_router_id 51
advert_int 1
accept
unicast_src_ip 1234:5678:9abc:def::3
unicast_peer {
1234:5678:9abc:def::2
}
virtual_ipaddress {
1234:5678:9abc:def::1
}
track_script {
chk_nginx_service
chk_manual_failover
}
notify "/usr/libexec/keepalived/nginx-ha-notify"
}请注意,由于VRRP IPv4和IPv6实例彼此完全独立,因此VRRP实例都可以使用相同的virtual_router_id。
1.8.对keepalived和VRRP进行故障排除
keepalived守护程序使用syslog实用程序进行日志记录。 在基于CentOS,RHEL和SLES的系统上,通常将输出写入/var/log/messages,而在基于Ubuntu和Debian的系统上,将输出写入/var/log/syslog。 日志条目记录事件,例如keepalived守护程序的启动和状态转换。
以下是一些示例条目,这些示例显示了keepalived守护进程正在启动以及节点将VRRP实例转换为主要状态的情况(为了便于阅读,在第一行之后的每一行中都删除了centos7-1主机名):
Feb 27 14:42:04 centos7-1 systemd: Starting LVS and VRRP High Availability Monitor...
Feb 27 14:42:04 Keepalived [19242]: Starting Keepalived v1.2.15 (02/26,2015)
Feb 27 14:42:04 Keepalived [19243]: Starting VRRP child process, pid=19244
Feb 27 14:42:04 Keepalived_vrrp [19244]: Registering Kernel netlink reflector
Feb 27 14:42:04 Keepalived_vrrp [19244]: Registering Kernel netlink command channel
Feb 27 14:42:04 Keepalived_vrrp [19244]: Registering gratuitous ARP shared channel
Feb 27 14:42:05 systemd: Started LVS and VRRP High Availability Monitor.
Feb 27 14:42:05 Keepalived_vrrp [19244]: Opening file '/etc/keepalived/keepalived.conf '.
Feb 27 14:42:05 Keepalived_vrrp [19244]: Truncating auth_pass to 8 characters
Feb 27 14:42:05 Keepalived_vrrp [19244]: Configuration is using: 64631 Bytes
Feb 27 14:42:05 Keepalived_vrrp [19244]: Using LinkWatch kernel netlink reflector...
Feb 27 14:42:05 Keepalived_vrrp [19244]: VRRP_Instance(VI_1) Entering BACKUP STATE
Feb 27 14:42:05 Keepalived_vrrp [19244]: VRRP sockpool: [ifindex(2), proto(112), unicast(1), fd(14,15)]
Feb 27 14:42:05 nginx-ha-keepalived: Transition to state 'BACKUP ' on VRRP instance 'VI_1 '.
Feb 27 14:42:05 Keepalived_vrrp [19244]: VRRP_Script(chk_nginx_service) succeeded
Feb 27 14:42:06 Keepalived_vrrp [19244]: VRRP_Instance(VI_1) forcing a new MASTER election
Feb 27 14:42:06 Keepalived_vrrp [19244]: VRRP_Instance(VI_1) forcing a new MASTER election
Feb 27 14:42:07 Keepalived_vrrp [19244]: VRRP_Instance(VI_1) Transition to MASTER STATE
Feb 27 14:42:08 Keepalived_vrrp [19244]: VRRP_Instance(VI_1) Entering MASTER STATE
Feb 27 14:42:08 Keepalived_vrrp [19244]: VRRP_Instance(VI_1) setting protocol VIPs.
Feb 27 14:42:08 Keepalived_vrrp [19244]: VRRP_Instance(VI_1) Sending gratuitous ARPs on eth0 for 192.168.100.150
Feb 27 14:42:08 nginx-ha-keepalived: Transition to state 'MASTER ' on VRRP instance 'VI_1 '.
Feb 27 14:42:13 Keepalived_vrrp [19244]: VRRP_Instance(VI_1) Sending gratuitous ARPs on eth0 for 192.168.100.150如果系统日志不能解释问题的根源,请使用以下参数运行tcpdump命令以显示在本地网络上发送的VRRP通告:
$ tcpdump -vvv -ni eth0 proto vrrp如果本地网络上有多个VRRP实例,并且想要过滤输出以仅包括给定服务的节点与其对等方之间的流量,请包括host参数,并在keepalived中指定unicast_peer块所定义的对等方的IP地址,如以下示例所示:
centos7-1 $ tcpdump -vvv -ni eth0 proto vrrp and host 192.168.100.101
tcpdump: listening on eth0, link-type EN10MB (Ethernet), capture size 65535 bytes
14:48:27.188100 IP (tos 0xc0, ttl 255, id 382, offset 0, flags [none],
proto VRRP (112), length 40)
192.168.100.100 > 192.168.100.101: vrrp 192.168.100.100 >
192.168.100.101: VRRPv2 , Advertisement , vrid 51, prio 151,
authtype simple , intvl 1s, length 20, addrs: 192.168.100.150 auth
"f8f0e511"输出中的几个字段对于调试非常有用:
vrid– 虚拟路由器ID(由virtual_router_id指令设置)prio– 节点的优先级(由“priority”指令设置)authtype– 使用的身份验证类型(由authentication指令设置)intvl– 通告的发送频率(由advert_int指令设置)auth– 已发送身份验证令牌(由auth_pass指令设置)
1.9.保持NGINX Plus配置文件同步
节点上的NGINX Plus配置文件都必须定义高度可用的服务。 有关同步NGINX Plus配置的信息,请参阅在集群中同步NGINX配置。
1.10.其他配置示例
nginx-ha-keepalived软件包在/usr/share/doc/nginx-ha-keepalived目录中包含更多配置示例。
2.使用keepalived配置Active-Active高可用性和其他被动节点
2.1.介绍
NGINX Plus利用keepalived以标准的主动-被动(active‑passive)方式提供高可用性(HA)。 如果主NGINX Plus节点出现问题,这将提供故障转移冗余。 我们可以通过添加其他节点和更改保持连接配置来扩展此功能,从而提供其他冗余和可伸缩性选项。 本指南假定已经使用NGINX HA解决方案在主动-被动(active‑passive)实施中配置了NGINX Plus。
注意:在公共云部署中,我们建议使用云提供商提供的第4层或TCP负载平衡服务将流量分配到NGINX Plus,以实现active‑active功能。
2.2.为什么要添加被动(Passive)节点?
