







经过我们 上一章的学习,我们掌握了两个”无产阶级劳动者”Network和HttpStack的工作流程,这两个工作者为我们实现了底层的Http协议和数据传输。那么本章我们就继续我们的分析流程。
Cache
上一篇中我们根据我们的使用流程,分析到了Network的创建这一步,我们现在继续,就是要创建RequestQueue了,代码是这个样子的:
RequestQueue queue;
if (maxDiskCacheBytes <= -1)
{
// No maximum size specified
queue = new RequestQueue(new DiskBasedCache(cacheDir), network);
}
else
{
// Disk cache size specified
queue = new RequestQueue(new DiskBasedCache(cacheDir, maxDiskCacheBytes), network);
}
queue.start();那看来我们的RequestQueue中必须要传递一个DiskBasedCache进去了,跟到DiskBasedCache中一看,是一个Cache的实现类,那么好,我们先搞定这个Cache接口,剩下对付这个”儿子”DiskBasedCache就简单多了。
Cache是Volley中所有缓存操作的接口,既然是缓存操作,那就得有索引,也就是说你要操作哪个缓存或者是哪个网络资源的缓存,对吧,网络资源和缓存总得有一个映射关系,要不要谁是谁的缓存都找不到,那就没意思了是吧,映射关系那我们就用键值对,键值对肯定就是Map形式的啦,自然而然,我们的Cache接口就基本上实现了一个Map形式的缓存操作接口,肯定有一个key,这个key是标识着某一个网络资源,而value就是对应的缓存对象或者缓存数据,废话说了这么多,还不如直接看代码:
/**
* 该接口用于以键值对的形式缓存byte数组,键是一个String
*/
public interface Cache {
/**
* 返回一个空的Entry.
* @param key key
* @return 一个 {@link Entry} or null
*/
Entry get(String key);
/**
* 添加或者替换entry到cache.
* @param key key
* @param entry 要存储的Entry
*/
void put(String key, Entry entry);
/**
* 执行任何具有潜在长期运行特性的动作之前,必须进行初始化;
* 该方法运行在子线程.
*/
void initialize();
/**
* 刷新Cache中的Entry.
* @param key key
* @param fullExpire 该Entry是否完整过期
*/
void invalidate(String key, boolean fullExpire);
/**
* 从cache中移除一个entry.
* @param key Cache key
*/
void remove(String key);
/**
* 清空cache.
*/
void clear();
/**
* 一个entry的数据和主数据实体bean.
*/
class Entry {
/** 数据区域. */
public byte[] data;
/** cache数据的Etag. */
public String etag;
/** 服务器响应的时间. */
public long serverDate;
/** 资源最后编辑时间. */
public long lastModified;
/** record 的ttl. */
public long ttl;
/** record 的软ttl. */
public long softTtl;
/** 从服务器接收的固定的响应头; 不能为null. */
public Map<String, String> responseHeaders = Collections.emptyMap();
/** 判断该资源是否超时. */
public boolean isExpired() {
return this.ttl < System.currentTimeMillis();
}
/** 返回True如果需要从原数据上刷新. */
public boolean refreshNeeded() {
return this.softTtl < System.currentTimeMillis();
}
}
}代码倒是很简单,毕竟是接口嘛,但是一看我们就知道刚才猜的没错,你看它的get,put,remove等方法都是需要一个key,而value的类型是一个Entry的内部类,这明显就是键值对的操作嘛(以后如果不做特殊说明,本文出现的key均指的是这个Cache操作的key),看来Cache操作的每一个缓存都是Entry类型了,我们把这个Entry的实例就叫做缓存对象更贴切,仔细看看这个缓存对象呗:
- data:是我们数据真正存储的区域,也就是说我们的数据,不论是文字,图片,视频还是什么别的类型,最终都会以byte数组的形式进行缓存,为啥是这种类型呢?通用啊,计算机存储的都是二进制,二进制最常用的形式就是byte数组,那么所有的数据都可以转换程二进制来存储,高啊,真是高啊!
