






前言
这篇文写的有点子啰嗦,甚至为了控制篇幅我还分出了其他好几篇文章,只在本文中保留了我认为必须存在。而之所以篇幅这么长,一方面是我在相关领域完全新手,啥啥都不会;而另一方面是我所参考的资料都过于精简,以至于遇到点问题,我就这是啥啊这是的大惊小怪;还有就是我偶发性的莫名其妙的头铁,以至于本应在前置解决的问题,但因为参考资料语焉不详,我选择性略过,已至于后期在bug里沉沦(写文顺序经过调整,如果看到不这样就会报啥错类似的话,那就是我在这里已经踩过坑了)。不过好在经过时间的洗礼,我也总算是取得了阶段性的胜利!
前置准备工作
SSH命令
vi文本编辑器
linux 命令
tmux 命令
tmux 是一个开源的终端复用器,用于在一个窗口中访问多个独立的终端会话。它允许用户在多个虚拟终端、窗口和窗格之间分割屏幕,并且可以轻松地在它们之间切换。tmux 还支持会话的持久化,这意味着即使关闭终端或重启系统,你的工作会话也可以被保存和恢复。
安装docker
更新现有的包列表:
apt updateapt-get update这一步有可能会如图
 报错:
报错:
Err:1 https://mirrors.tuna.tsinghua.edu.cn/debian bullseye InRelease
Cannot initiate the connection to mirrors.tuna.tsinghua.edu.cn:443 (2402:f000:1:400::2). - connect (101: Network is unreachable) Could not connect to mirrors.tuna.tsinghua.edu.cn:443 (101.6.15.130), connection timed out
Err:2 https://mirrors.tuna.tsinghua.edu.cn/debian bullseye-updates InRelease
Cannot initiate the connection to mirrors.tuna.tsinghua.edu.cn:443 (2402:f000:1:400::2). - connect (101: Network is unreachable)
Err:3 https://mirrors.tuna.tsinghua.edu.cn/debian bullseye-backports InRelease
Cannot initiate the connection to mirrors.tuna.tsinghua.edu.cn:443 (2402:f000:1:400::2). - connect (101: Network is unreachable)
Err:4 https://mirrors.tuna.tsinghua.edu.cn/debian-security bullseye-security InRelease
Cannot initiate the connection to mirrors.tuna.tsinghua.edu.cn:443 (2402:f000:1:400::2). - connect (101: Network is unreachable)遇到这个错误先ping一下查看网络情况,是否可用
 好样的,ping不通,先解决网络问题再继续往下吧
好样的,ping不通,先解决网络问题再继续往下吧
网络问题修复好,先重启下网络服务
systemctl restart networking.service查看下网络路由表 ,就可以继续往下安装了
route -n安装必要软件包
apt install apt-transport-https ca-certificates gnupg2 lsb-releaseapt-get install apt-transport-https ca-certificates gnupg2 lsb-release这一步我的错误在这里:
gnupg : Depends: gpgv (< 2.2.27-2+deb11u2.1~) but 2.2.40-1.1 is to be installed
E: Unable to correct problems, you have held broken packages.所以就直接卸载掉了不兼容的 gpgv,安装gnupg2。卸载语句:
apt-get remove gpgv添加Docker的GPG密钥:
curl -fsSL https://download.docker.com/linux/debian/gpg | gpg --dearmor -o /etc/apt/keyrings/docker.gpg
chmod a+r /etc/apt/keyrings/docker.gpg
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/debian \
"$(. /etc/os-release && echo "$VERSION_CODENAME")" stable" | \
tee /etc/apt/sources.list.d/docker.list > /dev/null
最后安装
apt-get update
apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin启动Docker服务:
systemctl start docker设置Docker服务开机自启动:
systemctl enable docker验证Docker安装:
docker --version
# Docker version 27.0.3, build 7d4bcd8修改docker管理系统cgroup的方式为systemd
docker、Containerd的cgroup和k8s一致才能正常安装启动k8s
vi /etc/docker/daemon.json
# 编辑文件,增加内容--确保文件格式正确,必要时可以使用JSON工具格式化
{
"exec-opts": [
"native.cgroupdriver=systemd"
],
"registry-mirrors": [
"https://asia-northeast1-docker.pkg.dev"
]
}
# 重启docker
systemctl restart docker
# 或
systemctl daemon-reload && systemctl restart docker
参考:
