







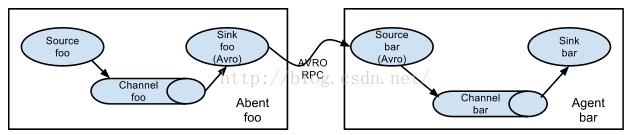
2个agent,一个负责采集数据,然后提交给收集数据的agent,收集到数据之后打印出来。
event:一个数据单元,带有一个可选的消息头
环境搭建:
hadoop1 数据采集端
hadoop2 数据接收端
数据采集端:
source:spooldir
channel:memory
sink:avro
数据接收端:
source:avro
channel:memory
sink:logger
说明:
spooldir source:监测配置的目录下新增的文件,并将文件中的数据读取出来。
需要注意两点:
1、拷贝到spool目录下的文件不可以再打开编辑。
2、spool目录下不可包含相应的子目录。
channel memory:数据存储在内存中
avro source:支持avro协议(实际上是Avro RPC),内置支持
avro sink:数据被转换成avro event,然后发送到配置的RPC端口上
logger sink:数据写入日志文件
集群搭建
下载:apache-flume-1.5.0-bin.tar.gz
[sparkadmin@hadoop1 ~]$ tar -zxvf apache-flume-1.5.0-bin.tar.gz
[sparkadmin@hadoop1 ~]$ ln -s apache-flume-1.5.0-bin flume
[sparkadmin@hadoop1 ~]$ cd flume/conf/
[sparkadmin@hadoop1 conf]$ ll
total 12
-rw-r--r-- 1 sparkadmin sparkadmin 1661 Mar 29 2014 flume-conf.properties.template
-rw-r--r-- 1 sparkadmin sparkadmin 1197 Mar 29 2014 flume-env.sh.template
-rw-r--r-- 1 sparkadmin sparkadmin 3063 Mar 29 2014 log4j.properties
[sparkadmin@hadoop1 conf]$ mv flume-env.sh.template flume-env.sh
[sparkadmin@hadoop1 conf]$ ll
total 12
-rw-r--r-- 1 sparkadmin sparkadmin 1661 Mar 29 2014 flume-conf.properties.template
-rw-r--r-- 1 sparkadmin sparkadmin 1197 Mar 29 2014 flume-env.sh
-rw-r--r-- 1 sparkadmin sparkadmin 3063 Mar 29 2014 log4j.properties
[sparkadmin@hadoop1 conf]$ vim flume-env.sh
添加:
JAVA_HOME=/home/sparkadmin/jdk1.7.0_60
通过scp 将hadoop1 上的flume 拷贝到 hadoop2 上面。
两个机器的环境必须一样。
[sparkadmin@hadoop1 ~]$ scp -rq apache-flume-1.5.0-bin hadoop2:/home/sparkadmin/
在hadoop1上面,数据采集端
[sparkadmin@hadoop1 conf]$ touch push.conf
[sparkadmin@hadoop1 conf]$ vim push.conf
a1.sources=k1
a1.sinks=r1
a1.channels=c1
#source
a1.sources.k1.type=spooldir
a1.sources.k1.spoolDir=/home/sparkadmin/tmp/logs
a1.sources.k1.channels=c1
a1.channels.c1.type=memory
a1.channels.c1.keep-alive=10 #超时秒数增加或删除一个事件
a1.channels.c1.capacity=100000 #容量:存储在通道的最大事件数
a1.channels.c1.transactionCapacity = 100000
a1.sinks.r1.type=avro
a1.sinks.r1.hostname=hadoop2 #数据接收端
a1.sinks.r1.port=55555
a1.sinks.r1.channel=c1
[sparkadmin@hadoop1 ~]$ mkdir -p tmp/logs
[sparkadmin@hadoop1 ~]$ cd tmp/logs/
[sparkadmin@hadoop1 logs]$ vim test.log
里面添加:
hello
flume
this is a agent!