- etag,lastModified:这两个是我们的老朋友,上一章中已经把他们分析烂了
- ttl:用于判断这个资源是不是已经过期超时,这里借鉴了网络路由之间的TTL概念,不懂的就百度一把就理解的差不多了
- serverDate:是服务器把该网络资源返回给我们的时候的时间,这个时间配合上ttl,我们就知道该缓存的有效期了,例如服务器返回资源的时间是3点15,ttl指定的时间是五分钟,那么这个资源的有效期就截至在3点20,就是这么简单,不要想复杂了。
- softTtl:用于判断过期的资源能否再次重用,这些用法等我们分析子类DiskBasedCache的时候就知道是怎么一回事儿了。
ok,内部类分析完了,我们看看方法,那些简单的方法我们就不浪费大家的脑细胞了,我们只看两个有意义的方法:initialize和invalidate.
initialize方法用于对缓存进行初始化,用于做一些缓存使用前的前置工作,大家都使用过AsyncTask吧,这个方法和onPreExecute是一个意思,这样一说大家就知道它的作用了,为啥要有这么一个方法呢?最大的理由是要提高效率,例如我们要操作的是一个基于文件的缓存,那么我们就可以预先把所有的缓存文件读取到内存中,这样等会儿拿缓存的时候就不需要再临时去读取文件了,这样不久提高效率了吗,那么预先读取缓存文件这些工作就是在initialize方法中做的。这个方法的重要性呢就不言而喻了。
invalidate用于对指定的Entry对应的缓存进行刷新,我们已经知道每一个缓存都是有有效期的,那么这个方法就是用于判断缓存是否还处在有效期内,这个方法第二个参数用于指定是否立即让缓存过期,也就是说我们有权利随时让某一个缓存过期,过期之后的缓存会被自动清理掉,省得占用我们的空间。
ok,接口已经分析完了,那接下来我们就来看看它的儿子DiskBasedCache是怎么实现它的吧。
DiskBasedCache
这个类实现了基于磁盘文件进行缓存的机制,也就是说把所有的缓存都以文件的形式存放在指定的一个缓存目录中去,到时候要用的时候我们就不需要联网去获取了,直接从本地地盘中获取,岂不快哉?
我们还是拿代码说话,先看成员变量都有啥:
/**
* Map的Key, CacheHeader键值对
* 初始大小16,加载因子0.75,也就是说超过12个元素就会扩容
* false 基于插入顺序排列元素 true 基于访问顺序排列元素(LRU算法)
*/
private final Map<String, CacheHeader> mEntries = new LinkedHashMap<String, CacheHeader>(16, .75f, true);
/** 当前被使用的总的空间大小(bytes). */
private long mTotalSize = 0;
/** 用于cache的根目录. */
private final File mRootDirectory;
/** 缓存的最大尺寸(bytes). */
private final int mMaxCacheSizeInBytes;
/** 默认最大的缓存尺寸(5MB). */
private static final int DEFAULT_DISK_USAGE_BYTES = 5 * 1024 * 1024;
/** 缓存中的警报线 */
private static final float HYSTERESIS_FACTOR = 0.9f;
/** 当前缓存文件格式的魔法数. */
private static final int CACHE_MAGIC = 0x20150306;看到LinkedHashMap我们就会心一笑,果然是离不开Map啊!下面一一说说这些成员变量:
- mEntries这个LinkedHashMap自然不用说,这就是所有缓存在内存中的存储区域,所用key正是我们在Cache中看到的东西,至于这个CacheHeader我们待会儿再分析,这个LinkedHashMap在构造的时候,设定了初始大小是16个,负载因子.75,accessOrder为true,玄机就在这个accessOrder上,传false是基于插入顺序来排列元素,传true是基于访问顺序排列元素,访问顺序排列意味着啥?意味着已经实现了LRU算法,没错,LRU算法的实现就是这么简单,So Easy!~
- mTotalSize是指当前实际的缓存大小,mMaxCacheSizeInBytes是所允许的最大缓存空间大小,DEFAULT_DISK_USAGE_BYTES是默认缓存空间为5MB,mRootDirectory就是缓存的存储目录,这些东西我们在上一章已经见过。
