






网上对其解读有点过了,只是合成了最后标准化层的参数,或者是更多的其他层参数。而不是网络结构。对于新任务下的网络结构以及参数如何生成,应该是做不到的,论文意义有限。
论文片段:我们提出了神经网络扩散(p-diff),其目的是从随机噪声中生成高性能的参数。如图2所示,我们的方法由两个过程组成,即参数自动编码器和生成器。给定一组训练过的高性能模型,我们首先选择这些参数中的一个子集,并将它们压平为一维向量。随后,我们引入了一个编码器,从这些向量中提取潜在表示,并伴随着一个解码器,负责从潜在表示中重建参数。然后,训练一个标准的潜在扩散模型,从随机噪声中合成潜在表示。经过训练后,我们利用p-diff通过以下链生成新的参数:随机噪声→反向处理→训练的解码器→生成的参数。
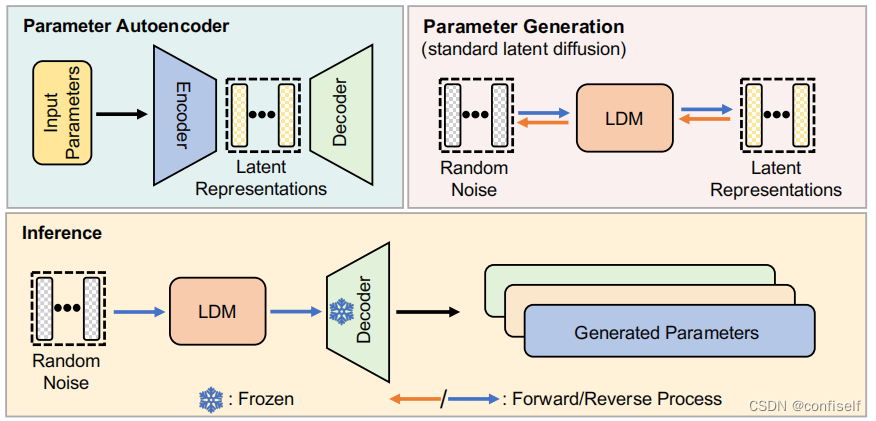
图2
1、什么是参数中的子集呢?如果是压缩成一维向量后再做编码解码训练的,那么解码后的依旧为一维向量,又如何恢复为特定的参数和参数值呢?
论文片段:训练autoencoder decoder。我们对预训练模型的参数子集进行了微调,并将微调后的参数密集地保存为训练样本。然后,我们将这些参数S压扁为一维向量V = [v1,……,vk,……,vK],其中V∈R (K×D),D是子集参数的大小。然后,训练一个自动编码器来重建这些参数V。我们默认使用一个自动编码器和一个4层编码器和解码器。与正常的自动编码器训练相同,我们将V‘和V之间的均方误差(MSE)损失最小化如下
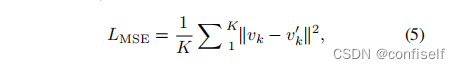
其中v‘k是第k个模型的重构参数。
论文片段:直接将随机噪声输入反向过程和经过训练的解码器,以生成一组新的高性能参数。这些生成的参数与剩余的模型参数连接起来,形成新的模型进行评估。神经网络参数和图像像素在几个关键方面表现出显著的差异,包括数据类型、维度、范围和物理解释。与图像不同的是,神经网络参数大多没有空间相关性,因此我们在参数自编码器和参数生成过程中,用一维卷积代替二维卷积。
论文片段:通过在潜在扩散模型和训练解码器中加入随机噪声,合成了100个新参数。然后将这些合成参数与上述固定参数连接起来,形成我们生成的模型。从这些生成的模型中,我们选择了在训练集上表现最好的模型。
从以上内容可以看出,模型中选取部分参数(参数子集)作为训练样本,K为训练样本数(不同模型)。但没有讲如何恢复100个参数的细节。
2、在有限的训练样本下训练了这个模型,其意义在哪里? 模型和图片不同,应该是不具备迁移效果的,更何况这些模型根据任务的不同,不同层的参数也有区别。给你一个新模型结构,生成的参数有意义吗?
论文片段:应用p-diff的位置。我们默认是合成最后两个标准化层的参数。为了研究p-diff在其他归一化层深度上的有效性,我们还探讨了合成其他浅层参数的性能。为了保持相同数量的BN参数,我们对三组BN层实现了我们的方法,它们是在不同深度的层之间。如标签页中所示。2(b),我们通过经验发现,我们的方法在所有BN层设置的深度上都比原始模型获得了更好的性能(最佳精度)。另一个发现是,合成深层比生成浅层可以获得更好的精度。这是因为生成浅层参数比生成深层参数更容易在正向传播过程中积累误差
所以,网上对其解读有点过了,知识合成了最后标准化层的参数,或者是更多的其他层参数。而不是网络结构。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









