







目录
Cache buffers Chain Latch 与Buffer Pin锁
Buffer Cache 内部原理与I/O
HASH链表
HASH链表与逻辑读
hash表结构及关系
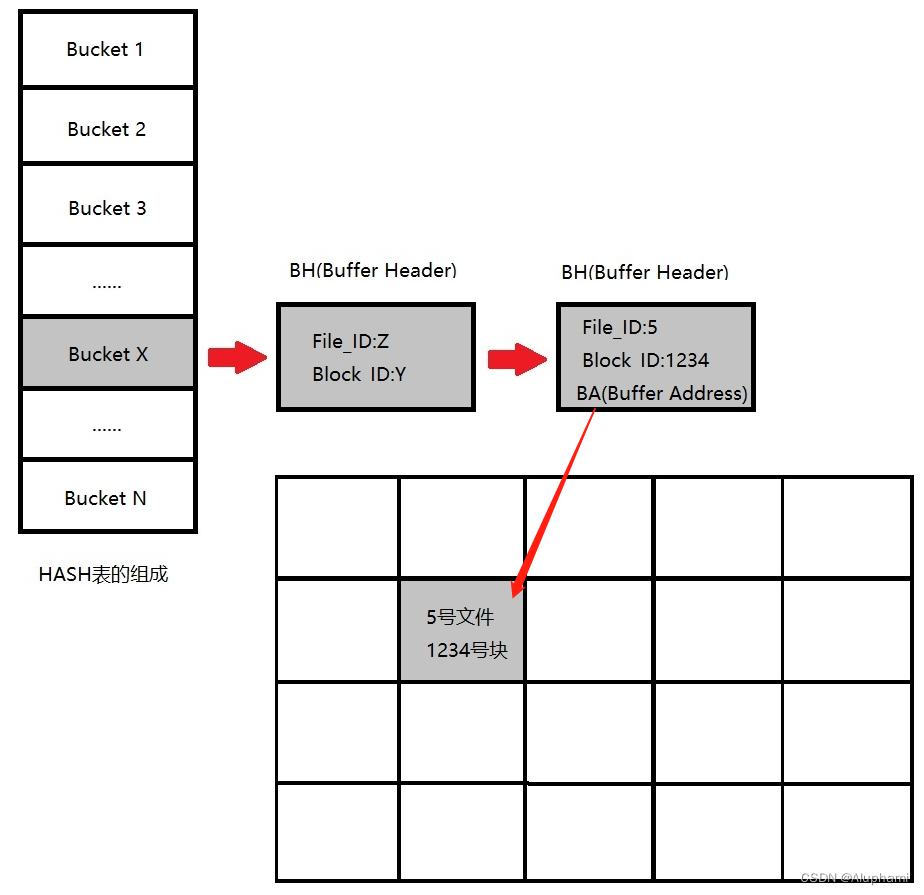
1、每个Bucket中,只保存一个指向CBC(Cache Buffers Cache链表)的链表头
2、Oracle中所有的链表都为双向
3、BH:每一个数据块在被读入buffer cache时,都会先在buffer cache中构造一个buffer header,buffer header与数据块一一对应
4、BA:记录数据块在Buffer Cache中的具体位置
搜索Buffer的步骤
1、进程根据要访问块的文件号、块号,计算hash值
2、根据hash值找到Hash Bucket
3、搜索Bucket后的链表,查找那个BH是目标BH
4、找到目标BH,从中取出Buffer的BA
5、按照BA访问Buffer
hash表中的重要组成部分是Bucket,hash bucket数量由_db_block_hash_buckets参数决定
SQL> col KSPPINM for a30
SQL> col KSPPSTVL for a30
SQL> col KSPPDESC for a50
SQL> SELECT ksppinm, ksppstvl, ksppdesc FROM x$ksppi x, x$ksppcv y WHERE x.indx = y.indx AND ksppinm = '_db_block_hash_buckets';
KSPPINM KSPPSTVL KSPPDESC
------------------------------ ------------------------------ --------------------------------------------------
_db_block_hash_buckets 524288 Number of database block hash buckets
查看buffer header的内容
SQL> select ID,dbms_rowid.rowid_object(rowid) object#,dbms_rowid.rowid_relative_fno(rowid) file#,dbms_rowid.rowid_block_number(rowid) block#,dbms_rowid.rowid_row_number(rowid) row# from t2;
ID OBJECT# FILE# BLOCK# ROW#
---------- ---------- ---------- ---------- ----------
1 100140 4 175 0
2 100140 4 175 1
3 100140 4 175 2
4 100140 4 175 3
SQL> select dbms_utility.make_data_block_address(4,175) from dual;
DBMS_UTILITY.MAKE_DATA_BLOCK_ADDRESS(4,175)
-------------------------------------------
16777391
SQL> alter session set events 'immediate trace name set_tsn_p1 level 5';
Session altered.
SQL> alter session set events 'immediate trace name buffer level 16777391';
Session altered.
SQL> select value from v$diag_info where name like'De%';
VALUE
--------------------------------------------------------------------------------
/u01/app/oracle/diag/rdbms/orcl/orcl1/trace/orcl1_ora_5059.trc
Dump of buffer cache at level 10 for tsn=4 rdba=16777391
BH (0xc5ef30d8)-------BH的hash值 file#: 4 rdba: 0x010000af (4/175) class: 1 ba: 0xc563e000 -------------记录数据块在buffer cache中的位置
set: 6 pool: 3 bsz: 8192 bsi: 0 sflg: 2 pwc: 465,19
dbwrid: 0 obj: 100140 objn: 100140 tsn: 4 afn: 4 hint: f
hash: [0xf0f53358,0xf0f53358]----下一个及前一个BH的hash值,如果这个hash chain上只有一个BH则值一样 lru: [0xc5ef3368,0xceeb0628]--指出下一个及前一个BH的在LRU链上HASH值
ckptq: [NULL] fileq: [NULL] objq: [0xc5ef3390,0xc5efaa30] objaq: [0xc5ef33a0,0xe4354af0]
st: XCURRENT md: NULL fpin: 'ktspbwh2: ktspfmdb' tch: 6 le: 0x69fab1a8
flags: block_written_once redo_since_read
LRBA: [0x0.0.0] LSCN: [0x0.0] HSCN: [0xffff.ffffffff] HSUB: [1]
GLOBAL CACHE ELEMENT DUMP (address: 0x69fab1a8):
id1: 0xaf id2: 0x4 pkey: OBJ#100140 block: (4/175)
lock: X rls: 0x0 acq: 0x0 latch: 1
flags: 0x20 fair: 0 recovery: 0 fpin: 'ktspbwh2: ktspfmdb'
bscn: 0x0.0 bctx: (nil) write: 0 scan: 0x0
lcp: (nil) lnk: [NULL] lch: [0xc5ef3210,0xc5ef3210]
seq: 7 hist: 113 424 180 143:0 325 352 32
LIST OF BUFFERS LINKED TO THIS GLOBAL CACHE ELEMENT:
flg: 0x02200000 state: XCURRENT tsn: 4 tsh: 6
addr: 0xc5ef30d8 obj: 100140 cls: DATA bscn: 0x0.525e50
buffer tsn: 4 rdba: 0x010000af (4/175)
scn: 0x0000.00525e50 seq: 0x01 flg: 0x06 tail: 0x5e500601
frmt: 0x02 chkval: 0xeb0e type: 0x06=trans data
Hex dump of block: st=0, typ_found=1
使用sys用户可以在X$BH中查看与dump类似的信息
select * from x$bh where dbarfil=4 and dbablk=175;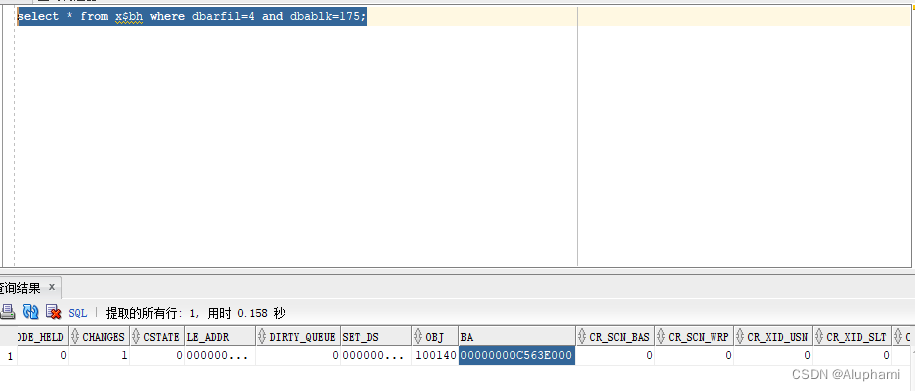
Cache buffers Chain Latch 与Buffer Pin锁

1、CBC Latch为链表前的锁,要访问链表,必须申请获得
2、它不单保护对链表的访问,当链表中找到目标BH后,如果对BH修改的话还要再BH上加锁,这个锁脚BufferPin修改完BufferPin以后,CBC Latch就释放。
3、通常CBC Latch要保护好几个Bucket
CBC Latch持有模式
1、共享
2、独占(修改时为独占)
一般逻辑读过程(独占CBC Latch)
由于读取的时候依旧要修改BH中的BufferPin,因此在申请CBCLatch时依旧为独占模式,修改BufferPin为S(S为共享模式,X为独占模式,默认为0)以后,CBCLatch释放,在BufferPin的保护下,到BH中的BA里找到Buffer地址,读取其中的数据
由于CBCLatch掌管多个Bucket,如果访问的时索引块,频率远高于普通块,就会造成Latch的竞争,为解决这一问题,Oracle采用如下方式解决
1、使用共享模式获得CBCLatch,不对BufferPin进行修改,直接在共享Latch的保护下读取BH中的BA,查询buffer中的数据,查询完毕,释放CBCLatch。
查看CBC Latch占用的内存量(字节)
select to_number (b.addr,'xxxxxxxxxxxxxxxxxxxxx')-to_number(a.addr,'xxxxxxxxxxxxxxxxxxxxx')
from
(select rownum rid,addr from
v$latch_children where
name='cache buffers chains' order by addr) a,
(select rownum rid,addr from
v$latch_children where
name='cache buffers chains' order by addr) b
where a.rid=b.rid+1 and rownum<=1;
字节
TO_NUMBER(B.ADDR,'XXXXXXXXXXXXXXXXXXXXX')-TO_NUMBER(A.ADDR,'XXXXXXXXXXXXXXXXXXXXX')
-----------------------------------------------------------------------------------
200CBC Latch竞争
导致CBClatch竞争的两种情况
1、热链竞争:多个进程频繁地以不兼容模式申请获得某一CBCLatch,访问其保护的不同链表和不同BH
2、热快竞争:多个进程频繁地以不兼容模式申请获得某一CBCLatch,访问其保护的同意链表下的同一BH
热链竞争解决办法
修改_db_block_hash_buckets,和_db_block_hash_latches,他们分别控制hash Bucket数量和CBC Latch数量,修改后BH和hash Bucket的对应关系会被重新计算,原本在同一链表中的BH很可能在重新计算后被分配到不同链表中。
Buffer Pin锁的两种模式:
共享和独占,分别对应读、写两种操作,如果读一个buffer,要先获得共享buffer pin,写的话需要获得独占buffer pin。buffer pin相关的等待事件为Buffer busy wait
Buffer pin的阻塞模式
1、写与写互相阻塞
2、读与写的阻塞模式
10g以后到12c中buffer busy wait做出的改变为读不阻塞写,而写阻塞读
过程如下
1、A进程在BH中成功设置S锁,相应的CBC Latch已经释放
2、B进程想要修改BH的状态,首先获得CBC Latch,
3、并查看BH状态,发现其他进程留下的S锁
4、B进程不会等待,而是在原来的BH上留下一个S锁,并释放小CBC Latch 在S锁的保护下,将原来的BH复制到Buffer Cache里另外的buffer中,此过程叫Buffer Clone,复制完成后释放CBC Latch,此时已在原BH中添加一行STATUS,值为XCUR,克隆目标的BH中STATUS没有值
5、再次获得CBC Latch 在新的BH中设置独占锁,完成后原来BH中STATUS状态为CR(consist read),目标BH状态为CXUR至此克隆完成
6、释放CBC Latch,在X锁下修改对应的Buffer
此时如果来一个C进程也要修改该BH,C进程要在STATUS为CXUR的BH中添加S锁,但是此时该BH为X锁,因此C进程被阻塞,此时等待事件为Buffer Busy Wait
因此造成Buffer Busy Wait的根本原因就是DML语句。
热链竞争模拟
查询测试表u01.t1第一行所在的文件号、块号和rowid
select dbms_rowid.rowid_relative_fno(rowid) file_id,dbms_rowid.rowid_block_number(rowid) block_id,rowid from u01.t1 where rownum=1;
FILE_ID BLOCK_ID ROWID
---------- ---------- ------------------
6 131 AAAYkvAAGAAAACDAAA
查询该块在x$bh表的Latch位置
select hladdr from x$bh where file#=6 and dbablk=131;
HLADDR
----------------
000000015A44B4E0
查询收到该CHC Latch保护的buffer,其中查到的test.t6表为构造出来的模拟表(创建多个表,直到出现与u01.t1表相同Latch)
select file#,dbablk,owner,object_name,b.data_object_id from x$bh a,dba_objects b where hladdr='000000015A44B4E0' and a.obj=b.data_object_id;
