







注:本文中所有公式和思路来自于邹博先生的《机器学习升级版》,我只是为了加深记忆和理解写的本文。
梯度下降算法我个人认为是极其重要的的一种参数优化手段,因为很常用,也容易理解,不多废话,直接步入主题。
我们在线性回归中,优化参数θ的时候,先是对目标函数求导来计算梯度:
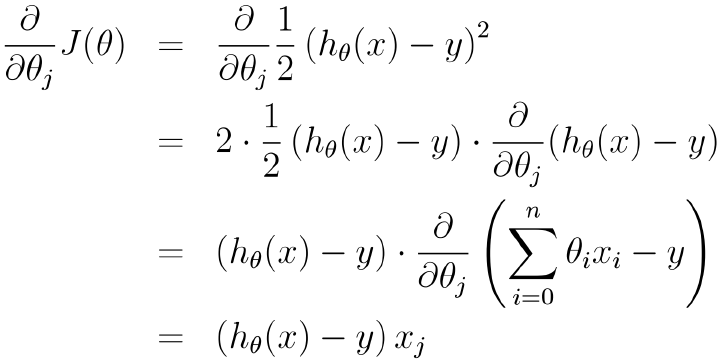
然后我们沿着梯度的方向下降(上升):
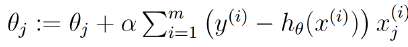
走到这一步似乎问题已经完全解决了,但是学习率α怎么确定呢?是选一个固定呢还是变化的更好呢?
我们直观的想象一下,学习率说白了就是每次梯度下降的大小(并非快慢,快慢是二阶导),那么在参数优化的最初阶段,最优值与当前值的差距较大,我们其实可以将步长调大一点,在迭代后期,使用较小的步长增加稳定度和精度。
我们不妨先仔细思考一下梯度下降的运行过程:
假设某次迭代 xk = a,沿着梯度方向,移动到xk+1 = b,则有:
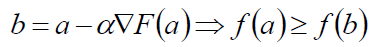
现在假设初始从x0为出发点,每次沿着梯度的反方向移动一定距离得到αk,得到序列:
对应个点直接的关系为:
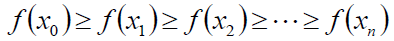
当n达到一定的值后,函数f(x)收敛到局部最小值。
现在我们不妨转换一下视角,记当前点为xk,当前的搜索方向为dk(如:负梯度方向),因为学习率α是待考察的对象,因此,将下列f(xk + αdk)看作是关于α的函数h(α):
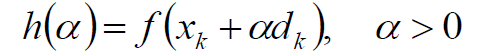
那么当α等于0的时候易得:
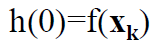
对h(α)求导:
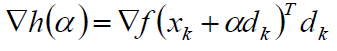
因为梯度下降是寻找f(x)的最小值,那么在xk和dk给定的前提下,就是寻找f(xk + αdk)的最小值:
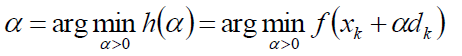
那么我们可以h(α)的导数为0,找到驻点:
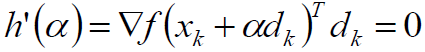
将α等于0代入:
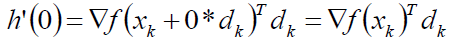
走到这一步不知道你是否会感觉不踏实呢,说实话,我第一次看到这的时候是怎么看怎么觉得不踏实,我们是为了解决一个函数的最值而创造了另一个函数再次求最值,那么就陷入了一个循环了,所以,我们不妨在此步骤打住,进而分析一下,我们首先选择了负梯度方向,那么可得:
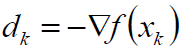
从而可以得到:

那么能够找到足够大的α,使得:
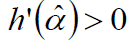
既然一个大于0,一个小于0,必定存在某α:
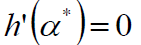
那么这个α*即为我们要找的一个学习率。
既然存在,咋求呢?
线性搜索(Line Search)
这是一种很简单的方式求一个最有学习率的方式:二分线性搜索
具体的做法:
不断将区间[α1,α2]分成两半,选择端点异号的一侧,直到区间足够小或者找到当前最优的学习率。
回溯线性搜索(Backing Line Search)
基于Armijo准测计算收缩方向上的最大步长。
其基本思想是沿着搜索方向移动一个较大的步长估计值,然后以迭代的方式不断缩减步长,直到该步长使得函数值f(xk + αdk)相对于当前函数值f(xk)的减小程度大于预期的期望值(即满足Armijo准则)为止。
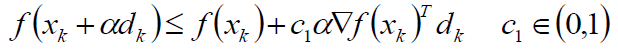
那么回溯线性搜索和二分线性搜索有什么区别呢?
二分线性搜索的目标是求得满足h'(α)≈0的最优步长的近似值,而回溯线性搜索放松了对步长的约束,只要求步长能使函数有一个足够大的变化即可。
除此之外,二分线性搜索可以减少下降次数,但是在计算最优步长上花费的代价很大,回溯线性搜索找到一个差不多的步长即可。
从回溯线性搜索中我们还可以得到更多的思考,那就是插值法。
插值法
我们如果采用了回溯线性搜索,那么手里现在已经有的数据为:
(1): xk处的函数值
(2): xk处的导数值
(3): 再加上第一次尝试的步长α0,如果α0满足条件,显然算法就结束了,如果不满足,那么就可以利用α0构造一个二次近似函数:
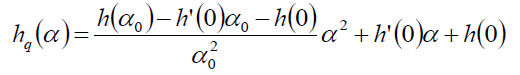
显然导数为0的最优值为:
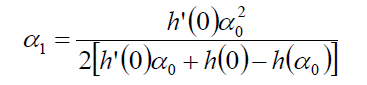
所以接着回溯线性搜索的思路,如果这个α1满足Armijo准则,则输出学习率,否则继续迭代。
到此,线性搜索就介绍完了,当然了我们这一整篇文章都在介绍沿着梯度去下降,那有没有别的方向呢?
下文将介绍沿着其他的方向去下降。















 177
177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









