







- 还在找AI知识库工具么?
- 还在为自己搭建AI知识库而苦恼么?
- 还在为文档分析、总结而烦躁么?
- 还在为不同诉求而注册、充值不同AI软件而苦恼么?
领航AGI聚合平台,解决你所有困扰!
今天主要讲如何在领航AGI上免费使用AI知识库、文档分析、总结摘要功能
1、注册登录,或进入控制台
2、AI工具集导航:领航AGI工具集 | 全球AI工具网址导航
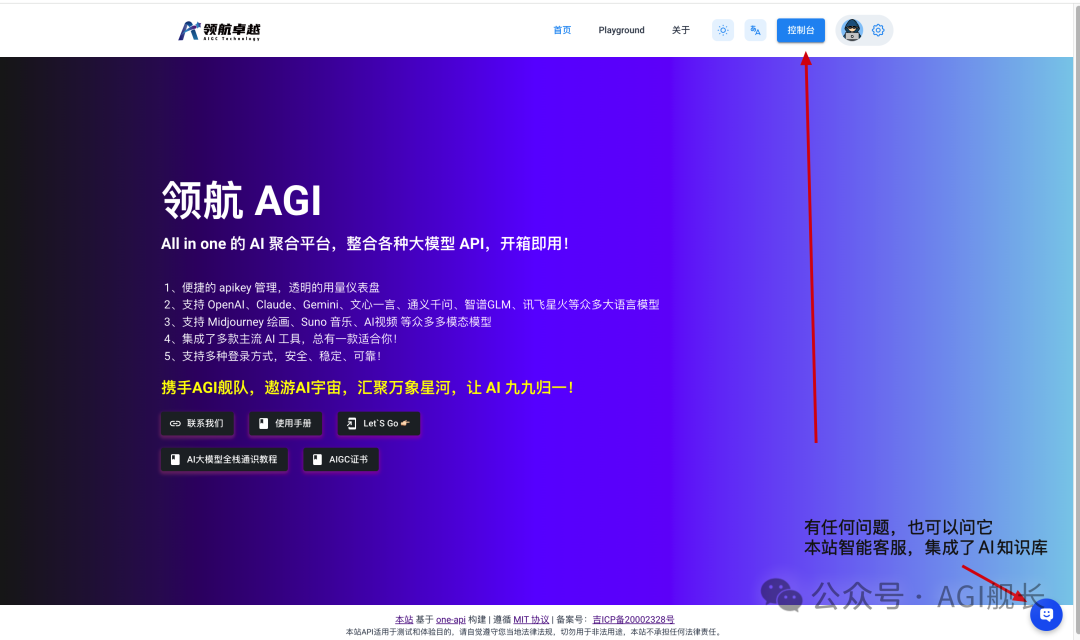
2、点击 playground 选择第三款AI工具,典藏款 LobeChat,立即开始
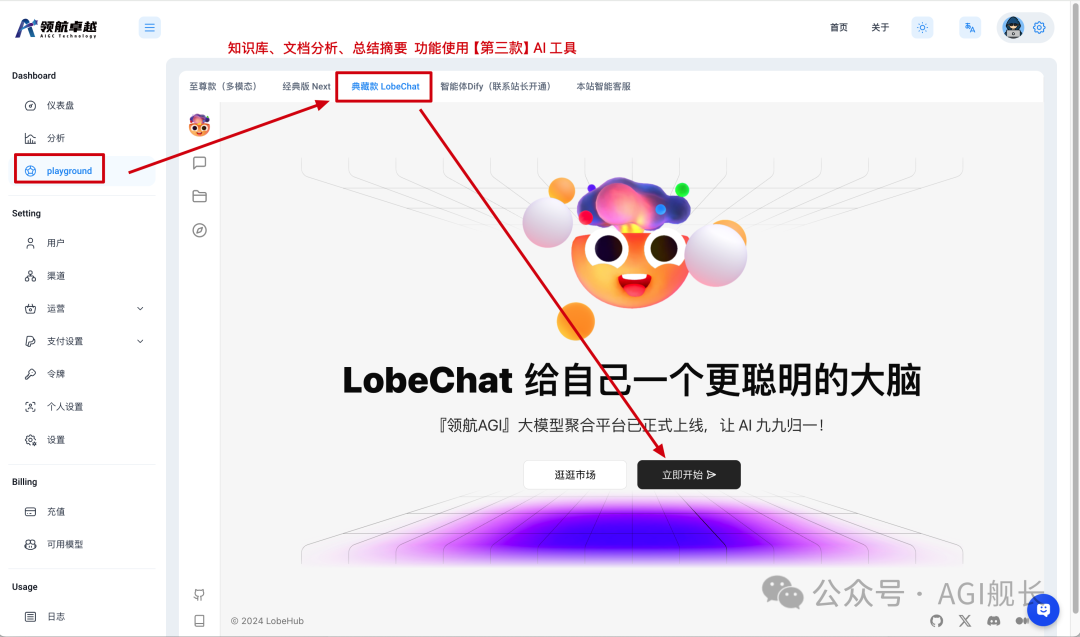
3、点击左上角头像,注册\登录, 这里做二次登录目的是,数据分离,以保证大家的数据隐私以及数据持久化(记忆)