- HYSTERESIS_FACTOR是缓存警报线,例如我们指定的缓存大小是5MB,如果超过了HYSTERESIS_FACTOR×5MB=4.5MB,就需要进行自动清理,直到缓存大小小于4.5MB才可以。CACHE_MAGIC用于插在缓存文件中间,区分缓存文件的结构,可以理解为一个隔板,把缓存文件的每一部分都隔离开来。
ok,现在我们就来说说这个CacheHeader,这家伙和Entry简直是一模一样啊,没错,你说对了,这个家伙就是Entry克隆出来的,我们可以简单理解成是Entry的实现类或者是装饰模式中的装饰类,因为我们知道,DiskBasedCache是基于磁盘文件进行操作的,那就需要和本地的IO流搭上关系,但是我们看到Cache中的Entry没有一点和IO流有关系的地方,其实这是对的,因为接口设计本来就要抽象和独立嘛,那么我们在实现类DiskBasedCache中又想要把这个Entry写入磁盘或者从磁盘中读取出来,怎么办?最直接的方法就是装饰模式,实现的和Entry一模一样,然后接替或者扩展Entry的功能,所有对Entry的操作最终都会被转化成对CacheHeader的操作,然后让CacheHeader去操作下面的IO流,这个设计很牛B有木有?我们可以画个图理解一下:
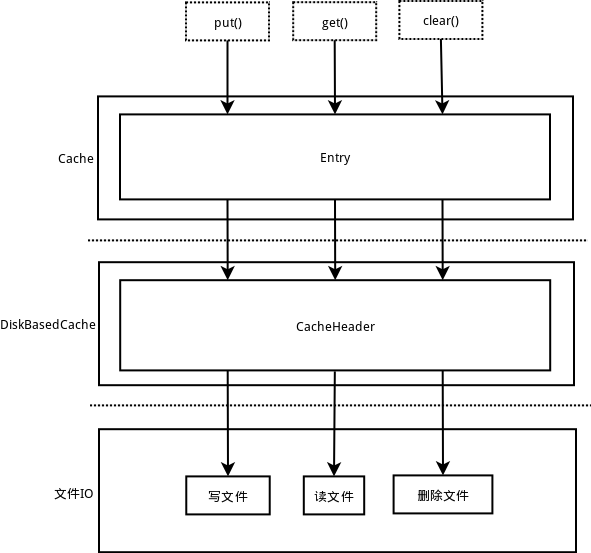
内部类也分析完了,该分析一个个的方法了,现在让我们看看Volley的设计人员是怎么设计一个优秀的基于磁盘的缓存系统的:
- clear:这个方法用于清除所有的缓存,那么就先删文件再清理Map,最后还要把mTotalSize置为0,由此我们可以看出底层的文件和这里的Map是严格保持一致的,不论是在文件大小,数量,还是在增删操作上都严格同步,也只有这样我们才能随时知道当前的缓存情况。
- put方法就有点意思了,上来不急着插入,先来清理一下内存空间,这里使用了pruneIfNeeded方法,这个方法是怎么工作的呢?先看空间能不能够容纳下我们要加入的这个Entry,可以容纳下就没有清理的必要了,否则的话就开始删我们的Map中的元素以及元素对应的文件,每删一次就判断一下空间够不够,够用就停止删除,我们知道Map是已经实现了LRU算法的,所以每次拿出来的都是访问时间最长的元素了,就不用做什么判断直接删除,完了之后返回到put方法中,接着因为我们是新加入的缓存,肯定要创建一个文件啦,那么这个文件名可不是随便乱起的,得保证以后我可以根据key来找到这个文件啊,这里很巧妙的使用了一个二分+Hash的的方法,这样根据key就可以计算出对应的唯一一个文件名,使用这样的文件名有两个好处,一是不容易重复,一个key就对应一个文件名,只要算法不变,到时候找的时候根据key计算出来的就是确定文件名,二是有简单的保密功能,由于Hash有极强的单向性,根据文件名是很难计算出对应的key的,那么如果黑客拿到了我们的缓存文件,短时间他也不能分辨出这一堆二进制文件都是干嘛的。
- get方法就很直白了,先根据key找打CacheHeader,然后找到对应的文件,封装成Entry返回就O了,这里又一次使用到了生成文件名的Hash算法。
- remove就没什么好说的,直接把从Map中删除,然后把文件也删掉就完成了
- 然后我们看看它所实现的initialize方法,果然如我们所料,这个方法就是预先把缓存目录中所有的缓存都预先读取出来了,封装成了CacheHeader对象存放在Map中,它开头那个判断很重要,如果目录是新创建的,就没有必要浪费资源去读取目录了。
- invalidate这个方法相当于抽查过滤,就是查看指定的Entry是否过期了,大家明白意思就好了,不必过多纠结。
- 还有两个私有方法putEntry和removeEntry,是用于直接操作Map的方法,他们更新完Map中的元素之后会顺便更新一下当前的mTotalSize,以便随时了解缓存状况。
- 剩下的一大堆的readXXX,writeXXX我们只需要知道是干嘛的就行了,不需要知道每一行的作用,我们知道DiskBasedCache是向文件读写数据来管理缓存,我们的缓存对象是Entry,这是个Object,怎么写到文件中去呢?如果用Java中的ObjectStream来序列化和反序列化对象,由于大量的使用到了反射,这样的效率简直不敢恭维,于是Volley的开发人员就自己实现了一套对象的IO操作方法,对象说到底还是由数组,整型,字符这些基本类型组成的嘛,于是就有了这些readInt(),writeInt()…,然后每次CacheHeader想要把Entry写入到文件就调用这些方法就行了,Google的大神想法果然与众不同.
