







 本文详细介绍了扩散模型的工作原理,如DDPM如何通过噪声预测和去噪,以及UNET在噪声预测器中的应用。还讨论了StableDiffusion如何利用VAE加速图像生成,并提到了DIT和SORA模型的优势,包括Transformer技术带来的可扩展性和性能提升。
本文详细介绍了扩散模型的工作原理,如DDPM如何通过噪声预测和去噪,以及UNET在噪声预测器中的应用。还讨论了StableDiffusion如何利用VAE加速图像生成,并提到了DIT和SORA模型的优势,包括Transformer技术带来的可扩展性和性能提升。
Diffusion model 扩散模型如何工作?
输入随机噪声和文本内容,通过多次预测并去除图片中的噪声后,最终生成清晰的图像。
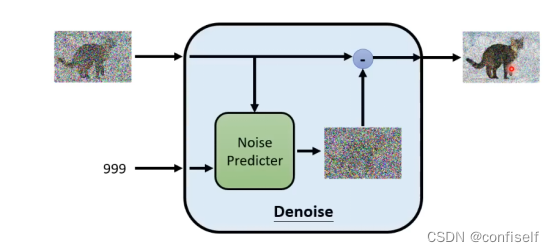
以上左边这张图,刚开始是随机噪声,999为时间序列。
为什么不直接预测下一张图片呢?
预测噪声还是简单一点。
如何训练 Noise Predicter呢?
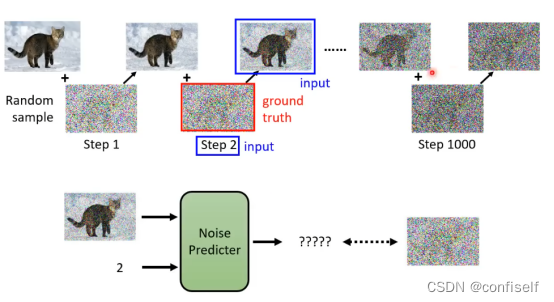
具体的方法是自己去按步骤加噪音,这样就构建了训练样本。预测目标就是我们加的噪声。
如何加入文字?
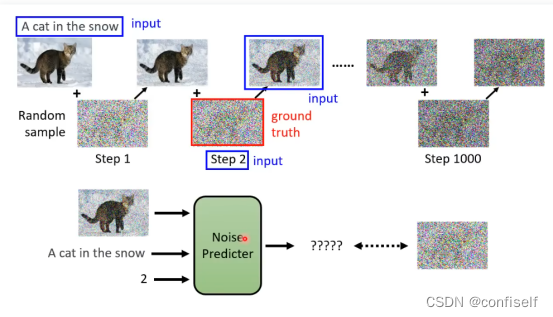
可以看出,增加文字输入即可
DDPM原理

当然具体的噪声loss计算,以及去噪公式稍微麻烦一点,并不是直接加减。
输入随机噪声和文本内容,通过多次预测并去除图片中的噪声后,最终生成清晰的图像。
以上左边这张图,刚开始是随机噪声,999为时间序列。
预测噪声还是简单一点。
具体的方法是自己去按步骤加噪音,这样就构建了训练样本。预测目标就是我们加的噪声。
可以看出,增加文字输入即可
当然具体的噪声loss计算,以及去噪公式稍微麻烦一点,并不是直接加减。
 227
7042
227
7042

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