许多组织对冗余级别有严格的要求,并且两节点主动-被动(active‑passive)系统可能无法满足这些要求。 添加配置为在其他两个节点都发生故障的情况下接管的第三个节点,可以提供更多的冗余,同时保持配置简单。 这也允许在节点上进行维护而不会丢失冗余。
2.3.为什么配置Active-Active HA?
以“active‑active”方式运行NGINX Plus,其中两个或更多节点可以同时处理流量。 这可以使用多个活动IP地址来实现。 每个IP地址都托管在单个NGINX实例上,并且Keepalived配置可确保将这些IP地址分布在两个或多个活动节点上。
- 托管多个服务时,每个服务的DNS名称都应解析为IP地址之一。 在服务之间共享IP地址。
- 使用轮询(round‑robin)DNS将单个DNS名称映射到多个IP地址
- 使用L3负载平衡设备(例如数据中心边缘负载平衡器)在IP地址之间分配L3流量。
Active‑active可用于增加负载均衡群集的容量,但请注意,如果一对active‑active对中的单个节点发生故障,则容量将减少一半。 可以使用active‑active作为一种安全形式,在节点间都处于主动状态时提供足够的资源来吸收意外的流量高峰,并且可以在较大的群集中使用active‑active提供更多的冗余。
请注意,负载平衡群集中的NGINX实例不共享配置或状态。 为了在active‑active方案中获得最佳性能,请确保将来自同一客户端的连接路由到相同的主动IP地址,并使用不依赖服务器端状态的会话持久性方法(例如sticky cookie)。
2.4.为其他被动(Passive)节点配置keepalived
要为现有的NGINX Plus active‑passive HA对配置其他被动(passive)节点,请执行以下步骤:
1.在新节点上安装nginx-plus和nginx-ha-keepalived软件包。
2.将/etc/keepalived/keepalived.conf从辅助节点复制到新节点上的相同位置。
3.在新节点上编辑keepalived.conf:
3.1.降低任何vrrp_instance块上的优先级(priority),使其低于其他节点。
3.2.更改unicast_src_ip以匹配新节点的主机IP地址。
3.3.将辅助节点的IP地址添加到unicast_peer部分,以便列出所有其他节点。
以下是IP地址为192.168.10.12的其他被动节点上的示例keepalived.conf。 其他两个节点的IP地址为192.168.10.10和192.168.10.11。 虚拟IP地址(VIP)为192.168.10.100。
vrrp_script chk_nginx_service {
script "/usr/lib/keepalived/nginx-ha-check"
interval 3
weight 50
}
vrrp_instance VI_1 {
interface eth0
state BACKUP
priority 99
virtual_router_id 51
advert_int 1
accept
unicast_src_ip 192.168.10.12
unicast_peer {
192.168.10.10
192.168.10.11
}
virtual_ipaddress {
192.168.10.100
}
track_script {
chk_nginx_service
}
notify "/usr/lib/keepalived/nginx-ha-notify"
}3.4.在其他节点上编辑keepalived.conf,将新的被动节点的IP地址添加到unicast_peer部分,以便列出所有其他节点:
unicast_peer {
192.168.10.11
192.168.10.12
}3.5.在所有节点上重新启动keepalived。
3.6.通过在前两个节点上停止NGINX Plus进行测试。
所有NGINX Plus节点必须具有相同的配置和SSL证书。 有关同步NGINX Plus配置的信息,请参阅在集群中同步NGINX配置。
2.5.为Active-Active HA配置keepalived
为了将流量同时引导到两个节点,必须使用附加的VIP。 这个新的VIP将在先前的被动节点上处于活动状态,因此每个节点都将使用其自己的VIP处于活动(active)状态。 要将现有的NGINX Plus HA对配置为active‑active,请执行以下步骤:
1.在辅助(secondary)节点上编辑keepalived.conf:
1.1.复制整个vrrp_instance block VI_1部分并将其粘贴到现有块下面
1.2.在复制的vrrp_instance部分中:
1.2.1.将新的vrrp_instance to VI_2或另一个唯一名称
1.2.2.将virtual_router_id更改为61或另一个唯一值
1.2.3.将virtual_ipaddress 更改为同一子网中的可用IP地址(在本示例中为192.168.10.101)
1.2.4.将priority值更改为100
vrrp_script chk_nginx_service {
script "/usr/lib/keepalived/nginx-ha-check"
interval 3
weight 50
}
vrrp_instance VI_1 {
interface eth0
state BACKUP
priority 101
virtual_router_id 51
advert_int 1
accept
unicast_src_ip 192.168.10.10
unicast_peer {
192.168.10.11
}
virtual_ipaddress {
192.168.10.100
}
track_script {
chk_nginx_service
}
notify "/usr/lib/keepalived/nginx-ha-notify"
}
vrrp_instance VI_2 {
interface eth0
state BACKUP
priority 100
virtual_router_id 61
advert_int 1
accept
unicast_src_ip 192.168.10.10
unicast_peer {
192.168.10.11
}
virtual_ipaddress {
192.168.10.101
}
track_script {
chk_nginx_service
}
notify "/usr/lib/keepalived/nginx-ha-notify"
}2.在主节点上编辑keepalived.conf:
2.1.重复在辅助节点上执行的编辑。
2.2.将新vrrp_instance中的priority设置为99或一个低于辅助节点上的优先级的值。
3.在所有节点上重新启动keepalived。
配置文件和 SSL 证书文件同步超出了本文档的范围,但请确保所有节点都具有相同的 NGINX Plus 配置。
2.6.为 Active-Active HA 配置 NGINX Plus