docker-ce | 镜像站使用帮助 | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
Containerd配置
安装docker时,已安装containerd.io
生成默认配置
containerd config default > /etc/containerd/config.toml修改CgroupDriver为systemd
vi /etc/containerd/config.toml
# [...]
# [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
# [...]
# SystemdCgroup = true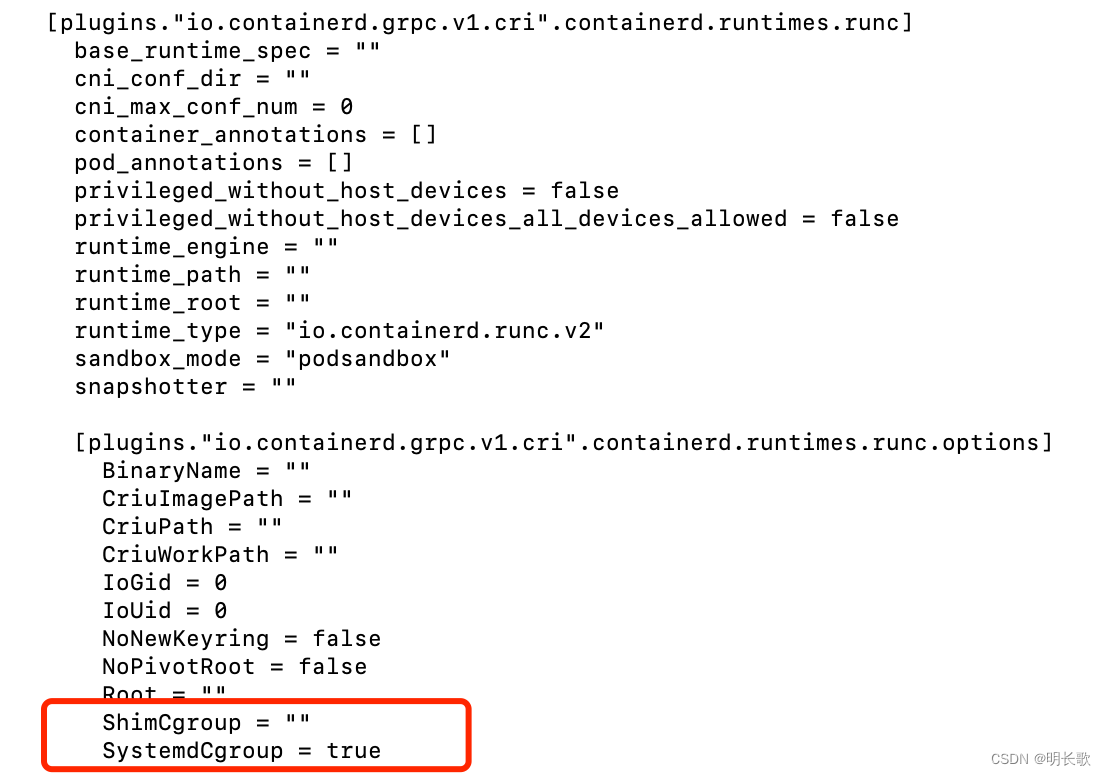
换国内镜像源
# 编辑containerd配置文件
vi /etc/containerd/config.toml
# 编辑内容--换国内源
[plugins."io.containerd.grpc.v1.cri"]
...
