






行列转换
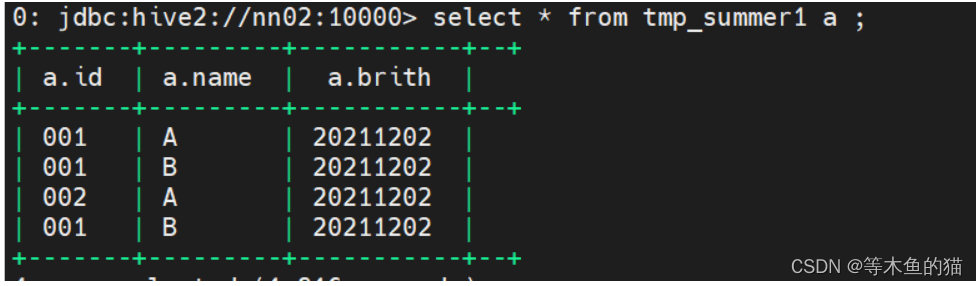
create table tmp_summer1(id string,name string brith string);
insert into tmp_summer1 values('001','A','20211202');
insert into tmp_summer1 values('001','B','20211202');
insert into tmp_summer1 values('002','A','20211202');
insert into tmp_summer1 values('001','B','20211202');
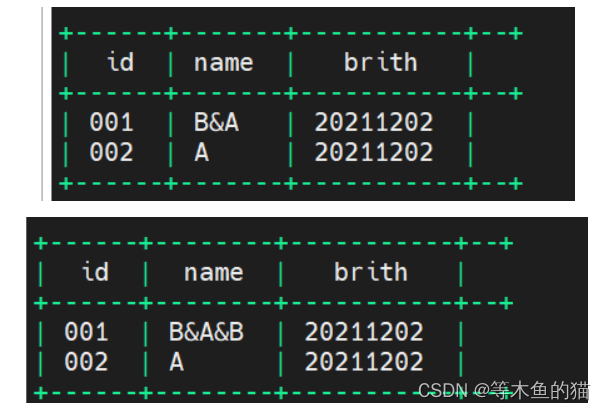
多行合并一行
--collect_set去重
-- 如果字段不是string类型则转: cast(c1 as string)
create table tmp_summer2 as
select id
,concat_ws('&',collect_set(name)) as name
,max(brith) as brith
from tmp_summer1 a
group by id;
--collect_list不去重
select id
,concat_ws('&',collect_list(name)) as name
,max(brith) as brith
from tmp_summer1 a
group by id;
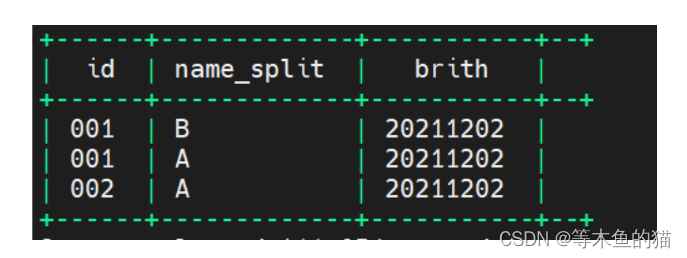
--列转行
create table tmp_summer3 as
select id,name_split,brith
from tmp_summer2
lateral view explode(split(name,'&')) tmpTable as name_split
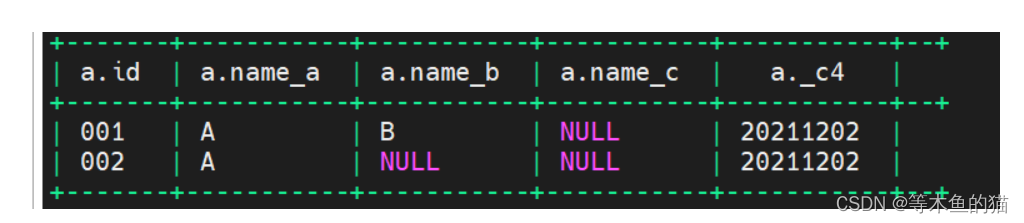
--将一列拆分为多列
create table tmp_summer4 as
select id
,max(case when name_split='A' then name_split else null end) as name_a
,max(case when name_split='B' then name_split else null end) as name_b
,max(case when name_split='C' then name_split else null end) as name_c
,max(brith) as brith
from tmp_summer3
group by id;
解析JSON
-- get_json_object(json_string, '$.key')
-- 功能:解析json的字符串json_string,返回key指定的内容。如果输入的json字符串无效,那么返回NULL。这个函数每次只能返回一个数据项。
SELECT
GET_JSON_OBJECT('{"level":"2","time":1650973942596,"type":"0"}','$.level' ) as level ;
日期函数
2021-09-16 00:00:00 ——> 20210916
to_char(ZHTCJSJ,'yyyymmdd') ——> from_unixtime(unix_timestamp(ZHTCJSJ),'yyyyMMdd')
from_unixtime(unix_timestamp(date1),'yyyyMMdd')
-- 当前日期
select current_date; --// 2021-12-23
select unix_timestamp(); --// 1640224807
-- 建议使用current_timestamp,有没有括号都可以
select current_timestamp(); --// 2021-12-23 09:57:57.638
-- 时间戳转日期
select from_unixtime(1505456567); --//2017-09-15 14:22:47
select from_unixtime(1505456567, 'yyyyMMdd'); --//20170915
select from_unixtime(1505456567, 'yyyy-MM-dd HH:mm:ss'); --// 2017-09-15 14:22:47
-- 日期转时间戳
select unix_timestamp('2019-09-15 14:23:00'); --//1568528580
-- 计算时间差
select datediff('2020-04-18','2019-11-21'); --//149
select datediff('2019-11-21', '2020-04-18'); --//-149
-- 查询该天是该月第几天
select dayofmonth(current_date); --//23
select dayofmonth('2021-12-23'); --//21
-- 计算月末:
select last_day(current_date); --//2021-12-31
select last_day('2021-12-15'); --//2021-12-31
-- 当月第1天:
select date_sub(current_date, dayofmonth(current_date)-1) --//2021-12-01
-- 下个月第1天:
select add_months(date_sub(current_date, dayofmonth(current_date)-1), 1);
--//2022-01-01
