







数据存储在文件中
在操作文件前,我们应该先创建一个SparkSession
val spark = SparkSession.builder()
.master("local[6]")
.appName("reader1")
.getOrCreate()
CSV类型文件
简单介绍:逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)
- 我们在读取数据文件时,应先说明文件的类型是什么,是csv,json,txt亦或者是其他,具体代码如下:
spark.read
.format("csv")
.load("data/BeijingPM20100101_20151231.csv")
.show()
- 但是如果每一次读写都需手动
format文件类型也太过于繁琐,我们其实可以使用.csv来直接读取csv文件
spark.read
.csv("data/BeijingPM20100101_20151231.csv")
.show()
- 在读取csv文件时,会默认将每一个数据元素都保存为字符串类型,若想要数据类型保持不变,可以选择自己手动设置或者直接
Schema,代码变成下方所示
spark.read
.option("header", true)
.option("inferSchema", true)
.csv("data/BeijingPM20100101_20151231.csv")
.show()
- csv文件的第一行内容通常都是列名,如果我们直接读取的话,系统会将其当成是数据,那么在处理数据的过程中就会容易报错,我们可以提前申明一下
spark.read
.option("header", true)
.option("inferSchema", true)
.csv("data/BeijingPM20100101_20151231.csv")
.show()
JSON类型文件
- json数据一般都是用来存储对象数据
- json格式的数据文件读取和csv很相似,具体如下所示:
val df = spark.read
.option("header",true)
.csv("data/BeijingPM20100101_20151231.csv")
.toJSON
- 我们可以使用
toJson方法直接将其他的文件格式转换成json类型
df.write.json("data/Beijing_pm2.json")
df.write.format("json").save("data/Beijing_pm2.json")
Parquet操作
- parquet是面向分析型业务的列式存储格式,是一种支持嵌套结构的存储格式,并且使用了列式存储的方式提升查询性能
- 我们可以读取csv类型的文件并且将文件格式保存为parquet
val df = spark.read.option("header", true).csv("data/BeijingPM20100101_20151231.csv")
//将数据写为parquet格式
df.write
.mode(SaveMode.Overwrite)
.format("parquet")
.save("data/beijing_pm3")
-
我们发现在保存parquet文件时与之前相比多了一个
mode,这是为了预防parquet保存路径已经有其他的文件存在,他一共有四种模式分别是:报错、重写、忽略和追加,默认时报错

-
parquet文件保存并不是一个文件,而是存为一个文件夹,如下图所示

-
那我们该如何读取parquet类型的文件呢?
spark.read .parquet("data/beijing_pm3")
分区操作
分区就是将数据以某一列为标准来进行分类,每一个类都是存为一个文件夹
- 分区操作的读写操作如下所示
val df = spark.read
.option("header", true)
.csv("data/BeijingPM20100101_20151231.csv")
//写文件,表分区
df.write
.partitionBy("year", "month")
.save("data/beijing_pm4")
//读文件,自动发现分区
spark.read
.parquet("data/beijing_pm4")
.printSchema()
partitionBy时标注以那一列来进行分区,分区的效果如下所示
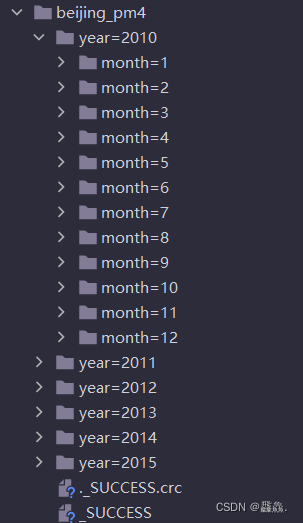
- 在读取分区表的时候不仅仅可以读取整表,还可以细分到某一个分区内,如读取2010年1月的数据,但是这样就会导致列的减少,会少年和月两列
spark.read
.parquet("data/beijing_pm4/year=2010/month=1")
.show()
数据存储在Hive表中
具体代码如下
//1、创建SparkSession
val spark = SparkSession.builder()
.appName("Hive")
.enableHiveSupport()
//填写hive有关的一些信息(端口号、数据库地址等)
.config("hive.metastore.uris", "thrift://node1:9083")
.config("spark.sql.warehouse.dir", "/dataset/hive")
.getOrCreate()
//读取数据
import spark.implicits._
//hive表的每一列的数据格式
val schema = StructType {
List(
StructField("name", StringType),
StructField("age", IntegerType),
StructField("gpa", FloatType)
)
}
//读取hdfs上的数据存入到hive中
val df = spark.read
//分割符时制表符
.option("delimited", "\t")
//文件的schema就是上面定义的
.schema(schema)
//文件在hdfs中的路径
.csv("hdfs:///dataset/student.csv")
val result = df.where('age > 50)
//写入数据
result.write.mode(SaveMode.Overwrite).saveAsTable("spark.student")
与MySQL有关
读取MySQL中的数据
def createDataFrame03() = {
spark.read
.format("jdbc")
.option("url", "jdbc:mysql://127.0.0.1:3306/spark")
.option("dbtable", "student")
.option("user", "root")
.option("password", "123456")
.load()
.show()
}
解释
- 第一个
option是url - 第二个
option是表名 - 第三个
option是用户名 - 第四个
option是密码
数据存储在MySQL中
//1、创建SparkSession
val spark = SparkSession.builder()
.appName("Mysql")
.master("local[6]")
.getOrCreate()
//读取数据
import spark.implicits._
val schema = StructType {
List(
StructField("name", StringType),
StructField("age", IntegerType),
StructField("gpa", FloatType)
)
}
val df = spark.read
.option("delimiter", "\t")
.schema(schema)
.csv("hdfs:///dataset/student.csv")
val result = df.where('age > 50)
//写入数据
result.write
.format("jdbc")
.option("url", "jdbc:mysql://node1:3306/spark")
.option("dbtable","student")
.option("user","spark")
.option("password","123456")
.mode(SaveMode.Overwrite)
.save()















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









