






CPU后端(BE)组件在第3.8.2节中进行了讨论。大部分情况下,CPU后端的低效率可以描述为FE已经获取和解码指令,但是BE负载过重,无法处理新指令。从技术上讲,这是一种FE无法传递uops的情况,因为后端缺乏接受新uops所需的资源。其中一个例子是由于数据缓存未命中或除法器负载过重而导致的停顿。
我想强调给读者的建议是,只有当TMA指向较高的“后端限制”指标时,才建议开始优化针对CPU后端的代码。TMA进一步将后端限制指标分为两个主要类别:内存限制和核心限制,我们将在接下来进行讨论。
8.1 Memory Bound //内存受限
当一个应用程序执行大量的内存访问并花费大量时间等待它们完成时,这样的应用程序被称为受内存限制。这意味着要进一步提高其性能,我们可能需要改进内存访问方式、减少此类访问次数或升级内存子系统本身。
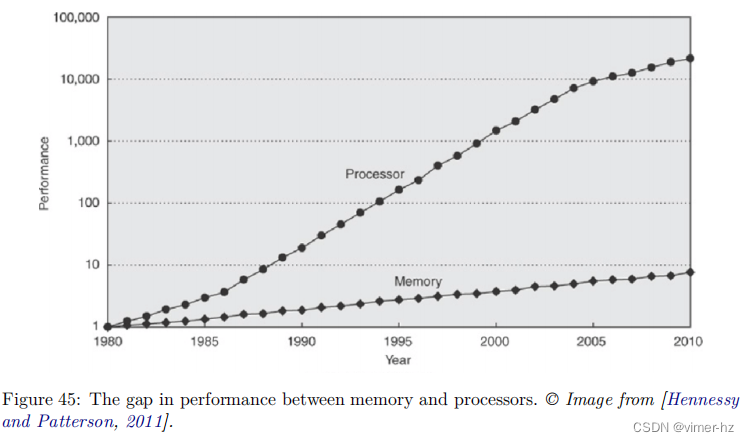
内存层次结构性能非常重要的说法得到了图45的支持。该图显示了内存和处理器之间性能差距的增长。垂直轴采用对数刻度,显示了CPU-DRAM性能差距的增长。内存基线是1980年64KB DRAM芯片的内存访问延迟。典型的DRAM性能改进每年为7%,而CPU每年可以享受20-50%的改进。[Hennessy和Patterson,2011]
在TMA中,内存受限(Memory Bound)估计了CPU流水线由于需求加载或存储指令而可能停顿的插槽比例。解决这类性能问题的第一步是找出导致高内存受限指标的内存访问(请参阅第6.1.4节)。一旦确定了具有问题的内存访问,就可以应用多种优化策略。下面我们将讨论几种典型情况。
8.1.1 Cache-Friendly Data Structures
如果变量在缓存中可以在几个时钟周期内获取,但如果不在缓存中,则从RAM内存中获取该变量可能需要超过一百个时钟周期。关于编写有利于缓存的算法和数据结构的重要性有很多信息,因为这是一个高性能应用程序的关键因素之一。缓存友好代码的关键支柱是时间和空间局部性(请参见第3.5节)的原则,其目标是允许有效地从缓存中获取所需的数据。在设计缓存友好代码时,将变量及其在内存中的位置视为缓存行,而不仅仅是个别变量,这将会很有帮助。
8.1.1.1 Access data sequentially.
利用空间局部性最佳的方法是进行连续的内存访问。通过这样做,我们可以允许硬件预取器(请参见第3.5.1.5.1节)识别内存访问模式,并提前获取下一块数据。在清单19中展示了一个实现这种缓存友好访问的C代码示例。该代码之所以“缓存友好”,是因为它按照内存中的排布顺序(行优先遍历)访问矩阵的元素。如果调换数组索引的顺序(例如,matrix[column][row]),将会导致按列优先遍历矩阵,这不利用空间局部性并且降低性能。
Listing 19 Cache-friendly memory accesses.
