







1.区(Extent):表空间的基本单位
Extent的基本概念
Extent:逻辑上连续空间。是表空间中空间分配基本单位。
10g:创建表,则至少分配一个Extent。
11.2以上:创建表,不分配Extent。只有插入第一行数据,才分配第一个Extent。避免创建大量表(比如分区表),但不用而浪费时间。是一种延迟分配机制。
Extent的分配信息,可在DBA_EXTENTS视图中。描述Extent_id,所属File,起始Block_id,包含多少个blocks,所属表(segment_name)
select extent_id, file_id, block_id, blocks
from dba_extents where
segment_name='TABLE1' order by extent_id;Extent如何定义大小?
统一区大小:
Extent大小为固定值,可以在创建表空间时指定,如下是1M的Extent大小
create tablespace tbs_ts1 datafile '/u01/Disk1/tbs_ts_01.dbf' size 50m uniform size 1m;建表,插入一条记录后,从DBA_EXTENTS中查看,能看到Extent信息:
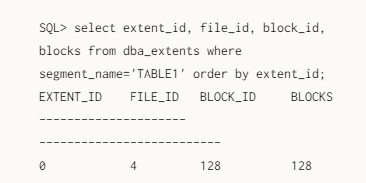
table1包含1个Extent(0),从4号文件128号块开始,大小128(块大小8K,*128,正好1MB)。
文件头:
从上面看,新申请的第一个extent是从128号块开始的,那前面的0~127,就是预留的文件头。
其中:0,1时候真正文件头。
2~127是位图块:记录区的分配情况。每个位图块中的一个二进制位,表示对应的一个区是否被分配。
其中第一个位图块(2号)是位图段头:记录区使用情况。
真正的位图信息从3号块开始。
新分配起始标记位:为加快检索可用的位(代表区),有一个标记位记录已经分配到哪里。新分配区时,从这个标志位开始查。
如果开启闪回,Drop只是改名,标记位不会下降
系统管理区大小
系统管理区大小:区大小不固定,根据表大小自动配置。随着表的大小变化,区大小也发生变化,持续怎增大。


0~15号区,Blocks大小为8
从16号开始,大小变为128个
继续增大表,区大小还会继续扩大。
小的区省空间。对于随机访问,小、大区没有影响;对于全表扫描,大区更合适(空间连续,机械硬盘效率高)。
通常建议使用系统管理区,找平衡;除非知道表 很大,直接建统一区大小,且区比较大的表空间。段超过64MB,区大小可以建议为8MB。
即使IO操作最大读都是1MB,但8MB区比1MB区有效,因为两个1MB可能是连续的。
位图标记方式,针对两种区是一样的方式,只是一次用的位数量不一样而已。例如:以64KB为准,每个二进制位代表64KB。对于1MB的区,就用16个来管理。
碎片,可忽略的问题:统一区大小,不会出现碎片。系统管理区中,会出现碎片,但情况较少。一个表创建后,很少Drop、Truncatre操作。在表空间层,碎片可忽略;在表、索引层,还是存在的。
2.中块的使用
段是描述存储空间,段(segment)由一组数据扩展(extent)构成,其中存储了表空间内各种逻辑存储结构的数据。一个段至少包含一个区。例如,Oracle能为每个表的数据段(data segment)分配数据扩展,还能为每个索引的索引段(index segment)分配数据扩展。
在DBA_OBJECTS视图中,object_id列是表ID,data_object_id列是段ID。
表ID创建就不变,段ID会变化。truncate会导致段ID变化(删除旧的、新建新的)。
dbms_rowid包,可以把对象ID、文件号、块号、行号和ROWID进行转换。
删除某行,只是在行上加删除标志,表明空间可被覆盖。在未提交时,锁并没有释放。做回滚后,不会重新寻找空间,所以行号不变。删除后提交再插入,行号会变化。
关于堆表的顺序问题
堆表的特点就是无序、插入快速。
插入时,在块中空间查找过程:
1、块中有一个标记,记录空间使用到哪里。空间是从下往上分配的,比如8192块,插入5行*100字节,标记位就是(8192-500) = 7692(示意),标记位就是7692
2、如果删除一行,标记位不变。再插入数据时,会从7692向上查找。删除行释放空间不会被使用。
只在一个页里面,看上去是顺序的。但不同页面,就不适合了。因为插入时根据PID计算随机过的。
ASSM(自动段空间管理):目的就是大并发插入,实际就是针对不同Session在分配块时,做了2次hash,减少冲突(buffer busy wait)
1、三级位图块结构

2个L3就很罕见
2、插入时选择块的步骤
1)先查数据字典,dba_segments的基表,确定段头位置
2)在段头中找到第一个L2块位置信息。注意,这里是按顺序选,只有第一个L2下面所有块都满了,才会选择下一个L2。
3)到L2块中根据执行插入操作进程的PID号,做HASH运算,得到一个随机数N,在L2中,找到第N个L1块的位置信息。
4)在确定L1块中,根据插入操作进程的PID,做HASH运算,得到随机数M,在L1中找到第M号数据块。
即:在具体分配在哪个块插入时,是根据插入进程的PID做了两次HASH,以提高并发能力(不同进程尽量找不同的块)。
新创建一个表时,它的L1-L3是倒过来的:
比如:128是L1,129是L1,130时候L2,131是L3
一个案例:
高水点影响ASSM计算L1块的范围,导致数据并发在小范围内选择,增加冲突。高水点向后移动是以L1中数据块量为单位。
如果块大小8KB,区大小1MB,L1中有64个块,高水位点就是以64位单位。如果不突破高水位,并发插入都在这64个块上插入。
会出现2个块同时修改一个块,则出现buffer busy waits。
L1的块数量不是定的,随着表增大会增大。
段头与Extent Map
查段头
select header_file, header_block from dba_segments
where segment_name = 'TABLE1';
seg$是基表。
段头包含第一个L3块,还包含区地图。每行描述一个区的的位置和长度。

01000080转为二进制为:
0000 0001 0000 0000 0000 0000 1000 0000
前10位代表文件号:0000 0001 00,代表4号文件
080是十进制128,起始块号。
继续往下 辅助地图

L1 dba:0x1000080 此区内第一个L1块开始的地方(即4号文件,128号块)
Data dba:0x1000084:用户数据开始的地方,即132号块
全表扫描时,按照Data dba扫。但这里没有长度,还得读全面的分区地图信息。
89、90的L1 dba相同。在1MB分区,当段大小超过64MB,一个L1存放256个数据块。这样,多个分区会使用同一个L1(因为256,能包含2个分区的信息)

索引范围扫描
按照根、枝、页的顺序。根块永远在索引段头的下一个块处。可以直接在数据字典找到段头,段头+1就能读出根块。
关于具体怎么读取,还需要后面再细化一下。















 208
208











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