现在,两个NGINX Plus节点通过它们自己的VIP处于活动状态,必须配置NGINX Plus 本身。向活动节点分配流量有两种选择。选项1使所有节点都处于活动状态,每个节点至少处理一个应用程序。选项2使所有节点上的所有应用程序都处于活动状态。
注意:如果正在负载平衡的应用程序需要session持久性,我们建议使用sticky cookie、sticky route、IP hash的方法,因为它们可以在多个活动节点上正常运行。Sticky learn 在内存中创建一个不在活动节点之间共享的session表。
2.7.为每个节点上的不同应用程序配置 NGINX Plus
在此配置中,每个 NGINX Plus 节点仅处理对它具有活动 VIP 的server块的请求。 在发生故障转移时,活动节点是其他 VIP 的主要节点,并处理对相关server块的请求。
每个server 块都包含 listen指令以指定它正在侦听的 VIP。
基于上一节的 active‑active keepalived 配置,我们在这里使用相同的两个 VIP。 在此示例中,应用程序 1 在 NGINX Plus 节点 1 上处于活动状态,应用程序 2 在 NGINX 节点 2 上处于活动状态:
server {
listen 192.168.10.100:80;
location / {
root /application1;
}
}
server {
listen 192.168.10.101:80;
location / {
root /application2;
}
}2.8.为所有节点上的所有应用程序配置 NGINX Plus
在这种配置中,NGINX Plus 能够处理任何 VIP 上任何应用程序的流量。 如果节点发生故障,该节点的 VIP 将移动到具有下一个最高优先级的节点。 这样 DNS 负载平衡配置不需要更改。
每个 NGINX Plus 节点都会侦听所有请求。 DNS 负载均衡用于将请求分发到 NGINX Plus 节点。 简单的循环 DNS 就足够了,可以根据 DNS 服务器的文档进行配置。 确保每个具有相同完全限定域名 (FQDN) 的 VIP 都有一个 A。 每次解析名称时,DNS 服务器的响应都包括所有 VIP,但顺序不同。
server {
listen *:80;
location /app1 {
root /application1;
}
location /app2 {
root /application2;
}
}2.9.组合和扩展方法
在 Active-Active HA 配置 NGINX Plus 中的两种方法可以组合用于active-active-passive配置,甚至可以扩展到具有任意数量活动节点的配置。
2.10.在三个或更多节点上配置 All-Active HA
以下 keepalived 配置用于active-active-active配置。 这里只是对第三个重复了添加活动节点的步骤。 请注意,此节点对于一个 VIP 是活动的,对于一个 VIP 是次要的,对于一个 VIP 是第三个。
vrrp_script chk_nginx_service {
script "/usr/lib/keepalived/nginx-ha-check"
interval 3
weight 50
}
vrrp_instance VI_1 {
interface eth0
state BACKUP
priority 101
virtual_router_id 51
advert_int 1
accept
unicast_src_ip 192.168.10.10
unicast_peer {
192.168.10.11
192.168.10.12
192.168.10.13
}
virtual_ipaddress {
192.168.10.100
}
track_script {
chk_nginx_service
}
notify "/usr/lib/keepalived/nginx-ha-notify"
}
vrrp_instance VI_2 {
interface eth0
state BACKUP
priority 100
virtual_router_id 61
advert_int 1
accept
unicast_src_ip 192.168.10.10
unicast_peer {
192.168.10.11
192.168.10.12
192.168.10.13
}
virtual_ipaddress {
192.168.10.101
}
track_script {
chk_nginx_service
}
notify "/usr/lib/keepalived/nginx-ha-notify"
}
vrrp_instance VI_3 {
interface eth0
state BACKUP
priority 99
virtual_router_id 71
advert_int 1
accept
unicast_src_ip 192.168.10.10
unicast_peer {
192.168.10.11
192.168.10.12
192.168.10.13
}
virtual_ipaddress {
192.168.10.102
}
track_script {
chk_nginx_service
}
notify "/usr/lib/keepalived/nginx-ha-notify"
}2.11.配置 Active-Active-Passive HA
此示例 keepalived 配置适用于active-active-passive配置中的被动节点。 它结合了为附加被动节点配置 keepalived 和为 Active-Active HA 配置 keepalived 中的步骤。
vrrp_script chk_nginx_service {
script "/usr/lib/keepalived/nginx-ha-check"
interval 3
weight 50
}
vrrp_instance VI_1 {
interface eth0
state BACKUP
priority 99
virtual_router_id 51
advert_int 1
accept
unicast_src_ip 192.168.10.12
unicast_peer {
192.168.10.10
192.168.10.11
}
virtual_ipaddress {
192.168.10.100
}
track_script {
chk_nginx_service
}
notify "/usr/lib/keepalived/nginx-ha-notify"
}
vrrp_instance VI_2 {
interface eth0
state BACKUP
priority 99
virtual_router_id 61
advert_int 1
accept
unicast_src_ip 192.168.10.12
unicast_peer {
192.168.10.10
192.168.10.11
}
virtual_ipaddress {
192.168.10.101
}
track_script {