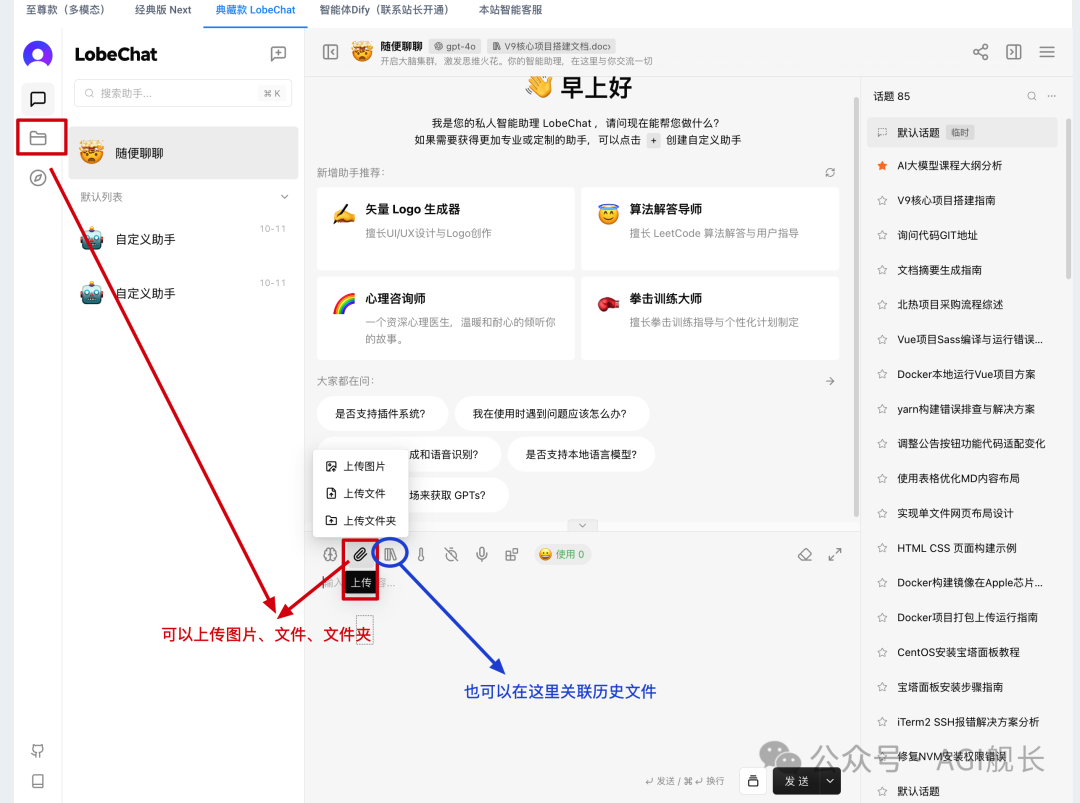
4、文件上传两个入口,一个是对话框上面的一排按钮,另一个是头像下方第二个文件夹按钮
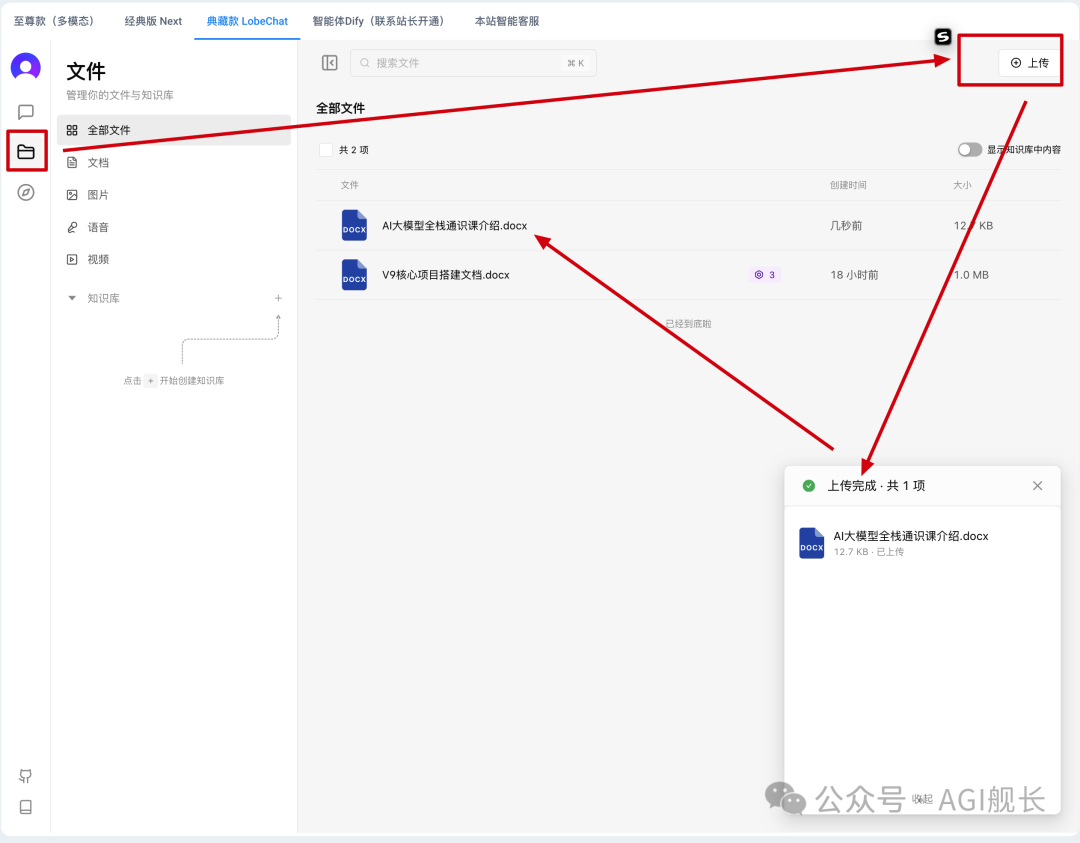
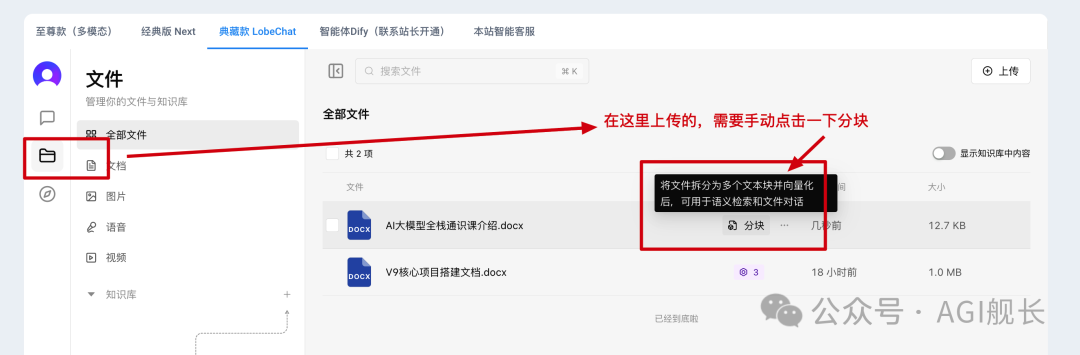
