






 文章详细阐述了从MySQL迁移到高斯DB的流程,包括数据迁移、SQL脚本转换、执行与错误排查,特别是针对大小写不敏感场景的处理。此外,讨论了二进制类型字段的jdbcType调整和查询时的大小写敏感问题,提到了高斯DB的兼容性类型、字符集和字符序设定,以及如何实现查询数据的大小写不敏感。
文章详细阐述了从MySQL迁移到高斯DB的流程,包括数据迁移、SQL脚本转换、执行与错误排查,特别是针对大小写不敏感场景的处理。此外,讨论了二进制类型字段的jdbcType调整和查询时的大小写敏感问题,提到了高斯DB的兼容性类型、字符集和字符序设定,以及如何实现查询数据的大小写不敏感。
目录
一、mysql转高斯适配流程(大小写不敏感场景)
1.数据迁移,导出sql脚本
使用navicat工具将mysql表的结构和数据迁移到gaussDB,gaussDB存在数据库和模式,模式对应mysql中的数据库,因此在gaussDB中提前建好模式。
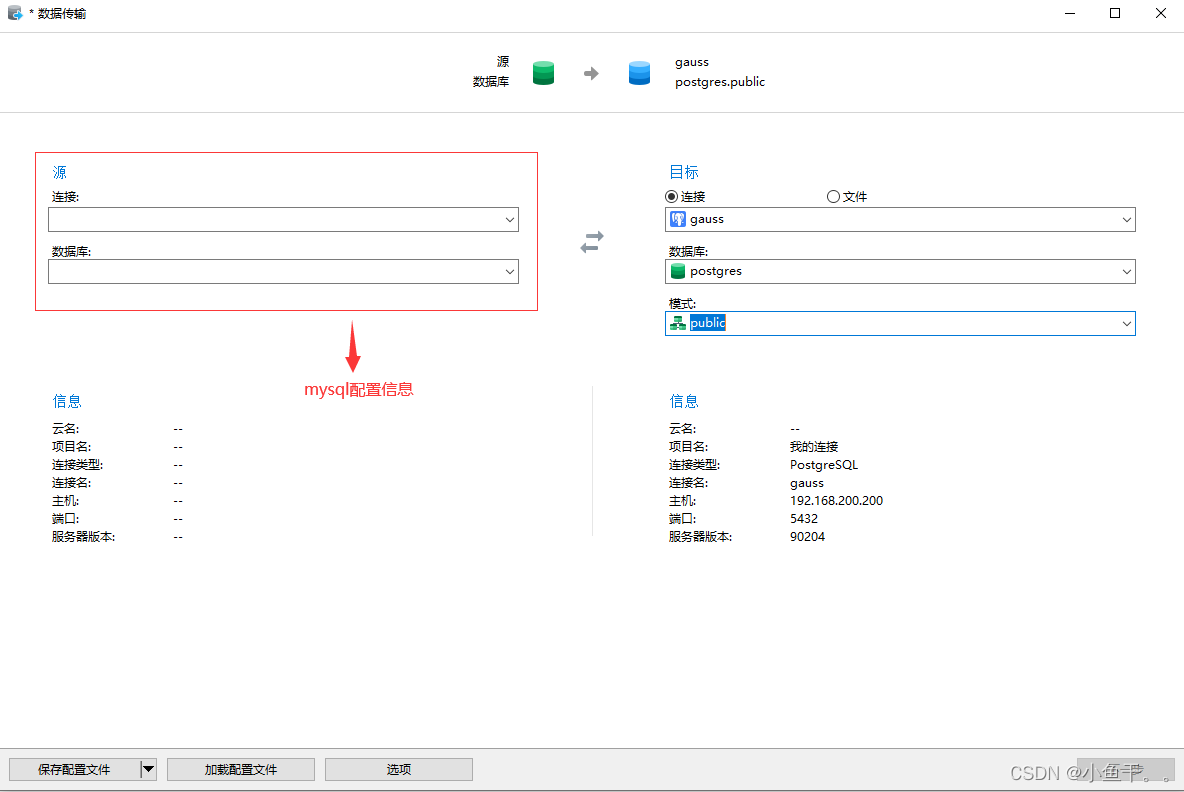
按照提示操作即可将mysql的表结构和数据导入gaussDB中,然后在gaussDB中选中模式,导出sql脚本。
2.转换sql脚本
使用文本编辑器打开上一步导出的sql脚本,全局替换双引号",替换为空。
3.执行sql脚本,排除错误
将第一步导入到gaussDB模式下的所有表删除,然后运行第二步转换的sql脚本,反选以下两个选项,如果出现错误,则排查修改后重复步骤三。
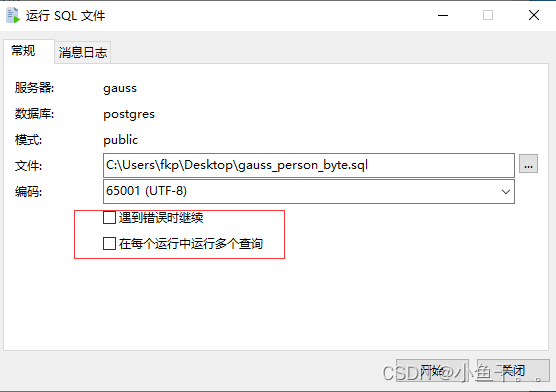
如果遇到表字段中存在数据库保留字导致无法创建的表,修改建表语句,将该字段用双引号包裹,如果字段名不是全小写,则改为全小写。
4.检查二进制类型字段的jdbcType
如果转换后的字段存在bytea类型,即二进制数据,需要检查代码mybatis的xml文件中在插入、更新、和结果映射时该字段的jdbcType,如果存在,删除即可。
二、适配注意事项
1.数据库安装和配置
为了方便安装,使用docker运行opengaussDB,执行以下命令将自动下载镜像并启动容器
docker run -d -e GS_PASSWORD=Fkp@123456 -p 5432:5432 -v /opt/opengauss/data:/var/lib/opengauss/data --privileged=true --name opengauss enmotech/opengauss参数说明:
-d docker容器后台运行
-e GS_PASSWORD=Fkp@123456 指定启动参数,数据库连接密码,密码强度需包含大小写特殊字符和数字
-p 5432:5432 端口映射
-v /opt/opengauss/data:/var/lib/opengauss/data 挂载主机目录,docker镜像中默认的opengauss存储数据目录为/var/lib/opengauss/data
--privileged=true 允许容器内该进程拥有特许权限
--name opengauss 容器名称
enmotech/opengauss 镜像名称
设置主机挂载目录在容器重启时数据库数据不会清除。
备注:我想改变gaussDB的端口号,使用-e GS_PORT=xxxx,-p:xxxx:xxxx启动后无法连接
2.建表语句
高斯数据库建表语句对引号很有讲究,是个大坑,下边列举四种建表语句,以字段名为例,数据库名,模式名,表名亦是如此。
DROP TABLE IF EXISTS "public"."gauss_person_byte";
CREATE TABLE "public"."gauss_person_byte" (
"id" varchar(255) COLLATE "pg_catalog"."default" NOT NULL,
"name" varchar(255) COLLATE "pg_catalog"."default"
);
DROP TABLE IF EXISTS "public"."gauss_person_byte";
CREATE TABLE "public"."gauss_person_byte" (
id varchar(255) COLLATE "pg_catalog"."default" NOT NULL,
name varchar(255) COLLATE "pg_catalog"."default"
);
DROP TABLE IF EXISTS "public"."gauss_person_byte";
CREATE TABLE "public"."gauss_person_byte" (
ID varchar(255) COLLATE "pg_catalog"."default" NOT NULL,
NAME varchar(255) COLLATE "pg_catalog"."default"
