







谱聚类是一直让我很郁闷的一个聚类方法,因为光知道做法,不知道原理,这样用起来的时候真心很虚,就是很纳闷,为啥这么做就可以呢?
谱聚类是利用相似矩阵或其他派生矩阵的结构特征,将样本划分到不相交类别中,并使类内样本相似度很高,而类别间样本相似度较低的一类技术,是一种启发式的聚类算法。
现在就介绍一下谱聚类的原理吧
由于实体与实体之间的相互作用,产生了大量的复杂数据集,我们可以用数学中的图论的概念来表达这类复杂的数据,其中结点表示的实体,边表示实体之间的的相互作用。
不放我们先简单介绍一点图论的知识吧。
图G由一一系列的结点和边组成,G={V,E},图的结构由邻接矩阵A来表示。
其中如果结点i和j相接,则Aij=1,如果不相接,Aij=0

图既可以是有向的也可以是无向图,无向图的邻接矩阵使对称的,这都比较好理解。
当然了,这里都是用1/0表示两个节点之间是有关系的,我们当然可以对边进行加权,如果联系大的话我们的权值就大,这样的话,我们既可以用距离公式,算两个样本点的距离,那么这个邻接矩阵A就是一个加权边的邻接矩阵,矩阵中的每一个元素也代表着两个样本的距离。
图的拉普拉斯矩阵可由邻接矩阵导出:
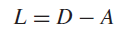
D是对角阵,表示的样本i到其他所有样本的距离的加和:
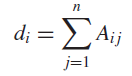
这个di也叫结点i的度,我们现在说一下这个未正则的拉普拉斯矩阵的性质:
a. L是对称半正定的
b. 各特征值为实数且非负,最小值为0,因此,因此,可以将特征值排列:
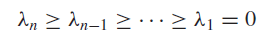
c. 零特征值的个数等于图连接部分的数目,对应的特征向量可以作为一个指示向量,表示给定的结点属于那一部分,我们可以通过一幅图来表示这个特性:
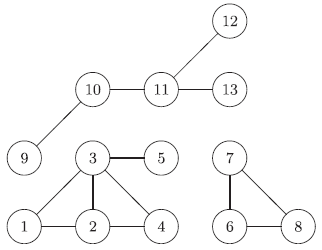
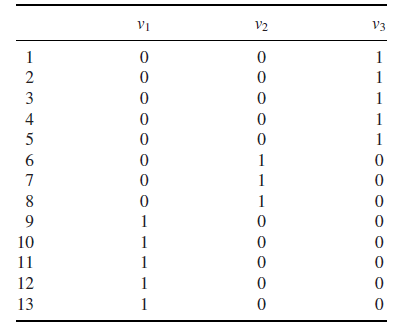
如上图所示,拉普拉斯矩阵0特征值的个数为3个,这就表明其由3个相互分离的部分,同样我们从右边的表中可以看出,12345为一部分,678为一部分,10111213为一部分,因此,特征向量矩阵的行表示出结点属于那一部分。
是不是和聚类有些相近了呢!!!
我们直接套用在聚类框架下来看看这个谱聚类:
a: 定义样本之间的相似度,形成相似度矩阵A
b: 通过相似度矩阵计算拉普拉斯矩阵
c: 对拉普拉斯矩阵进行特征分解,选择前k小的特征值的特征向量,构成n*k维特征向量矩阵
d: 利用K-means算法,将n个按照特征向量行划分的k维样本划分到k个类别中去。
完活,仅此而已,真心不难!!!
另外,我们求相似矩阵的时候,有很多种方式,这里介绍两种:
首先定义两节点边上的权值,这些权值用以衡量两节点的相似性,权值的定义方法也有很多种,我们假定一个邻接矩阵A,矩阵元素Aij = s(xi,xj),
s(xi,xj)是样本x和y之间的相似度。我们设定一个ε邻域,当样本之间的距离小于这个ε邻域是,结点之间就存在一条边:
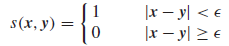
除此之外,我们还可以用高斯相似度来做:
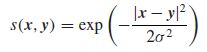
当然了,拉普拉斯矩阵的形式也有三种:
刚刚介绍的那种是未正则的拉普拉斯矩阵,除此之外还有:
规范化拉普拉斯矩阵(正则化拉普拉斯矩阵):
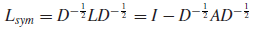
(非对称)随机游走拉普拉斯矩阵:
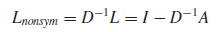
需要注意的是,随机游走拉普拉斯矩阵最终取的是前k大的,而非前k小的。















 2569
2569











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