chk_nginx_service
}
notify "/usr/lib/keepalived/nginx-ha-notify"
}3.在集群中同步 NGINX 配置
3.1.概述
NGINX Plus 通常部署在由两个或更多设备组成的高可用性 (HA) 集群中。 配置共享功能,能够将配置从集群中的一台机器(主)推送到其对等机器:
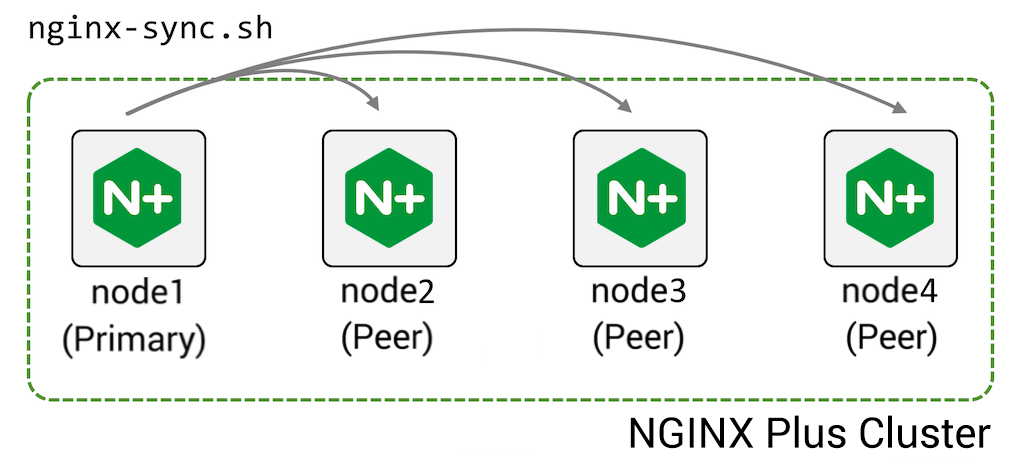
要配置此功能:
- 在主机上安装 nginx-sync 包
- 以 root 身份授予主机 ssh 访问对等机器的权限
- 在主机上创建配置文件/etc/nginx-sync.conf:
-
NODES="node2.example.com node3.example.com node4.example.com" CONFPATHS="/etc/nginx/nginx.conf /etc/nginx/conf.d" EXCLUDE="default.conf"
-
- 在主节点上运行
nginx-sync.sh命令,将CONFPATHS中的配置文件名称推送到指定的NODES,省略EXCLUDE中命名的配置文件。
nginx-sync.sh 包括许多安全检查:
- 在继续之前验证系统先决条件
- 验证本地(主要)配置(
nginx -t)并在失败时退出 - 在每个对等点上创建配置的远程备份
- 使用
rsync将主要配置推送到对等节点,验证对等节点上的配置(nginx -t),如果成功则在对等节点上重新加载 NGINX Plus(service nginx reloa) - 如果任何步骤失败,则回滚到对等体上的备份
3.2.说明
3.2.1.在主机器上安装 nginx-sync
对于 RHEL 或 CentOS:
$ sudo yum install nginx-sync对于 Ubuntu 或 Debian:
$ sudo apt-get install nginx-sync3.2.2.配置对等方的 root SSH 访问
此过程使主节点上的 root 用户能够通过 ssh 连接到每个对等节点上的 root 帐户,这需要将文件 rsync 同步到对等节点并在对等节点上运行命令以验证配置、重新加载 NGINX Plus 等。
- 在主节点上,为root生成一个SSH认证密钥对,查看密钥的公开部分:
-
$ sudo ssh-keygen -t rsa -b 2048 $ sudo cat /root/.ssh/id_rsa.pub ssh-rsa AAAAB3Nz4rFgt...vgaD root@node1
-
- 获取主节点的 IP 地址(以下示例中为 192.168.1.2):
-
$ ip addr 1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0: mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 link/ether 52:54:00:34:6c:35 brd ff:ff:ff:ff:ff:ff inet 192.168.1.2/24 brd 192.168.1.255 scope global eth0 valid_lft forever preferred_lft forever inet6 fe80::5054:ff:fe34:6c35/64 scope link valid_lft forever preferred_lft forever
-
- 在每个对等节点上,将公钥附加到 root 的 authorized_keys文件中。from=192.168.1.2 前缀限制只能访问主节点的 IP 地址:
-
$ sudo mkdir /root/.ssh $ sudo echo ‘from=”192.168.1.2" ssh-rsa AAAAB3Nz4rFgt...vgaD root@node1' >> /root/.ssh/authorized_keys
-
- 将以下行添加到 /etc/ssh/sshd_config:
-
PermitRootLogin without-password
-
- 在每个对等点(但不是主要)上重新加载 sshd 以允许 SSH 密钥身份验证:
-
$ sudo service ssh reload
-
- 验证 root 用户可以在不提供密码的情况下通过 ssh 连接到每个其他节点:
-
$ sudo ssh root@node2.example.com <hostname>
-
3.2.3.在主节点上创建 nginx-sync.conf 配置文件
在主节点上,使用以下内容创建文件 /etc/nginx-sync.conf:
NODES="node2.example.com node3.example.com node4.example.com"
CONFPATHS="/etc/nginx/nginx.conf /etc/nginx/conf.d"
EXCLUDE="default.conf"3.2.4.常用参数
使用空格或换行符分隔每个列表中的项目:
- NODES – 从主节点接收配置的对等节点列表
- CONFPATHS – 要从主节点分发到对等节点的文件和目录列表
- EXCLUDE –(可选)主节点上不分发给对等节点的配置文件列表
3.2.5.高级参数
- BACKUPDIR – 每个对等点上的备份位置(默认 /var/lib/nginx-sync)
- DIFF –
diff二进制文件的位置(默认/usr/bin/diff) - LOCKFILE – 用于确保一次仅运行一个
nginx-sync操作的锁定文件的位置(默认为 /tmp/nginx-sync.lock) - NGINX – nginx-plus 二进制文件的位置(默认 /usr/sbin/nginx)
- POSTSYNC – 要在每个远程节点上进行的以空格分隔的文件替换列表,格式为“
<filename>|<sed-expression>”。 替换适用于:
sed -i'' <sed-expression> <filename>例如,该命令将keepalived.conf中node2.example.com的IP地址(192.168.2.2) 替换为node1.example.com的IP地址 (192.168.2.1):
POSTSYNC="/etc/keepalived/keepalived.conf|'s/192\.168\.2\.1/192.168.2.2/'"- RSYNC –
rsync二进制文件的位置(默认 /usr/bin/rsync) - SSH –
ssh二进制文件的位置(默认为/usr/bin/ssh)
3.2.6.测试配置
测试前备份配置。
- 同步配置并在对等节点上重新加载 NGINX Plus –
nginx-sync.sh - 显示使用信息 –
nginx-sync.sh -h - 比较主节点和节点之间的配置 –
nginx-sync.sh -c <peer-node> - 将主节点上的配置与所有节点进行比较 –
nginx-sync.sh -C
3.3.经常遇到的问题
3.3.1.为什么我需要向 root 授予 SSH 访问权限?
