






HTTP简介
(1)HTTP的由来
HTTP即为HyperText Transfer Protocol的英文的缩写,中文翻译是超文本传输协议或者翻译为超文件传输协议,它是一种因特网上比较流行的传输协议。
HTTP最初用来发布和接收由文本组成的HTML网页页面的协议方法,后来才逐渐从只能传输文本数据,到可以传输图片文件、影视频文件,以及各种压缩、程序文件等各种文件数据。
(2)HTTP协议版本
目前使用的基本上都是HTTP/1.1版本。如下图,在访问百度的时候发的GET请求用的HTTP版本为HTTP/1.1:
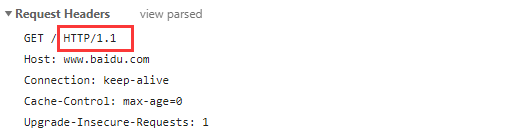
(3)HTTP协议所在OSI层次
HTTP属于应用层,位于TCP/IP的顶层。如下图:

由上图可知,HTTP是基于TCP的为基础的进行工作的,所以HTTP不会出现数据丢失和数据乱序的情况。客户端通过TCP建立的链接后,用套接字发送HTTP,同理通过套接字接收HTTP的请求响应。
(4)HTTP发送请求过程
主要的过程如下:
1. 客户端与服务器建立TCP链接;
2. 客户端向服务器发送请求,如果服务器接收请求,则回送响应码和所需的信息数据,响应的过程是一个异步于其他的过程的过程;
3. 重复第二步,直到客户端将要和服务器断开链接;
4. 客户端与服务器断开链接;
注意:HTTP/1.1支持持久链接,在客户端发送一个请求直到收到响应之前,可以再次发送多个请求,即在完成一个请求和接收一个应答之后,还可以多次在这之后或者并列的完成多次"请求—应答";而对于HTTP/1.0则不支持持久链接。
(5)HTTP的特点
1. 以TCP的方式工作,上面已经分析;
2. HTTP是无状态的,即服务器不会存储关于客户端的任何状态信息,也不会保存客户端的请求究竟是何种请求类型。如果一个客户端请求两次相同的内容,服务器也会进行两次返回请求的对象内容,而不管原来是不是已经向客户端发送过这个请求的对象;
3. HTTP使用元信息作为标头,即在请求的主体之前添加一部分信息,我们把这一部分数据称之为元信息(Metainfotmation),对于源信息所在的部分,我们称之为标头(Header),上面第一个图中的Request Header即为我们请求百度页面的标头,其中的"Host: www.baidu.com"和"Connection: keep-Alive"等信息都属于元信息;
(6)HTTP/1.0和HTTP/1.1之间的区别
| HTTP/1.0 | HTTP/1.1 | |
| 请求类型 | 请求类型比1.1的版本少的多,定义了基本的请求类型:GET请求、POST请求和HEAD请求 | 提供了8种请求类型:GET请求、POST请求、PUT请求、HEAD请求、DELETE请求、OPTIONS请求、TRACE请求和CONNECT请求。 |
| 是否支持长链接 | 不支持 | 支持 |
| 标头结构 | 无要求,标头不需要Host部分 | 标头部分必须有Host部分,其它都是可选部分 |
| 现使用情况 | 几乎不再使用 | 绝大部分浏览器和服务器都使用1.1版本 |
HTTP的请求与相应简述(重要)
(1)Web页面的构成
Web页面即网页页面由多个页面元素构成,我们把这些元素称之为对象或者是资源,这些对象或者资源在Web页面上由单个URL所引用,我们可以通过URL来找到访问这些对象的地址路径,进而来访问这些对象。特别的,我们把Web页面的源HTML文件也看作一个对象,即一个Web页面由其自身的源HTML文件和其页面上引用的其他对象资源文件所构成。如果一个页面中包含1个视频,1个字幕,3张图片,那么这个页面由6个对象构成。
(2)HTTP/1.1请求的种类
我们将GET、POST等的请求类型也称之为请求的方法。HTTP 1.1提供了如下表8种类型的请求方法:
| 请求的方法名 | 说明 |
| GET | 请求获取特定的资源,例如,请求一个Web页面 |
| POST | 请求向指定资源提交数据进行处理(例如,提交表单或者上传文件),请求的数据被包含在请求体中 |
| PUT | 向指定资源位置上传其最新内容,例如,请求储存一个Web页面 |
| HEAD | 向服务器请求获取与GET请求相一致的响应,只不过响应体将不会被返回。这一方法可以在不必传输整个响应内容的情况下,就可以获取包含在响应消息头中的源信息。 |
| DELETE | 请求删除指定的资源 |
| OPTIONS | 返回服务器正对特定资源所支持的HTTP请求方法 |
| TRACE | 回显服务器收到的请求 |
| CONNECT | 预留给能够将连接改为管道方式的代理服务器 |
我们在上表中最常用的方法就是GET方法和POST方法,也称之为GET请求和POST请求。
注意:1. 如果服务器不支持或者客户端发送了错误的请求方法,服务器会返回错误并立即关闭连接;
2. 请求的名称是区分大小写的,一般以大写的方式表示;
3. 对于HTTP/1.1服务器至少应该事先GET和HEAD方法,而其它的方法都是可选的;
(3)HTTP请求的基本格式(重要)
格式如下:
< request-line >
< headers >
< blank line >
{ < request-body > }
格式代码说明见如下表格:
| 请求内容 | 说明解析 |
| <request-line> | 第一行必须是一个请求行(request line),说明请求的类型、要访问的资源以及使用的HTTP版本,这些内容之间用空格来分隔。例如: GET / HTTP/1.1 |
| <headers> | 接着的这个是标头的部分,说明服务器要使用的附加信息,这部分一般是由多行组成。 |
| <blank line> | 然后在标头之后是一个空行(blank line),它表示的标头的结束位置。而这个空行是必须要存在的无论前后的内容如何,即使不存在请求体的部分,这个空行也是必须要存在的。 |
| <request-body> | 空行之后是请求的主体(request-body),主体中可以包含任意的数据。 |
注意:1. 请求行和标头必须以回车换行(<CR><LF>)作为结尾。空行内必须只有<CR><LF>而无其他空格;
2. 在HTTP/1.1中,标头中必须有Host部分,其他都是可选的;
3. 即使不存在请求体的部分,这个空行也是必须要存在的;
※这里稍微提一下<CR><LF>的含义和来源:
CR是Carriage Return的英文的缩写,意思是"回车",我们通常用" \r "来表示。
LF是Line Feed的英文缩写,意思是"换行",我们通常用" \n "来表示。
在Windows系统中用" \r\n "表示下一行,而在MAC系统中则是用" \r "表示下一行,在 Unix系统中是用" \n "表示下一行,所以上面说的是在Windows下用回车换行(<CR><LF>)作为结尾。
这里我们平时些程序的时候,最常用到的是GET请求和POST请求,我们就以这两个请求为列子,探究一下请求体的格式:
(4)GET请求的请求体举例
我们在百度的页面中输入1,然后点击"百度一下"。在Chrome的控制台中可以看到如下的内容,如图:

