







- 论文:Point-Voxel CNN for Efficient 3D Deep Learning
- 来源:NeurIPS2019 Spotlight
- 机构:MIT &上交
- 论文:https://arxiv.org/abs/1907.03739
- 代码:https://github.com/mit-han-lab/pvcnn

- 解决问题
- 基于体素的模型的计算成本和内存占用都随输入分辨率呈立方增长,这使得提高分辨率具有内存限制。对于基于点的网络而言,高达80 %的时间浪费在构造记忆局部性较差的稀疏数据上,而不是实际的特征提取上。
- 方法实现
- PVCNN它以点的形式表示 3D 输入数据,以减少内存消耗,同时以体素为单位执行卷积,以减少不规则、稀疏的数据访问并提高局部性。
- 实验结果
- PVCNN在3D物体检测相比Frustrum PointNet++相比
- 2.4%的mAP提升:与Frustrum PointNet++相比,这种新方法在目标检测或分类任务中的准确性提高了2.4%,也就是说,它的平均精度更高。
- 1.5倍速度提升:这个新方法的运行速度比Frustrum PointNet++快1.5倍,处理相同数据所需的时间更少。
- GPU内存减少:此外,这个方法的GPU内存使用量减少了1.5倍,表明它在计算资源的利用上更为高效。
原理介绍
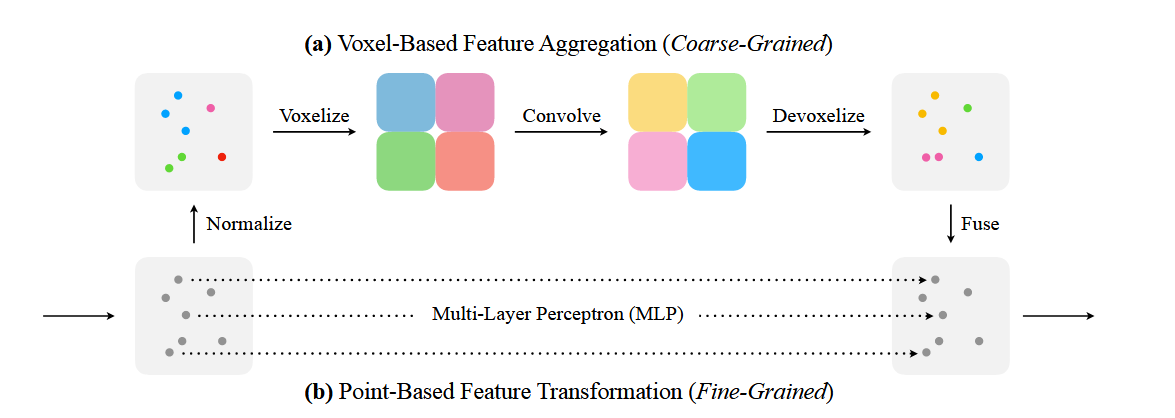
- 体素化 (Voxelization)
- 首先,将点云数据映射到低分辨率的体素网格中。具体来说,点云的坐标先被标准化,然后按照设定的体素分辨率将点的特征聚合到对应的体素网格中。
- 体素卷积 (Voxel Convolution)
- 在体素网格上应用3D卷积操作。由于体素网格是规则的,3D卷积能够有效地聚合邻域内的特征,从而提取出局部的空间特征。
- 体素到点的映射 (Devoxelization)
- 将体素卷积后的特征映射回点云数据中。这一步通常使用三线性插值法,将体素网格的特征分配给其包含的点。这种方式保证了每个点的特征具有足够的分辨率和独特性。
- 点卷积 (Point-Based Feature Transformation)
- 除了体素卷积之外,PVConv还对每个点进行独立的特征提取。通过MLP(多层感知器)对每个点的特征进行细粒度的变换,以补充体素卷积捕捉到的粗粒度信息。
- 特征融合 (Feature Fusion)
- 最终,将从体素卷积和点卷积中提取到的特征进行融合。这通常通过简单的加法操作实现,因为这两个分支提供了互补的信息。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