-- 字符串转时间(字符串必须为:yyyy-MM-dd格式)
select to_date('2020-01-01');
select to_date('2020-01-01 12:12:12');
-- 日期、时间戳、字符串类型格式化输出标准时间格式
select date_format(current_timestamp(), 'yyyy-MM-dd HH:mm:ss');
select date_format(current_date(), 'yyyyMMdd');
select date_format('2020-06-01', 'yyyy-MM-dd HH:mm:ss');
-- 计算emp表中,每个人的工龄
select *, round(datediff(current_date, hiredate)/365,1) as workingyears
from emp;
字符串函数
-- 转小写。lower
select lower("HELLO WORLD");
-- 转大写。upper
select lower(ename), ename from emp;
-- 求字符串长度。length
select length(ename), ename from emp;
-- 字符串拼接。 concat / ||
select empno || " " ||ename idname from emp;
select concat(empno, " " ,ename) idname from emp;
-- 指定分隔符。concat_ws(separator, [string | array(string)]+)
SELECT concat_ws('.', 'www', array('lagou', 'com'));
select concat_ws(" ", ename, job) from emp;
-- 求子串。substr
SELECT substr('www.lagou.com', 5);
SELECT substr('www.lagou.com', -5);
SELECT substr('www.lagou.com', 5, 5);
-- 字符串切分。split,注意 '.' 要转义
select split("www.lagou.com", "\\.");
数学函数
-- 四舍五入。round
select round(314.15926);
select round(314.15926, 2);
select round(314.15926, -2);
-- 向上取整。ceil
select ceil(3.1415926);
-- 向下取整。floor
select floor(3.1415926);
-- 其他数学函数包括:绝对值、平方、开方、对数运算、三角运算等
条件函数
-- if (boolean testCondition, T valueTrue, T valueFalseOrNull)
select sal, if (sal<1500, 1, if (sal < 3000, 2, 3)) from emp;
-- CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] END
-- 将emp表的员工工资等级分类:0-1500、1500-3000、3000以上
select sal, if (sal<=1500, 1, if (sal <= 3000, 2, 3)) from emp;
-- CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] END -- 复杂条件用 case when 更直观
select sal, case when sal<=1500 then 1
when sal<=3000 then 2
else 3 end sallevel
from emp;
-- 以下语句等价
select ename, deptno,
case deptno when 10 then 'accounting'
when 20 then 'research'
when 30 then 'sales'
else 'unknown' end deptname
from emp;
select ename, deptno,
case when deptno=10 then 'accounting'
when deptno=20 then 'research'
when deptno=30 then 'sales'
else 'unknown' end deptname
from emp;
-- COALESCE(T v1, T v2, ...)。返回参数中的第一个非空值;如果所有值都为 NULL,那么返回NULL
select sal, coalesce(comm, 0) from emp;
-- isnull(a) isnotnull(a)
select * from emp where isnull(comm);
select * from emp where isnotnull(comm);
-- nvl(T value, T default_value)
select empno, ename, job, mgr, hiredate, deptno, sal + nvl(comm,0) sumsal from emp;
-- nullif(x, y) 相等为空,否则为a
SELECT nullif("b", "b"), nullif("b", "a");
UDTF
User Defined Table-Generating Functions
用户定义表生成函数,一行输入,多行输出
-- explode,炸裂函数
-- 就是将一行中复杂的 array 或者 map 结构拆分成多行
select explode(array('A','B','C')) as col;