FILE# DBABLK OWNER OBJECT_NAM DATA_OBJECT_ID
---------- ---------- --------------- ---------- --------------
4 10904 TEST T6 100646
6 131 U01 T1 100655
利用ROWID_CREATE函数查到test.t6表在改块的第一行
DBMS_ROWID.ROWID_CREATE (
rowid_type IN NUMBER,
object_number IN NUMBER,
relative_fno IN NUMBER,
block_number IN NUMBER,
row_number IN NUMBER)
RETURN ROWID;
select dbms_rowid.rowid_create(1,100646,4,10904,1) from dual;
DBMS_ROWID.ROWID_CREATE(1,100646,4,10904,1)
------------------------------------------------------
AAAYkmAAEAAACqYAAB
按书中开两个会话分别执行如下脚本,查询同意Latch保护下的buffer
declare
r int;
begin
for i in 1..1000000000 loop
select count(*) into r from TEST.T6 where rowid='AAAYkmAAEAAACqYAAB';
end loop;
end;
/
declare
r VARCHAR2(30);
begin
for i in 1..1000000000 loop
select OWNER into r from U01.T1 where rowid='AAAYkvAAGAAAACDAAA';
end loop;
end;
/
查询等待事件发现未出现CBCLatch相关的等待事件
select sid,event,p1raw,p2raw from v$session where wait_class<>'Idle' order by event;
SID EVENT P1RAW P2RAW
----- ------------------------------ ---------------- ----------------
21 SQL*Net message to client 0000000062657100 0000000000000001
原因是我用的版本为11.2.0.4,经查阅资料,在11.2.0.4中已将select语句改为使用CBC Latch共享锁,如果有兴趣可以在之前版本模拟出来。
如果想在11.2.0.4版本模拟出热链竞争,需要使用CBCLatch 独占锁,因此将第二个脚本的select改为update语句即可
重新执行两个脚本
declare
r int;
begin
for i in 1..1000000000 loop
select count(*) into r from TEST.T6 where rowid='AAAYkmAAEAAACqYAAB';
end loop;
end;
/
declare
r VARCHAR2(30);
begin
for i in 1..1000000000 loop
r:='U01'||i
update u01.t1 set OWNER=r where rowid='AAAYkvAAGAAAACDAAA';
end loop;
end;
/
再次查询等待事件即可出现书中结果。其中p1raw表示latch的地址,p2raw表示latch的编号,他们征用的latch的确为000000015A44B4E0。
select sid,event,p1raw,p2raw from v$session where wait_class<>'Idle' order by event;
SID EVENT P1RAW P2RAW
----- ------------------------------ ---------------- ----------------
21 SQL*Net message to client 0000000062657100 0000000000000001
147 latch: cache buffers chains 000000015A44B4E0 00000000000000B1
24 latch: cache buffers chains 000000015A44B4E0 00000000000000B1
9 log file parallel write 0000000000000001 0000000000001CF2
修改_db_block_hash_latches参数并重启数据库,重新分配Latch
SELECT ksppinm, ksppstvl, ksppdesc FROM x$ksppi x, x$ksppcv y WHERE x.indx = y.indx AND ksppinm = '_db_block_hash_latches';
KSPPINM KSPPSTVL KSPPDESC
------------------------------ -------------------- --------------------------------------------------
_db_block_hash_latches 32768 Number of database block hash latches
SQL> alter system set "_db_block_hash_latches" = 65536 scope=spfile;
System altered.
SQL> exit
Disconnected from Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production
With the Partitioning, Real Application Clusters, Automatic Storage Management, OLAP,
Data Mining and Real Application Testing options
[oracle@11rac1 ~]$ srvctl stop db -d orcl
[oracle@11rac1 ~]$ srvctl start db -d orcl
[oracle@11rac1 ~]$ sqlplus / as sysdba
SQL*Plus: Release 11.2.0.4.0 Production on Fri Apr 29 10:06:15 2022
Copyright (c) 1982, 2013, Oracle. All rights reserved.
Connected to:
Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production
With the Partitioning, Real Application Clusters, Automatic Storage Management, OLAP,
Data Mining and Real Application Testing options
SQL> col ksppinm for a30
SQL> col ksppstvl for a20
SQL> col ksppdesc for a50
SQL> set line 200 pagesize 200
SQL> SELECT ksppinm, ksppstvl, ksppdesc FROM x$ksppi x, x$ksppcv y WHERE x.indx = y.indx AND ksppinm = '_db_block_hash_latches';
KSPPINM KSPPSTVL KSPPDESC
------------------------------ -------------------- --------------------------------------------------
_db_block_hash_latches 65536 Number of database block hash latches
查询两个表使其进入buffer,发现两个buffer已不再公用一个Latch
SQL> select count(*) from test.t6;
COUNT(*)
----------
183362
SQL> select count(*) from u01.t1;
COUNT(*)
----------
183362
SQL> select hladdr from x$bh where file#=6 and dbablk=131;
HLADDR
----------------
000000015AA78A68
SQL> select hladdr from x$bh where file#=4 and dbablk=10904;
HLADDR
----------------
000000015AA789A0
重新执行两个脚本,虽然还有等待事件,但已不再争抢CBCLatch
declare
r int;
begin
for i in 1..1000000000 loop
select count(*) into r from TEST.T6 where rowid='AAAYkmAAEAAACqYAAB';
end loop;
end;
/
declare
r VARCHAR2(30);
begin
for i in 1..1000000000 loop
r:='U01'||i
update u01.t1 set OWNER=r where rowid='AAAYkvAAGAAAACDAAA';
end loop;
end;
/
select sid,event,p1raw,p2raw from v$session where wait_class<>'Idle' order by event;
SID EVENT P1RAW P2RAW
----- ------------------------------------------------------------ ---------------- ----------------
147 SQL*Net message to client 0000000062657100 0000000000000001
151 latch: shared pool 000000006010E880 0000000000000150
9 log file parallel write 0000000000000001 0000000000001605
146 log file switch completion 00 00
模拟热快竞争
经过几个版本测试发现从11.2.0.1-11.2.0.3中latch竞争随着版本递进,数量在变少,直到11.2..0.4时,这种情况的latch完全没有了,可能时在版本升级的时候oracle在算法上做了更新
11.2.0.1
创建测试表并插入1行(索引可以创建,但要普通索引)
SQL> create table t1 (c1 int);
Table created.
SQL> insert into t1 values(1);
1 row created.
SQL> commit;
Commit complete.
窗口1,2同时执行命令块,此时卡住,进入等待
declare
n int;
begin
for i in 1 .. 100000000 loop
select c1 into n from t1 where c1=1;
end loop;
end;
/
在窗口3中查看等待事件
SQL> col event for a30
SQL> select sid,event,p1raw,p2raw from v$session where wait_class<>'Idle' order by event;
SID EVENT P1RAW P2RAW
---------- ------------------------------ ---------------- ----------------
410 SQL*Net message to client 0000000062657100 0000000000000001
SQL> /
SID EVENT P1RAW P2RAW
---------- ------------------------------ ---------------- ----------------
410 SQL*Net message to client 0000000062657100 0000000000000001
21 latch: cache buffers chains 0000000120DB2908 0000000000000096
25 latch: cache buffers chains 0000000120DB2908 0000000000000096
可以看到大量 buffers chains
下面掐掉执行的命令块,在t1表上建立唯一索引后重复测试
SQL> create unique index ind_t1 on t1(c1);
Index created.
