







简单图片爬虫过程:
一.将链接url源码读出,将其作为列表输出
二.使用正则表达式将源码中有关图片的源码筛选出来,(*.jpg文件)
三.在输出的过程中按照自己的方式命名
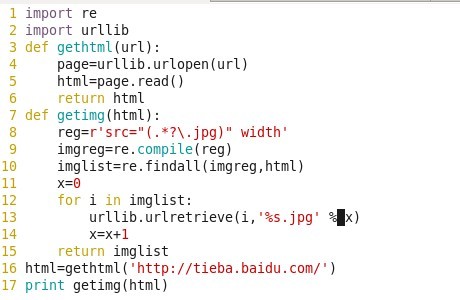
这里边唯一的难点恐怕是正则表达式的书写,下面我们初步系统的讲解一下正则表达式:
前面有一讲专门介绍了正则表达式, 具体可以查看链接,这里只进行一些重要的补充。
\b:
正则表达式元字符。\b只匹配一个位置,并不匹配空格、标点符号/换行符中的一个,这里使用正则表达式在线测试工具进行验证(以下同样)

如上,\b可以控制开头和结尾,这种可以用来匹配整个单词而不只是其中的一部分
虽然之前的正则表达式已经描述,这里在熟悉一下:‘.’匹配除了换行符的任意字符,注意不包含换行符,‘*’也是元字符,它代表的既不是字符也不是位置,而是数量
因此.*意味着任意数量的不包含换行的字符,如上\bhi\b.*\blucy\b,这里表示开头为hi,结尾为lucy,中间为任意多个字符(可以没有)
总结:
+:重复一次或更多次
?:重复0次或者一次
{n}:重复n次
{n,}:重复n次或更多次
{n,m}:重复n到m次

如上可以看出?和[]\d{}等的用法,但是也可以看出这种电话号码匹配是有问题的(半括号也可以匹配成功)
分支条件:
是指n种方式并列,从左向右进行匹配,当第一种情况不匹配成功时就匹配第二种,,使用'|'符号,以此类推
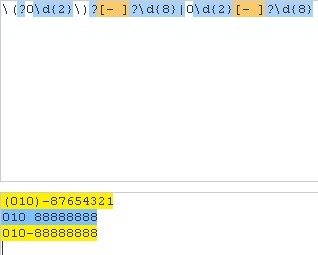
如上是两种情况,一种是有括号的一种是没有括号的,但是注意以下特别情况:
\d{5}-\d{4}|\d{5}
\d{5}|\d{5}-\d{4}
如上两个匹配的过程是不同的,如果是前者,先匹配约束强的,如果不能匹配,才进入\d{5}。但是后者相反,因此一般情况下我们采用前者
分组技术:

如上可以将分组重复3次,非常有用的功能,但是如上如果是ip地址的正则匹配的话对于256.300.888.999也是会被匹配的到的,正确的操作应该是:

这个分组分为三种情况:第一个是2[0-4]\d、25[0-5]和[01]?\d\d?。这三部分分别对应了ip地址的三种合理情况。
匹配最少重复:
正则表达式的特点是贪心法的思想,即通常的行为是匹配尽可能多的字符,如a.*b,它将会匹配最长的以a开头以b结尾的字符串。如aabab则会匹配出aabab
那么如何匹配尽可能少的字符呢:
答案是使用.*?,如下:

他会匹配aab和ab,注意第一个为什么不匹配ab呢?因为正则表达式中最先开始的匹配有最高的优先级。
总结:
*?重复任意次,但尽可能少重复
+?重复一次或多次,但尽可能少重复
??重复0次或1次,但尽可能少重复
{n,m}?重复n次到m次,但尽可能少重复
注释:
?#comment
2[0-4]\d(?#200-249)|25[0-5](?#250-255)|[01]?\d\d?(?#0-199)
后向引用:

如上\1表示分组内的项,两个完整的单词中间夹着空白字符即可(空白字符可以是空格、tab等)














 1747
1747











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