好了,我们简单的就把Cache家族的两个类分析完毕了,其实还有一个Cache实现叫NoCache,听名字就是一个空实现,没有分析的必要.Volley的Cache机制果然强大,要不然怎么说人家效率高呢,我们要学习的还有很多啊。
RequestQueue
接下来我们要对付的是Volley中的大妖怪-RequestQueue,这个请求队列我们的仔细把它解剖解剖。
RequestQueue可以认为是Volley中Request的集散地,相当于我们快递公司的集散中心,而且工作流程和非常类似,我们还是先分析成员变量和方法,接着分析它的工作流程,成员变量有这些:
/** Request完成之后的回调接口. */
public interface RequestFinishedListener<T> {
/** Request的处理完成的时候调用这个接口. */
void onRequestFinished(Request<T> request);
}
/** 用于生成请求的单调递增序列号. */
private AtomicInteger mSequenceGenerator = new AtomicInteger();
/**
* 当一个request已经存在一个正在执行的另一个重复request的时候,会被放置到这个中转区域
* <ul>
* <li>containsKey(cacheKey) 方法表示给定的Cache key已经存在一个正在执行的请求.</li>
* <li>get(cacheKey) 返回给定的cache key对应的正在等待执行的请求. 正在执行的请求不包含在返回列表中.如果没有请求被中转则返回null.</li>
* </ul>
*/
private final Map<String, Queue<Request<?>>> mWaitingRequests = new HashMap<String, Queue<Request<?>>>();
/**
* 当前正在被RequestQueue处理的request集合. 任何处于等待队列中的请求或者正在被调度器处理的请求都会被放置于该集合中.
*/
private final Set<Request<?>> mCurrentRequests = new HashSet<Request<?>>();
/** 缓存分类队列. */
private final PriorityBlockingQueue<Request<?>> mCacheQueue = new PriorityBlockingQueue<Request<?>>();
/** 网络分类队列. */
private final PriorityBlockingQueue<Request<?>> mNetworkQueue = new PriorityBlockingQueue<Request<?>>();
/** 网络请求分发器开启的数量,最大同时允许4个线程进行网络请求. */
private static final int DEFAULT_NETWORK_THREAD_POOL_SIZE = 4;
/** 用于检索和存储响应的高速缓存接口. */
private final Cache mCache;
/** 用于执行请求的Network接口. */
private final Network mNetwork;
/** 响应传递机制. */
private final ResponseDelivery mDelivery;
/** 网络调度器. */
private NetworkDispatcher[] mDispatchers;
/** 缓存调度器. */
private CacheDispatcher mCacheDispatcher;
/** 请求完成回调接口的集合 */
private final List<RequestFinishedListener> mFinishedListeners = new ArrayList<RequestFinishedListener>();- 把这个接口RequestFinishedListener放进来是因为我们有一个成员变量是RequestFinishedListener集合,这个接口用于回调Request处理完成的事件,也就是说,外部对象可以通过向RequestQueue设置RequestFinishedListener接口来获取某一个Request执行完毕的结果。
- mSequenceGenerator是一个单调递增的序列号生成器,用于给每一个进到RequestQueue的Request生成一个唯一的整形序列号。
- mWaitingRequests是一个Map,key是String类型,你没看错,这个key就是我们前边分析过的Cache的key,value是一个Queue类型,是一个单列集合。这个Map用于存储所有等待接收网络资源的Request,所以我们暂且称为中转区。
- mCurrentRequests则是所有的Request的存储区域,也就是说凡是进入到当前RequestQueue中的Request都会用mSequenceGenerator给你编个号,然后把你放进mCurrentRequests中等待分类。
- mCacheQueue和mNetworkQueue一个是用于存储那些访问本地缓存就可以得到资源的Request,一个用于存储访问网络获取资源的Request,PriorityBlockingQueue是Java中基于自然排序的队列类,不明白的请自行Google。
- DEFAULT_NETWORK_THREAD_POOL_SIZE用于定义同时进行网络请求的线程数,看起来4个线程足够了。
- mCache是应该而且必须出现在这里的,不论访问缓存还是网络请求都要进行缓存操作,Cache不来行嘛?