SQL> select sid,event,p1raw,p2raw from v$session where wait_class<>'Idle' order by event;
SID EVENT P1RAW P2RAW
---------- ------------------------------ ---------------- ----------------
410 SQL*Net message to client 0000000062657100 0000000000000001
21 cursor: pin S 0000000066634CA9 0000001900000001
25 cursor: pin S 0000000066634CA9 0000001500000000
已经变其他竞争,说明目前不存在热快竞争了。
Buffer Busy Wait测试
分别查看当前窗口的SID
SQL> select c.sid,spid,pid,a.SERIAL# from (select sid from v$mystat where rownum<=1) c,v$session a,v$process b where c.sid=a.sid and a.paddr=b.addr;
SID SPID PID SERIAL#
---------- ---------- ---------- ----------
25 26957 42 233
SQL> select c.sid,spid,pid,a.SERIAL# from (select sid from v$mystat where rownum<=1) c,v$session a,v$process b where c.sid=a.sid and a.paddr=b.addr;
SID SPID PID SERIAL#
---------- ---------- ---------- ----------
26 26860 36 255
创建测试表
SQL> create table tb_01 (c1 int);
Table created.
SQL> insert into tb_01 values(1);
1 row created.
SQL> commit;
Commit complete.
查询第一行的ROWID
SQL> select dbms_rowid.rowid_relative_fno(rowid) file_id,dbms_rowid.rowid_block_number(rowid) block_id,rowid from tb_01 where rownum=1;
FILE_ID BLOCK_ID ROWID
---------- ---------- ------------------
1 87481 AAASL5AABAAAVW5AAA
25窗口执行程序块
declare
j int;
begin
for i in 1 .. 3000000 loop
select c1 into j from tb_01 where rowid='AAASL5AABAAAVW5AAA';
end loop;
end;
/
26窗口执行
begin
for i in 1 .. 10 loop
update tb_01 set c1=c1+0 where rowid='AAASL5AABAAAVW5AAA';
end loop;
commit;
end;
/
另开一个窗口查看信息
SQL> select SID,EVENT,TOTAL_WAITS,TOTAL_TIMEOUTS,TIME_WAITED_MICRO/100,TIME_WAITED_MICRO/TOTAL_WAITS/100
2 from v$session_event
3 where sid in(25,26) and event in('buffer busy waits');
SID EVENT TOTAL_WAITS TOTAL_TIMEOUTS TIME_WAITED_MICRO/100 TIME_WAITED_MICRO/TOTAL_WAITS/100
---------- ------------------------------ ----------- -------------- --------------------- ---------------------------------
25 buffer busy waits 1 0 12.21 12.21
可以看到25会话中又buffer busy waits,26会话中执行DML,读不会阻塞写,因此32号会话中没有等待事件
将26号窗口的循环增加到600次
begin
for i in 1 .. 600 loop
update tb_01 set c1=c1+0 where rowid='AAASL5AABAAAVW5AAA';
end loop;
commit;
end;
/
再次查看等待信息
SQL> select SID,EVENT,TOTAL_WAITS,TOTAL_TIMEOUTS,TIME_WAITED_MICRO/100,TIME_WAITED_MICRO/TOTAL_WAITS/100
2 from v$session_event
3 where sid in(25,26) and event in('buffer busy waits');
SID EVENT TOTAL_WAITS TOTAL_TIMEOUTS TIME_WAITED_MICRO/100 TIME_WAITED_MICRO/TOTAL_WAITS/100
---------- ------------------------------ ----------- -------------- --------------------- ---------------------------------
25 buffer busy waits 111 0 22.04 .198558559
26 buffer busy waits 5 0 1.48 .296
除了25号会话中的查询又buffer busy waits外,26号会话中也出现了等待事件
先说结论,等待事件发生在了回滚段的块上
虽然25号会话的查询不会阻塞26号会话,但是当25号会话要读UNDO Block,构造CR块的时候,他会在UNDO Block的buffer上加上更高级别的共享Buffer Pin锁,这种Buffer Pin锁将阻塞26号会话向UNDO Block中写入前映像数据
通过控制事务持续事件长短,可映像构造CR块的次数来进行测试比较
修改程序块为每500条提交一次
在26号窗口执行
begin
for i in 1 .. 60000 loop
update tb_01 set c1=c1+0 where rowid='AAASL5AABAAAVW5AAA';
if mod(i,500) = 0 then
commit;
end if;
end loop;
commit;
end;
/
查看等待事件
SQL> select SID,EVENT,TOTAL_WAITS,TOTAL_TIMEOUTS,TIME_WAITED_MICRO/100,TIME_WAITED_MICRO/TOTAL_WAITS/100
2 from v$session_event
3 where sid in(25,26) and event in('buffer busy waits');
SID EVENT TOTAL_WAITS TOTAL_TIMEOUTS TIME_WAITED_MICRO/100 TIME_WAITED_MICRO/TOTAL_WAITS/100
---------- ------------------------------ ----------- -------------- --------------------- ---------------------------------
25 buffer busy waits 17190 0 1683.78 .097951134
26 buffer busy waits 1062 0 186.76 .175856874
两次结果相减
得知25号会话发生17079次,26号会话有1057次
再次修改程序块改为每条提交
begin
for i in 1 .. 60000 loop
update tb_01 set c1=c1+0 where rowid='AAASL5AABAAAVW5AAA';
commit;
end loop;
commit;
end;
/
查看等待事件
SQL> select SID,EVENT,TOTAL_WAITS,TOTAL_TIMEOUTS,TIME_WAITED_MICRO/100,TIME_WAITED_MICRO/TOTAL_WAITS/100
2 from v$session_event
3 where sid in(25,26) and event in('buffer busy waits');
SID EVENT TOTAL_WAITS TOTAL_TIMEOUTS TIME_WAITED_MICRO/100 TIME_WAITED_MICRO/TOTAL_WAITS/100
---------- ------------------------------ ----------- -------------- --------------------- ---------------------------------
25 buffer busy waits 41235 0 4258.54 .103274888
26 buffer busy waits 1628 0 268.58 .16497543
发现等待事件减少一半
检查点队列链表
检查点队列CKPT-Q
脏块:
和磁盘中的block数据不一致,还没有写到磁盘中的buffer为脏块
DBWR进程:
统一把脏块写入磁盘的进程,这个过程也叫刷新脏块
DBWR刷新脏块的时候需要按照一个链表,这个链表就是buffer的顺序

1、update5号文件中的1234块,首先获得CBC Latch后修改该块为脏块,随后加入CKPT-Q,,被修改时还要记录相应的Redo数据19.1.16为Redo Block Address即RBA,表示19号redo的第1号块的16字节;
2、update5号文件中的4321块,同步骤1一样并把记录放在CKPT-Q的末尾并记录Redo;
3、再次update5号文件的1234块,这是再次修改该块内容,不需要再次持有Checkpoint Queue Latch,并不是每次修改都要持有该Latch,只有在块从不脏变脏的过程才需要它,因此CKPT-Q无需改动,只需要记录redo,因为修改了两次,因此记录了两条redo,第一次记录块由不脏变脏的的redo地址为Low RBA,最后一次产生redo的地址为High RBA,可以看出LRBA的顺序就是CKPT-Q中脏块的顺序。
4、update6号文件。基本同步骤2,只是修改的块和记录的redo不同;
5、写脏块又DBWR进程负责,默认三秒被唤醒一次,如果唤醒以后发现脏块太多,就会开始将脏块写到磁盘中,但是DBWR并不是每次醒来就把所有脏块写入磁盘,假设只写一个脏块,
它会首先获得Checkpoint Quete Latch,然后扫描队列头,并按照队列的顺序写入脏块,当它确定要写脏块后,会把脏块从CKPT-Q中移到对象列(OBJ-Q)中,写完后立即释放Checkpoint Quete Latch,此时5号文件的1234块变为不脏,数据为最后一次修改的值。
RBA内容
新建测试表
SQL> create table tb_rba_01 (c1 varchar2(10));
Table created.
SQL> insert into tb_rba_01 values('ZZZZZZ');
1 row created.
SQL> commit;
Commit complete.
查询所在的文件块
SELECT DBMS_ROWID.rowid_relative_fno(rowid) FNO,dbms_rowid.rowid_block_number(rowid) block_id,dbms_rowid.ROWID_ROW_NUMBER(rowid) row_id,c1 from tb_rba_01;
FNO BLOCK_ID ROW_ID C1
---------- ---------- ---------- ----------
1 117945 0 AAAAAA
1 117945 1 YYYYYY
1 117945 2 XXXXXX
在x$bh中查看信息
select dbablk ,lrba_seq,lrba_bno,flag from x$bh b where file#=1 and dbablk=117945;
DBABLK LRBA_SEQ LRBA_BNO FLAG
---------- ---------- ---------- ----------
117945 0 0 2097152
看下当前的cache low rba和on disk rba
select cplrba_seq,cplrba_bno,cplrba_bof,cpodr_seq,cpodr_bno,cpodr_bof,cphbt,cpodt from x$kcccp where indx=0 ;
CPLRBA_SEQ CPLRBA_BNO CPLRBA_BOF CPODR_SEQ CPODR_BNO CPODR_BOF CPHBT CPODT
---------- ---------- ---------- ---------- ---------- ---------- ---------- --------------------
71 259246 0 71 341124 0 1104865486 06/07/2022 22:01:48
更新数据
update tb_rba_01 set c1='BBBBBB' where c1='AAAAAA';
1 row updated.
commit;
commit complete.