sandbox_image = "registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.8"
# 没有换源可能导致systemctl status kubelet.service输出
# couldn't get current server API group list: Get "http://localhost:8080/api?timeout=32s": dial tcp [::1]:8080: connect: connection refused这类错误
#用journalctl -u kubelet 进一步检查输出:【RunPodSandbox from runtime service failed" err="rpc error: code = Unknown desc = failed to get sandbox image】
# 沙盒镜像获取失败,此时需要换成国内源
重启containerd
# 重启
systemctl restart containerd
# 设置开机启动
systemctl enable containerd --now
# 查看
systemctl status containerd安装k8s相关
安装kubeadm
在 Debian 12 和 Ubuntu 22.04 之前的版本中,/etc/apt/keyrings默认情况下不存在;您可以创建该目录(我的系统不需要)
mkdir -p -m 755 /etc/apt/keyrings
# mkdir: 这是创建新目录的命令。
# -p: 这个选项告诉 mkdir 如果目录的上级目录不存在的话,应该一并创建它们。这样,即使目标目录的路径中包含了不存在的目录,命令也不会报错。
-m: 这个选项后面跟随的参数用来设置新创建目录的权限。
755: 这是一个八进制数,用来设置文件或目录的权限。在这种情况下,它表示目录所有者具有读、写和执行权限(7),组用户和其他用户具有读和执行权限(5)。
#这个命令通常在安装软件包或添加新的软件源之前使用,以确保有正确的权限设置,APT 可以访问这些密钥环。下载用于 Kubernetes 软件包仓库的公共签名密钥
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.30/deb/Release.key | gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg添加 Kubernetes apt 仓库
echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.30/deb/ /' | tee /etc/apt/sources.list.d/kubernetes.list更新 apt 包索引,安装 kubelet、kubeadm 和 kubectl,并锁定其版本:
apt-get update
apt-get install -y kubelet kubeadm kubectl
apt-mark hold kubelet kubeadm kubectl
# apt-mark hold 命令用于将指定的软件包标记为“hold”,这意味着这些软件包将不会被自动更新。这对于你想要固定在当前版本的软件包非常有用,比如在 Kubernetes 集群中,你可能想要保持 kubelet、kubeadm 和 kubectl 的版本一致,以避免自动更新可能导致的兼容性问题。查看kubeadm config init和join的默认配置
kubeadm config print init-defaults
kubeadm config print join-defaults生成 kubeadm-config,并修改配置参数
# 生成默认配置
kubeadm config print init-defaults > kubeadm-config.yaml
# 查看编辑kubeadm-config.yaml
vi kubeadm-config.yaml
# 增加或修改cgroup配置
---
kind: KubeletConfiguration
apiVersion: kubelet.config.k8s.io/v1beta1
cgroupDriver: systemd
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs
# 重启
systemctl daemon-reload && systemctl restart kubelet
# 验证配置
kubelet --version查看系统支持的cgroup版本
grep cgroup /proc/filesystems
# nodev cgroup
# cgroup2关闭交换空间
# 检查交换空间状态
swapon --show
# 如果启用了交换空间,你可以使用以下命令临时关闭
swapoff -a
# /etc/fstab 中的交换空间条目
vi /etc/fstab
# 注释掉类似下面这句话
#UUID=xxxx-xxxx-xxxx-xxxx none swap sw 0 0
# 禁用 systemd 的交换空间管理器
systemctl mask swap.target
# 检查交换空间状态
swapon --show
# kubeadm init前关闭交换空间,不需要往下执行-------------------------------------------------
# 如果kubeadm初始化失败,systemctl status kubelet.service输出【command failed" err="failed to run Kubelet: running with swap on is not supported, please"】进行下面步骤
# 重启
systemctl daemon-reload
systemctl restart kubelet.service
# 检查kubelet.service
systemctl status kubelet.service开放必要端口
iptables -A INPUT -p tcp -m multiport --dports 6443,2379,2380,10250 -j ACCEPT
# 查看
iptables -L初始化集群
# 清空kubeadm集群(如果有init失败,需要先清空)
kubeadm reset
rm -rf /var/lib/kubernetes
# 拉取镜像(在这里失败,解决方法是将kubeadm-config.yaml文件中的镜像地址改为本地阿里云地址)
kubeadm config images pull --config kubeadm-config.yaml
# 初始化kubeadm集群
kubeadm init --config kubeadm-config.yaml查看kublet文件(看不看都行)