主节点需要能够以root用户的身份在对等机上远程运行命令(例如,service nginx reload),并且需要能够更新root拥有的配置文件(例如,in/etc/nginx/)。
授予 root 用户 SSH 访问权限似乎是放弃了太多权限,但重要的是要记住,任何可以编写远程 NGINX Plus 配置并重新加载远程 NGINX Plus 进程的进程都可以破坏该进程,从而获得对服务器的远程root访问权。
因此,假设在主节点上获得 root 访问权限的用户在对等节点上也具有 root 访问权限。
3.3.2.主节点故障如何同步配置?
如果主节点出现故障并且不会很快恢复服务,则需要按照安装中的说明将对等节点升级为主节点。这包括
预先配置多台机器作为主节点运行,但必须确保在给定时间实际上只有一个节点作为主节点运行。
3.3.3.如果对等节点发生故障会发生什么?
如果对等节点出现故障,则它不再接收配置更新。 nginx-sync.sh 脚本会返回错误,但会继续将配置分发给其余对等方。
当节点恢复时,其配置已过期。通过运行 nginx-sync.sh -c <recovered-peer-node> -d 来显示配置差异:
$ nginx-sync.sh -c node2.example.com -d
...
diff -ru /tmp/localconf.1XrIqP7f/etc/nginx/conf.d/responder.conf /tmp/remoteconf.Xq5LWGKU/etc/nginx/conf.d/responder.conf
--- /tmp/localconf.1XrIqP7f/etc/nginx/conf.d/responder.conf 2020-09-25 10:29:36.988064021 -0800
+++ /tmp/remoteconf.Xq5LWGKU/etc/nginx/conf.d/responder.conf 2020-09-25 10:28:39.764066539 -0800
@@ -4,6 +4,6 @@
listen 80;
location / {
- return 200 "Received request on $server_addr on host $hostname blue\n";
+ return 200 "Received request on $server_addr on host $hostname red\n";
}
}
* Synchronization ended at Fri Sep 25 18:30:49 UTC 2020下次运行 nginx-sync.sh 时,节点将使用当前的主要配置进行更新。
3.4.群集中的运行时状态共享
本章介绍如何使用 NGINX Plus 在 NGINX 集群节点之间同步共享内存区域,包括粘性学习会话持久性(sticky learn session persistenc)、请求限制和键值存储数据。
3.4.1.说明
如果多个 NGINX Plus 实例组织在一个集群中,它们可以在它们之间共享一些状态数据,包括:
所有 NGINX Plus 实例都可以与集群中的所有其他成员交换状态数据,前提是共享内存区域在所有集群成员上具有相同的名称。
3.4.2.先决条件
- NGINX Plus R16 用于跨集群共享请求处理和键值数据的限制
- NGINX Plus R15 用于跨集群共享粘性学习数据的限制
3.4.3.配置区域同步
对于集群中的每个 NGINX 实例,打开 NGINX 配置文件并执行以下步骤:
1.启用集群节点之间的同步:在顶级stream {}块中,使用 zone_sync 指令创建server {}:
stream {
#...
server {
zone_sync;
#...
}
}2.使用 zone_sync_server指令指定集群中的所有其他 NGINX 实例。 如果使用解析器(resolver),可以使用 DNS 服务动态添加集群节点:
stream {
resolver 10.0.0.53 valid=20s;
server {
zone_sync;
zone_sync_server nginx-cluster.example.com:9000 resolve;
}
}否则,每个集群节点都可以静态添加为 zone_sync_server 指令的单独行:
stream {
server {
zone_sync;
zone_sync_server nginx-node1.example.com:9000;
zone_sync_server nginx-node2.example.com:9000;
zone_sync_server nginx-node3.example.com:9000;
}
} 3.通过为 TCP 服务器指定listen 指令的 ssl 参数来启用 SSL:
stream {
resolver 10.0.0.53 valid=20s;
server {
listen 10.0.0.1:9000 ssl;
#...
zone_sync;
zone_sync_server nginx-cluster.example.com:9000 resolve;
#...
}
}4.使用 ssl_certificate 指令指定证书的路径,使用 ssl_certificate_key 指令指定私钥的路径。 证书和密钥都必须采用 PEM 格式:
stream {
resolver 10.0.0.53 valid=20s;
server {
listen 10.0.0.1:9000 ssl;
ssl_certificate_key /etc/ssl/nginx-1.example.com.key.pem;
ssl_certificate /etc/ssl/nginx-1.example.com.server_cert.pem;
zone_sync;
zone_sync_server nginx-cluster.example.com:9000 resolve;
#...
}
}5.使用 zone_sync_ssl 指令启用集群服务器之间的 SSL 连接:
stream {
resolver 10.0.0.53 valid=20s;
server {
listen 10.0.0.1:9000 ssl;
ssl_certificate_key /etc/ssl/nginx-1.example.com.key.pem;
ssl_certificate /etc/ssl/nginx-1.example.com.server_cert.pem;
zone_sync;
zone_sync_server nginx-cluster.example.com:9000 resolve;
zone_sync_ssl;
#...