);
DROP TABLE IF EXISTS "public"."gauss_person_byte";
CREATE TABLE "public"."gauss_person_byte" (
"ID" varchar(255) COLLATE "pg_catalog"."default" NOT NULL,
"NAME" varchar(255) COLLATE "pg_catalog"."default"
);
以下是四种查询方式,引用了id列。
select id from gauss_person_byte;
select ID from gauss_person_byte;
select "id" from gauss_person_byte;
select "ID" from gauss_person_byte;为了方便区分,我们给建表语句所建的表从上到下标注T1,T2,T3,T4,查询语句从上到下标注为Q1,Q2,Q3,Q4。以下是执行结果。
T1 -> Q1:success T1 -> Q2:success T1 -> Q3:success T1 -> Q4:fail
T2 -> Q1:success T2 -> Q2:success T2 -> Q3:success T2 -> Q4:fail
T3 -> Q1:success T3 -> Q2:success T3 -> Q3:success T3 -> Q4:fail
T4 -> Q1:fail T4 -> Q2:fail T4 -> Q3:fail T4 -> Q4:success
分析:
在我们写sql语句时一般不会将字段名用双引号包裹,即Q3,Q4情况,因此这里不做过多的解释,只给出执行结果,另外说明T4的情况也包括字段名是大小写混搭的,例如Name,这种T4的见表语句,在查询时必须和建表语句的字段写法完全一样,即使用双引号包裹且字段名大小写完全一致。
分析Q1和Q2的情况,即结果中的前两列:
T1:双引号包裹,名全部小写,这种存在很大的局限性,因为无法保证之前的表字段名中全部是小写,如果存在大写情况则变成了T4类型,查询时受到很大限制。何时使用T1的格式呢,当字段是数据库的保留字时,如果不适用引号包裹则导致建表失败,此时将字段名用双引号包裹,且将其全部转换为小写。
T2、T3:推荐的建表格式,在大小写不敏感场景下最灵活的建表格式,唯一的局限在于字段名是数据库保留字时导致建表失败,可采用T1格式转换,具体如上述T1下半段描述。T3格式有一个反常情况,即标红T3 -> Q3,T3 -> Q4,但是Q3和Q4的查询写法并不常见,因此暂且忽略。
T4:双引号包裹,字段名称存在大写,此时查询必须和建表语句完全一致,否则查询失败。
结论:
1.在大小写不敏感的场景下优先选择T2、T3格式,如果存在数据库保留字情况,可将字段改为T1格式。
2.在大小写敏感的场景下使用T4,但查询时字段引用需要使用双引号包裹,局限性较大,如果字段名全部小写,即T1,则大小写敏感会失效,例如T1 -> Q2 success.
3.二进制数据类型转换问题
mysql中的blob类型转换到gaussDB中为bytea类型,在mybatis的xml中将jdbcType删除,否则可能导致插入和更新失败的情况。
gaussDB底层参考postgresql,而postgresql在高版本中已经将blob类型废弃,gaussDB中虽仍保存blob类型,但是使用jdbc操作时,插入和更新数据会报错。
1.gaussDB的bytea类型和blob类型对比
openGaussDB版本:(查看方式:查询sql,select version();)
(openGauss 5.0.0 build a07d57c3) compiled at 2023-03-29 03:09:38 commit 0 last mr on x86_64-unknown-linux-gnu, compiled by g++ (GCC) 7.3.0, 64-bit
建一个表gauss_person_byte,其中byte_content类型为bytea,byte_content2为blob
CREATE TABLE "public"."gauss_person_byte" (
"id" varchar(255) COLLATE "pg_catalog"."default" NOT NULL,
"name" varchar(255) COLLATE "pg_catalog"."default",
"byte_content" bytea,
"byte_content2" blob,
CONSTRAINT "gauss_person_byte_pkey" PRIMARY KEY ("id")
)
;
ALTER TABLE "public"."gauss_person_byte"
OWNER TO "gaussdb";通过以下代码测试插入数据和插入null
