






将16bits的pcm信号编码成8bits样本进行传输
有基于G.711标准的两种算法(A-law, u-law)
A律压缩相对来说较简单。将一个16bit数压缩为8bit,保留最高位为符号位,814bit为段落码,07bit为段内码。
u律压缩取每个prb的i,q数据最大值,然后根据最大值判断移位,再根据压缩bit数及i,q值的大小做相应的移位处理。
G711
也称为PCM(脉冲编码调制),是国际电信联盟订定出来的一套语音压缩标准,主要用于电话。它主要用脉冲编码调制对音频采样,采样率为8k每秒。它利用一个64Kbps未压缩通道传输语音讯号。起压缩率为1:2,即把16位数据压缩成8位。G.711是主流的波形声音编解码器。
G.711 标准下主要有两种压缩算法。一种是
- µ-law algorithm (又称often u-law, ulaw, mu-law),主要运用于北美和日本;
- 另一种是A-law algorithm,主要运用于欧洲和世界其他地区。其中,后者是特别设计用来方便计算机处理的。
这两种算法都使用一个采样率为8kHz的输入来创建64Kbps的数字输出。a-law也叫g711a,输入的是13位(其实是S16的高13位).
A-law algorithm
A-law 是 CCITT 推荐的全欧洲使用的压缩标准。将线性采样值限制为12个量级位,A-law 压缩由公式1定义,其中A为压缩参数(欧洲为A=87.7), x 为需要压缩的归一化整数。
表1给出了 A-law 编码表。线性输入数据的符号位从表中省略。如果输入样本为负,则8位代码的符号位(S)设置为1,如果输入样本为正,则设置为0
压缩过程
(1)取符号位并取反得到s,
(2)获取强度位eee,获取方法如图所示
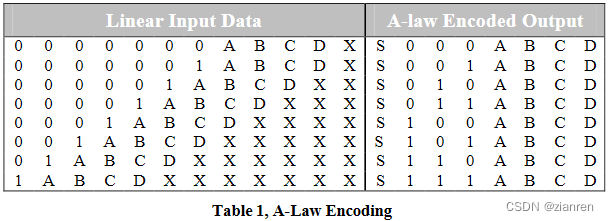
(3)获取高位样本位wxyz
(4)组合为seeewxyz,将seeewxyz逢偶数为取补数,编码完毕
通过表中定义的逻辑对输入数据进行编码后,对8位码应用翻转模式,以增加传输线上的传输密度,从而提高硬件性能。翻转模式是通过用 0x55 异或处理8位码来实现的。
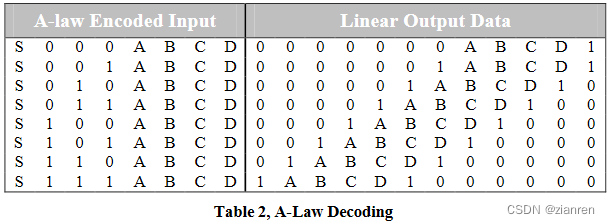
解码 A-law 编码的数据本质上是一个反向编码步骤的问题。表2给出了翻转模式后应用的A-law解码表。编码过程中丢弃的最低有效位近似于间隔的中值。这在输出部分中以 1…0 形式尾随在D位后。
编码代码如下
#define MAX (32635)
void encode(unsigned char *dst, short *src, size_t len)
{
for(int i = 0; i < len ; i++)
{
// *dst++ = *src++;
short pcm = *src++;
int sign = (pcm & 0x8000) >> 8;
if(sign != 0)
pcm = -pcm;
if(pcm > MAX) pcm = MAX;
int exponent = 7;
int expMask;
for(expMask = 0x4000; (pcm & expMask) == 0 && exponent >0; exponent--,expMask >>= 1){}
int mantissa = (pcm >> ((exponent == 0) ? 4 : (exponent + 3))) & 0x0f;
unsigned char alaw = (unsigned char)(sign | exponent << 4 | mantissa);
*dst++ = (unsigned char)(alaw ^0xD5);
}
}
译码代码如下
void decode(short *dst, unsigned char *src, size_t len)
{
for(size_t i=0; i < len ; i++)
{
unsigned char alaw = *src++;
alaw ^= 0xD5;
int sign = alaw & 0x80;
int exponent = (alaw & 0x70) >> 4;
int data = alaw & 0x0f;
data <<= 4;
data += 8; //丢失的a 写1
if(exponent != 0) //将wxyz前面的1补上
data += 0x100;
if(exponent > 1)
data <<= (exponent - 1);
*dst++ = (short)(sign == 0 ? data : -data);
}
}
测试函数
std::string filename = "3.pcm";
FILE* file = fopen(filename.c_str(), "rb");
ScheduleServer::CPCMPlayer player;
short* frame = (short*) malloc(480);
unsigned char * data = (unsigned char *) malloc(480);
while (true)
{
size_t read_len = fread(frame, sizeof(short), 480, file);
if(480 != read_len)
{
fseek(file, 0, SEEK_SET);
//break;
}
encode(data,frame,read_len);
decode(frame,data,read_len);
player.play(frame);
}
free(frame);
µ-law algorithm
美国和日本采用μ法压缩。将线性样本值限制为13个量级位,μ律压缩由公式2定义,其中μ是压缩参数(美国和日本的μ =255), x 是要压缩的归一化整数。
μ-Law 的编码和译码过程与 A-law 相似。然而,有一些显著的区别:
- μ-law 编码器通常对线性13位幅度数据进行操作,而不是 A-law 的12位幅度数据
- 在弦确定之前,将偏置值33添加到线性输入数据的绝对值中,以简化弦和步长计算
- 符号位的定义是反过来的
- 翻转模式应用在8位码中的所有位
表3展示了 μ-law 编码表。线性输入数据的符号位从表中省略。如果输入样本为正,则8位代码的符号位(S)设置为1,如果输入样本为负,则设置为0。