# 编辑
vi /var/lib/kubelet/config.yaml
# 查看
cat /usr/lib/systemd/system/kubelet.service
[Unit]
Description=kubelet: The Kubernetes Node Agent
Documentation=https://kubernetes.io/docs/
Wants=network-online.target
After=network-online.target
[Service]
ExecStart=/usr/bin/kubelet --config=/var/lib/kubelet/config.yaml
Restart=always
StartLimitInterval=0
RestartSec=10
[Install]
WantedBy=multi-user.target初始化成功:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join 192.168.xx.xxx:6443 --token p8u7wj.188l6nd0lw0bbp2r \
--discovery-token-ca-cert-hash sha256:bf79f2cfc51dae1662dc91a89d034d71759f536addfadedfa8a3102c70c99d65 \
--control-plane
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.xx.xxx:6443 --token p8u7wj.188l6nd0lw0bbp2r \
--discovery-token-ca-cert-hash sha256:bf79f2cfc51dae1662dc91a89d034d71759f536addfadedfa8a3102c70c99d65
查看用户是否为root用户
id -u
# 0
whoami
# root
root用户直接输入命令:
# 手动设置(例如,使用 export 命令),它们不会自动传播到新的会话。
export KUBECONFIG=/etc/kubernetes/admin.confk8s 集群初始化正常,同电脑再开远程窗口通过与初始化正常的链接方式(ssh ip root)链接却访问不到集群的原因:
export KUBECONFIG=/etc/kubernetes/admin.conf当新窗口echo $KUBECONFIG 输出为空,kubectl config view输出没有相应更新内容而初始化成功窗口输出正常时的原因可能是【如果第一个 SSH 会话可以成功访问 Kubernetes 集群,而在新开启的 SSH 会话中环境变量丢失,即使这两个会话都是以 root 用户身份访问相同的 IP 地址,可能的原因包括】:
-
环境变量作用域: 环境变量可能只在原始会话中设置,并没有被导出到所有子会话。在 Bash 中,如果环境变量是在当前会话中设置的(而不是在
.bashrc或.profile中),它将不会影响新开启的会话。 -
SSH 会话配置: SSH 连接可能没有配置为自动加载用户的环境变量。通常,SSH 会话会加载用户的 shell 配置文件,如
.bashrc或.bash_profile,如果这些文件中没有正确设置环境变量,它们就不会被加载。 -
手动设置的环境变量: 如果环境变量是在原始 SSH 会话中手动设置的(例如,使用
export命令),它们不会自动传播到新的会话。 -
不同的 shell: 如果新旧 SSH 会话使用的 shell 类型不同(例如,从 Bash 切换到 zsh 或其他),环境变量的配置方式可能不同。
-
配置文件未被加载: 新 SSH 会话可能没有加载包含环境变量设置的配置文件。
-
权限或策略限制: 某些系统策略或权限设置可能限制了环境变量的传播。
-
SSH Daemon 配置: SSH 服务器的配置可能影响环境变量的传递。
-
使用
sudo或su: 如果你是通过sudo或su切换到 root 用户,环境变量可能不会被正确继承。
配置 k8s 网络插件
按照初始化完成后的提示安装网络插件,这里选用的是calico
# 使用 wget 命令从提供的 URL 下载 calico.yaml 文件。wget 是一个用于从网络上下载文件的命令行工具。
wget https://docs.projectcalico.org/manifests/calico.yaml
# 使用 sed 命令编辑下载的 calico.yaml 文件。
#sed 是一个流编辑器,-i 选项表示直接在原文件上进行编辑。这里的编辑操作是将文件中所有的 192.168.0.0/16 替换为 10.244.0.0/16。
sed -i "s#192\.168\.0\.0/16#10\.244\.0\.0/16#" calico.yaml
# 使用 kubectl 命令将编辑后的 calico.yaml 文件应用到 Kubernetes 集群中。
# kubectl 是 Kubernetes 的命令行工具,apply 命令用于应用一个配置文件,-f 选项表示指定要应用的配置文件。
kubectl apply -f calico.yaml
# 这段代码使得在下载 calico.yaml 文件后,用户可以方便地对其进行网络配置的修改,然后将其应用到 Kubernetes 集群中。通过这种方式,可以简化部署 Calico 网络插件的过程,并且提高了部署的效率和准确性。K8S单机部署节点处理
单机版的k8s安装后, 无法部署服务。因为默认master不能部署pod,有污点, 需要去掉污点或者新增一个node,新增node节点客观条件不是很允许,所以这里直接去除污点。
# 查看节点,有输出说明有节点
kubectl get node -o yaml | grep taint -A 5
# 输出
# taints:
# - effect: NoSchedule
# key: node-role.kubernetes.io/control-plane
# 删除污点,[control-]看上面输出的key路径
kubectl taint nodes --all node-role.kubernetes.io/control-plane-
# 查看节点,无输出,污点删除成功
kubectl get node -o yaml | grep taint -A 5安装部署Rancher
创建应用pv
# 创建pv.yaml
vi pv.yaml
# 编辑pv.yaml文件
# 详细内容见下方链接
# 应用配置
kubectl apply -f pv.yaml
# 验证 PV 是否创建成功
kubectl get pvpv解释以及配置:pv.yaml
安装helm
# 使用脚本安装
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3
