






感知机是一种经典的神经网络算法,用于数据分类。其图形化展示如下图,相互连接的神经元
j
j
j和神经元
k
k
k做了放大处理,我们可以更清楚地了解感知机中每个神经元的计算逻辑。
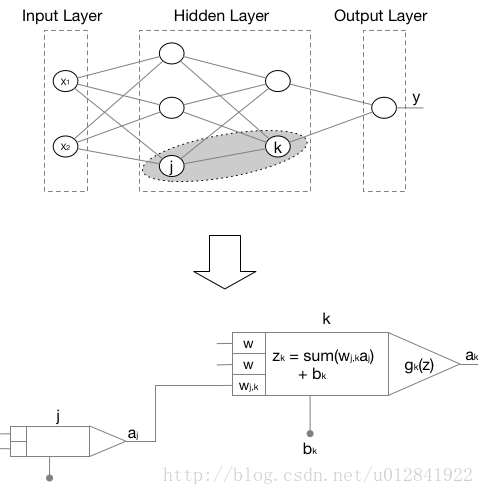
其中,输入层
x
1
x_1
x1和
x
2
x_2
x2对应于一条有两个特征的数据,输出层
y
y
y表示这条数据的标签(类别)。对于神经元
k
k
k,接收它左侧三个神经元的输出,作为其输入。每一个输入配有一个权重
w
j
k
w_{jk}
wjk,因此,神经元
k
k
k接收的输入总和为
z
k
=
∑
j
w
j
k
a
j
+
b
k
z_k = \sum\limits_j w_{jk}a_j + b_k
zk=j∑wjkaj+bk。
g
k
(
z
)
g_k(z)
gk(z)是神经元
k
k
k的激活函数,其结果
a
k
a_k
ak作为神经元
k
k
k的输出。即:
a
k
=
g
k
(
∑
j
w
j
k
a
j
+
b
k
)
a_k = g_k(\sum\limits_j w_{jk}a_j + b_k)
ak=gk(j∑wjkaj+bk)
常见的激活函数有:

学习策略
此处,我们以双输入单神经元感知机,
s
g
n
_
f
u
n
c
sgn\_func
sgn_func作为激活函数为例开始讲解感知机的学习策略。如下图:
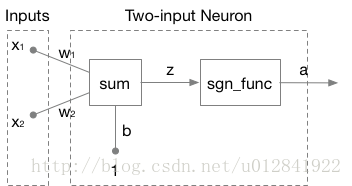
如上神经网络的输出定义为
a
=
s
g
n
(
W
T
X
+
b
)
=
s
g
n
(
w
1
x
1
+
w
2
x
2
+
b
)
a = sgn(W^TX + b) = sgn(w_1x_1 + w_2x_2 + b)
a=sgn(WTX+b)=sgn(w1x1+w2x2+b),决策边界定义为
z
=
W
T
X
+
b
=
w
1
x
1
+
w
2
x
2
+
b
=
0
z = W^TX + b = w_1x_1 + w_2x_2 + b = 0
z=WTX+b=w1x1+w2x2+b=0。其图形化展示如下:
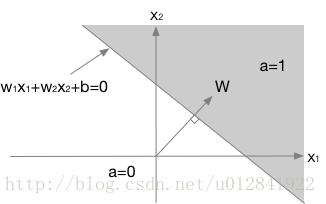
其中, W W W为决策边界 W T X + b = 0 W^TX + b = 0 WTX+b=0的法向量,始终垂直于决策边界。
对于输入数据
{
x
1
=
[
1
2
]
,
y
1
=
1
}
{
x
2
=
[
−
0.5
2
]
,
y
2
=
0
}
{
x
3
=
[
−
0.5
−
1
]
,
y
3
=
0
}
\{ x_1 = \begin{bmatrix} 1\\ 2 \end{bmatrix}, y_1 = 1\} \{ x_2 = \begin{bmatrix} -0.5\\ 2 \end{bmatrix}, y_2 = 0\} \{ x_3 = \begin{bmatrix} -0.5\\ -1 \end{bmatrix}, y_3 = 0\}
{x1=[12],y1=1}{x2=[−0.52],y2=0}{x3=[−0.5−1],y3=0},下图中空心圆表示
y
i
=
0
y_i = 0
yi=0,实心圆表示
y
i
=
1
y_i = 1
yi=1。感知机的学习策略步骤如下:
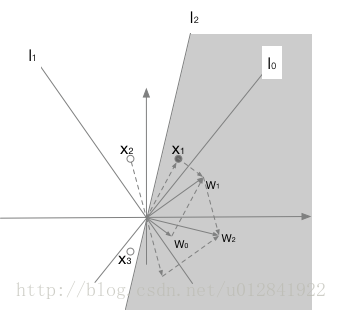
- 令 x i 0 = 1 x_i^0 = 1 xi0=1和 w 0 = b w_0 = b w0=b,我们随机初始化 W W W构建感知机模型 l 0 : W 0 X = 0 l_0: W_0 X=0 l0:W0X=0;