通过表中定义的逻辑对输入数据进行编码后,对8位码应用翻转模式,以增加传输线上的传输密度,从而提高硬件性能。用 0xFF 对8位码进行异或运算,从而实现翻转模式。
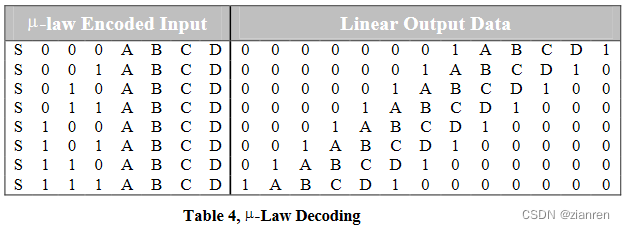
解码 μ-Law 编码的数据本质上是反向编码步骤的问题。表4给出了翻转模式后应用的 μ-Law 译码表。编码过程中丢弃的最低有效位近似于间隔的中值。这在输出部分中以 1…0 形式尾随在D位后。
https://tda-2030.github.io/2021/05/22/ALaw_and_MuLaw_Companding/
//aLaw
0000000 abcd x <=> 000 abcd
0000001 abcd x <=> 001 abcd
000001 abcd xx <=> 010 abcd
00001 abcd xxx <=> 011 abcd
0001 abcd xxxx <=> 100 abcd
001 abcd xxxxx <=> 101 abcd
01 abcd xxxxxx <=> 110 abcd
1 abcd xxxxxxx <=> 111 abcd
//uLaw
00000001 abcd x <=> 000 abcd
0000001 abcd xx <=> 001 abcd
000001 abcd xxx <=> 010 abcd
00001 abcd xxxx <=> 011 abcd
0001 abcd xxxxx <=> 100 abcd
001 abcd xxxxxx <=> 101 abcd
01 abcd xxxxxxx <=> 110 abcd
1 abcd xxxxxxxx <=> 111 abcd
示例:
输入pcm数据为3210,二进制对应为(0000 1100 1000 1010)
二进制变换下排列组合方式(0 0001 1001 0001010)
(1)获取符号位最高位为0,取反,s=1
(2)获取强度位0001,查表,编码制应该是eee=100
(3)获取高位样本wxyz=1001
(4)组合为11001001,逢偶数为取反为10011100
A律十三折线法G711编解码介绍
把16bit的音频数据转为8bit。
最简单的方式是均匀量化, >>8 (右移8位),但这样做会使得声音的噪音变大。
最好的做法是使用非均匀量化(如A-Law),其原理是对于小音量的声音,其蕴含的信息量更大,人耳对小音量
更敏感;而大音量部分则影响没那么大。因此使用非均匀量化的方式,对于小音量部分保留更多的数据,大音量部分则保留更少的数据。具体实现如下:
这里选择A-Law(A律)算法,也可以用uLaw(μ律),两种算法可相互转化。
令量化器过载电压为1,相当于把输入信号进行归一化,那么A律对数压缩定义为:
当0 <= x <= 1/A时,f(x)=(Ax)/(1+lnA)
当1/A <= x <= 1时,f(x)=(1+lnAx)/(1+lnA)
在现行的国际标准中A=87.6,此时信号很小时(即小信号时),从上式可以看到信号被放大了16倍,
这相当于A压缩率与无压缩特性比较,对于小信号的情况,量化间隔比均匀量化时减小了16倍,
因此,量化误差大大降低;而对于大信号的情况例如x=1,量化间隔比均匀量化时增大了5.47倍,
量化误差增大了。这样实际上就实现了“压大补小”的效果。
图形曲线如下(只画出正数部分,对于负数也是同样的道理)(这里用了归一化):
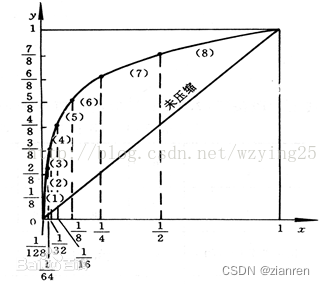
但是要在程序中实现该曲线,比较复杂。因此这里使用8段折线来近似表示。
把x轴划分为不均匀的8份,第一点取1/2处,第二点取1/4处,第三点取1/8处……第七点取1/128.
把y轴划分为均匀的8分段。
https://blog.csdn.net/jackzhouyu/article/details/108140976
https://www.cnblogs.com/callmesblog/p/16055487.html
音频处理——G711标准详解
https://blog.csdn.net/qq_28258885/article/details/120215750















 4625
4625











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