chmod 700 get_helm.sh
./get_helm.sh
# 或者直接执行安装(我是直接执行安装失败了,所以才采用上面的方式安装)
curl https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | bash
# 添加 Rancher 的 Helm Chart 仓库:(非生产环境,所以使用最新版)
helm repo add rancher-latest https://releases.rancher.com/server-charts/latest
安装 ingress
Rancher UI 和 API 通过 Ingress 公开。换言之,安装 Rancher 的 Kubernetes 集群必须包含一个 Ingress Controller。
(✘)使用 Helm安装 (安装失败,忽略,看下一个)
# 创建 Ingress Controller 的命名空间:
kubectl create namespace ingress-nginx
# 为 Nginx Ingress Controller 添加 Helm Chart 仓库
helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx
helm repo update
# 使用 Helm 安装 Nginx Ingress Controller-->安装失败
helm upgrade --install ingress-nginx ingress-nginx \
--namespace ingress-nginx \
--set controller.replicaCount=2 \
--set controller.service.type=LoadBalancer \
--set controller.service.externalTrafficPolicy=Local \
--set controller.service.externalIPs=192.168.xx.xxx
# 换一种方式安装
helm repo list #列出当前配置在 Helm 客户端中的所有 Helm 仓库
helm search repo ingress-nginx #用于在已添加到本地 Helm 客户端的 Helm 仓库中搜索特定的关键字
# 输出ingress-nginx/ingress-nginx 4.11.1 1.11.1 Ingress controller for Kubernetes using NGINX a...
helm pull ingress-nginx/ingress-nginx #从指定的 Helm 仓库下载一个特定的 chart 包到本地
tar -xf ingress-nginx-4.11.1.tgz #提取指定的tar包的文件名
tree ingress-nginx -L 1 #输出显示ingress-nginx 目录下的所有第一级项(文件和目录)
# 输出
ingress-nginx
|-- Chart.yaml
|-- OWNERS
|-- README.md
|-- README.md.gotmpl
|-- changelog
|-- ci
|-- templates
|-- tests
`-- values.yaml
# 修改values.yaml(在values.yaml目录下编辑)
cd ingress-nginx
vi values.yaml
# install(在Chart.yaml目录下安装)
helm install ingress-nginx -n ingress-nginx .
# 检查 Ingress Controller Pod 是否成功部署:
kubectl get pods -n ingress-nginx
# 验证 Ingress Controller 服务
kubectl get svc -n ingress-nginx(✓)使用 YAML 清单安装
# 下载官网的deploy.yaml配置文件
wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.11.1/deploy/static/provider/cloud/deploy.yaml
# 镜像拉取(使用docker,自己找个国内镜像网站,拉取版本看deploy.yaml配置)
docker pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/registry.k8s.io/ingress-nginx/controller:v1.11.1
docker pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/registry.k8s.io/ingress-nginx/kube-webhook-certgen:v1.4.1
# 给镜像重命名(可省略,亲测就算重命名,不改原始镜像源,仍然ErrImagePull,所以此步可不要)
docker tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/registry.k8s.io/ingress-nginx/controller:v1.11.1 registry.k8s.io/ingress-nginx/controller:v1.11.1
docker tag swr.cn-north-4.myhuaweicloud.com/ddn-k8s/registry.k8s.io/ingress-nginx/kube-webhook-certgen:v1.4.1 registry.k8s.io/ingress-nginx/kube-webhook-certgen:v1.4.1
# 编辑下载的deploy.yaml配置文件
vi deploy.yaml
# 安装
kubectl apply -f deploy.yaml
# 检查 Ingress Controller Pod 是否成功部署:
kubectl get pods -n ingress-nginx
# 验证 Ingress Controller 服务
kubectl get svc -n ingress-nginx我的deploy.yaml配置
安装默认的ingress class
安装一个默认的ingress class很有必要,我在安装Rancher完成后,自定义域名死活访问不到,一查就是缺少一个默认的ingressClass导致的,原因如下:
# rancher安装完成后,查看。写在此处是为了说明安装一个默认的ingress class的必要
kubectl get ingress -A
# NAMESPACE NAME CLASS HOSTS ADDRESS PORTS AGE
# cattle-system rancher <none> rancher.xxx.com 80, 443 18h生成编辑文件
# 生成class文件
vi ingress-class.yaml