- 在决策边界 l 0 l_0 l0的分类下,发现 x 1 x_1 x1被错误分类,即 y = 1 , a = 0 y = 1, a = 0 y=1,a=0。因此,参数更新公式有 W 1 = W 0 + x 1 W_1 = W_0 + x_1 W1=W0+x1(新的参数向量 W 1 W_1 W1使得新的决策边界 l 1 l_1 l1向 x 1 x_1 x1的方向旋转);
- 在决策边界 l 1 l_1 l1的分类下,发现 x 2 x_2 x2被错误分类,即 y = 0 , a = 1 y = 0, a = 1 y=0,a=1。因此,参数更新公式有 W 2 = W 1 − x 2 W_2 = W_1 - x_2 W2=W1−x2(新的参数向量 W 2 W_2 W2使得新的决策边界 l 2 l_2 l2向远离 x 2 x_2 x2的方向旋转);
- 在决策边界 l 2 l_2 l2的分类下,发现 x 1 , x 2 , x 3 x_1, x_2, x_3 x1,x2,x3均被正确分类,即 y = 0 , a = 0 y = 0, a = 0 y=0,a=0或 y = 1 , a = 1 y = 1, a = 1 y=1,a=1。因此,参数不再更新。
总结如上两种错误分类情况,即得统一的参数更新公式:
W
n
e
w
=
W
o
l
d
+
(
y
−
a
)
X
W^{new} = W^{old} + (y-a)X
Wnew=Wold+(y−a)X
此参数更新公式对于单隐层多神经元感知机同样适用,不过是 W W W由向量变成了矩阵。
感知机的收敛性
由于
y
−
a
∈
{
−
1
,
1
}
y-a \in \{-1, 1\}
y−a∈{−1,1},可令
W
(
k
+
1
)
=
W
(
k
)
+
X
′
(
k
)
W(k+1) = W(k) +X^{\prime}(k)
W(k+1)=W(k)+X′(k)。其中:
X
′
(
k
)
∈
{
x
1
,
x
2
,
…
,
x
m
,
−
x
1
,
−
x
2
,
…
,
−
x
m
}
X^{\prime}(k) \in \{ x_1, x_2, \dots, x_m, -x_1, -x_2, \dots, -x_m\}
X′(k)∈{x1,x2,…,xm,−x1,−x2,…,−xm}
然后,我们假设感知机存在一个最终解
W
⋆
W^{\star}
W⋆,使得:
W
⋆
T
x
i
>
δ
>
0
∣
y
=
1
W
⋆
T
x
i
<
−
δ
<
0
∣
y
=
0
{W^{\star}}^Tx_i \gt \delta \gt 0 \vert y=1 \\ {W^{\star}}^Tx_i \lt -\delta \lt 0 \vert y=0
W⋆Txi>δ>0∣y=1W⋆Txi<−δ<0∣y=0
其中, δ \delta δ表示某可能很小的正数。结合 X ′ ( k ) X^{\prime}(k) X′(k)的定义,得 W ⋆ T X ′ ( k ) > δ {W^{\star}}^TX^{\prime}(k) \gt \delta W⋆TX′(k)>δ。
P r o o f : \mathcal Proof: Proof:
初始化感知机参数
W
(
0
)
W(0)
W(0)为
0
\mathbf 0
0,经过
k
k
k次迭代后:
W
(
K
)
=
X
′
(
0
)
+
X
′
(
1
)
+
X
′
(
2
)
+
⋯
+
X
′
(
k
−
1
)
W
⋆
T
W
(
K
)
=
W
⋆
T
X
′
(
0
)
+
W
⋆
T
X
′
(
1
)
+
W
⋆
T
X