-
GET /s?ie=utf-8&f=8&...&inputT=533 HTTP/1.1 -
Host: www.baidu.com -
Connection: keep-alive -
Upgrade-Insecure-Requests: 1 -
User-Agent: <...> -
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8 -
Referer: https://www.baidu.com/?tn=02003390_15_hao_pg -
Accept-Encoding: gzip, deflate, br -
Accept-Language: zh-CN,zh;q=0.9 -
Cookie: <...>
我把一些不重要的内容进行了省略化,我们重点分析一下重要的几行,如下分析表格:
| 重要行 | 解析 |
| 第一行 (GET起始行) | 这一行是由3个部分组成的,分别是"GET"、"/s?name1=value1&...&nameN=valueN"和"HTTP/1.1"组成。 【1】其中"GET"是说明请求的类型是GET请求; 【2】而" /s?name1=value1&...&nameN=valueN "部分,在" ? "之前的部分是URL地址,即Host加上"?"之前的部分,即为 " www,baidu.com/s ",如果是单纯一个" / "就表示的是网址下的根目录" www.baidu.com/ ",对于" ? "之后的部分,则是GET请求的参数,每一个参数之间通过" & "分隔,其格式如下: URL?name1=value1&name2=value2&...&nameN=valueN 这一条信息被称为查询字符串(Query String); 【3】最后的" HTTP/1.1 "说明使用的HTTP协议版本是1.1版本; |
| 第二行 (Host起始行) | 第二行是Host标头,指出请求的目的地址。结合上面第一行的第二部分使用。 注意:上面已经说过HTTP1.1才需要使用标头Host,而1.0的版本是不需要的; |
| 第三行(Connenction起始行) | 第三行是Connection标头,通常将浏览器操作设置为Keep-Alive(当然也可以是其他的值)。 |
| 第四行(User-Agent起始行) | 第四行是User-Agent标头,服务器和客户端脚本都能够访问它,它是浏览器类型检测逻辑的重要基础。该信息由使用的浏览器来定义,并且在每个请求中都会自动发送。 |
| 最后空行 | 这一行在上面的图中并没有标出,但是按照上面的格式,这一行是存在的,表示标头的结束。 注意:上面已经说过即使不存在请求体的部分,这个空行也是必须要存在的。 |
(5)POST请求体举例
我们来使用一下百度翻译,翻译"乌龙茶",获得请求体如下图所示:

可以看到其中不但有请求的标头,还有表单数据。我将上面的数据整理如下:
-
Request Header: -
POST /langdetect HTTP/1.1 -
Host: fanyi.baidu.com -
Connection: keep-alive -
Content-Length: 33 -
Accept: */* -
Origin: https://fanyi.baidu.com -
X-Requested-With: XMLHttpRequest -
User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.81 Safari/537.36 -
Content-Type: application/x-www-form-urlencoded; charset=UTF-8 -
Referer: https://fanyi.baidu.com/?aldtype=16047 -
Accept-Encoding: gzip, deflate, br -
Accept-Language: zh-CN,zh;q=0.9 -
Cookie: <...> -
Form Data: -
query=%E4%B9%8C%E9%BE%99%E8%8C%B6
我把一些不重要的内容进行了省略化,我们重点分析一下重要的几行,如下分析表格:
| 重要行 | 解析 |
| 第一行(GET起始行) | 【1】第一行的第一部分请求类型修改为了POST请求; 【2】第二部分仅仅只含有URL,而不再含有" ? ",以及" ? "之后的参数部分,这部分消失的参数将会出现的请求体的表单部分中; 我们可以看到请求的地址为 "fanyi.baidu.com/langdetect " |
| 第二行(Host起始行)、第三行(Connection起始行)、第八行(User-Agent起始行) | 和上面的GET请求的标头作用一致 |
| 第四行(Content-Length起始行) | 这一行的Content-Length标头说明了请求主体的字节数 |
| 第九行(Content-Type起始行) | 第九航的Content-Type标头 |
(6)HTTP响应的基本格式(重要)
格式如下:
< status-line >
< headers >
< blank line >
{ < response-body > }
格式代码说明见如下表格:
| 响应内容 | 解析说明 |
| < status-line > | 第一行都会是一个状态行,该行的内容一次是当前的HTTP版本号、3位数字组成的状态码以及描述这个状态的短语组成,每个组成部分用空格分隔 |
| < headers >、< blank line >和{ < response-body > } | 之后的部分个请求体格式中的差别不大 |
(7)HTTP状态码分类及常用状态码(重要)
【1】状态码以第一个数字代表当前响应的类型,具体的规定如下表:
| 状态码 | 大类含义 | 解释 |
| 1XX | 消息 | 请求已经被服务器接收,继续处理 |
| 2XX | 成功 | 请求已经成功被服务器接收、理解并接收 |
| 3XX | 重定向 | 需要后续操作才能完成这一请求 |
| 4XX | 请求错误 | 请求含有词法错误或者无法被执行 |
| 5XX | 服务器错误 | 服务器在处理某个正确请求的时候发生错误 |
【2】HTTP常用的状态码
| 状态码 | 含义 | 说明 |
| 200 | OK | 找到了资源,并且一切正常 |
| 304 | NOT MODIFIED | 该资源在上次请求之后没有任何修改(这通常用于浏览器的缓存机制) |
| 401 | UNAUTHORIZED | 客户端无权访问该资源(这通常会使得浏览器要求用户输入用户名和密码,以登录到服务器) |
| 403 | FORBIDDEN | 客户端未能获得授权(这通常是在401之后输入了不正确的用户名或密码) |
| 404 | NOT FOUND | 在指定的位置不存在所申请的资源 |
| 405 | METHOD NOT ALLOWED | 不支持对应的请求方法 |
| 501 | NOT IMPLEMEMTED | 服务器不能识别请求或者未实现指定的请求 |















 2530
2530











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