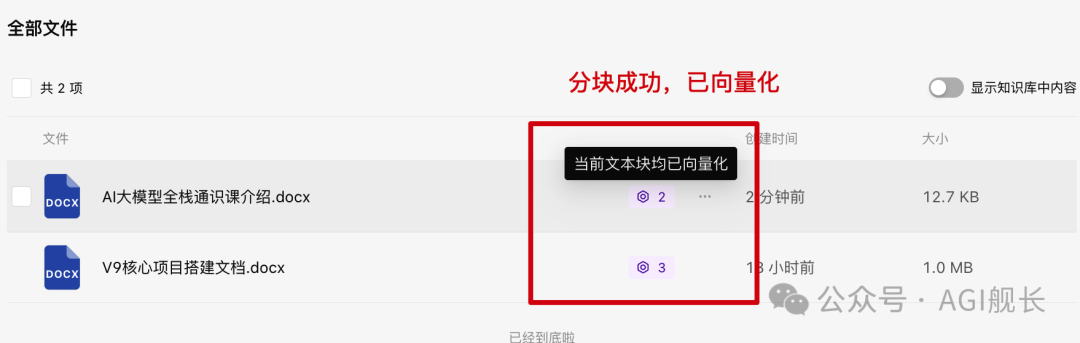
5、分块检查(向量化过程,对话框上传的会自动分块, 文件处上传的需要手动点击一下)
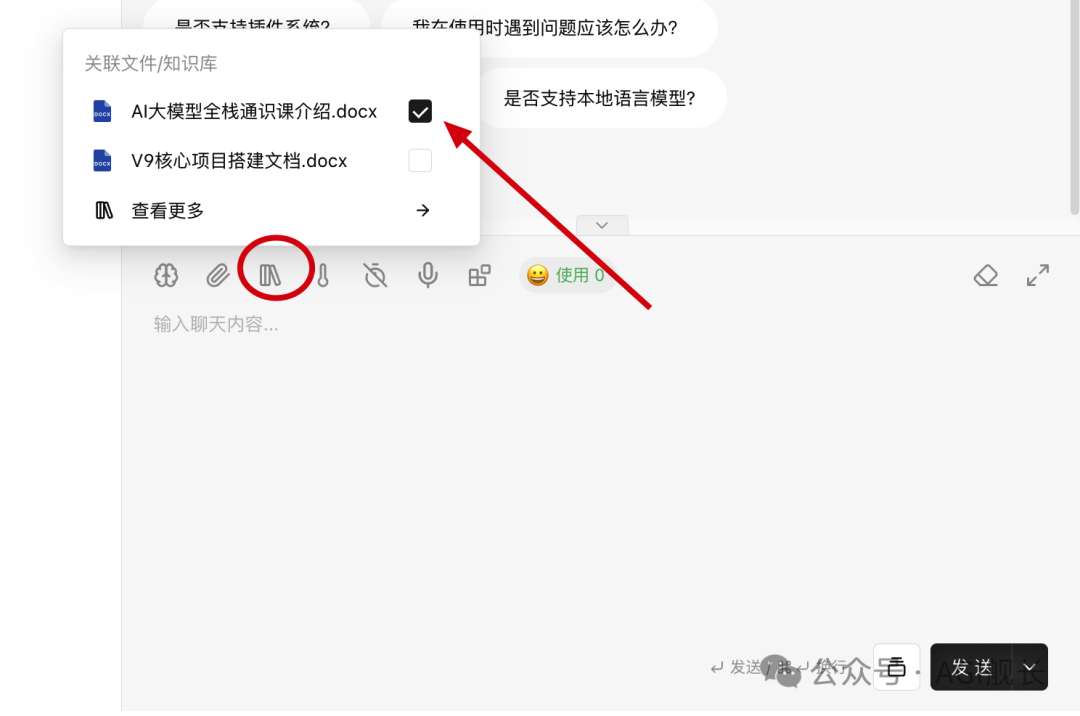
6、对话框添加知识库
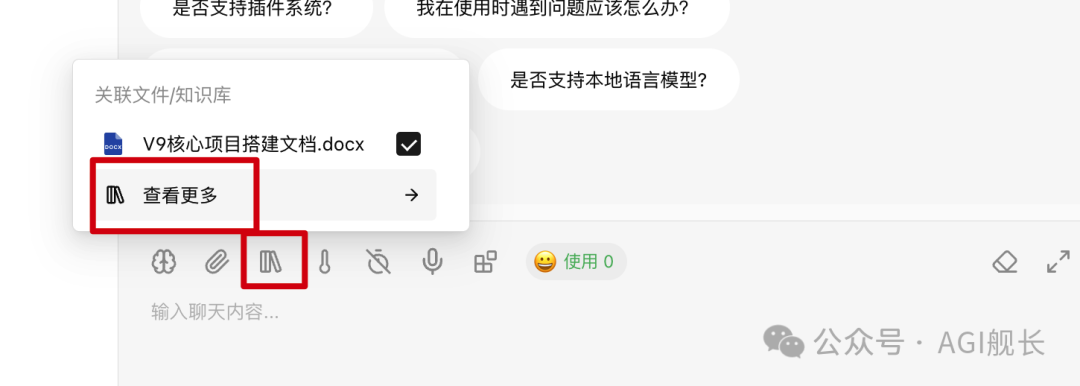

7、对话中引用知识库