package com.fkp;
import com.baomidou.mybatisplus.core.toolkit.Wrappers;
import com.fkp.postgresql.entity.PersonByte;
import com.fkp.postgresql.mapper.PersonByteMapper;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.ByteArrayInputStream;
import java.sql.*;
import java.util.List;
import java.util.UUID;
@SpringBootTest
class JdbcTest {
@Test
void test() throws ClassNotFoundException, SQLException {
//加载驱动
Class.forName("org.postgresql.Driver");
Connection connection = DriverManager.getConnection("jdbc:postgresql://192.168.200.200:5432/postgres?currentSchema=public", "gaussdb", "Fkp@123456");
//开启事务
connection.setAutoCommit(false);
PreparedStatement preparedStatement = connection.prepareStatement("insert into gauss_person_byte values (?, ?, ?, ?)");
preparedStatement.setString(1, UUID.randomUUID().toString());
preparedStatement.setString(2, "zhangsan");
byte[] bytes = {1, 2, 3, 4};
ByteArrayInputStream inputStream = new ByteArrayInputStream(bytes);
//gaussDB的bytea类型可以通过setBinaryStream,setBytes,setObject插入数据,setBlob不可用,报错openGauss does not support large object yet
// preparedStatement.setBinaryStream(3, inputStream);
// preparedStatement.setBytes(3, bytes);
// preparedStatement.setObject(3, bytes);
preparedStatement.setBlob(3, inputStream);
//gaussDB的bytea类型插入null的JDBCType可以为VARBINARY,NULL,OTHER,通过BLOB报错:column "byte_content" is of type bytea but expression is of type oid
// preparedStatement.setNull(3, JDBCType.VARBINARY.getVendorTypeNumber());
// preparedStatement.setNull(3, JDBCType.BLOB.getVendorTypeNumber());
// preparedStatement.setNull(3, JDBCType.NULL.getVendorTypeNumber());
// preparedStatement.setNull(3, JDBCType.OTHER.getVendorTypeNumber());
//gaussDB的blob类型,通过setObject,setBytes,setBinaryStream均无法插入,报错:column "byte_content2" is of type blob but expression is of type bytea;通过setBlob也无法插入,报错:openGauss does not support large object yet
// preparedStatement.setObject(4, bytes);
// preparedStatement.setBytes(4, bytes);
// preparedStatement.setBinaryStream(4, inputStream);
// preparedStatement.setBlob(4, inputStream);
//gaussDB的blob类型插入null,JDBCType为BLOB,VARBINARY均无法插入,通过OTHER,NULL可以插入
