







hi, 大家好,我是宋哈哈,今天分享一个利用 python 的 jieba 库 和 wordcloud 词云库 做一个字符串的词频分析和词云可视化
编程环境:
python 版本:3.6.8
编辑器:pycharm 2020.1.3 专业版
系统环境:win10 专业版
一、在写代码前,需要准备的是 一个做词云的图片,可以百度找,可以自己用PS设计。也可以保存我下方的图片:保存名为 bj.jpg ---> 切记重命名。

二、在编辑器中 新建一个目录叫 “datafile”,用来保存生成好的 EXCEL 和 词云图片。

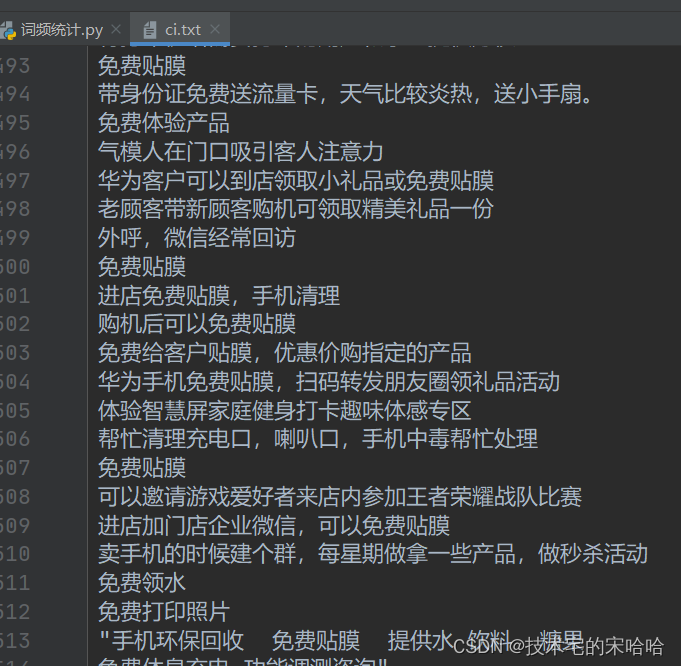
三、新建一个 文本文档 后缀为 txt,名为 ci.txt, 用来存储被 统计的字符串。【不用在乎是否换行】
首先是导入库:如果运行报错的,请 自己安装。
#encoding:utf-8
import re # 正则表达式库
import collections # 词频统计库
import numpy as np # numpy数据处理库
import jieba # 结巴分词
import wordcloud # 词云展示库
from PIL import Image # 图像处理库
import matplotlib.pyplot as plt # 图像展示库
from matplotlib import colors
import csv
import pandas as pd内容代码:
datalist = []
excelFilename = 'H列' # 保存文件名称
def wordFrequency():
# 读取文件
fn = open('ci.txt', 'rt', encoding='utf-8') # 打开文件
string_data = fn.read() # 读出整个文件
fn.close() # 关闭文件
# 文本预处理
pattern = re.compile(u'\t|\n|\.|-|:|;|\)|\(|\?|"') # 定义正则表达式匹配模式
string_data = re.sub(pattern, '', string_data) # 将符合模式的字符去除
# 文本分词
seg_list_exact = jieba.cut(string_data, cut_all=False) # 精确模式分词
object_list = []
remove_words = [u'的', u',', u'和', u'是', u'随着', u'对于', u'对', u'等', u'能', u'都', u'。', u' ', u'、', u'中', u'在', u'了',
u'通常', u'如果', u'我们', u'需要'] # 自定义去除词库
for word in seg_list_exact: # 循环读出每个分词
if word not in remove_words: # 如果不在去除词库中
if len(word) > 2: # 筛选关键词长度
print(word, len(word))
object_list.append(word) # 分词追加到列表
# 词频统计
word_counts = collections.Counter(object_list) # 对分词做词频统计
word_counts_top = word_counts.most_common(200) # 获取前200最高频的词
for words in word_counts_top:
data = [words[0], words[-1]]
datalist.append(data)
# 建立颜色数组,可更改颜色
color_list = ['#0000FF', '#CC0033', '#333333']
# 调用
colormap = colors.ListedColormap(color_list)
# 词频展示
mask = np.array(Image.open('bj.jpg')) # 定义词频背景
wc = wordcloud.WordCloud(
font_path='C:/Windows/Fonts/simhei.ttf', # 设置字体格式
mask=mask, # 设置背景图
max_words=200, # 最多显示词数
max_font_size=100, # 字体最大值
background_color='white',
colormap=colormap,
random_state=18
)
wc.generate_from_frequencies(word_counts) # 从字典生成词云
# image_colors = wordcloud.ImageColorGenerator(mask) # 从背景图建立颜色方案
# wc.recolor(color_func=image_colors) # 将词云颜色设置为背景图方案
wc.to_file(f'datafile/{excelFilename}.jpg')
plt.imshow(wc) # 显示词云
plt.axis('off') # 关闭坐标轴
plt.show() # 显示图像
把统计出来的词频保存为 EXCEL 文件:
def saveExcels():
