









k8s入门
这个博客主要介绍k8s的详细网站,下一个博客,将用案例进行演示
安装
mac上安装,https://blog.csdn.net/adson1987/article/details/106337079,其他操作系统网上也有其他步骤
还可以通过systemctl进行自动重启
k8s架构
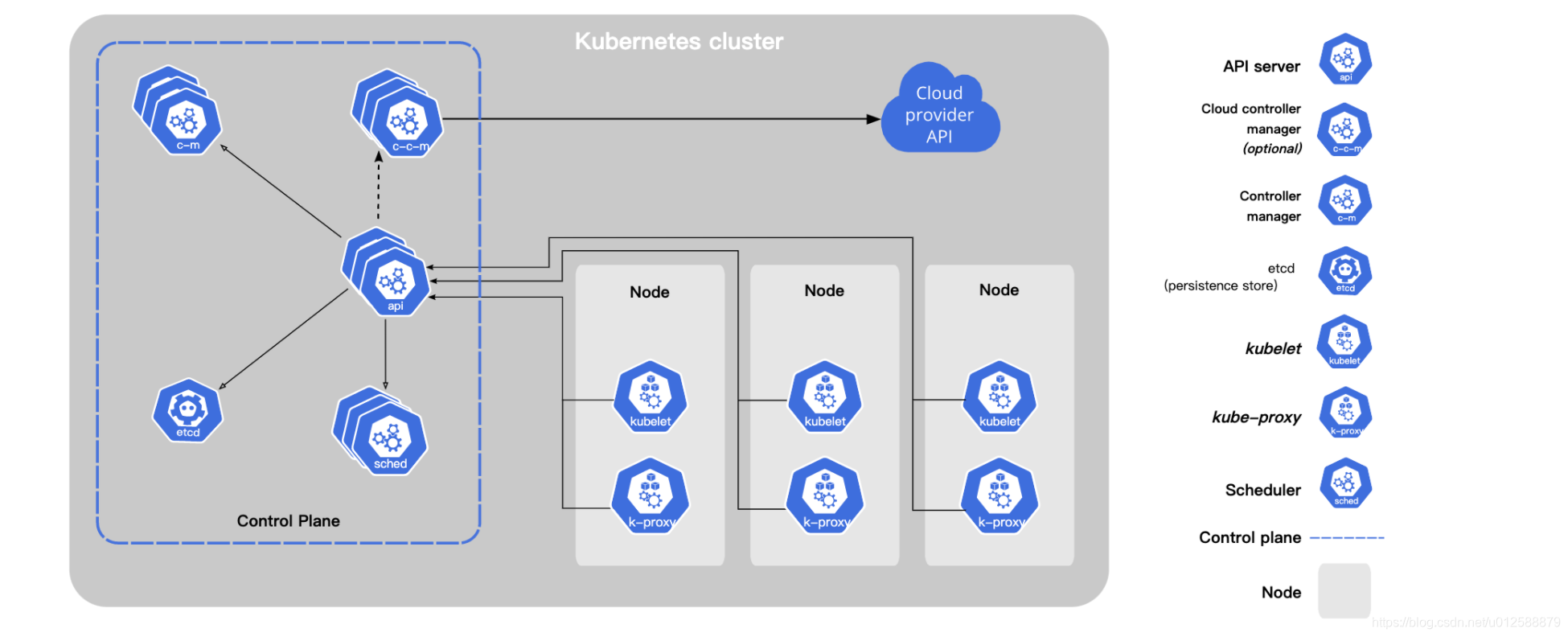
架构图如下图所示,详细的各种模块的概念见博客:https://www.cnblogs.com/linuxk/p/10291178.html
核心组件比较常见的是kubelet , pod, node, master等,kubenet是在每个node节点创建pod等操作,并向master报告状态
master上是controll pane,比如sched,就是调度器,通过向各个node调度进行控制,而每个nod上就是kubelete来进行对容器进行操作
master上的组件为
-
scheduler,整体调度器,为创建的pod 选择node
-
etcd ,存储cluster上所有数据
-
Controler manage ,控制器,监控和反馈nodes的信息,比如挂啦,啥的,还有维持pod的数量
-
api server,提供k8s所有增删改查的restful api接口
node上的组件为
-
kubelet 是每个node上的代理,保证node上pod的健康性
-
Kube-proxy,k8s service的实现,实现了转发等功能
-

k8s作用
K8s不是容器,而是管理、编排容器,尤其是在现在微服务的时代,管理多个容器是有必要的