SQL> SELECT DBMS_ROWID.rowid_relative_fno(rowid) FNO,dbms_rowid.rowid_block_number(rowid) block_id,dbms_rowid.ROWID_ROW_NUMBER(rowid) row_id,c1 from tb_rba_01;
FNO BLOCK_ID ROW_ID C1
---------- ---------- ---------- ----------
1 117945 0 AAAAAA
1 117945 1 YYYYYY
1 117945 2 XXXXXX
查看状态变为脏数据
select dbablk ,lrba_seq,lrba_bno,flag from x$bh b where file#=1 and dbablk=117945;
DBABLK LRBA_SEQ LRBA_BNO FLAG
---------- ---------- ---------- ----------
117945 75 24252 2097153
117945 0 0 524288
cache low rba 变为267883
SQL> select cplrba_seq,cplrba_bno,cplrba_bof,cpodr_seq,cpodr_bno,cpodr_bof,cphbt,cpodt from x$kcccp where indx=0 ;
CPLRBA_SEQ CPLRBA_BNO CPLRBA_BOF CPODR_SEQ CPODR_BNO CPODR_BOF CPHBT CPODT
---------- ---------- ---------- ---------- ---------- ---------- ---------- --------------------
75 267883 0 72 92029 0 1104865556 06/08/2022 03:17:44
再次更新数据
update tb_rba_01 set c1='BBBBBB' where c1='AAAAAA';
i row updated.
commit;
commit complete.
lrba没有变,是因为对于一个脏块,只会有一个lrba,直到这个脏块被刷到磁盘
SQL> select dbablk ,lrba_seq,lrba_bno,flag from x$bh b where file#=1 and dbablk=117945;
DBABLK LRBA_SEQ LRBA_BNO FLAG
---------- ---------- ---------- ----------
117945 75 24252 1
117945 0 0 0
117945 0 0 524288
SQL> select cplrba_seq,cplrba_bno,cplrba_bof,cpodr_seq,cpodr_bno,cpodr_bof,cphbt,cpodt from x$kcccp where indx=0 ;
CPLRBA_SEQ CPLRBA_BNO CPLRBA_BOF CPODR_SEQ CPODR_BNO CPODR_BOF CPHBT CPODT
---------- ---------- ---------- ---------- ---------- ---------- ---------- --------------------
75 24211 0 72 24255 0 1104865618 06/08/2022 03:19:44
再过一会儿查看buffer中的内容,可以看到lrba内容已经被清掉,证明此时脏块已经写入磁盘
SQL> select dbablk ,lrba_seq,lrba_bno,flag from x$bh b where file#=1 and dbablk=117945;
DBABLK LRBA_SEQ LRBA_BNO FLAG
---------- ---------- ---------- ----------
117945 0 0 2097152
117945 0 0 0
117945 0 0 524288
查看sequence号为72的redo
SQL> select a.sequence#,a.status,b.member from v$log a,v$logfile b where a.group#=b.group#;
SEQUENCE# STATUS MEMBER
---------- ---------------- ------------------------------
72 CURRENT /oradata/ORCL/redo03.log
71 INACTIVE /oradata/ORCL/redo02.log
70 INACTIVE /oradata/ORCL/redo01.log
dump出这个redo
SQL> alter system dump logfile'/oradata/ORCL/redo03.log';
System altered.
SQL> select c.sid,spid,pid,a.SERIAL# from (select sid from v$mystat where rownum<=1) c,v$session a,v$process b where c.sid=a.sid and a.paddr=b.addr;
SID SPID PID SERIAL#
---------- ------------------------ ---------- ----------
390 8174 50 6901
[oracle@localhost trace]$ ll | grep 8174
-rw-r----- 1 oracle oinstall 88174 Jun 7 16:34 orcl_m003_12766.trc
-rw-r----- 1 oracle oinstall 3054 Jun 7 22:34 orcl_ora_8174.trc
-rw-r----- 1 oracle oinstall 898 Jun 7 22:34 orcl_ora_8174.trm
关于文件号和块号同DBA的转换规则
SQL> variable dba varchar2(30)
SQL> exec :dba :=dbms_utility.make_data_block_address(1,117945);
PL/SQL procedure successfully completed.
SQL> print dba
DBA
--------------------------------
4312249
select
dbms_utility.data_block_address_block(4312249) "BLOCK",
dbms_utility.data_block_address_file(4312249) "FILE"
from dual;
查看里面的内容可以看到块被修改和更新的记录。(这里只截取了第一次修改的部分)再细的东西看不懂了就
....
REDO RECORD - Thread:1 RBA: 0x00004b.00000386.0010 LEN: 0x007c VLD: 0x06 CON_UID: 0
SCN: 0x00000000006a748f SUBSCN: 1 06/08/2022 00:16:56
(LWN RBA: 0x00004b.00000386.0010 LEN: 0x00000001 NST: 0x0001 SCN: 0x00000000006a748f)
CHANGE #1 MEDIA RECOVERY MARKER CON_ID:0 SCN:0x0000000000000000 SEQ:0 OP:23.1 ENC:0 FLG:0x0000
Block Written - afn: 1 rdba: 0x0041ccb9 BFT:(1024,4312249) non-BFT:(1,117945)
scn: 0x00000000006a73ee seq: 2 flg:0x06
....
REDO RECORD - Thread:1 RBA: 0x00004b.00005ebc.0010 LEN: 0x025c VLD: 0x0d CON_UID: 0---------为16进制转换成10进制为24252
SCN: 0x00000000006a93ec SUBSCN: 1 06/08/2022 03:17:15
(LWN RBA: 0x00004b.00005ebc.0010 LEN: 0x00000002 NST: 0x0001 SCN: 0x00000000006a93eb)
CHANGE #1 CON_ID:0 TYP:2 CLS:1 AFN:1 DBA:0x0041ccb9 OBJ:83101 SCN:0x00000000006a73ee SEQ:2 OP:11.19 ENC:0 RBL:0 FLG:0x0000
KTB Redo
op: 0x01 ver: 0x01
compat bit: 4 (post-11) padding: 1
op: F xid: 0x000a.007.000012bf uba: 0x01000405.04c5.09
Array Update of 1 rows:
tabn: 0 slot: 0(0x0) flag: 0x2c lock: 2 ckix: 0
ncol: 1 nnew: 1 size: 0
KDO Op code: 21 row dependencies Disabled
xtype: XAxtype KDO_KDOM2 flags: 0x00000080 bdba: 0x0041ccb9 hdba: 0x0041ccb8
itli: 2 ispac: 0 maxfr: 4863
vect = 0
col 0: [ 6] 4e 4e 4e 4e 4e 4e --------------------修改后数据NNNNNN
CHANGE #2 CON_ID:0 TYP:0 CLS:35 AFN:4 DBA:0x01000110 OBJ:4294967295 SCN:0x00000000006a938d SEQ:1 OP:5.2 ENC:0 RBL:0 FLG:0x0000
ktudh redo: slt: 0x0007 sqn: 0x000012bf flg: 0x0012 siz: 192 fbi: 0
uba: 0x01000405.04c5.09 pxid: 0x0000.000.00000000
CHANGE #3 CON_ID:0 TYP:0 CLS:35 AFN:4 DBA:0x01000110 OBJ:4294967295 SCN:0x00000000006a93ec SEQ:1 OP:5.4 ENC:0 RBL:0 FLG:0x0000
ktucm redo: slt: 0x0007 sqn: 0x000012bf srt: 0 sta: 9 flg: 0x2 ktucf redo: uba: 0x01000405.04c5.09 ext: 2 spc: 6732 fbi: 0
CHANGE #4 CON_ID:0 TYP:0 CLS:36 AFN:4 DBA:0x01000405 OBJ:4294967295 SCN:0x00000000006a938b SEQ:1 OP:5.1 ENC:0 RBL:0 FLG:0x0000
ktudb redo: siz: 192 spc: 6926 flg: 0x0012 seq: 0x04c5 rec: 0x09
xid: 0x000a.007.000012bf
ktubl redo: slt: 7 wrp: 1 flg: 0x0c08 prev dba: 0x00000000 rci: 0 opc: 11.1 [objn: 83101 objd: 83101 tsn: 0]
[Undo type ] Regular undo [User undo done ] No [Last buffer split] No
[Temp object] No [Tablespace Undo ] No [User only ] No
Begin trans
prev ctl uba: 0x01000405.04c5.08 prev ctl max cmt scn: 0x00000000006a8f8b
prev tx cmt scn: 0x00000000006a8f8c
txn start scn: 0x0000000000000000 logon user: 0
prev brb: 0x01000405 prev bcl: 0x00000000
BuExt idx: 0 flg2: 0
KDO undo record:
KTB Redo
op: 0x04 ver: 0x01
compat bit: 4 (post-11) padding: 1
op: L itl: xid: 0x0006.016.000012b5 uba: 0x010007b7.04ef.03
flg: C--- lkc: 0 scn: 0x00000000006a70a4
Array Update of 1 rows:
tabn: 0 slot: 0(0x0) flag: 0x2c lock: 0 ckix: 0
ncol: 1 nnew: 1 size: 0
KDO Op code: 21 row dependencies Disabled
xtype: XAxtype KDO_KDOM2 flags: 0x00000080 bdba: 0x0041ccb9 hdba: 0x0041ccb8
itli: 2 ispac: 0 maxfr: 4863
vect = 0
col 0: [ 6] 41 41 41 41 41 41 --------------------修改前数据AAAAAA
....
检查队列与实例恢复

假设上一操作中宕机,buffer中的内容已经没有,CKPT-Q的内容也没有了,因为CKPT-Q和Redo的顺序时对应的,因此实例恢复的顺序就是Redo中记录的顺序
19.1.16时redo的最开始,它记录着5号文件的1234块,以此类推
那么他从什么地方开始恢复呢?
他是从Redo记录中第一个脏块开始,应为5号文件的1234号块已经写入磁盘,因此它是从19.1.400即5号文件的4321块开始恢复,恢复到19.2.80的时候会怎样呢,首先它最后一次记录的值是BBBBBB,因此它是不需要被恢复,但实际情况是5号文件的1234号块会再次从磁盘中被读到buffer里,并且重新把BBBBBB记录再次写成BBBBBB
因为实例恢复是从CKPT-Q头记录的LRBA位置开始恢复,那么oracle又是从哪里知道LRBA的位置呢,他是通过CKPT进程,CKPT进程没3秒一次,将检查点位置对应的LRBA记录到控制文件中
实例恢复测试
修改tb_rba_01表中的记录
SQL> select * from tb_rba_01;
C1
----------
IIIIII
YYYYYY
XXXXXX
VVVVVV
DDDDDD
SQL> update tb_rba_01 set c1='OOOOOO' where c1='IIIIII';
1 row updated.
SQL> commit;
Commit complete.
在改块处于脏块时模拟宕机
SQL> select dbablk ,lrba_seq,lrba_bno,flag from x$bh b where file#=1 and dbablk=117945;
DBABLK LRBA_SEQ LRBA_BNO FLAG
---------- ---------- ---------- ----------
117945 76 312564 1
117945 0 0 524288
SQL> shutdown abort;
ORACLE instance shut down.
再次启动数据库,oracle会自动进行实例恢复,恢复以后数据库OPEN。
SQL> startup;
ORACLE instance started.
Total System Global Area 771748536 bytes
Fixed Size 8901304 bytes
Variable Size 532676608 bytes
Database Buffers 226492416 bytes
Redo Buffers 3678208 bytes
Database mounted.
Database opened.