}
}6.使用 zone_sync_ssl_certificate 和 zone_sync_ssl_certificate_key 指令在另一个集群服务器上启用 SSL 证书身份验证:
stream {
resolver 10.0.0.53 valid=20s;
server {
listen 10.0.0.1:9000 ssl;
ssl_certificate_key /etc/ssl/nginx-1.example.com.key.pem;
ssl_certificate /etc/ssl/nginx-1.example.com.server_cert.pem;
zone_sync;
zone_sync_server nginx-cluster.example.com:9000 resolve;
zone_sync_ssl;
zone_sync_ssl_certificate localhost.crt;
zone_sync_ssl_certificate_key localhost.key;
#...
}
}此外,使用 zone_sync_ssl_verify, zone_sync_ssl_verify_depth, zone_sync_ssl_trusted_certificate 启用另一个集群服务器证书的验证:
stream {
resolver 10.0.0.53 valid=20s;
server {
listen 10.0.0.1:9000 ssl;
ssl_certificate_key /etc/ssl/nginx-1.example.com.key.pem;
ssl_certificate /etc/ssl/nginx-1.example.com.server_cert.pem;
zone_sync;
zone_sync_server nginx-cluster.example.com:9000 resolve;
zone_sync_ssl;
zone_sync_ssl_certificate localhost.crt;
zone_sync_ssl_certificate_key localhost.key;
zone_sync_ssl_verify on;
zone_sync_ssl_verify_depth 2;
zone_sync_ssl_trusted_certificate /etc/ssl/ca_chain.crt.pem;
}
}3.5.同步微调
通常,不必调整同步选项,但在某些情况下,调整其中一些值会很有用:
#...
zone_sync;
zone_sync_server nginx-cluster.example.com:9000 resolve;
zone_sync_buffers 256 4k;
zone_sync_connect_retry_interval 1s;
zone_sync_connect_timeout 5s;
zone_sync_interval 1s;
zone_sync_timeout 5s;
#...zone_sync_buffers控制缓冲区的数量及其大小。 增加缓冲区的数量将增加其中存储的信息数量。zone_sync_connect_retry_interval设置与集群节点的连接尝试之间的超时时间。zone_sync_connect_timeout设置连接到集群节点所需的时间。zone_sync_interval在共享内存区域中设置轮询更新的间隔。 增大该值可能会导致cpu和内存资源的高消耗,减小该值可能导致集群节点之间的数据不一致。zone_sync_timeout设置集群节点之间 TCP 流的生命周期。 如果 TCP 流空闲时间超过该值,则连接将关闭。
3.6.管理集群节点
3.6.1.启动节点
要启动一个新节点:
- 在 DNS 的情况下,使用新节点的 IP 地址更新集群主机名的 DNS 记录并启动一个实例
- 在静态添加节点的情况下,将节点地址添加到 nginx 配置文件并重新加载所有其他节点
当节点启动时,它会从 DNS 或静态配置中发现其他节点并开始发送更新。 其他节点最终使用 DNS 发现新节点并开始向其推送更新。
3.6.2.停止节点
要停止节点,请发送“QUIT”信号:
nginx -s quit一旦节点收到信号,它就会完成区域同步并优雅地关闭打开的连接。
3.6.3.删除节点
删除节点:
- 如果是 DNS,请更新集群主机名(hostname)的 DNS 记录并删除节点的 IP 地址
- 如果是静态添加的节点,请从每个节点的 nginx 配置文件中删除该节点的地址并重新加载每个节点。
当节点被移除时,其他节点会关闭与被移除节点的连接,并且将不再尝试连接到它。 删除节点后,可以将其停止。
3.7.在集群中使用同步
3.7.1.粘性学习区同步
如果现有的配置已经使用了粘性学习功能,则可以将同步参数添加到集群中每个 NGINX 实例的配置文件中现有sticky指令来简单地跨集群共享现有状态。 请注意,集群中所有其他 NGINX 节点的区域名称必须相同:
upstream my_backend {
zone my_backend 64k;
server backends.example.com resolve;
sticky learn zone=sessions:1m
create=$upstream_cookie_session
lookup=$cookie_session
sync;
}
server {
listen 80;
location / {
proxy_pass http://my_backend;
}
}3.7.2.请求限制区域同步
如果现有的配置已经使用了速率限制,则可以简单地将sync参数添加到集群中每个 NGINX 实例的配置文件中 limit_req_zone 指令来跨集群应用这些限制:
limit_req_zone $remote_addr zone=req:1M rate=100r/s sync;
server {
listen 80;
location / {
limit_req zone=req;
proxy_pass http://my_backend;
}
}集群中所有其他 NGINX 节点中的区域名称也必须相同。
3.7.3.键值存储区同步
类似于速率限制和粘性学习,键值共享内存区域的内容可以通过 keyval_zone 指令的sync参数在集群中的 NGINX 机器之间共享:
keyval_zone zone=one:32k state=/var/lib/nginx/state/one.keyval sync;
keyval $arg_text $text zone=one;
#...
server {
#...