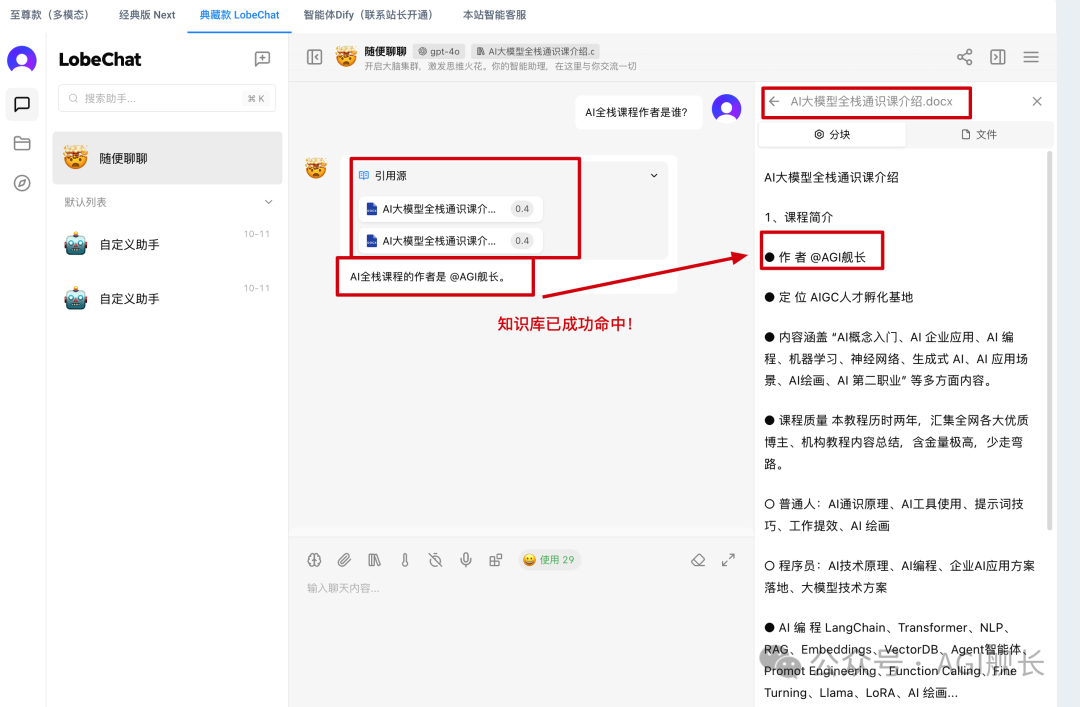
就问你,帅不帅,快去体验一下吧~
视频版教程
推荐一款免费好用的「AI 知识库」工具,可进行RAG问答、文档分析、总结摘要等,自动进行chunk拆分与向量化



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