- mNetwork也不用说,访问网络进行资源获取怎么少得了它?
- mDelivery是一个响应回递类,我们知道网络请求是在子线程中进行的,当Network执行完毕或者是缓存获取完毕怎么把响应数据传递到主线程中的RequestQueue中来呢?就得靠这个mDelivery,人家可是主线程和子线程的中间人。
- mDispatchers用于访问网络资源的调度器数组,其实不论是NetworkDispatcher网络调度器还是下面的CacheDispatcher缓存调度器都是Thread的子类,也就是说网络调度器允许有多个同时进行,我们这里默认是4个线程,但是这个可以由构造指定,缓存调度器就只有一个,为啥网络的就多一些?因为网络请求慢嘛,多派点人手增加效率嘛,缓存读取多轻松啊,一个人就可以搞定。
接下来就分析成员方法了,构造方法就不说了。
/**
* 开启队列调度.
*/
public void start() {
stop(); // 调用stop以保证当前所有正在运行的调度器都停止掉.
// 创建并开启缓存调度.
mCacheDispatcher = new CacheDispatcher(mCacheQueue, mNetworkQueue, mCache, mDelivery);
mCacheDispatcher.start();
// 根据相应的线程池大小创建网络调度器.
for (int i = 0; i < mDispatchers.length; i++) {
NetworkDispatcher networkDispatcher = new NetworkDispatcher(mNetworkQueue, mNetwork, mCache, mDelivery);
mDispatchers[i] = networkDispatcher;
// 开启网络调度器
networkDispatcher.start();
}
}start方法用于开启这个RequestQueue,我们看到,主要是开启mCacheDispatcher和networkDispatcher这些调度器,让这些调度器去执行mCacheQueue和mNetworkQueue中的Request。
/**
* 关闭缓存和网络调度器.
*/
public void stop() {
if (mCacheDispatcher != null) {
mCacheDispatcher.quit();
}
for (NetworkDispatcher mDispatcher : mDispatchers) {
if (mDispatcher != null) {
mDispatcher.quit();
}
}
}stop和start方法相反,用于停止RequestsQueue,同样也是操作mCacheDispatcher和NetworkDispatcher,而且我们在start方法中也提前调用了一下stop,算是做了一次赛前清扫活动。
getSequenceNumber和getCache过于简单,不说了,我们看看这个东西:
/**
* 一个简单的过滤接口, 用于 {@link RequestQueue#cancelAll(RequestFilter)}.
*/
public interface RequestFilter {
boolean apply(Request<?> request);
}
/**
* 取消此队列中的所有请求,该队列中的所有请求都适用 .
* @param filter 要使用的过滤方法
*/
public void cancelAll(RequestFilter filter) {
synchronized (mCurrentRequests) {
for (Request<?> request : mCurrentRequests) {
if (filter.apply(request)) {
request.cancel();
}
}
}
}
/**
* 取消此队列中带有给定的tag的所有请求, Tag不能为null并且具有平等的标识.