for (row = 0; row < NUMROWS; row++)
for (column = 0; column < NUMCOLUMNS; column++)
matrix[row][column] = row + column;清单19中呈现的示例是经典的,但通常实际应用程序比这复杂得多。有时候,为了编写缓存友好的代码,你需要更加深入一些。例如,在一个排序的大数组中,标准的二分查找实现并不利用空间局部性,因为它测试位于彼此相距很远且不共享同一缓存行的不同位置的元素。解决这个问题最著名的方法是使用Eytzinger布局[Khuong和Morin,2015]来存储数组的元素。其思想是使用类似广度优先搜索(BFS)的布局,在一个数组中维护一个隐式的二叉搜索树,通常在二叉堆中可见。如果代码在数组中执行大量的二分查找,将其转换为Eytzinger布局可能会有益处。
8.1.1.2 Use appropriate containers.
几乎每种编程语言都有各种准备好的容器可供使用。但了解它们的底层存储和性能影响是很重要的。选择适当的C++容器的一个很好的逐步指南可以在[Fog, 2004,第9.7章 数据结构和容器类]中找到。
此外,在选择数据存储方式时,要考虑代码对数据的处理方式。考虑这样一种情况:在对象大小较大时,需要在数组中存储对象还是存储指向这些对象的指针之间进行选择。存储指针的数组需要更少的内存。这对于修改数组的操作有益,因为指针数组需要传输的内存较少。然而,如果保留对象本身,则通过数组进行线性扫描将更快,因为它更加缓存友好并且不需要间接内存访问。
8.1.1.3 Packing the data. //使数据更紧凑
通过使数据更紧凑,可以提高内存层次结构的利用率。有许多方法可以压缩数据。其中一个经典示例是使用位域(bitfields)。在清单20中展示了一个可能受益于数据压缩的代码示例。如果我们知道a、b和c表示的是占用一定位数进行编码的枚举值,我们可以减小结构体S的存储空间(参见清单21)。
Listing 20 Packing Data: baseline struct.
struct S {
unsigned a;
unsigned b;
unsigned c;
}; // S is sizeof(unsigned int) * 3Listing 21 Packing Data: packed struct.
struct S {
unsigned a:4;
unsigned b:2;
unsigned c:2;
}; // S is only 1 byte这样做大大减少了来回传输的内存量,并节省了缓存空间。但需要牢记的是,这样做会增加访问每个压缩元素的成本。由于b的位与a和c共享同一机器字(machine word),编译器需要执行右移(>>)和按位与(AND)操作来加载它。类似地,存储值时需要执行左移(<<)和按位或(OR)操作。在计算效率低下的内存传输引起延迟的情况下,数据压缩是有益的。
此外,程序员可以通过重新排列结构体或类中的字段来减少内存使用,以避免编译器添加的填充字节(padding)。编译器插入未使用的内存字节(填充)的原因是为了实现对结构体的各个成员进行有效存储和提取。在示例中,如果按照成员大小递减的顺序声明S1的成员,则可以减小其大小。
8.1.1.4 Aligning and padding.
另一种提高内存子系统利用率的技术是对数据进行对齐。可能会出现这样的情况:一个占据16字节的对象跨越了两个缓存行,即它在一个缓存行上开始,在下一个缓存行上结束。获取这样的对象需要读取两个缓存行,如果对象正确对齐,可以避免这种情况。清单23展示了如何使用C++11的alignas关键字来对齐内存对象。
最有效地访问变量的方式是将其存储在可被变量大小整除的内存地址上。例如,double类型占用8字节的存储空间。因此,最好将其存储在可以被8整除的地址上。大小应始终为2的幂次方。大于16字节的对象应存储在可以被16整除的地址上。
Listing 22 Avoid compiler padding.
struct S1 {
bool b;
int i;
short s;
}; // S1 is sizeof(int) * 3
struct S2 {
int i;
short s;
bool b;
}; // S2 is sizeof(int) * 2Listing 23 Aligning data using the “alignas” keyword.
// Make an aligned array
alignas(16) int16_t a[N];
// Objects of struct S are aligned at cache line boundaries
#define CACHELINE_ALIGN alignas(64)
struct CACHELINE_ALIGN S {
//...