location / {
return 200 $text;
}
location /api {
api write=on;
}
}3.8.监控集群状态
可以使用 NGINX Plus API 指标监控集群状态数据:
- 共享内存区域的名称
- 节点上的记录总数
- 需要发送的记录数
- 集群中每个节点的同步状态
3.9.配置 API
为了访问 API 指标,需要配置 API:
1.使用 api 指令以读写模式启用 NGINX Plus API:
# ...
server {
listen 80;
server_name www.example.com;
location /api {
api write=on;
}
}2.强烈建议限制对该位置的访问,例如仅允许从 localhost (127.0.0.1) 访问,并限制某些具有 HTTP 基本身份验证的用户访问 PATCH, POST 和 DELETE 方法:
# ...
server {
listen 80;
server_name www.example.com;
location /api {
limit_except GET {
auth_basic "NGINX Plus API";
auth_basic_user_file /path/to/passwd/file;
}
api write=on;
allow 127.0.0.1;
deny all;
}
}3.10.使用 API 轮询同步状态
获取共享内存区的同步状态,发送API命令,例如使用curl:
$ curl -s '127.0.0.1/api/6/stream/zone_sync' | jq输出将是:
{
"zones" : {
"zone1" : {
"records_pending" : 2061,
"records_total" : 260575
},
"zone2" : {
"records_pending" : 0,
"records_total" : 14749
}
},
"status" : {
"bytes_in" : 1364923761,
"msgs_in" : 337236,
"msgs_out" : 346717,
"bytes_out" : 1402765472,
"nodes_online" : 15
}
} 如果所有节点具有大致相同的记录数 (records_total) 和几乎为空的传出队列(records_pending),则可以认为集群是健康的。
4.NGINX Plus 如何执行区域同步
4.1.介绍
4.1.1.用例
鉴于该功能的特定功能,即
- 单独处理每个节点上的请求,无需咨询其他节点
- 更改的最终交付
- 过期记录
考虑以下用例:
- 会话缓存(Session caching):第一个请求创建一个与其他节点共享的会话。 后续请求在任何集群节点上使用相同的会话。 节点上缺少会话更多的是性能损失,而不是致命错误。
- 资源限制(Resource limiting):每个节点评估本地资源并通知其他节点。 平均而言,适当地施加了集群限制。
- 动态配置(Dynamic configuration):动态配置条目(例如,临时重定向规则、访问规则和限制)在一个节点上输入后自动在集群内共享。 一旦其他节点收到它们,就会应用新规则。
4.2.模块
该功能很复杂,它的支持分为 nginx core、ngx_stream_zone_sync_module 模块和实际使用共享区域的模块(例如,sticky或 limit_req 模块;这里,我们将此类模块称为功能(functional)模块)。
在这里,区域同步模块负责:
- 所有与网络相关的功能,包括
- 集群节点发现
- 管理与集群节点的网络连接
- 提供传输层安全性(使用
ssl模块) - 将功能模块提供的数据推送到远程节点
- 接收来自远程节点的数据并将其分发给功能模块
- 跟踪区域的变化并处理区域的输出队列
在服务器端,区域同步模块是一个常规的流模块,因此支持访问控制、传输层安全和限制。
功能模块负责:
- 序列化区域记录,以便它们可以与密钥和时间戳元数据一起通过网络发送
- 反序列化消息并使用远程数据更新本地区域
- 维护在本地更新且必须在集群内分发的记录队列
核心提供区域同步模块和功能模块之间的必要接口。
4.3.同步
4.3.1.数据模型
每个功能模块将其数据表示为记录队列。 记录对于区域同步模块是不透明的; 它只处理记录的序列化表示,同时将它们发送到其他节点。 队列包含需要发送到集群的记录。 只有在节点上本地创建的记录才可能出现在输出队列中。 队列是侵入性的,可能包括存储在一个区域中的所有记录。
区域同步模块以固定的时间间隔轮询配置区域的输出队列,控制集群的不一致窗口有多大。 此外,它允许在频繁更新单个记录的情况下减少传输的数据量(会话的典型用例,创建会话并随后多次更新)。
可以创建或更新同步记录。 目前不支持删除操作; 相反,每个记录都有一个配置定义的生命周期。 当一条记录过期时,它会在本地被删除,并且不会向集群发送更新。
功能模块控制是否在访问/更新时延长记录寿命。
数据最终会变得一致:当更新的值在集群节点之间发生变化时,总会有一个时间跨度。 通过调整区域同步间隔可以减少(但不能消除)跨度。 根据 CAP 定理,区域同步集群可以归类为 AP 系统。
一致性的保证是每个节点最终都会接收到集群中按时间戳排序的所有事件,使用通用算法处理它们,并到达与其他节点相同的状态。
显然,该算法取决于所有集群节点的适当时间同步,因此在所有节点上设置 NTP 或类似技术非常重要。
4.3.2.数据流
- 功能模块创建新记录(例如新的粘性会话)
- 记录插入输出队列
- 功能模块可以继续其正常操作。 因此,记录可以在与其他节点共享之前多次更新甚至删除(例如,在直接请求后在节点本地)。
- 周期性定时器触发,区域同步模块检查功能模块的输出队列。
- 如果队列不为空,则区域同步模块要求功能模块将传出记录序列化并将它们写入自己的缓冲区。
- 功能模块使用自己的序列化格式序列化一条记录。 通常,它包括密钥、时间戳和有效负载。
- 区域同步模块消耗输出队列,直到没有可用的缓冲区空间或队列为空。
- 区域同步模块将它读取的所有信息发送到已与其建立连接的节点,将记录构建为包含区域名称和版本详细信息的消息。 如果发生错误并且无法将记录传递到节点,则关闭与节点的连接以重新建立。 请参阅下面对集群部分初始状态的说明。