df = pd.DataFrame(datalist,columns=['词语','词频次数'])
df.to_excel(f'datafile/{excelFilename}.xlsx')
运行代码:
if __name__ == '__main__':
wordFrequency()
saveExcels()
完整代码,复制即可用:
#encoding:utf-8
import re # 正则表达式库
import collections # 词频统计库
import numpy as np # numpy数据处理库
import jieba # 结巴分词
import wordcloud # 词云展示库
from PIL import Image # 图像处理库
import matplotlib.pyplot as plt # 图像展示库
from matplotlib import colors
import csv
import pandas as pd
datalist = []
excelFilename = 'H列' # 保存文件名称
def wordFrequency():
# 读取文件
fn = open('ci.txt', 'rt', encoding='utf-8') # 打开文件
string_data = fn.read() # 读出整个文件
fn.close() # 关闭文件
# 文本预处理
pattern = re.compile(u'\t|\n|\.|-|:|;|\)|\(|\?|"') # 定义正则表达式匹配模式
string_data = re.sub(pattern, '', string_data) # 将符合模式的字符去除
# 文本分词
seg_list_exact = jieba.cut(string_data, cut_all=False) # 精确模式分词
object_list = []
remove_words = [u'的', u',', u'和', u'是', u'随着', u'对于', u'对', u'等', u'能', u'都', u'。', u' ', u'、', u'中', u'在', u'了',
u'通常', u'如果', u'我们', u'需要'] # 自定义去除词库
for word in seg_list_exact: # 循环读出每个分词
if word not in remove_words: # 如果不在去除词库中
if len(word) > 2: # 筛选关键词长度
print(word, len(word))
object_list.append(word) # 分词追加到列表
# 词频统计
word_counts = collections.Counter(object_list) # 对分词做词频统计
word_counts_top = word_counts.most_common(200) # 获取前200最高频的词
for words in word_counts_top:
data = [words[0], words[-1]]
datalist.append(data)
# 建立颜色数组,可更改颜色
color_list = ['#0000FF', '#CC0033', '#333333']
# 调用
colormap = colors.ListedColormap(color_list)
# 词频展示
mask = np.array(Image.open('bj.jpg')) # 定义词频背景
wc = wordcloud.WordCloud(
font_path='C:/Windows/Fonts/simhei.ttf', # 设置字体格式
mask=mask, # 设置背景图
max_words=200, # 最多显示词数
max_font_size=100, # 字体最大值
background_color='white',
colormap=colormap,
random_state=18
)
wc.generate_from_frequencies(word_counts) # 从字典生成词云
# image_colors = wordcloud.ImageColorGenerator(mask) # 从背景图建立颜色方案
# wc.recolor(color_func=image_colors) # 将词云颜色设置为背景图方案
wc.to_file(f'datafile/{excelFilename}.jpg')
plt.imshow(wc) # 显示词云
plt.axis('off') # 关闭坐标轴
plt.show() # 显示图像
def saveExcels():
df = pd.DataFrame(datalist,columns=['词语','词频次数'])
df.to_excel(f'datafile/{excelFilename}.xlsx')
if __name__ == '__main__':
wordFrequency()
saveExcels()如果对你有用,别忘记收藏至浏览器收藏夹。感谢阅读。

















 2633
2633











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