};因此,最好将其存储在可以被8整除的地址上。大小应始终为2的幂次方。大于16字节的对象应存储在可以被16整除的地址上。这样做有助于减少内存带宽的利用,并提高性能。
对齐可能会导致未使用字节的空洞,从而降低内存带宽的利用率。在上面的示例中,如果结构体S只有40字节,那么下一个S对象将从下一个缓存行的开头开始,这意味着每个包含S结构体对象的缓存行将有64 - 40 = 24个未使用的字节。
有时需要填充数据结构成员以避免缓存争用(详见[Fog, 2004, 第9.10章 缓存争用])和伪共享(见第11.7.3节)。例如,在多线程应用程序中,当两个线程A和B访问同一结构体的不同字段时,可能会发生伪共享问题。当成员a和b有可能占用同一缓存行时,缓存一致性问题可能会严重降低程序的速度。为了解决这个问题,可以填充S,使得成员a和b不共享同一缓存行,如清单25所示。
Listing 24 Padding data: baseline version.
struct S {
int a; // written by thread A
int b; // written by thread B
};Listing 25 Padding data: improved version.
#define CACHELINE_ALIGN alignas(64)
struct S {
int a; // written by thread A
CACHELINE_ALIGN int b; // written by thread B
};对于通过malloc进行的动态分配,返回的内存地址保证满足目标平台的最小对齐要求。有些应用程序可能会受益于更严格的对齐要求。例如,使用64字节对齐而不是默认的16字节对齐来动态分配16字节。为了利用这一点,POSIX系统的用户可以使用memalign API。其他用户可以按照这里的描述自行实现。
在对齐考虑中最重要的领域之一是SIMD代码。当依赖编译器自动向量化时,开发人员不需要做任何特殊处理。然而,当您使用编译器矢量内置函数(参见第10.2节)编写代码时,很常见它们要求地址可以被16、32或64整除。编译器内置头文件提供的矢量类型已经进行了注释,以确保适当的对齐。
// ptr will be aligned by alignof(__m512) if using C++17
__m512 * ptr = new __m512[N];8.1.1.5 Dynamic memory allocation.
首先,有许多可以替代malloc的内存分配器,它们更快、更具可伸缩性,并且更好地解决了地址碎片问题。只需使用非标准的内存分配器,就可以获得几个百分点的性能提升。其中一些流行的内存分配库包括jemalloc和tcmalloc。
其次,可以使用自定义分配器来加速分配过程,例如,使用arena分配器。其主要优点之一是开销较低,因为此类分配器不会为每个内存分配执行系统调用。另一个优点是其高度灵活性。开发人员可以基于操作系统提供的内存区域实现自己的分配策略。一个简单的策略是维护两个不同的分配器,每个分配器都有自己的arena(内存区域):一个用于热数据,一个用于冷数据。将热数据放在一起可以提供共享缓存行的机会,从而改善内存带宽利用率和空间局部性。它还改善了TLB利用率,因为热数据占用的内存页面较少。此外,自定义内存分配器可以使用线程本地存储来实现每个线程的分配,并消除线程之间的任何同步。当应用程序基于线程池并且不会生成大量线程时,这将非常有用。
8.1.1.6 Tune the code for memory hierarchy.
对于某些应用程序,性能取决于特定级别缓存的大小。其中最著名的例子是使用循环分块(tiling)改进矩阵乘法的性能。其思想是将矩阵的工作大小分成较小的片段(块),以便每个块都适应L2缓存。
大多数体系结构都提供类似于CPUID的指令,允许我们查询缓存的大小。另外,可以使用缓存无关算法,其目标是在任何缓存大小下都能够良好地工作。
英特尔的CPU具有数据线性地址硬件(见第6.3.3节),支持如easyperf博客文章所描述的缓存分块技术。
通过合理利用缓存结构和缓存相关的特性,可以显著提高应用程序的性能。
8.1.2 Explicit Memory Prefetching //显示内存预取
在通用工作负载中,常常存在数据访问没有明确模式或是随机的情况,因此硬件无法提前有效预取数据(请参考第3.5.1.5.1节中有关硬件预取器的信息)。这些情况下,缓存未命中无法通过选择更好的数据结构来消除。例如,在第26个代码清单中展示了这种情况的一个例子。假设calcNextIndex返回彼此差异显著的随机值。在这种情况下,后续加载arr[j]会指向内存中的完全新位置,并且很可能导致缓存未命中。当arr数组足够大时,硬件预取器将无法捕捉到模式并未能提前获取所需的数据。在第26个示例中,计算索引j和请求元素arr[j]之间存在一段时间窗口。由于这一点,我们可以使用__builtin_prefetch等显式预取指令,如第27个代码清单所示。
使用显式预取指令可以在计算索引和访问该索引对应元素之间的时间窗口中,提前将需要的数据加载到缓存中,从而减少缓存未命中的次数。这样可以显著改善访存性能,在数据访问无明显模式或随机的情况下尤为有效。
Listing 26 Memory Prefetching: baseline version.