- 远程节点接收消息并将其分派到适当的功能模块和区域。 功能模块现在必须使用来自远程节点的信息(密钥、时间戳和有效载荷)通过以下方式刷新其本地状态:
- 如果不存在这样的键,则在键处插入新记录
- 如果远程时间戳较新,则更新现有记录
- 如果本地时间戳较新,则忽略更新
- 该功能模块能够将区域状态序列化到磁盘(即启用“state”的 keyval)保存记录时间戳,以确保在服务器重启后正确处理记录生命周期。
4.4.介绍
4.4.1.拓扑
在拓扑上,集群是一个全网格,其中每个节点都连接到所有其他节点,任何更改都会推送到其他节点。
所有集群节点都是平等的。 没有特殊的中心节点或主节点; 每个节点处理请求而不等待其他节点。
节点提交对本地内存的任何更改并继续处理请求。 其他节点最终会收到有关本地更改的通知。
一个节点不知道它的本地值是否是“最好的/最新的”; 它依赖于它们,直到应用来自其他节点的更新。
一个节点侦听来自其他节点的更改并在它们到达时应用它们。
4.4.2.初始状态
当一个节点连接到集群时,它已经有一个状态,并且不知道这个状态的任何部分之前是否被发送到集群。 最终的解决方案是将整个节点状态与集群合并。 这个过程称为快照:当与新节点建立网络连接时,集群和节点交换快照。 选择最新版本的记录来形成新的联合状态。 此过程与常规操作并行运行,因此节点无需等到快照结束。
集群大脑分裂后会发生相同的过程:新节点出现在集群中并与对等方交换其当前状态。 如果状态很大并且集群中有很多节点,同步可能需要一些时间并引入额外的零星系统负载。
当一个节点下线时,它会暂时影响其他节点:从区域读取的下一个数据延迟到写入超时到期,或者检测到连接写入错误,并且故障节点断开连接。 然后,在其余节点之间继续同步,直到重新建立与离线节点的连接。
4.4.3.线格式
该模块使用一组为每个节点连接预先分配的缓冲区来传递更改。 缓冲区包含消息头和序列化记录。 消息头包含:
- 完整的消息长度,包括其有效载荷(payload)
- 协议版本(目前为 1)
- 区域名称长度
- 模块标签 - 唯一的模块 ID
- 模块版本
- 目标区域名称
固定长度的头部分的大小是 12 个字节。 要成功发送消息,签名(模块标签和版本)必须与目标匹配。 带有未知签名的消息将被忽略(例如,向另一个节点添加新区域可以产生这样的消息)。 序列化记录的长度取决于具体的功能模块; 例如,sticky 模块会生成一个 21 字节的固定长度标头和一个最多 32 字节的会话 ID。 如果单个序列化记录太大而无法放入缓冲区,则会记录错误并在同步期间忽略该记录。 这也表明应该增加缓冲区大小。
4.4.4.监控
访问日志的标准功能允许观察与其他集群节点的流会话并记录支持的变量,例如 $remote_addr, $status, $upstream_bytes_sent, $bytes_received。 错误日志注册带有各种事件详细信息的 NOTICE 级别条目:节点发现、节点连接、接受的客户端等。 在适当的级别报告发生的错误。
区域同步模块通过 API 模块导出多个计数器:stream/zone_sync 端点包括具有每个实例信息的status 端点; zones/ 端点列出每个区域的统计信息。
节点在线指标显示与其他节点建立的连接数。 通常,它应该等于 N 减 1,其中 N 是所有集群节点的数量。
此外,端点包含入站和出站消息和字节的累积计数器。
每个区域的统计信息包括共享内存区域中的记录总数和输出队列中的记录数。
4.4.5.缩放比例
请注意,通过同步,您的节点开始从其他节点接收多个更新,这通常需要锁定一定数量的共享内存以插入/更新记录。
对于许多工作和节点,这可能会成为瓶颈。 如果事件数量较多,则消耗的网络带宽和 CPU 使用率会相应增加。
4.5.FAQ
1.当一个节点与集群隔离时会发生什么?
当一个节点与集群隔离时,它继续作为单个节点运行:即它在本地管理会话并继续响应客户端,同时不断尝试连接到其他节点。
2.当孤立节点重新连接到集群时会发生什么?
当一个节点重新连接时,它执行完全重新同步:它将所有本地会话发送到集群,并依次从其他节点接收数据。因此,当所有节点连接时,它们最终会达到一致状态。
3.如果多个节点同步相同的数据,如何解决冲突?
冲突解决基于时间,因此在集群中同步时钟至关重要。 如果两个节点使用相同的键创建了一条记录,则最新的记录获胜。
4.是否有集群同步数据的状态文件?
不需要。集群同步数据在集群之间共享,因此无需将其写出到磁盘。 keyval 模块能够将本地节点状态保存到磁盘。
5.NGINX Plus 可以配置为在同步完成之前拒绝连接吗?
不,因为没有这样的状态。 每个节点只接收来自其他节点的更新流并将自己的更新发送给其他节点。 如果没有新数据到达集群,所有节点都会有一个空的积压队列,这可以算作“完全同步”,但实际上这种情况通常不会遇到:总是有客户端。
6.如何故意让节点离线?
该文档描述了如何控制集群节点。
7.我们如何监控集群状态数据?
NGINX Plus API 中的每个同步区域都有 2 个可用的计数器:节点上的记录总数,以及需要发送的记录数。 如果所有节点的记录数量大致相同,并且传出队列几乎为空,我们可以认为集群是健康的。
8.我们如何监控集群健康状况?
NGINX Plus API 还公开了 2 个进一步的指标:
- 连接节点数:这预计在所有节点上都相等,并且等于集群中的节点总数减一。 也就是说,您可以监控集群连接:如果某些节点死机/断开连接,此计数器将更改
- 发送队列的长度:理想情况下,这是零(低负载)或某个常数(平均负载)。 如果积压工作不断增加而您没有进行更改(即向集群添加或删除节点),则表明存在问题(网络连接问题、死节点等)
- 监视错误日志:记录所有相关事件。 默认情况下,只记录错误。 可以在 INFO 级别查看更多集群事件。
4.6.历史
在 NGINX Plus R15 中,引入了在实例之间同步内存区域的能力; 目前仅支持带有学习方法的粘性会话。
在 NGINX Plus R16 中,共享区域同步被扩展为支持 keyval 和 limit_req 模块。
在 NGINX Plus R18 中,可以使用 listen 指令中的通配符在集群中的所有实例之间应用单个 zone_sync 配置。
















 145
145











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