SQL> select dbablk ,lrba_seq,lrba_bno,flag from x$bh b where file#=1 and dbablk=117945;
DBABLK LRBA_SEQ LRBA_BNO FLAG
---------- ---------- ---------- ----------
117945 0 0 0
检查alert日志显示数据库从312525处开始实例恢复,一直恢复到312566,而我们脏块在redo的位置时31564,因此可以看出改块已经被写入磁盘
Beginning crash recovery of 1 threads
Thread 1: Recovery starting at checkpoint rba (logseq 76 block 312525), scn 0
2022-06-09T20:40:28.561128-04:00
Started redo scan
2022-06-09T20:40:28.666638-04:00
Completed redo scan
read 20 KB redo, 29 data blocks need recovery
2022-06-09T20:40:28.669513-04:00
Started redo application at
Thread 1: logseq 76, block 312525, offset 0
2022-06-09T20:40:28.670754-04:00
Recovery of Online Redo Log: Thread 1 Group 1 Seq 76 Reading mem 0
Mem# 0: /oradata/ORCL/redo01.log
2022-06-09T20:40:28.690927-04:00
Completed redo application of 0.01MB
2022-06-09T20:40:29.282271-04:00
Completed crash recovery at
Thread 1: RBA 76.312566.16, nab 312566, scn 0x00000000006c7dce
29 data blocks read, 29 data blocks written, 20 redo k-bytes read
2022-06-09T20:40:29.664020-04:00
转储控制文件,可以看到LRBA的记录
SQL> alter session set events 'immediate trace name controlf level 2';
Session altered.
SQL> select c.sid,spid,pid,a.SERIAL# from (select sid from v$mystat where rownum<=1) c,v$session a,v$process b where c.sid=a.sid and a.paddr=b.addr;
SID SPID PID SERIAL#
---------- ------------------------ ---------- ----------
390 30212 33 15098
CHECKPOINT PROGRESS RECORDS
***************************************************************************
(size = 8180, compat size = 8180, section max = 11, section in-use = 0,
last-recid= 0, old-recno = 0, last-recno = 0)
(extent = 1, blkno = 2, numrecs = 11)
THREAD #1 - status:0x2 flags:0x0 dirty:28
low cache rba:(0x4d.2dc1.0) on disk rba:(0x4d.2e0b.0)--------77号redo的11713块
on disk scn: 0x00000000006e1295 06/09/2022 21:39:33
resetlogs scn: 0x00000000001d4fd1 12/06/2021 21:59:04
heartbeat: 1106958286 mount id: 1634695094DBWR如何写脏块

DBWR每3秒醒来后会检查那些块需要写入,评判标准是MTTR即(fast_start_mttr_target)参数,该参数表示用户希望oracle在多长时间内完成实例恢复,如果设置为300,则表示oracle在300秒内恢复。为达到这个目标,oracle会根据所记录的数据库硬件性能,产生的redo量来估算恢复一个脏块锁需要的时间。10g以后MTTR缺省值为0,表示自动调节DBWR写脏块的频率,一般不需要修改,除非数据库写入量很大。
如果一次行写的脏块太多,DBWR不可能将所有脏块进行合并,那么只能分批进行,所以会把块分成多个Batch,单独对每个Batch中的块进行合并,先从第一个Batch开始,这个Batch中的脏块会被移出CKPT-Q,并被移动到各个对象的OBJ-Q中然后再那里进行合并,并写入磁盘。这里共分了3个Batch,在这个Batch被写入磁盘的过程中会产生一个名为db_file_parallel_write的等待事件,所有脏块写入后,等待事件结束,开始下一个Batch,图中由于有3个Batch,因此,他会产生3个等待事件
DBWR在写脏块的时候,会对要写的脏块进行整合,从而在链表中将相邻的脏块合并,例如A、F块,他们虽然在链表中合并,但是在buffer cache中未必相连,因此,为了让他们合并成一个大的I/0,以便一次性写入磁盘,oracle会在share pool中开辟处一块新的空间作为I/O的合并缓冲区,它会把A、F块合并成一个16KB大小的块(默认8KB)来写入,并算作一次I/O,因此无论每次写入的块为多大,都算作一次I/O。通过v$filestat中的phywrts可以查看
创建测试用户到一个新的表空间
SQL> create user dbwr identified by dbwr default tablespace tbs_02;
User created.
SQL> grant dba to dbwr;
Grant succeeded.
SQL> conn dbwr/dbwr;
Connected.
创建测试表
SQL> create table tb_dbwr_01 (c1 varchar2(10));
Table created.
SQL> insert into tb_dbwr_01 values('AAAAAA');
1 row created.
SQL> insert into tb_dbwr_01 values('BBBBBB');
1 row created.
SQL> insert into tb_dbwr_01 values('CCCCCC');
1 row created.
SQL> commit;
Commit complete.
查看数据位置
SQL> SELECT DBMS_ROWID.rowid_relative_fno(rowid) FNO,dbms_rowid.rowid_block_number(rowid) block_id,dbms_rowid.ROWID_ROW_NUMBER(rowid) row_id,c1 from dbwr.tb_dbwr_01;
FNO BLOCK_ID ROW_ID C1
---------- ---------- ---------- ----------
2 398 0 AAAAAA
2 398 1 BBBBBB
2 398 2 CCCCCC
更新表
SQL> update tb_dbwr_01 set c1='ZZZZZZ' where c1='AAAAAA';
1 row updated.
SQL> commit;
Commit complete.
SQL> update tb_dbwr_01 set c1='XXXXXX' where c1='BBBBBB';
1 row updated.
SQL> update tb_dbwr_01 set c1='YYYYYY' where c1='CCCCCC';
1 row updated.
SQL> commit;
Commit complete.
查看BH,此时脏数据还没有写入磁盘
SQL> select dbablk ,lrba_seq,lrba_bno,flag from x$bh b where file#=2 and dbablk=398;
DBABLK LRBA_SEQ LRBA_BNO FLAG
---------- ---------- ---------- ----------
398 77 242070 1
398 0 0 0
398 0 0 0
398 0 0 0
SQL> select a.file#,a.phywrts,b.name from v$filestat a,v$datafile b where a.file#=b.file#;
FILE# PHYWRTS NAME
---------- ---------- --------------------------------------------------
1 1771 /oradata/ORCL/system01.dbf
2 0 /oradata/ORCL/tbs_02.dbf--------------该数据文件写入次数为0
3 6271 /oradata/ORCL/sysaux01.dbf
4 3219 /oradata/ORCL/undotbs01.dbf
5 0 /oradata/ORCL/tbs_01.dbf
7 0 /oradata/ORCL/users01.dbf
8 0 /oradata/ORCL/tbs_03.dbf
9 0 /oradata/ORCL/tbs_04.dbf
10 0 /oradata/ORCL/tbs_05.dbf
此时,脏块写入完成