*/
public void cancelAll(final Object tag) {
if (tag == null) {
throw new IllegalArgumentException("Cannot cancelAll with a null tag");
}
// RequestFilter的作用在这里显示出来了
cancelAll(new RequestFilter() {
@Override
public boolean apply(Request<?> request) {
return request.getTag() == tag;
}
});
}这个RequestFilter接口用于过滤Request,所以apply是一个过滤的方法,至于怎么过滤则要看实现类,我们看第二个cancelAll,带Object tag参数的这个,它里边就实现了一个RequestFilter,这里的过滤规则是说Request中的tag要等于传递进来的tag,然后我们在第一个cancleAll中使用这个匿名内部类RequestFilter,凡是符合过滤规则的Request统统干掉,所以这三部分合在一起的意思就是,凡是tag等于Object tag的Request,统统干掉!
/**
* 向调度队列中增加一个Request.
* @param request 要服务的request
* @return 被过滤器认为可以接受的request
*/
public <T> Request<T> add(Request<T> request) {
// 将请求标记为属于这个队列,并将其添加到当前请求的集合中.
request.setRequestQueue(this);
synchronized (mCurrentRequests) {
mCurrentRequests.add(request);
}
// 按照他们被添加的顺序处理这些request.
request.setSequence(getSequenceNumber());
request.addMarker("add-to-queue");
// 如果请求是不可缓存的,跳过缓存队列,直接走网络通信
if (!request.shouldCache()) {
mNetworkQueue.add(request);
return request;
}
// Insert request into stage if there's already a request with the same cache key in flight.
// 如果有一个相同的cache Key的request正在被执行,那么当前这个request就会被安排在中转区域
synchronized (mWaitingRequests) {
// 拿出当前request的key
String cacheKey = request.getCacheKey();
// 查看中转区域中是否存在当前request的key
if (mWaitingRequests.containsKey(cacheKey)) {
// 有一个相同的cache Key的request正在被执行. 把当前的request放进队列中.
Queue<Request<?>> stagedRequests = mWaitingRequests.get(cacheKey);
if (stagedRequests == null) {
stagedRequests = new LinkedList<Request<?>>();
}
stagedRequests.add(request);
// 把队列放进中转区域
mWaitingRequests.put(cacheKey, stagedRequests);
if (VolleyLog.DEBUG) {
VolleyLog.v("Request for cacheKey=%s is in flight, putting on hold.", cacheKey);
}
} else {
// 中转区域中没有该Key对应的请求队列,那么我们这个request就是第一个了。我们直接把key放进中转队列中做键
// 但是要记得我们这第一个request是要被执行的
// 为这个cacheKey插入一个null队列到中转区域, 标记有一个正在执行的请求.
mWaitingRequests.put(cacheKey, null);
// 放进缓存队列中
mCacheQueue.add(request);
}
return request;
}
}add方法很重要,而且也是我们经常使用的方法,它首先会给Request设置一个RequestQueue对象,也就是当前的RequestQueue,等于告诉其他的RequestQueue,这Request是我的,你们都别想了,其次就给这个Request分配了一个序列号,比写上标记”add-to-queue”,并存放在仓库中,等待分类,就像是去澡堂洗澡,拿了手牌,换了衣服,服务员就会说:”XXX号包厢,男宾一位!”。然后就是进行分类,怎么分类的呢?根据Request的shouldCache,如果是true就说明这个Request进缓存队列,否则就进网络队列,那么看来一个Request在创建之后,就应该知道自己是走缓存还是走网络了,要是进缓存队列还不能直接进,还得先判断中转区有没有你这个key,流程是这样的,第一个走缓存的Request判断在中转区有没有对应的key,没有的话,那这个Request就需要在中转区创建一个key的键值对,Queue留null,然后再放它进入mCacheQueue,接着第二个和第三个进来的时候,中转区有对应的key了,把自己放进key对应的Queue,Queue是null怎么办?创建一个呗,反正只有第一个可以进入
mCacheQueue,其余key相同的Request你们都在中转区等着。
/**
* 该方法被 {@link Request#finish(String)}调用, 标记指定的request已经被处理完毕.