// preparedStatement.setNull(4, JDBCType.OTHER.getVendorTypeNumber());
preparedStatement.setNull(4, JDBCType.NULL.getVendorTypeNumber());
boolean execute = preparedStatement.execute();
//提交事务
connection.commit();
System.out.println(execute);
preparedStatement.close();
connection.close();
}
}
2.比对结果
| 插入方法\数据类型 | bytea | blob |
| setBinaryStream | success | 报错B |
| setBytes | success | 报错B |
| setObject | success | 报错B |
| setBlob | 报错A | 报错A |
| setNull,JDBCType=VARBINARY | success | 报错C |
| setNull,JDBCType=BLOB | success | 报错C |
| setNull,JDBCType=NULL | success | success |
| setNull,JDBCType=OTHER | success | success |
备注:
报错A:openGauss does not support large object yet
报错B:column "byte_content2" is of type blob but expression is of type bytea
报错C:column "byte_content" is of type bytea but expression is of type oid
3.结论:
1.高斯数据库不支持blob数据类型,通过postgresql驱动的setBlob方法向该类型字段插入数据时报错openGauss does not support large object yet,其错误是openGaussDB服务端返回的错误。
2.上述代码中通过setBytes,setBinaryStream方法插入时报错column "byte_content2" is of type blob but expression is of type bytea,该错误由于postgresql驱动将数据转为bytea类型请求服务端,服务端发现类型不一致,返回该错误。
3.使用openGaussDB存储二进制数据应使用bytea数据类型。
4.查询大小写敏感问题
高斯数据库默认对于查询是大小写敏感的。
1.例子
数据库中存在user表,name为唯一主键。
| name | age |
| tom | 23 |
| jack | 25 |
select * from user where name = 'tom' 可以查询出name为tom的记录
select * from user where name = 'Tom' 查询结果为空
插入数据亦是如此
insert into user values('Tom', 24) 插入成功
说明高斯数据库默认对于字段的值是大小写敏感的,即区分大小写,而mysql默认是不区分大小写的,那么高斯数据库如何设置。
2.了解高斯数据库的兼容性类型和字符集和字符序
1.兼容性类型
在创建数据库时可以指定兼容的数据库类型,可以指定A、B、C、PG,分别表示兼容Oracle、MySQL、Teradata(TD)和PostgreSQL。默认使用A兼容类型。
兼容类型在创建数据库时指定,之后不能修改,因为其指定后将按照特定的规则存储数据。
 https://docs.opengauss.org/zh/docs/5.0.0/docs/SQLReference/CREATE-TABLE.html
https://docs.opengauss.org/zh/docs/5.0.0/docs/SQLReference/CREATE-TABLE.html2.字符集和字符序
这里给出简单的字符集和字符序的定义:
- 字符集(
character set):定义了字符以及字符的编码;- 字符序(
collation):定义了字符的比较规则。- 举个例子:
有四个字符:A、B、a、b,这四个字符的编码分别是 A = 0,B = 1,a = 2,b = 3(这里的字符 + 编码就构成了字符集)。
字符的比较方式为:
不同字符:比如 A、B,或者 a、b,最直观的比较方式是采用它们的编码,比如因为 0 < 1,所以 A < B
相同字符不同大小写:比如 A、a,虽然它们编码不同,但我们觉得大小写字符应该是相等的,也就是说 A == a