′
(
2
)
+
⋯
+
W
⋆
T
X
′
(
k
−
1
)
W(K) = X^{\prime}(0) + X^{\prime}(1) + X^{\prime}(2) + \dots + X^{\prime}(k-1) \\ {W^{\star}}^TW(K) = {W^{\star}}^TX^{\prime}(0) + {W^{\star}}^TX^{\prime}(1) + {W^{\star}}^TX^{\prime}(2) + \dots + {W^{\star}}^TX^{\prime}(k-1)
W(K)=X′(0)+X′(1)+X′(2)+⋯+X′(k−1)W⋆TW(K)=W⋆TX′(0)+W⋆TX′(1)+W⋆TX′(2)+⋯+W⋆TX′(k−1)
由于
W
⋆
T
X
′
(
k
)
>
δ
{W^{\star}}^TX^{\prime}(k) \gt \delta
W⋆TX′(k)>δ,得
W
⋆
T
W
(
K
)
>
k
δ
{W^{\star}}^TW(K) \gt k\delta
W⋆TW(K)>kδ。
(
W
⋆
T
W
(
K
)
)
2
=
(
∥
W
⋆
∥
∥
W
(
K
)
∥
cos
θ
)
2
≤
∥
W
⋆
∥
2
∥
W
(
K
)
∥
2
∥
W
(
K
)
∥
2
≥
(
W
⋆
T
W
(
K
)
)
2
∥
W
⋆
∥
2
>
(
k
δ
)
2
∥
W
⋆
∥
2
({W^{\star}}^TW(K))^2 = (\Vert W^{\star} \Vert \Vert W(K) \Vert \cos\theta)^2 \le {\Vert W^{\star} \Vert}^2 {\Vert W(K) \Vert}^2 \\ {\Vert W(K) \Vert}^2 \ge \frac {({W^{\star}}^TW(K))^2}{{\Vert W^{\star} \Vert}^2} \gt \frac {(k\delta)^2}{{\Vert W^{\star} \Vert}^2}
(W⋆TW(K))2=(∥W⋆∥∥W(K)∥cosθ)2≤∥W⋆∥2∥W(K)∥2∥W(K)∥2≥∥W⋆∥2(W⋆TW(K))2>∥W⋆∥2(kδ)2
接下来计算
∥
W
(
K
)
∥
\Vert W(K) \Vert
∥W(K)∥的上界:
∥
W
(
K
)
∥
2
=
W
T
(
K
)
W
(
K
)
=
[
W
(
K
−
1
)
+
X
′
(
K
−
1
)
]
T
[
W
(
K
−
1
)
+
X
′
(
K
−
1
)
]
=
W
T
(
K
−
1
)
W
(
K
−
1
)
+
2
W
T
(
K
−
1
)
X
′
(
K
−
1
)
+
X
′
T
(
K
−
1
)
X
′
(
K
−
1
)
\begin{aligned} & {\Vert W(K) \Vert}^2 = W^T(K)W(K) \\ & = [W(K-1) + X^{\prime}(K-1)]^T[W(K-1) + X^{\prime}(K-1)] \\ & = W^T(K-1)W(K-1) + 2W^T(K-1)X^{\prime}(K-1) + {X^{\prime}}^T(K-1)X^{\prime}(K-1) \end{aligned}
∥W(K)∥2=WT(K)W(K)=[W(K−1)+X′(K−1)]T[W(K−1)+X′(K−1)]=WT(K−1)W(K−1)+2WT(K−1)X′(K−1)+X′T(K−1)X′(K−1)
对于
W
(
K
−
1
)
W(K-1)
W(K−1),决策边界仍处于更新状态中。因此,必有数据被错误分类。如果