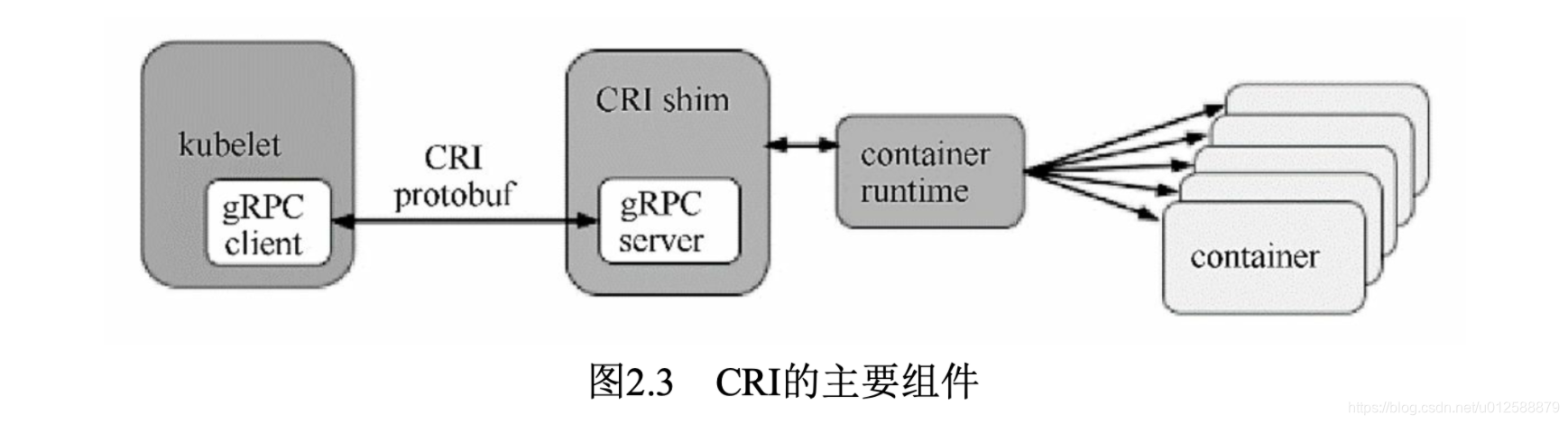
而容器有多种,不止docker一种,因此需要一些抽奖的接口,对底层进行抽象,这就有了CRI,CRI是kubelet和pod(或者可以精确到container)之间进行通信或者管理(比如启动、停止能力)的接口定义,然后具体容器,比如docker,rkt容器都实现了接口,那么就可以通过相同grpc接口进行请求操作,当然,中间可能并非直接请求到pod,可能有个CRI shim代理
重要组件讲解
od
pod是k8s最小调度单位,里面有多个容器,每个容器就是docker等容器
具体的各个参数配置可以去官网查或者百度,在此不一一列举了
pod生命周期
-
pending 正在创建
-
Running 启动状态
-
Succeeded 所有容器都启动成功
-
Ready 可以接受请求
-
Failed 至少一个容器退出失败
-
Unknown 因为网络等原因无法知道状态
pod状态
-
PodScheduled: the Pod has been scheduled to a node. -
ContainersReady: all containers in the Pod are ready. -
Initialized: all init containers have started successfully. -
Ready: the Pod is able to serve requests and should be added to the load balancing pools of all matching Services.