my name is jame and i like my car,so the car id red
在hadoop2上,数据接收端
[sparkadmin@hadoop2 conf]$ touch pull.conf
[sparkadmin@hadoop2 conf]$ vim pull.conf
a1.sources=k1
a1.channels=r1
a1.sinks=s1
a1.sources.k1.type=avro
a1.sources.k1.bind=hadoop2
a1.sources.k1.port=55555
a1.sources.k1.channels=r1
a1.channels.r1.type=memory
a1.channels.r1.keep-alive=10
a1.channels.r1.capacity=100000
a1.channels.r1.transactionCapacity=100000
a1.sinks.s1.type=logger
a1.sinks.s1.channel=r1
首先启动接收端
在hadoop2上面执行
[sparkadmin@hadoop2 flume]$ bin/flume-ng agent --conf conf --conf-file conf/pull.conf --name a1 -Dflume.root.logger=INFO,console
然后启动采集端
在hadoop1上面执行
[sparkadmin@hadoop1 flume]$ bin/flume-ng agent -n a1 -c conf -f conf/push.conf
启动hadoop1之后,hadoop2将会打印出下面的信息:
2016-09-29 15:29:59,972 (New I/O server boss #1 ([id: 0x2e36f80d, /hadoop2:55555])) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:171)] [id: 0x4db05bef, /hadoop1:41168 => /hadoop2:55555] OPEN
2016-09-29 15:29:59,972 (New I/O worker #5) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:171)] [id: 0x4db05bef, /hadoop1:41168 => /hadoop2:55555] BOUND: /hadoop2:55555
2016-09-29 15:29:59,972 (New I/O worker #5) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:171)] [id: 0x4db05bef, /hadoop1:41168 => /hadoop2:55555] CONNECTED: /hadoop1:41168
这个表示hadoop1 和 hadoop2 连接上了。接着会打印出文件里面的数据。
2016-09-29 15:20:39,939 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:70)] Event: { headers:{} body: 68 65 6C 6C 6F hello }
2016-09-29 15:20:39,940 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:70)] Event: { headers:{} body: 66 6C 75 6D 65 flume }
2016-09-29 15:20:39,940 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:70)] Event: { headers:{} body: 74 68 69 73 20 69 73 20 61 20 61 67 65 6E 74 21 this is a agent! }
2016-09-29 15:20:39,940 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:70)] Event: { headers:{} body: 6D 79 20 6E 61 6D 65 20 69 73 20 6A 61 6D 65 20 my name is jame }
把文件拷贝到tmp/logs/下面,数据将会再hadoop2上打印出来
[sparkadmin@hadoop1 ~]$ cp weblogs_aggregate.txt tmp/logs/
跑完之后会在文件后面加上 .COMPLETED 的后缀
[sparkadmin@hadoop1 logs]$ ll
total 876
-rw-rw-r-- 1 sparkadmin sparkadmin 81 Sep 29 14:57 test.log.COMPLETED
-rw-r--r-- 1 sparkadmin sparkadmin 890709 Sep 29 15:22 weblogs_aggregate.txt.COMPLETED
如果连接不上的话,说明 hadoop2 上面没有安装Avro
安装Avro
首先要安装cmake
[sparkadmin@hadoop2 ~]$ wget http://www.cmake.org/files/v2.8/cmake-2.8.11.tar.gz
[sparkadmin@hadoop2 ~]$ tar -zxvf cmake-2.8.11.tar.gz
[sparkadmin@hadoop2 ~]$ cd cmake-2.8.11
[sparkadmin@hadoop2 cmake-2.8.11]$ ./bootstrap
如果报错:Cannot find appropriate C compiler on this system.
需要安装这个:yum install gcc gcc-c++ -y
[sparkadmin@hadoop2 cmake-2.8.11]$ make
[sparkadmin@hadoop2 cmake-2.8.11]$ sudo make install
安装Avro
[sparkadmin@hadoop2 ~]$ wget http://apache.fayea.com/avro/stable/c/avro-c-1.8.1.tar.gz
[sparkadmin@hadoop2 ~]$ tar -zxvf avro-c-1.8.1.tar.gz
[sparkadmin@hadoop2 ~]$ cd avro-c-1.8.1
[sparkadmin@hadoop2 avro-c-1.8.1]$ mkdir build
[sparkadmin@hadoop2 avro-c-1.8.1]$ cd build
[sparkadmin@hadoop2 build]$ sudo cmake .. -DCMAKE_INSTALL_PREFIX=$PREFIX -DCMAKE_BUILD_TYPE=RelWithDebInfo
[sparkadmin@hadoop2 build]$ make
[sparkadmin@hadoop2 build]$ make install















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