for (int i = 0; i < N; ++i) {
int j = calcNextIndex();
// ...
doSomeExtensiveComputation();
// ...
x = arr[j]; // this load misses in L3 cache a lot
}为了让预取提示生效,请确保提前将其插入到适当的位置,以便在加载的值在其他计算中使用之前,它已经存在于缓存中。同时,也不要插入得太早,因为这样可能会污染缓存,使得一段时间内没有使用的数据占据了缓存空间。为了估计预取窗口,可以使用第6.2.5节中描述的方法。
工程师最常使用显式内存预取的场景是获取下一次循环迭代所需的数据。然而,线性函数预取也可以非常有帮助,例如,当您事先知道数据的地址,但在一定延迟(预取窗口)后请求该数据时。这种情况下,线性函数预取能起到很好的作用。
Listing 27 Memory Prefetching: using built-in prefetch hints.
for (int i = 0; i < N; ++i) {
int j = calcNextIndex();
__builtin_prefetch(a + j, 0, 1); // well before the load
// ...
doSomeExtensiveComputation();
// ...
x = arr[j];
}确实,显式内存预取并不可移植,这意味着在一个平台上可以获得性能提升,并不保证在另一个平台上也能获得类似的加速效果。更糟糕的是,当不正确使用时,它可能会恶化缓存的性能。如果使用错误大小的内存块或者过于频繁地请求预取,可能会迫使其他有用的数据从缓存中被驱逐出去。
虽然软件预取能够让程序员具备控制和灵活性,但要正确使用并不总是容易。考虑一种情况,我们想要将预取指令插入到平均IPC为2的代码片段中,每次DRAM访问需要100个周期。为了达到最佳效果,我们需要在加载之前的200个指令处插入预取指令。但这并不总是可能的,特别是当加载地址就在加载本身之前计算时。指针追踪问题可以是显式预取无法解决的一个很好的例子。
最后,显式预取指令会增加代码大小并增加CPU前端的压力。预取指令就像其他任何指令一样,会消耗CPU资源,当使用不当时,可能会降低程序的性能。
8.1.3 Optimizing For DTLB
正如第3节所描述的,TLB是一个快速但有限的核心缓存,用于内存地址的虚拟地址到物理地址的转换。如果没有TLB,每个应用程序的内存访问都需要耗时的内核页表页行走来计算每个引用的虚拟地址的正确物理地址。
TLB层次结构通常包括L1 ITLB(指令)、L1 DTLB(数据)和L2 STLB(指令和数据的统一缓存)。L1 ITLB的缺失通常只会导致非常小的惩罚,通常可以通过乱序执行来隐藏。STLB的缺失将导致调用页行走器。在运行时,这个惩罚可能是明显的,因为在此过程中,CPU会停顿[Suresh Srinivas, 2019]。假设Linux内核中默认的页面大小为4KB,现代的L1级别的TLB缓存只能保存最近使用的几百个页面表项,覆盖大约1MB的地址空间,而L2 STLB则可以保存多达几千个页面表项。具体的数字可以在https://ark.intel.com上找到特定处理器的信息。
在Linux和Windows系统上,应用程序被加载到内存中的是以4KB页面为单位的,默认情况下大多数系统都是这样的。分配许多小页面是昂贵的。如果一个应用程序活跃地引用了数十GB或数百GB的内存,那么就需要很多4KB大小的页面,每个页面都会争夺有限的TLB条目。使用大的2MB页面,可以用只有十个页面就映射20MB的内存,而使用4KB页面则需要5120个页面。这意味着需要更少的TLB条目,从而减少了TLB缺失的次数。无论是Windows还是Linux,都允许应用程序建立大页内存区域。HugeTLB子系统的支持取决于体系结构,而AMD64和Intel 64体系结构均支持2MB(huge)和1GB(gigantic)页面。