这上面定义了两条比较规则,这些比较规则的集合就是字符序 collation:同样是大写字符、小写字符,则比较他们的编码大小;
如果两个字符为大小写关系,则它们相等。
字符编码认为和字符集时同义词。
要实现查询时对字段的值不区分大小写,需要指定兼容性类型为B类型,即兼容MySQL,建表时指定大小写不敏感的字符序。
建表时指定字符序说明引用官方文档:
COLLATE collation
COLLATE子句指定列的排序规则(字符序)(该列必须是可排列的数据类型)。如果没有指定,则使用默认的排序规则。排序规则可以使用“select * from pg_collation;”命令从pg_collation系统表中查询,默认的排序规则为查询结果中以default开始的行。对于B模式数据库下(即sql_compatibility = 'B')还支持utf8mb4_bin、utf8mb4_general_ci、utf8mb4_unicode_ci、binary字符序。
说明:
- 仅字符类型支持指定字符集,指定为binary字符集或字符序实际是将字符类型转化为对应的二进制类型,若类型映射不存在则报错。当前仅有TEXT类型转化为BLOB的映射。
- 除binary字符集和字符序外,当前仅支持指定与数据库编码相同的字符集。
- 未显式指定字段字符集或字符序时,若指定了表的默认字符集或字符序,字段字符集和字符序将从表上继承。若表的默认字符集或字符序不存在,当b_format_behavior_compat_options = 'default_collation'时,字段的字符集和字符序将继承当前数据库的字符集及其对应的默认字符序。
表 1 B模式(即sql_compatibility = 'B')下支持的字符集和字符序介绍
| 字符序名称 | ||
|---|---|---|
| utf8_general_ci | utf8 | 使用通用排序规则,不区分大小写。 |
| utf8_unicode_ci | utf8 | 使用通用排序规则,不区分大小写。 |
| utf8_bin | utf8 | 使用二进制排序规则,区分大小写。 |
3.实现查询数据大小写不敏感
1.创建数据库,指定B兼容性类型。
create database fkp_test7 DBCOMPATIBILITY 'b';2.创建模式并应用模式
create schema test;
set search_path = test;3.创建表,在需要大小写不敏感的字段指定字符序类型为utf8mb4_general_ci,大小写敏感的字段字符序指定为utf8mb4_general_bin,注意该字段必须为字符串类型,varchar,text等。
DROP TABLE IF EXISTS policy;
CREATE TABLE policy (
id varchar(32) COLLATE pg_catalog.utf8mb4_general_ci NOT NULL,
type varchar(100) COLLATE pg_catalog.utf8mb4_general_ci,
name varchar(100) COLLATE pg_catalog.utf8mb4_bin,
);
ALTER TABLE policy ADD CONSTRAINT access_control_policy_pkey PRIMARY KEY (id);通过指定字符串的字符序类型即可实现查询字段值时的大小写敏感问题,前提数据库必须是B兼容性类型。
在创建模式时可以指定其字符序和字符集,从而使在此模式下创建表时无需显式指定表的字符序就可以实现大小写不敏感。建表时指定字符序优先级高于模式的字符序。
CREATE SCHEMA test_schema
CHARSET = utf8mb4
COLLATE = utf8mb4_general_ci ;尝试在建数据库时指定没有成功,因为指定LC_COLLATE和LC_CTYPE时无法指定类似utf8mb4_general_ci的值,执行报错。
备注:
建表语句中pg_catalog.utf8mb4_general_ci的pg_catalog,加不加都可以,对于pg_catalog的解释:
pg catalog是系统级的schema,用于存储系统函数和系统元数据。每个database创建好以后默认都会含有两个catalog:一个名为pg_catalog,用于存储 PostgreSQL 系统自带的函数、表、系统视图、数据类型转换器以及数据类型定义等元数据;另一个是information_schema,用于存储 ANSI 标准中所要求提供的元数据查询视图,这些视图遵从 ANSI SQL 标准的要求,以指定的格式向外界提供 PostgreSQL 元数据信息。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