SQL> select dbablk ,lrba_seq,lrba_bno,flag from x$bh b where file#=2 and dbablk=398;
DBABLK LRBA_SEQ LRBA_BNO FLAG
---------- ---------- ---------- ----------
398 0 0 2097152
398 0 0 0
398 0 0 0
398 0 0 0
查看写入次数此时为2,证明进行了两次IO
SQL> select a.file#,a.phywrts,b.name from v$filestat a,v$datafile b where a.file#=b.file#;
FILE# PHYWRTS NAME
---------- ---------- --------------------------------------------------
1 1786 /oradata/ORCL/system01.dbf
2 2 /oradata/ORCL/tbs_02.dbf
3 6272 /oradata/ORCL/sysaux01.dbf
4 3224 /oradata/ORCL/undotbs01.dbf
5 0 /oradata/ORCL/tbs_01.dbf
7 0 /oradata/ORCL/users01.dbf
8 0 /oradata/ORCL/tbs_03.dbf
9 0 /oradata/ORCL/tbs_04.dbf
10 0 /oradata/ORCL/tbs_05.dbf
查询等待事件,发现没有db_file_parallel_write,是因为数据量小,没有进行分批写入
SQL> select sid,event,TOTAL_WAITS from v$session_event where sid =457;
SID EVENT TOTAL_WAITS
---------- ------------------------------------------------------------ -----------
457 Disk file operations I/O 27
457 control file sequential read 560
457 db file sequential read 6
457 SQL*Net message to client 46
457 SQL*Net message from client 45
457 SQL*Net break/reset to clien t 1
457 events in waitclass Other 69
7 rows selected.如何提高DBWR的写效率
提高DBWR写效率,就是减少块数、次数和Batch,对于写I/O,在块数相同的情况下,如果I/O次数越少,那么每次I/O写的块数就越多,也就是相连的块数越多。这样写的性能就越好。
减少batch有一个隐含参数_db_writer_coalesce_area_size,这个值越大,batch分配的内存就越大,数量就会减少。
SELECT ksppinm, ksppstvl, ksppdesc
FROM x$ksppi x, x$ksppcv y
WHERE x.indx = y.indx
AND ksppinm = '_db_writer_coalesce_area_size';
KSPPINM KSPPSTVL KSPPDESC
------------------------------ ---------- --------------------------------------------------
_db_writer_coalesce_area_size 2097152 Size of memory allocated to dbwriter for coalescin
g writesLRU队列
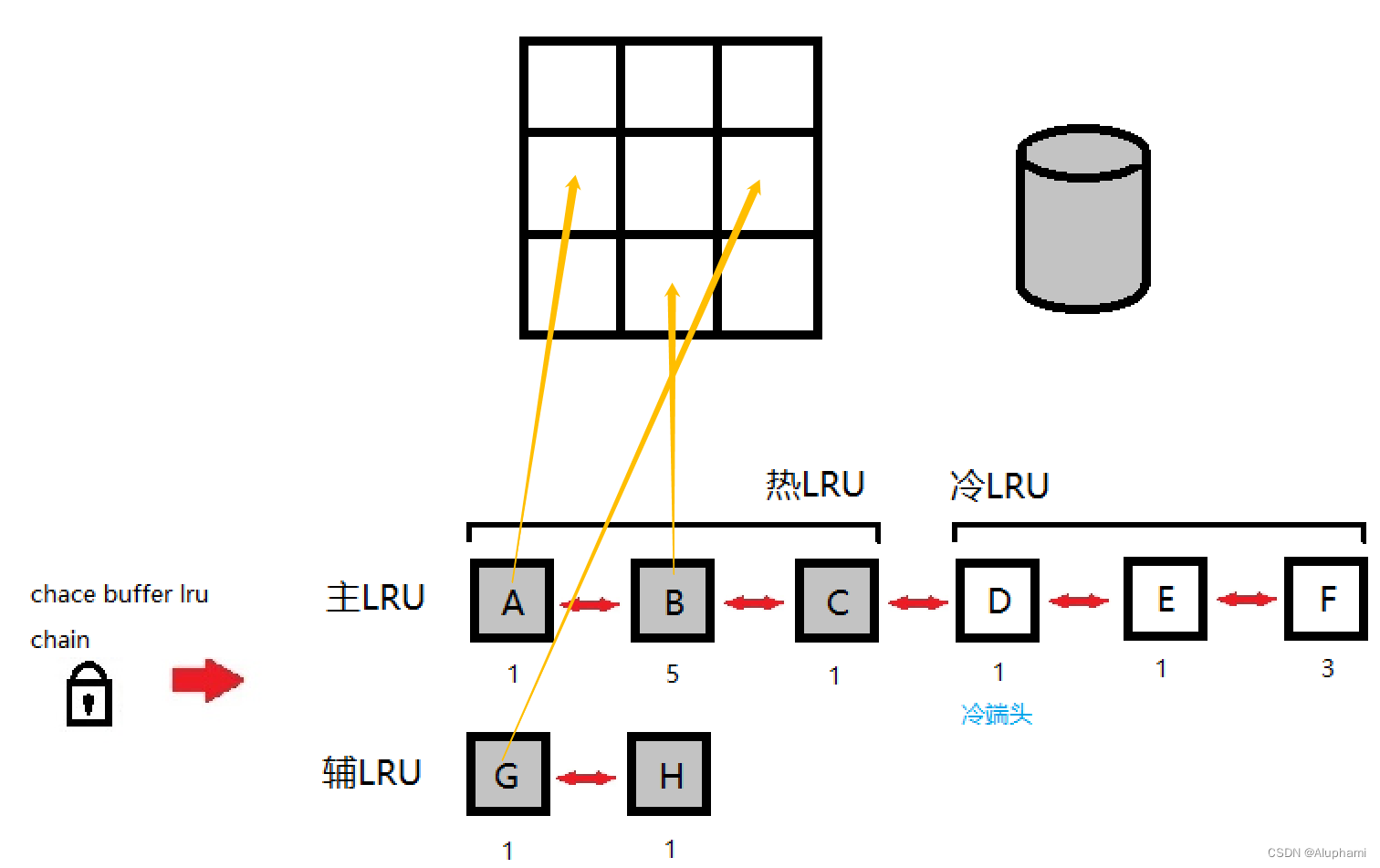
主LRU、辅LRU链表
物理读时,服务器进程要将数据块从文件读进Buffer cache,但是Buffer Cache有限,最不常用的Buffer将被替换掉。
LRU会将Cache中的所有Buffer用两条链来链在一起,主LRU和辅LRU,主LRU又有冷端和热端,同时每个buffer有个访问计数TCH,它以3秒为一个阶段,每个阶段只要有进程访问,它的数值就会加1。
主LRU和辅LRU占比为4:1
第一次物理读
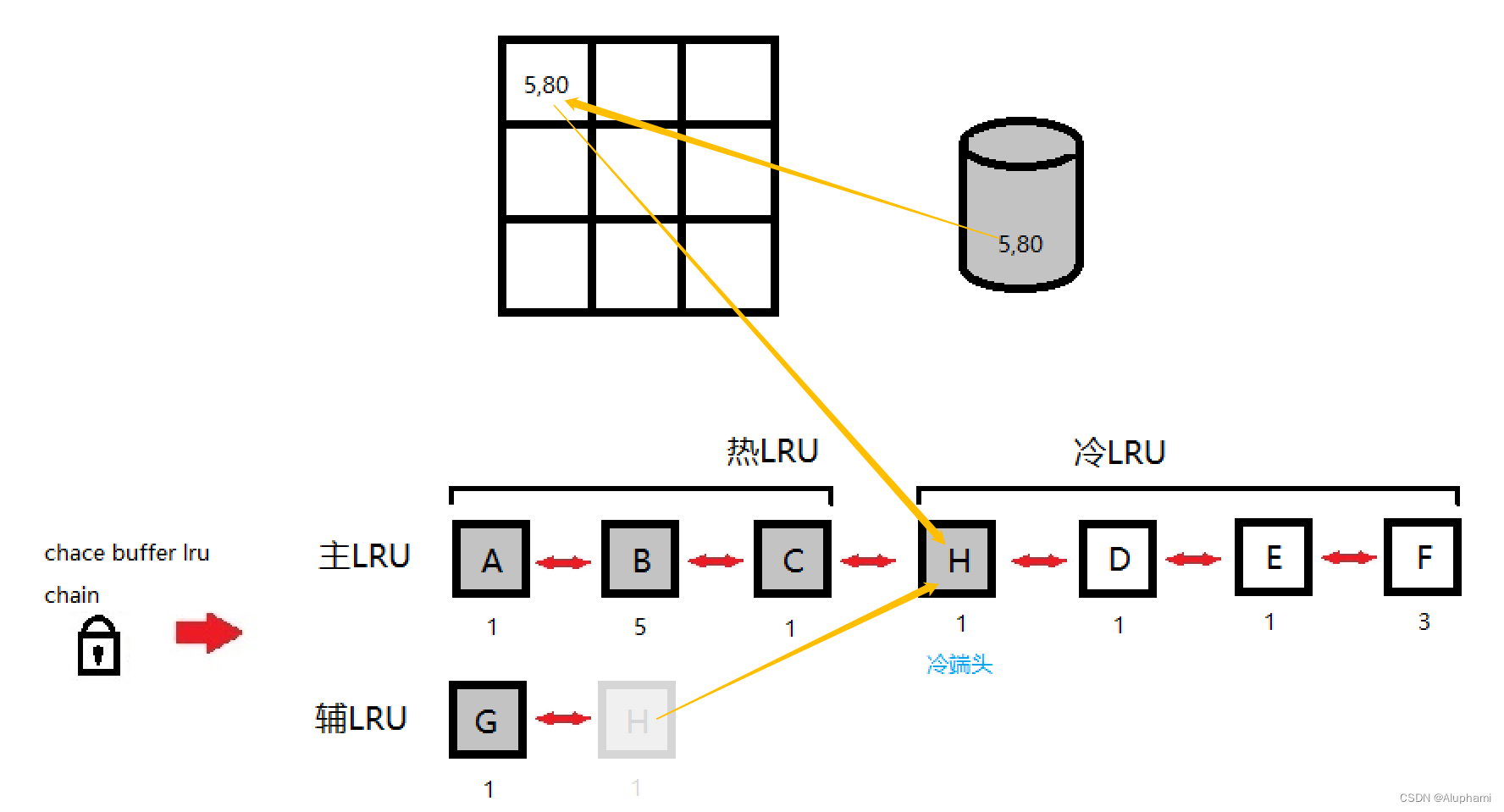
第二次物理读
F块由于TCH为3,因此它被移到热端头,并清零TCH

第三次物理读E为脏块不能覆盖,因此被跳过

总结:
1、进程从辅助LRU链表尾开始搜索可覆盖的块,也叫牺牲者;
2、如果辅助LRU为空,或者辅助LRU链上没有可用的块(都是脏块),将从主LRU冷端尾开始搜索牺牲者;
3、找到可覆盖的牺牲者后,他将移到主LRU的冷端头。它对应的Buffer被新的物理读获得的数据覆盖;
4、脏块会被跳过;
5、在搜索LRU的过程中,遇到TCH大于等于2的Buffer,则会将其移动到热端头,并为了维持主LRU和辅LRU的比例,把热端尾的块移动到冷端头。
查询主辅LRU
SQL> select cnum_set,cnum_repl,anum_repl from x$kcbwds;
CNUM_SET CNUM_REPL ANUM_REPL
---------- ---------- ----------
0 0 0
0 0 0
23912 23912 5939
0 0 0
0 0 0
0 0 0
0 0 0
0 0 0
0 0 0
9 rows selected.
辅LRU所占比例
SQL> select round(sum(ANUM_REPL)/sum(CNUM_SET)*100,2) from x$kcbwds;
ROUND(SUM(ANUM_REPL)/SUM(CNUM_SET)*100,2)
-----------------------------------------
24.86
在x$bh中,LRU_FLAG记录LRU信息
SQL> alter session set events'immediate trace name buffers level 1';
Session altered.
SQL> select lru_flag,count(*) from x$bh group by lru_flag;
LRU_FLAG COUNT(*)
---------- ----------
6 254
8 11955
2 20
4 5443
0 6036
SQL> select file#,dbablk,ba,lru_flag from x$bh where lru_flag=6 and rownum=1;
FILE# DBABLK BA LRU_FLAG
---------- ---------- ---------------- ----------
3 67762 0000000078732000 6
[oracle@localhost trace]$ vi orcl_ora_2241.trc
。。。
BH (0x787f5dd8) file#: 3 rdba: 0x00c108b2 (3/67762) class: 1 ba: 0x78732000
set: 3 pool: 3 bsz: 8192 bsi: 0 sflg: 0 pwc: 0,0
dbwrid: 0 obj: 11508 objn: 11508 tsn: [0/1] afn: 3 hint: f
hash: [0x6c197ab8,0x753ef240] lru: [0x793d6750,0x79be54f8]
lru-flags: moved_to_tail on_auxiliary_list
ckptq: [NULL] fileq: [NULL]
objq: [NULL] objaq: [NULL]
st: CR md: NULL fpin: 'kdiwh15: kdifxs' fscn: 0x0 tch: 1 lfb: 252
cr: [scn: 0x7508cc],[xid: 0x0.0.0],[uba: 0x0.0.0],[cls: 0x7508cc],[sfl: 0x0],[lc: 0x0]
flags:
Printing buffer operation history (latest change first):
cnt: 9
01. sid:07 L940:z_sw_cur:sw:cq 02. sid:07 L070:zswcu:ent:ob
03. sid:07 L082:zcr:ret:TRU 04. sid:07 L145:zib:mk:EXCL
05. sid:07 L212:zib:bic:FSQ 06. sid:07 L122:zgb:set:st
07. sid:07 L830:olq1:clr:WRT+CKT 08. sid:07 L951:zgb:lnk:objq
09. sid:07 L372:zgb:set:MEXCL 10. sid:07 L123:zgb:no:FEN
11. sid:07 L896:z_mkfr:ulnk:objq 12. sid:07 L083:zgb:ent:fn
13. sid:07 L192:kcbbic2:bic:FBD 14. sid:07 L191:kcbbic2:bic:FBW
15. sid:07 L602:bic1_int:bis:FWC 16. sid:07 L822:bic1_int:ent:rtn
。。。
可知LRU_FLAG 6代表是被移动到了辅助链的尾部,而负责移动的进程就是SMON
用同样的方法查看其他状态
SQL> select file#,dbablk,ba,lru_flag from x$bh where lru_flag=8 and rownum=1;
FILE# DBABLK BA LRU_FLAG
---------- ---------- ---------------- ----------
1 5499 0000000079A1C000 8
...