正如我们刚刚学到的那样,减少ITLB缺失的一种方法是使用更大的页面大小。值得庆幸的是,TLB也能够缓存2MB和1GB页面的条目。如果前面提到的应用程序使用了2MB页面而不是默认的4KB页面,它将使TLB的压力减少512倍。同样地,如果它从使用2MB页面更新为使用1GB页面,它将再次将TLB的压力减少512倍。这是一个很大的改进!对于某些应用程序来说,使用较大的页面大小可能有益,因为在缓存中用于存储转换的空间较少,可以为应用程序代码提供更多的可用空间。巨大的页面通常会导致更少的页行走,并且由于表本身更紧凑,所以在发生TLB缺失时,在内核页表中进行页行走的惩罚也会降低。
大页面可以用于代码、数据或两者兼而有之。如果您的工作负载有一个大的堆,那么对数据使用大页面是值得尝试的。像关系型数据库系统(如MySQL、PostgreSQL、Oracle等)和配置有大堆区域的Java应用程序这样的大内存应用程序经常受益于使用大页面。在[Suresh Srinivas, 2019]中,有一个使用巨大页面优化运行时的示例,展示了这个功能如何在三个环境中的三个应用程序中提高性能并减少ITLB缺失(最多50%)。
然而,就像其他许多功能一样,大页面并不适用于每个应用程序。如果一个应用程序只想分配一个字节的数据,那么使用4KB页面而不是巨大页面会更好;这样可以更有效地使用内存。
在Linux操作系统上,有两种在应用程序中使用大页面的方式:显式和透明巨大页面。
8.1.3.1 Explicit Hugepages.
作为系统内存的一部分,巨大页面可以作为巨大页面文件系统(hugetlbfs)提供,应用程序可以使用系统调用(例如mmap)来访问它。可以通过cat /proc/meminfo命令和HugePages_Total条目来检查系统上适当配置的巨大页面。巨大页面可以在启动时或运行时进行预留。在启动时进行预留增加了成功的可能性,因为内存尚未被显著碎片化。有关预留巨大页面的详细说明,请参考Red Hat性能调优指南。
还有一种选项是使用libhugetlbfs库,在大型页面之上动态分配内存,该库覆盖了现有动态链接二进制可执行文件中使用的malloc调用。它不需要修改代码甚至重新链接二进制文件;最终用户只需配置几个环境变量即可。它可以同时使用显式预留的巨大页面和透明页面。有关更多详细信息,请参阅libhugetlbfs的操作文档。
对于从代码中对大页面的访问需要更精细控制的情况(即不影响每个内存分配),开发人员有以下替代方案:
• 使用MAP_HUGETLB标志的mmap(示例代码197)。
• 使用挂载的hugetlbfs文件系统中的文件的mmap(示例代码198)。
• 使用SHM_HUGETLB标志的shmget(示例代码199)。
8.1.3.2 Transparent Hugepages.
Linux还提供透明巨大页面支持(THP),它可以自动管理大页面,并对应用程序透明。在Linux下,您可以启用THP,在需要大块内存时动态切换到巨大页面。THP功能有两种操作模式:系统级和进程级。当启用系统级THP时,内核会尝试在可能分配巨大页面的情况下为任何进程分配巨大页面,因此不需要手动预留巨大页面。如果按进程启用了THP,内核仅将巨大页面分配给通过madvise系统调用归属的各个进程的内存区域。您可以使用以下命令检查系统中是否已启用THP:
$ cat /sys/kernel/mm/transparent_hugepage/enabled
always [madvise] never如果值始终为"always"(系统级)或"madvise"(进程级),则THP对您的应用程序可用。使用"madvise"选项,只有通过madvise系统调用标记为MADV_HUGEPAGE的内存区域内启用了THP。有关每个选项的完整规范,可以在Linux内核文档中找到有关THP的文档。