y
=
1
,
a
=
0
y = 1, a = 0
y=1,a=0,
W
T
(
K
−
1
)
X
′
(
K
−
1
)
=
W
T
(
K
−
1
)
X
(
K
−
1
)
≤
0
W^T(K-1)X^{\prime}(K-1) = W^T(K-1)X(K-1) \le 0
WT(K−1)X′(K−1)=WT(K−1)X(K−1)≤0;如果
y
=
0
,
a
=
1
y = 0 , a = 1
y=0,a=1,
W
T
(
K
−
1
)
X
′
(
K
−
1
)
=
−
W
T
(
K
−
1
)
X
(
K
−
1
)
≤
0
W^T(K-1)X^{\prime}(K-1) = -W^T(K-1)X(K-1) \le 0
WT(K−1)X′(K−1)=−WT(K−1)X(K−1)≤0(读者可以自行构建二维坐标系验证)。因此:
∥
W
(
K
)
∥
2
≤
∥
W
(
K
−
1
)
∥
2
+
∥
X
′
(
K
−
1
)
∥
2
{\Vert W(K) \Vert}^2 \le \Vert W(K-1) \Vert^2 + \Vert X^{\prime}(K-1) \Vert^2
∥W(K)∥2≤∥W(K−1)∥2+∥X′(K−1)∥2
重复迭代可得:
∥
W
(
K
)
∥
2
≤
∥
X
′
(
0
)
∥
2
+
∥
X
′
(
1
)
∥
2
+
⋯
+
∥
X
′
(
K
−
1
)
∥
2
{\Vert W(K) \Vert}^2 \le \Vert X^{\prime}(0) \Vert^2 + \Vert X^{\prime}(1) \Vert^2 + \dots + \Vert X^{\prime}(K-1) \Vert^2
∥W(K)∥2≤∥X′(0)∥2+∥X′(1)∥2+⋯+∥X′(K−1)∥2
令
Π
=
max
(
∥
X
′
(
i
)
∥
2
)
\Pi = \max(\Vert X^{\prime}(i) \Vert^2)
Π=max(∥X′(i)∥2),得:
∥
W
(
K
)
∥
2
≤
k
Π
{\Vert W(K) \Vert}^2 \le k \Pi
∥W(K)∥2≤kΠ
结合
∥
W
(
K
)
∥
2
>
(
k
δ
)
2
∥
W
⋆
∥
2
{\Vert W(K) \Vert}^2 \gt \frac {(k\delta)^2}{{\Vert W^{\star} \Vert}^2}
∥W(K)∥2>∥W⋆∥2(kδ)2,得:
(
k
δ
)
2
∥
W
⋆
∥
2
<
∥
W
(
K
)
∥
2
≤
k
Π
k
<
Π
∥
W
⋆
∥
2
δ
2
\frac {(k\delta)^2}{{\Vert W^{\star} \Vert}^2} < {\Vert W(K) \Vert}^2 \le k \Pi \\ k < \frac {\Pi {\Vert W^{\star} \Vert}^2}{\delta^2}
∥W⋆∥2(kδ)2<∥W(K)∥2≤kΠk<δ2Π∥W⋆∥2
得证感知机的学习能在有限次数内完成。
感知机的局限性
上面对单层神经元感知机学习策略的讲解和收敛性的证明都基于一个假设:数据是线性可分的。即存在一个超平面能将不同类的数据分隔开。然而,现实中的数据大多是非线性可分的,如下图:
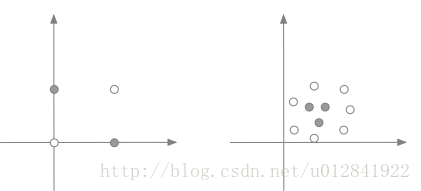
而非线性数据可通过引入多层神经元处理。















 198
198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