pod生命周期和状态不是一个意思,前者是pod的PodStatus的phase变量,后者是podstauts的pod conditions数组,前者是一个个阶段,后者是状态,但是也可以一一对应
pod健康检查
两类探针
-
livenessProbe 存活指针,判断pod是否是是running状态,如果不健康,则kubelet将杀掉该容器,并根据容器的重启策略做相应从策略
-
readinessProbe 判断pod是否可用指针,判断是否可用,只有ready状态才能接受请求, 对于被service管理的pod,不为ready状态,service对应的endpoint list将移除该pod,避免服务被转发到不可用的pod上
执行探针的方式
-
execAction 通过给容器发送命令判断返回值来判断健康状态
-
tcp socket action, 通过ip和端口号是否能建立tcp连接判断健康状态
-
http get action, 通过配置端口和url发送http请求通过状态码来判断
调度器
pod只是k8s的最小单元,需要进行控制,比如创建,销毁,重启等,而在k8s中,由控制器进行操作,最常见的控制器是Deployment,之前是Deployment,也有其他的一些控制器,比如NodeSelector、Job、CronJob等
-
Deployment
Deployment前身是Replication controller,顾名思义就是controller, rc最后演变为replica set,这个演变最大特点是知道部署的进度,而Deployment在内部使用了rs,侧面说明Deployment还有其他隐藏的功能
Deployment是系统全自动调度,也就是pod的副本的部署(比如部署在哪个节点上)都是由master节点的Scheuler来控制调度
-
NodeSelector
定向调度,通过label标签匹配节点,比如os, host等,部署到具体的节点
-
NodeAfinity, PodAfinity
NodeAfinity可以看做是NodeSelector的升级版,通过满足一组条件而不只是匹配,比如IN, not In, exists等来匹配节点
而PodAfinity则是将要调度的pod部署到通过条件匹配到pod所在的节点上
-
Taints和Tolerations
前面介绍的NodeAffinity节点亲和性,是在Pod上定义的一种属性, 使得Pod能够被调度到某些Node上运行(优先选择或强制要求)。Taint 则正好相反,它让Node拒绝Pod的运行。
Taint需要和Toleration配合使用,让Pod避开那些不合适的Node。在 Node上设置一个或多个Taint之后,除非Pod明确声明能够容忍这些污 点,否则无法在这些Node上运行。Toleration是Pod的属性,让Pod能够 (注意,只是能够,而非必须)运行在标注了Taint的Node上。
-
pod priority preemption
优先级抢占,资源不足情况下,高优先级的部署,低优先级的pod被释放
-
DaemonSet
每个node部署一个pod
-
job和 cron job
job是一次性执行完的任务,cron job是定时执行任务,这个跟微服务中的任务有点类似,只不过这两种job是容器层面的
Deployment
Deployment是比较常用的调度器
kubectl describe deployments/具体deployment 命令仔 细观察Deployment的更新
kubectl edit可以编辑deployment
rollout pause命令可以暂停deployment更新,因为可能还没改完,想改完之后再启用
再rollout resume
升级
比如重新部署,也就是image会换,这时候有两个策略
-
recreate 删除正在所有正在运行的pod,再重新部署最新的
-
rollingUpdate 灰度发布,最终达到部署最新的,批量杀掉pod
也可以通过rolling update命令动态进行滚动升级
回滚
rollout history查看deploy版本
rollout undo 进行回滚,具体参考kubunete权威指南
扩容
-
手动扩容,根据scale命令进行扩容平
-
自动扩容,HPA控制器根据cpu利用率等指标进行扩容
Service
service可以看做是所有pod的一个抽象,用于负载均衡,项目可以直接通过请求service,由k8s来自己做负载均衡,不过有的项目是自己来做负载均衡,并未真正使用到service
service还可以配置通过端口,转发到不同的服务
service负载均衡
-
RoundRobin:轮询模式,即轮询将请求转发到后端的各个Pod 上。
-
SessionAffinity:基于客户端IP地址进行会话保持的模式,即第 1次将某个客户端发起的请求转发到后端的某个Pod上,之后从相同的客 户端发起的请求都将被转发到后端相同的Pod上。
Ingress
ingress提供http功能,将请求转发到不同的service或者pod














 1474
1474











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