8.1.3.3 Explicit vs. Transparent Hugepages.
与显式巨大页面(EHP)需要提前在虚拟内存中保留不同,THP并不需要。内核在后台尝试分配一个THP,如果失败,将默认使用标准的4k页面。这一切对用户来说都是透明的。分配过程可能涉及多个内核进程,负责为未来的THP在虚拟内存中腾出空间(可能包括将内存交换到磁盘、碎片化或压缩页面)。透明巨大页面的后台维护会带来非确定性的内核延迟开销,因为它管理着不可避免的碎片化和交换问题。而EHP则不会受到内存碎片化的影响,也无法被交换到磁盘上。
其次,EHP可用于应用程序的所有段,包括文本段(即同时受益于DTLB和ITLB),而THP仅适用于动态分配的内存区域。
THP的一个优点是相比EHP需要较少的操作系统配置工作,这有助于加快实验速度。
8.2 Core Bound //核心受限
第二类CPU后端瓶颈是核心限制(Core Bound)。一般来说,该指标表示CPU乱序执行引擎内的所有停顿,并且这些停顿不是由于内存问题引起的。核心限制指标有两个主要类别:
• 硬件计算资源短缺。这表明某些执行单元过载(执行端口争用)。当工作负载频繁执行大量的重型指令时,就会出现这种情况。例如,除法和平方根运算由Divider单元处理,其延迟时间可能比其他指令要长很多。
• 软件指令之间的依赖关系。这表示程序数据流或指令流中的依赖关系限制了性能。例如,依赖浮点运算的高延迟算术操作会导致指令级并行性(ILP)较低。
在本小节中,我们将介绍最常见的优化技术,如函数内联、矢量化和循环优化。这些优化旨在减少执行的指令总数,在工作负载经历高的Retiring指标时也会有所帮助。但作者认为在这里讨论它们是合适的。
8.2.1 Inlining Functions
函数内联是将对函数F的调用替换为针对该调用实际参数进行特化的F代码。内联是最重要的编译器优化之一,不仅可以消除函数调用的开销,还可以启用其他优化。这是因为当编译器内联一个函数时,编译器分析的范围扩大到了更大的代码块。然而,内联也有一些缺点:可能会增加代码大小和编译时间。
在很多编译器中,函数内联的主要机制依赖于某种成本模型。例如,对于LLVM编译器,它基于计算每个函数调用(调用点)的成本和阈值来进行内联。只有当成本小于阈值时才会进行内联。通常,内联一个函数调用的成本基于该函数中指令的数量和类型。阈值通常是固定的,但在某些情况下可以变化。
在这个普遍成本模型周围存在许多启发式规则。例如:
- 微小的函数(包装器)几乎总是会被内联。
- 仅有一个调用点的函数是内联的首选候选对象。
- 大型函数通常不会被内联,因为它们会使调用者函数的代码膨胀。
此外,也存在一些内联存在问题的情况:
- 递归函数无法内联到其自身。
- 通过指针引用的函数可以在直接调用的位置进行内联,但必须保留在二进制文件中,即不能完全内联和消除。对于具有外部链接的函数也是如此。
如前所述,编译器在判断是否内联一个函数时通常采用成本模型方法,这在实践中通常效果良好。一般来说,依靠编译器来做出所有内联决策并在需要时进行调整是一个不错的策略。成本模型无法考虑到每种可能的情况,这给改进留下了空间。有时编译器需要开发人员提供特殊提示。一种找到程序中潜在内联候选的方法是查看分析数据,特别是函数的前导部分和尾声部分的热度。下面是一个函数剖面的示例,其中前导和尾声部分消耗了函数时间的约50%:
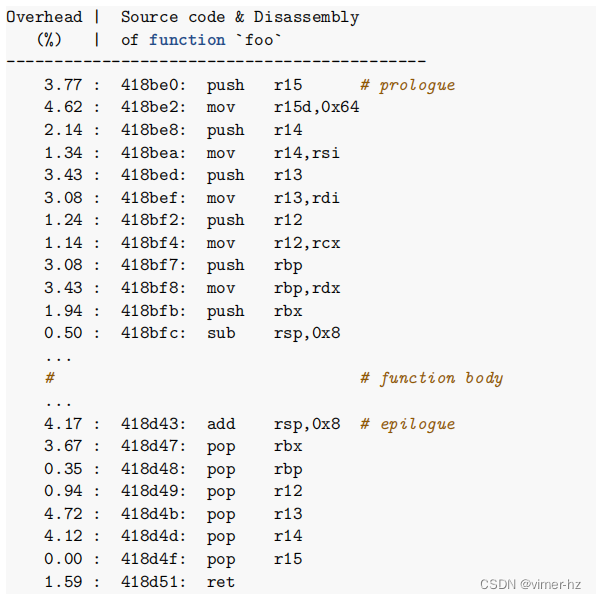