* <p>Releases waiting requests for <code>request.getCacheKey()</code> if <code>request.shouldCache()</code>.</p>
*/
<T> void finish(Request<T> request) {
// 从当前正在处理的请求的集合中删除 .
synchronized (mCurrentRequests) {
mCurrentRequests.remove(request);
}
synchronized (mFinishedListeners) {
// 挨个调用每一个FinishListener,告诉他们这个Request已经被执行完毕
for (RequestFinishedListener<T> listener : mFinishedListeners) {
listener.onRequestFinished(request);
}
}
// request需要被缓存的时候,它有可能有相同CacheKey的request被驻留在中转区域
if (request.shouldCache()) {
synchronized (mWaitingRequests) {
// 获取CacheKey
String cacheKey = request.getCacheKey();
// 从中转区域中拿到Key为CacheKey的等待队列
Queue<Request<?>> waitingRequests = mWaitingRequests.remove(cacheKey);
if (waitingRequests != null) {
if (VolleyLog.DEBUG) {
VolleyLog.v("Releasing %d waiting requests for cacheKey=%s.", waitingRequests.size(), cacheKey);
}
// 处理等待队列中所有的requests. 这些request不会再被一一的执行, 他们可以使用我们已经执行完毕的request给他们准备好的Cache.
mCacheQueue.addAll(waitingRequests);
}
}
}
}finish方法是在Request执行完毕之后,mDelivery把它传递到RequestQueue之后调用的,既然Request执行完毕,我们就要把它从mCurrentRequests仓库中移除,然后挨个的调用RequestFinishedListener通知外部对象,说XXX个Request已经执行完毕了,这样还不算完,还记得中转区等待的那群兄弟们嘛?你拿到资源之后,总不能自己抬腿就跑吧,得给大伙分享分享啊,兄弟们我们等你等的好着急啊,mCacheQueue.addAll(waitingRequests)调用就是分享资源的方法。
剩下的addRequestFinishedListener和removeRequestFinishedListener就不用分析了,所以我们已经把RequestQueue的成员和方法分析完毕了,接下来该分析它的执行流程了,具体怎么样执行的呢?
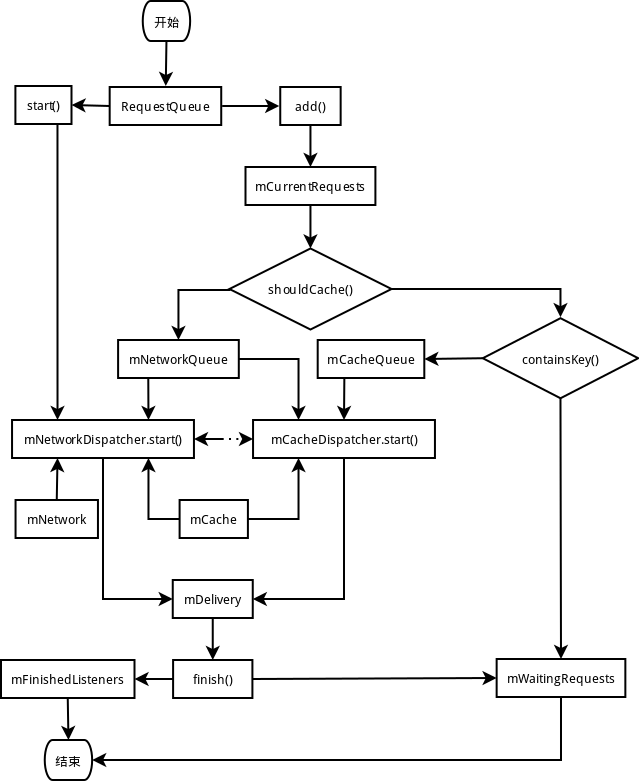
- 首先得先要创建RequestQueue对象,我们在使用的时候就是先创建了一个RequestQueue对象
- 接着调用start方法让两个调度器工作起来,这样整个RequestQueue就运行起来了
- 运行起来还不够,RequestQueue就像一台机器,老空转费油也费电,那就得让他干活,所以我们会调用add方法向里边添加Request
- Request执行完毕之后,会由mDelivery把它从子线程传递过来,则会走我们的finish方法,finish方法将这个执行完毕的Request分发给每个Listener,这样整个流程就执行完了。
有图的话理解起来会更形象,所以我画了张简图,大家凑合着看看吧:
小结
至此我们对Cache家族和RequestQueue也分析完毕了,想必大家对Volley中的缓存和请求队列有了一个比较深入别的认识了,Cache是Volley中高效执行的关键,RequestQueue的合理管理也让我们学到了很多东西,那么接下来的一章我们就再进一步,深入探索一下Volley中请求的调度和执行细节。

















 383
383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