# 编辑文件
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
labels:
app.kubernetes.io/component: controller
name: nginx-ingress
annotations:
ingressclass.kubernetes.io/is-default-class: "true"
spec:
controller: k8s.io/ingress-nginx安装命令
kubectl apply -f ingress-class.yaml删除ingress配置(如果有需要的话)
# 删除 deploy.yaml 文件中定义的所有资源
kubectl delete -f deploy.yaml
# 清理命名空间
kubectl delete namespace <namespace>安装 cert-manager
# 添加 Jetstack Helm 仓库
helm repo add jetstack https://charts.jetstack.io
# 更新本地 Helm Chart 仓库缓存
helm repo update
# 安装 cert-manager Helm Chart
helm install cert-manager jetstack/cert-manager \
--namespace cert-manager \
--create-namespace \
--set installCRDs=true
# 验证
kubectl get pods --namespace cert-manager
# NAME READY STATUS RESTARTS AGE
# cert-manager-5c6866597-zw7kh 1/1 Running 0 2m
# cert-manager-cainjector-577f6d9fd7-tr77l 1/1 Running 0 2m
# cert-manager-webhook-787858fcdb-nlzsq 1/1 Running 0 2m(✘&✓)Helm安装rancher
这里先说明一下,我一开始在本地搭建k8s集群,集群的版本是1.30.0版本,使用helm安装Rancher的时候说不兼容,于是直接采用docker安装Rancher,然后导入1.30.0版本集群(集群导入成功!)但是本着来都来了,用都用了,而且docker安装的Rancher一是自带一个k8s集群倒显得我上面的工作有点多余,二是--privileged令我不大开心。于是,我将k8s集群的版本换成1.28.0后又由helm安装了一遍Rancher。这样Rancher就只需要管理我本地的集群就可以啦!这就是标题旁边又是叉又是勾的原因。
不兼容(Error: INSTALLATION FAILED: chart requires kubeVersion: < 1.29.0-0 which is incompatible with Kubernetes v1.30.0)
# 为 Rancher 创建命名空间
kubectl create namespace cattle-system
# 创建
helm install rancher rancher-latest/rancher \
--namespace cattle-system \
--set hostname=rancher.my.org \
--set bootstrapPassword=admin
删除cattle-system命名空间
# 列出所有 Helm releases
helm list --all-namespaces
# 卸载 Rancher:
helm uninstall rancher -n cattle-system
# 清理 Kubernetes 资源(可选)
kubectl get pvc -n cattle-system
kubectl delete pvc <pvc-name> -n cattle-system
# 检查网络相关资源:
kubectl get ingress,services,lb -n cattle-system
kubectl delete ingress <ingress-name> -n cattle-system
kubectl delete service <service-name> -n cattle-system
# 正常删除失败
kubectl delete namespace cattle-system
# 正常删除失败,命名空间Terminating,执行以下命令
kubectl get ns | grep cattle-system # 查看状态
kubectl get namespace cattle-system -o json | tr -d "\n" | sed "s/\"finalizers\": \[[^]]\+\]/\"finalizers\": []/" | kubectl replace --raw /api/v1/namespaces/cattle-system/finalize -f -
# 检查遗留的 Secrets:
kubectl get secrets -n cattle-system
kubectl delete secret <secret-name> -n cattle-system
# 查看命名空间状态
kubectl get ns | grep cattle-systemkubectl create namespace cattle-system报错: 【Error from server (InternalError): Internal error occurred: failed calling webhook "rancher.cattle.io.namespaces.create-non-kubesystem": failed to call webhook: Post "https://rancher-webhook.cattle-system.svc:443/v1/webhook/validation/namespaces?timeout=10s": service "rancher-webhook" not found】
# 查看rancher.cattle.io
kubectl get MutatingWebhookConfiguration
# NAME WEBHOOKS AGE
# ...
# rancher.cattle.io 7 65m
# 查看rancher.cattle.io
kubectl get ValidatingWebhookConfiguration
# NAME WEBHOOKS AGE
...
rancher.cattle.io 18 66m
...