BH (0x79be9a60) file#: 1 rdba: 0x0040157b (1/5499) class: 1 ba: 0x79a1c000
set: 3 pool: 3 bsz: 8192 bsi: 0 sflg: 0 pwc: 0,0
dbwrid: 0 obj: 823 objn: 823 tsn: [0/0] afn: 1 hint: f
hash: [0x6c194c78,0x6c194c78] lru: [0x79be5660,0x77fdece8]
lru-flags: hot_buffer
ckptq: [NULL] fileq: [NULL]
objq: [0x78ff3e90,0x634663f0] objaq: [0x79be5698,0x78ff3ea0]
st: XCURRENT md: NULL fpin: 'qeilwh06: qeilbk' fscn: 0x6ea5b5 tch: 14
flags: block_written_once
LRBA: [0x0.0.0] LSCN: [0x0] HSCN: [0x750c6b] HSUB: [1]
Printing buffer operation history (latest change first):
cnt: 4
01. sid:07 L192:kcbbic2:bic:FBD 02. sid:07 L191:kcbbic2:bic:FBW
03. sid:07 L602:bic1_int:bis:FWC 04. sid:07 L822:bic1_int:ent:rtn
05. sid:07 L832:oswmqbg1:clr:WRT 06. sid:07 L930:kubc:sw:mq
07. sid:07 L913:bxsv:sw:objq 08. sid:07 L608:bxsv:bis:FBW
09. sid:07 L464:chg1_mn:bic:FMS 10. sid:07 L778:chg1_mn:bis:FMS
11. sid:07 L348:get:set:mode 12. sid:07 L464:chg1_mn:bic:FMS
13. sid:07 L778:chg1_mn:bis:FMS 14. sid:07 L348:get:set:mode
15. sid:07 L464:chg1_mn:bic:FMS 16. sid:07 L778:chg1_mn:bis:FMS
BH (0x7a7ef5c8) file#: 1 rdba: 0x0040b02e (1/45102) class: 1 ba: 0x7a69e000
...
SQL> select file#,dbablk,ba,lru_flag from x$bh where lru_flag=2 and rownum=1;
FILE# DBABLK BA LRU_FLAG
---------- ---------- ---------------- ----------
1 51236 000000007CACE000 2
...
BH (0x7cbf1788) file#: 3 rdba: 0x00c0c35a (3/50010) class: 4 ba: 0x7cace000
set: 3 pool: 3 bsz: 8192 bsi: 0 sflg: 0 pwc: 0,0
dbwrid: 0 obj: 84229 objn: 84229 tsn: [0/1] afn: 3 hint: f
hash: [0x7cbe0e70,0x7a3e85f8] lru: [0x72fed658,0x72bd3780]
ckptq: [NULL] fileq: [NULL]
objq: [NULL] objaq: [NULL]
st: CR md: NULL tch: 1 lfb: 255
cr: [scn: 0x75173f],[xid: 0x0.0.0],[uba: 0x0.0.0],[cls: 0x75173f],[sfl: 0x0],[lc: 0x75173f]
flags: only_sequential_access
Printing buffer operation history (latest change first):
cnt: 7
01. sid:11 L122:zgb:set:st 02. sid:11 L123:zgb:no:FEN
03. sid:11 L896:z_mkfr:ulnk:objq 04. sid:11 L083:zgb:ent:fn
05. sid:03 L338:zibmlt:set:MSHR 06. sid:03 L144:zibmlt:mk:EXCL
07. sid:03 L122:zgb:set:st 08. sid:03 L830:olq1:clr:WRT+CKT
09. sid:03 L951:zgb:lnk:objq 10. sid:03 L372:zgb:set:MEXCL
11. sid:03 L123:zgb:no:FEN 12. sid:03 L896:z_mkfr:ulnk:objq
13. sid:03 L083:zgb:ent:fn 14. sid:03 L338:zibmlt:set:MSHR
15. sid:03 L144:zibmlt:mk:EXCL 16. sid:03 L122:zgb:set:st
...
SQL> select file#,dbablk,ba,lru_flag from x$bh where lru_flag=4 and rownum=1;
FILE# DBABLK BA LRU_FLAG
---------- ---------- ---------------- ----------
4 5971 0000000078076000 4
...
BH (0x783d71a8) file#: 4 rdba: 0x01001753 (4/5971) class: 32 ba: 0x78076000
set: 3 pool: 3 bsz: 8192 bsi: 0 sflg: 0 pwc: 0,0
dbwrid: 0 obj: -1 objn: 0 tsn: [0/2] afn: 4 hint: f
hash: [0x6c194c48,0x6c194c48] lru: [0x717f9b38,0x7afe6308]
lru-flags: on_auxiliary_list
ckptq: [NULL] fileq: [NULL]
objq: [0x71bf0ec0,0x7afe6330] objaq: [0x71bf0ed0,0x7afe6340]
st: XCURRENT md: NULL fpin: 'ktuwh03: ktugnb' fscn: 0x7508e5 tch: 1
flags: block_written_once
LRBA: [0x0.0.0] LSCN: [0x0] HSCN: [0x7508e5] HSUB: [1]
Printing buffer operation history (latest change first):
cnt: 16
01. sid:07 L192:kcbbic2:bic:FBD 02. sid:07 L191:kcbbic2:bic:FBW
03. sid:07 L602:bic1_int:bis:FWC 04. sid:07 L822:bic1_int:ent:rtn
05. sid:07 L832:oswmqbg1:clr:WRT 06. sid:07 L930:kubc:sw:mq
07. sid:07 L913:bxsv:sw:objq 08. sid:07 L608:bxsv:bis:FBW
09. sid:07 L607:bxsv:bis:FFW 10. sid:07 L464:chg1_mn:bic:FMS
11. sid:07 L778:chg1_mn:bis:FMS 12. sid:07 L362:chg1:set:MEXCL
13. sid:07 L464:chg1_mn:bic:FMS 14. sid:07 L778:chg1_mn:bis:FMS
15. sid:07 L362:chg1:set:MEXCL 16. sid:07 L464:chg1_mn:bic:FMS
...
SQL> select file#,dbablk,ba,lru_flag from x$bh where lru_flag=0 and rownum=1;
FILE# DBABLK BA LRU_FLAG
---------- ---------- ---------------- ----------
1 45102 000000007A69E000 0
...
BH (0x7a7ef5c8) file#: 1 rdba: 0x0040b02e (1/45102) class: 1 ba: 0x7a69e000
set: 3 pool: 3 bsz: 8192 bsi: 0 sflg: 0 pwc: 0,0
dbwrid: 0 obj: 2 objn: 4 tsn: [0/0] afn: 1 hint: f
hash: [0x6c194cb8,0x6c194cb8] lru: [0x717de748,0x78bd6750]
ckptq: [NULL] fileq: [NULL]
objq: [0x713ec000,0x7c7e1a10] objaq: [0x713ec010,0x7c7e1a20]
st: XCURRENT md: NULL fpin: 'kdswh11: kdst_fetch' fscn: 0x6ea3a4 tch: 7
flags: only_sequential_access
LRBA: [0x0.0.0] LSCN: [0x0] HSCN: [0x0] HSUB: [65535]
Printing buffer operation history (latest change first):
cnt: 4
01. sid:07 L836:z_age_hot:mv:cld 02. sid:06 L836:z_age_hot:mv:cld
03. sid:04 L836:z_age_hot:mv:cld 04. sid:07 L836:z_age_hot:mv:cld
05. sid:09 L836:z_age_hot:mv:cld 06. sid:04 L836:z_age_hot:mv:cld
07. sid:03 L836:z_age_hot:mv:cld 08. sid:05 L836:z_age_hot:mv:cld
09. sid:02 L836:z_age_hot:mv:cld 10. sid:04 L836:z_age_hot:mv:cld
11. sid:04 L836:z_age_hot:mv:cld 12. sid:04 L836:z_age_hot:mv:cld
13. sid:04 L836:z_age_hot:mv:cld 14. sid:02 L836:z_age_hot:mv:cld
15. sid:04 L836:z_age_hot:mv:cld 16. sid:13 L836:z_age_hot:mv:cld
脏链表LRUW
LRUW用于存放脏块,在块变脏时,并不会立即进入LRUW链表,而是要等到进程搜索可覆盖的牺牲者时,这些脏块才会被移到LRUW中。
图中I,J被锁定,辅助LRU中没有多余位置,脏块G的TCH为1,H为2,H被移动到热端头,而G被移动到主LRUW中。
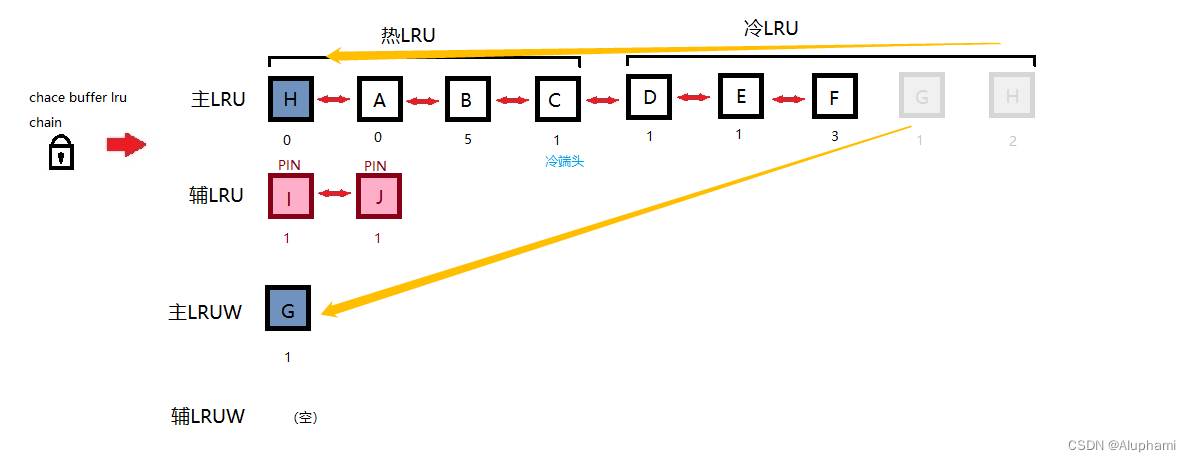
当DBWR醒来以后,只要LRUW中有一个脏块,他就会马上写到磁盘中
最后写完以后会把它继续放到辅助LRU尾,等待再次被覆盖。
 Free Buffer Waits
Free Buffer Waits
_db_large_dirty_queue 参数表示如果检查点中的脏块超过25%就会触发写脏块,此参数用来减少Free Buffer Waits
产生Free Buffer Waits是当服务器进程扫描LRU链表寻找可用的块时,如果找到了40%的Buffer都没有找到可覆盖的Buffer,进程将停止继续扫描LRU,唤醒DBWR写藏快,同时进程转入睡眠,开始Free Buffer Waits。其中40%这个参数由_db_block_max_scan_pct控制。

扫描过的40%块中以下几种类型不能被覆盖
1)正在被其他进程Buffer Pin Lock的;
2)TCH大于2的;
3)脏块。

服务器在进程在扫描LRU时,会将遇到的脏块移到LRUW中,当进程完成LRU扫描,找到可覆盖的buffer时,在进入下一流程前,会判断一下脏块总数,如果小于25%,则正常进入下一流程,被移到LRUW的脏块在DBWR超时醒来后写到磁盘中,如果脏块数接近25%,则不会等待DBWR3秒,而是立即唤醒DBWR然后在进入下一流程,这种情况不会产生Free Buffer Waits.