select explode(map('a', 8, 'b', 88, 'c', 888));
-- UDTF's are not supported outside the SELECT clause, nor nested in expressions
-- SELECT pageid, explode(adid_list) AS myCol... is not supported
-- SELECT explode(explode(adid_list)) AS myCol... is not supported
-- lateral view 常与 表生成函数explode结合使用
-- lateral view 语法:
--Lateral View 用于和UDTF函数【explode,split】结合来使用。
--首先通过UDTF函数将数据拆分成多行,再将多行结果组合成一个支持别名的虚拟表。
--主要解决在select使用UDTF做查询的过程中查询只能包含单个UDTF,不能包含其它字段以及多个UDTF的情况。
lateralView: LATERAL VIEW udtf(expression) tableAlias AS columnAlias (',' columnAlias)*
fromClause: FROM baseTable (lateralView)*
-- lateral view 的基本使用
with t1 as (
select 'OK' cola, split('www.lagou.com', '\\.') colb
)
select cola, colc from t1 lateral view explode(colb) t2 as colc;
窗口函数
窗口函数用于计算基于组的某种聚合值,它和聚合函数的不同之处是:对于每个组返回多行,而聚合函数对于每个组只返回一行
over() 开窗
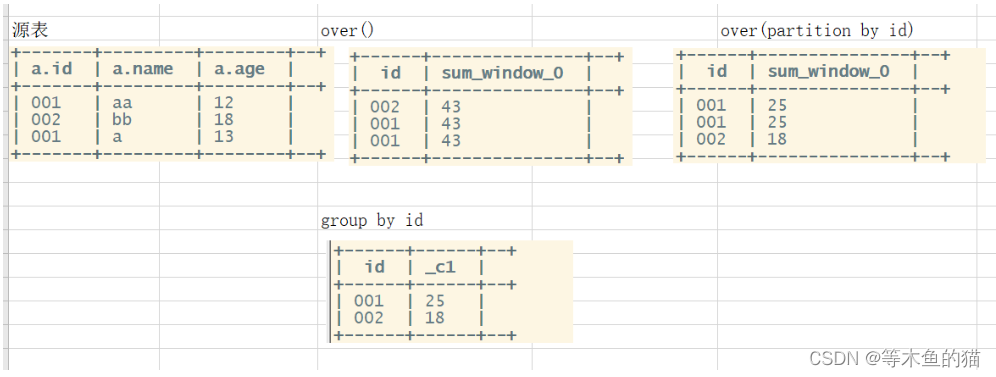
select sum(age) from tb1;
错误: select id,sum(age) as sum_age from tb1;
--窗口函数是针对每一行数据的,如果over中没有参数,默认的是全部结果集
select id,sum(age) over() as sum_age from tb1;
--在over窗口中进行分区,对某一列进行分区统计,窗口的大小就是分区的大小
select id,sum(age) over(partition by id) as sum_age from tb1;
-- order by
select id
,sum(age) over(partition by id order by age) as sum_age
from tb1;
--Window子句 rows between ... and ...
select id
,sum(age) over(partition by id order by age
between 1 preceding and 1 following) as sum_age
from tb1;
排名函数
row_number()。排名顺序增加不会重复;如1、2、3、4、… …
rank()。 排名相等会在名次中留下空位;如1、2、2、4、5、… …
dense_rank()。 排名相等会在名次中不会留下空位 ;如1、2、2、3、4、… …
select id,name,age
,row_number() over(partition by id order by age desc) as rank1
,rank() over(partition by id order by age desc) as rank2
,dense_rank() over(partition by id order by age desc) as rank3
from tb1;
序列函数
lag。返回当前数据行的上一行数据
lead。返回当前数据行的下一行数据
first_value。取分组内排序后,截止到当前行,第一个值
last_value。分组内排序后,截止到当前行,最后一个值
ntile。将分组的数据按照顺序切分成n片,返回当前切片值
select id, name, age,
ntile(2) over(partition by id order by age) as ntile
from tb1;
with tmp as (
select id, name, age,
dense_rank() over (partition by id order by age desc) as rank
from tb1)
select id, score, rank,
nvl(score - lag(score) over (partition by class order by score desc), 0) lagscore
from tmp
where rank<=3;
with as
--WITH AS 语句可以为一个子查询语句块定义一个名称,功能类似临时表
-- with子句只能被select查询块引用
-- with子句的返回结果存到用户的临时表空间中,只做一次查询,反复使用,提高效率
-- 在同级select前有多个查询定义的时候,第1个用with,后面的不用with,并且用逗号隔开
-- 最后一个with 子句与下面的查询之间不能有逗号,只通过右括号分割,with 子句的查询必须用括号括起来
--相当于建了两个临时表a和b
with
a as (select * from tb1),
b as (select * from tb2)
select * from a, b where a.id = b.id;















 198
198











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