# 删除rancher.cattle.io
kubectl delete MutatingWebhookConfiguration rancher.cattle.io
# 删除rancher.cattle.io
kubectl delete ValidatingWebhookConfiguration rancher.cattle.io
# 再次创建命名空间成功
kubectl create namespace cattle-systemkubectl get pods -n cattle-system输出:rancher-756b4d88d5-6dstl 0/1 CrashLoopBackOff 5 (17s ago) 4m18s
# 获取错误 Pod 的日志
kubectl logs rancher-756b4d88d5-6dstl -n cattle-system
#输出错误信息:[FATAL] clusters.management.cattle.io is forbidden: User "system:serviceaccount:cattle-system:rancher" cannot list resource "clusters" in API group "management.cattle.io" at the cluster scope
# 创建文件,绑定角色
rancher-cluster-role-binding.yaml
# 文件内容
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: rancher-cluster-binding
subjects:
- kind: ServiceAccount
name: rancher
namespace: cattle-system
roleRef:
kind: ClusterRole
name: cluster-admin
apiGroup: rbac.authorization.k8s.io
# 应用YAML文件
kubectl apply -f rancher-cluster-role-binding.yaml
helm upgrade 命令更新现有安装(未尝试过,慎重,我一般是卸载重新安装)
# 查看命令
helm get values rancher -n cattle-system
# helm upgrade 命令更新现有安装
helm upgrade rancher rancher-latest/rancher \
--namespace cattle-system \
--set hostname=rancher.my.org \
--set bootstrapPassword=admin
使用自定义证书安装
helm install rancher rancher-latest/rancher \
--namespace cattle-system \
--set hostname=rancher.lxq.com \
--set bootstrapPassword=admin \
--set ingress.tls.source=secret \
--set privateCA=true本次在搭建Rancher的本地环境时修改了hosts 文件,手动映射了域名和 IP 地址。这样做可以使用自定义的域名但坏处是如果外部机器想要访问Rancher也需要对域名和ip进行映射。(域名买不起,免费域名也有限制,ngix反向代理啥的,看了看没看懂,所以选择了最简单,最傻瓜的一种)
vi /etc/hosts
[...]
192.168.xxx.xxx rancher.xxx.com外部访问机器使用了clashX Pro做了代理,因此只修改其配置文件即可,没用代理,修改本机hosts文件也行。(我本次搭建的目的纯纯是为了练手,加上一点点的好奇心,重点不在这里。所以生产环境不要这样哦,不过生产环境肯定也有域名了。这里写这么详细,是因为别人一搭就好了而我在这里徘徊良久......)
# 增加
hosts:
"rancher.xxx.com": 192.168.xx.xxx修改本地hosts文件及外部访问机器本地hosts文件后,rancher UI网站仍然不能访问
(✓)Docker 安装Rancher
# 拉取 Rancher 镜像:
docker pull rancher/rancher:latest
# 运行 Rancher 容器--端口被占用
docker run -d --restart=unless-stopped -p 80:80 -p 443:443 rancher/rancher:latest
# 运行 Rancher 容器
docker run -d --privileged --restart=unless-stopped -p 9088:80 -p 9443:443 rancher/rancher:latest
# 登录Rancher
# 打开https://<ip>:9443/dashboard/auth/login,注意一定要是https
# 按照引导登录
# docker ps 查看containerId
# docker logs <containerId> 2>&1 | grep "Bootstrap Password:"生成密码
# 进入引导页,选择随机生成密码:lvRZwoXLldi4Ymsn(自定义密码长度较长,先使用随机密码)
参考
https://code.webterren.com/COAL-Terren/k8s-deploy/src/branch/main/local.md
全网最简单的ingress-nginx安装部署Kubernetes 笔记(10)— Ingress、Ingress Controller、IngressClass 的产生缘由、YAML 描述及使用
















 233
233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