这可能是一个强有力的指标,表明如果我们内联该函数,前导和尾声部分的运行时间可能会被节省下来。需要注意的是,即使前导和尾声部分是热点代码,也不一定意味着内联该函数就会有利可图。内联触发了许多不同的变化,因此很难预测结果。始终通过测量改变后的代码的性能来确认是否需要强制内联。
对于GCC和Clang编译器,可以使用C++11的[[gnu::always_inline]]属性来给内联 foo 函数提供提示,如下所示的代码示例。对于MSVC编译器,可以使用__forceinline关键字。
[[gnu::always_inline]] int foo() {
// foo body
}8.2.2 Loop Optimizations
循环是几乎所有高性能(HPC)程序的核心。由于循环代表着需要执行大量次数的代码片段,因此执行时间的大部分都花费在循环中。对于这样一个关键的代码片段来说,微小的改变可能会对程序的性能产生很大的影响。因此,仔细分析程序中热门循环的性能并了解改进它们的可能选项非常重要。
要有效优化一个循环,关键是了解循环的瓶颈所在。一旦找到了耗时最长的循环,尝试确定其瓶颈。通常情况下,循环的性能受限于以下一个或多个方面:内存延迟、内存带宽或计算机的计算能力。屋顶线性模型(Roofline Performance Model)(第5.5节)是评估不同循环性能与硬件理论极限之间关系的良好起点。自顶向下的微架构分析(Top-Down Microarchitecture Analysis)(第6.1节)也是了解瓶颈信息的另一个良好来源。
通过使用这些工具和方法,可以更好地了解循环的性能问题,并确定如何改进循环以提高程序性能。这包括利用合适的算法、优化数据布局、使用矢量化指令、循环展开、循环分块等技术来减少内存延迟、提高内存带宽和充分利用计算能力。此外,根据具体的硬件架构和应用场景,调整循环的执行策略也非常重要。
在本节中,我们将介绍一些最常见的循环优化方法,以解决前面提到的各种瓶颈类型。首先,我们将讨论低级优化,这些优化只在单个循环内部对代码进行移动。这类优化通常有助于使循环内的计算更加有效。接下来,我们将介绍高级优化,它们对循环进行重构,通常涉及多个循环。第二类优化的目标通常是改善内存访问,消除内存带宽和内存延迟问题。需要注意的是,这里列举的并不是所有已发现的循环变换的完整列表。读者可以参考[Cooper and Torczon,2012]以获取有关每种变换的更详细信息。
编译器可以自动识别执行某种循环变换的机会。然而,有时候需要开发人员的干预才能达到预期的结果。在本节的第二部分,我们将探讨在循环中发现性能改进机会的可能方式。了解对给定循环执行了哪些变换,以及编译器无法做到哪些优化,是成功进行性能调优的关键之一。最后,我们将考虑使用多面体框架优化循环的另一种替代方式。
8.2.2.1 Low-level optimizations.
首先,我们将考虑简单的循环优化,这些优化会转换单个循环内部的代码:循环不变式代码移动(Loop Invariant Code Motion)、循环展开(Loop Unrolling)、循环强度降低(Loop Strength Reduction)和循环不交换(Loop Unswitching)。这些优化通常有助于改善具有高算术密集度的循环的性能(参见第5.5节),即当循环受到CPU计算能力限制时。一般来说,编译器在执行这些转换时表现良好;然而,仍然存在一些情况,编译器可能需要开发人员的支持。我们将在后续章节中讨论这个问题。
Loop Invariant Code Motion (LICM).