SELECT ksppinm, ksppstvl, ksppdesc
FROM x$ksppi x, x$ksppcv y
WHERE x.indx = y.indx
AND ksppinm = '_db_large_dirty_queue';
KSPPINM KSPPSTVL KSPPDESC
---------------------------- ---------- ------------------------------------------------------------
_db_large_dirty_queue 25 Number of buffers which force dirty queue to be written
SELECT ksppinm, ksppstvl, ksppdesc
FROM x$ksppi x, x$ksppcv y
WHERE x.indx = y.indx
AND ksppinm = '_db_block_max_scan_pct';
KSPPINM KSPPSTVL KSPPDESC
---------------------------- ---------- ------------------------------------------------------------
_db_block_max_scan_pct 40 Percentage of buffers to inspect when looking for free日志切换与写脏块
日志切换时的检查点,不一定是增量检查点,没有等待的日志切换,并不会触发DBWR立即写脏块,他只是唤醒DBWR,并告知DBWR已经发生了日志切换,写不写脏块,由DBWR自己判断。
日志切换还会触发CKPT进程写数据文件头,和DBWR一样买这个动作也不是立即执行,要等到日志文件中Redo Recoder对应的脏块都被写进磁盘后才会执行。也就是当时的日志状态从Active变成Inactive时,CKPT才会去写文件头(CKPT会写入RBA,SCN,chkpt cnt和crl cnt)



增量检查点间隔设置为1天后,手动切换日志,则Active将持续一天
SQL> alter system set "_disable_selftune_checkpointing"=true;
System altered.
SQL> alter system set fast_start_mttr_target=0;
System altered.
SQL> alter system set log_checkpoint_timeout=86400;
System altered.
SQL> alter system switch logfile;
System altered.
SQL> select group#,sequence#,status from v$log;
GROUP# SEQUENCE# STATUS
---------- ---------- ----------------
1 148 CURRENT
2 146 INACTIVE
3 147 ACTIVE
再次切换日志,发现两个Active状态的日志文件。
SQL> alter system switch logfile;
System altered.
SQL> select group#,sequence#,status from v$log;
GROUP# SEQUENCE# STATUS
---------- ---------- ----------------
1 148 ACTIVE
2 149 CURRENT
3 147 ACTIVE
如果此时再切换日志,由于没有Inactive的日志了,Active日志又不能覆盖,则这时候DBWR将不再按照正常的增量检查点机制,判断是否要写脏块,而是立即开始从检查点队列写脏块。此时的等待事件是log file switch(checkpoint incomplete)I/O总结
逻辑读资料分析
逻辑读分为一致性读(consistent gets)和当前读(db block gets)
一致性读出了consistent gets外,还有一项consistent gets-examination这是一种以共享CBC Latch进行的逻辑读,索引的根块、枝块还有唯一索引在以等值条件访问时,从索引的根、枝、叶,到表块都是以这种CBC Latch方式逻辑读。
建立测试表t1
SQL> create table t1 as select rownum id,object_name from dba_objects;
Table created.
在id列上建立唯一索引
SQL> create unique index te_id on t1(id);
Index created.
检查当前SID
SQL> select sid from v$mystat where rownum=1;
SID
----------
468
检查他目前的一致性读
SQL> select name,value from v$sesstat a,v$statname b where a.statistic#=b.statistic#
2 and sid='468' and(name in('consistent gets','consistent gets examination'));
NAME VALUE
---------------------------------------------------------------- ----------
consistent gets 4
consistent gets examination 0
执行程序,读取100次
SQL> declare
2 m_name varchar2(100);
3 begin
4 for i in 1..100 loop
5 select object_name into m_name from t1 where id=1;
6 end loop;
7 end;
8 /
PL/SQL procedure successfully completed.
再次查询
由于sql语句的where条件是id=1,id列有唯一索引,每次指挥查出一行,所以每次CBC Latch都是共享的,因此每次读都是consistent gets examination
select name,value from v$sesstat a,v$statname b where a.statistic#=b.statistic#
2 and sid='468' and(name in('consistent gets','consistent gets examination'));
NAME VALUE
---------------------------------------------------------------- ----------
consistent gets 304
consistent gets examination 300
减少逻辑读-行的读取
sqlplus中arraysize表示预抓取行数,默认为15
SDU称为session data unit,数据先被塞入SDU,再通过网络发送给用户,可以通过sqlnet.ora修改
arraysize
创建测试表并插入800行
SQL> insert into t3 values(id1,id2,name);
table created.
declare
begin
for i in 1..800 loop
insert into t3 values(1,1,'AA');
end loop;
commit;
end;
/
select dbms_rowid.rowid_relative_fno(rowid) file_id,
dbms_rowid.rowid_block_number(rowid) block_id,
count(*)
from t3 group by
dbms_rowid.rowid_relative_fno(rowid),
dbms_rowid.rowid_block_number(rowid);
查看行分布
SQL> select dbms_rowid.rowid_relative_fno(rowid) file_id,
2 dbms_rowid.rowid_block_number(rowid) block_id,
3 count(*)
4 from t3 group by
5 dbms_rowid.rowid_relative_fno(rowid),
6 dbms_rowid.rowid_block_number(rowid);
FILE_ID BLOCK_ID COUNT(*)
---------- ---------- ----------
1 853066 281
1 853065 519
设定arraysize为300查看执行计划
SQL> set arraysize 300;
SQL> select * from t3;
800 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 4161002650
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 800 | 26400 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS FULL| T3 | 800 | 26400 | 2 (0)| 00:00:01 |
--------------------------------------------------------------------------
Note
-----
- dynamic statistics used: dynamic sampling (level=2)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
7 consistent gets -------------------------------------------逻辑读为7
0 physical reads
0 redo size
12326 bytes sent via SQL*Net to client
400 bytes received via SQL*Net from client
4 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
800 rows processed

下面改成520
SQL> set arraysize 520;
SQL> select * from t3;
800 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 4161002650
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 800 | 26400 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS FULL| T3 | 800 | 26400 | 2 (0)| 00:00:01 |
--------------------------------------------------------------------------
Note
-----
- dynamic statistics used: dynamic sampling (level=2)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
6 consistent gets ---------------------------------------逻辑读变成了6次
0 physical reads
0 redo size
12132 bytes sent via SQL*Net to client
389 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
800 rows processed

如果按照默认的15来查询
逻辑读会很多
SQL> select * from t3;
800 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 4161002650
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 800 | 7200 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS FULL| T3 | 800 | 7200 | 2 (0)| 00:00:01 |
--------------------------------------------------------------------------
Statistics
----------------------------------------------------------
14 recursive calls
0 db block gets
96 consistent gets -----------------------------------高达96次
3 physical reads
0 redo size
22220 bytes sent via SQL*Net to client
961 bytes received via SQL*Net from client
55 SQL*Net roundtrips to/from client
3 sorts (memory)
0 sorts (disk)
800 rows processed
DU对网络传输次数的影响
首先设置SDU为8K
[oracle@localhost admin]$ cat sqlnet.ora
DEFAULT_SDU_SIZE=8192
查询当前会话号
select c.sid,spid,pid,a.SERIAL# from (select sid from v$mystat where rownum<=1 ) c,v$session a,v$process b
where c.sid=a.sid and a.paddr=b.addr;
SID SPID PID SERIAL#
---------- ------------------------ ---------- ----------
422 29490 56 37662
查询当前NET相关等待事件
select event,TOTAL_WAITS,time_waited_micro/100 wtms,time_waited_micro/TOTAL_WAITS/100 avms
from v$session_event where sid in (422)
and event in ('SQL*Net message from client','SQL*Net more data to client');
EVENT TOTAL_WAITS WTMS AVMS
---------------------------------------- ----------- ---------- ----------
SQL*Net message from client 8 712928.05 89116.0063
查询t3表
SQL> select * from t3;
800 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 4161002650
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 800 | 7200 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS FULL| T3 | 800 | 7200 | 2 (0)| 00:00:01 |
--------------------------------------------------------------------------
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
4 consistent gets
0 physical reads
0 redo size
11938 bytes sent via SQL*Net to client
378 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
800 rows processed
再查询等待事件
EVENT TOTAL_WAITS WTMS AVMS
---------------------------------------- ----------- ---------- ----------
SQL*Net more data to client 1 .79 .79
SQL*Net message from client 15 2320325.99 154688.399
SQL*Net more data to client增加一次,说明SDU满了,服务器只能先将SDU内数据发送给客户端后记录一次SQL*Net more data to client,再将剩余数据发给客户端
更改SDU为16384 扩大一倍重新查询
select c.sid,spid,pid,a.SERIAL# from (select sid from v$mystat where rownum<=1 ) c,v$session a,v$process b
2 where c.sid=a.sid and a.paddr=b.addr;
SID SPID PID SERIAL#
---------- ------------------------ ---------- ----------
422 30228 56 7786
SQL> set arraysize 800
SQL> set autot trace
SQL> select * from t3;
800 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 4161002650
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 800 | 7200 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS FULL| T3 | 800 | 7200 | 2 (0)| 00:00:01 |
--------------------------------------------------------------------------
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
4 consistent gets
0 physical reads
0 redo size
11938 bytes sent via SQL*Net to client
378 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
800 rows processed
EVENT TOTAL_WAITS WTMS AVMS
---------------------------------------- ----------- ---------- ----------
SQL*Net message from client 15 374471.79 24964.786
可以看见SDU能容纳下所有800条数据,因此不会产生SQL*Net more data to client
















 315
315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