在循环中永远不会改变的表达式被称为循环不变式(loop invariants)。由于它们的值在循环迭代过程中保持不变,我们可以将循环不变式表达式移到循环外部。我们可以通过将结果存储在一个临时变量中,并在循环内部使用临时变量来实现这一操作(参见清单28)。
Loop Unrolling.
归纳变量(induction variable)是循环中的一个变量,其值是循环迭代次数的函数。例如,v = f(i),其中i是迭代次数。在每次迭代中修改归纳变量可能很昂贵。相反,我们可以展开循环,并为每个归纳变量的增量执行多次迭代(参见清单29)。循环展开的主要好处是每次迭代可以执行更多的计算。在每次迭代结束时,需要增加索引值、进行测试,并且如果还有更多迭代需要处理,则跳转回循环的顶部。这个工作可以被看作是循环的“税”,可以减少。通过将清单29中的循环展开2倍,我们将执行的比较和分支指令数量减少了一半。

循环展开是一个众所周知的优化方法,但仍然有很多人对此感到困惑,并尝试手动展开循环。我建议开发人员不应该手动展开任何循环。首先,编译器在进行循环展开时表现非常出色,通常能够实现很优化的展开方式。第二个原因是处理器具有“内置展开器”,这得益于其乱序推测执行引擎(参见第3节)。当处理器等待第一次迭代的加载完成时,它可以推测性地开始执行第二次迭代的加载操作。这可以向前跨越多次迭代,在指令重排序缓冲区(ROB)中有效地展开循环。
所以,由于编译器和处理器都能够自动处理循环展开,开发人员无需手动展开循环。这样做更容易导致代码复杂性增加、易错和可读性下降。如果开发人员尝试手动展开循环,可能会产生不必要的代码冗余和维护成本。相反,应该将精力放在编写清晰、简洁且易于理解的代码上,让编译器和处理器负责优化循环展开以提高性能。
Loop Strength Reduction (LSR).
LSR(循环强度降低)的思想是用廉价的指令替换昂贵的指令。这种转换可以应用于所有使用归纳变量的表达式。强度降低通常应用于数组索引。编译器通过分析变量在循环迭代中的演变方式来执行LSR(见清单30)。

Loop Unswitching.
如果一个循环内部包含一个不变的条件判断语句,我们可以将其移到循环外部。这可以通过复制循环体,并将其放置在条件判断语句的if和else子句中的各个版本中来实现(见清单31)。虽然循环拆分可能会使代码量增加一倍,但现在每个新的循环都可以单独进行优化。
循环拆分是一种优化技术,它的目标是减少循环内部的条件判断次数,以提高执行效率。当循环中的条件在每次迭代中都保持不变时,这种优化可以提供更好的性能。
通过将循环体复制到条件判断语句的if和else子句中,我们可以在每个版本的循环中单独进行优化。这样,编译器可以针对不同的条件进行优化,并生成更有效的代码。
虽然循环拆分会导致代码量增加,但这种优化可以提高程序的执行效率。通过分别对每个拆分后的循环进行优化,可以针对不同的条件进行更精细的控制流优化和计算优化,从而获得更好的性能。

8.2.2.2 High-level optimizations.
还有一类循环变换可以改变循环的结构,通常会影响到多个嵌套循环。我们将介绍循环交换、循环分块(瓦片化)以及循环融合和分布(分裂)。这组变换旨在改进内存访问方式,消除内存带宽和内存延迟的瓶颈。从编译器的角度来看,合法且自动地进行高级循环变换非常困难。往往很难证明所做的任何优化的益处。在这种意义上,开发人员处于更好的位置,因为他们只需关注在特定代码段中变换的合法性,而不必考虑可能发生的每种情况。不幸的是,这也意味着我们经常需要手动进行这样的变换。
循环交换、循环分块和循环融合与分布是用于优化内存访问、消除内存带宽和内存延迟瓶颈的重要循环变换技术。循环交换可以改变循环的执行顺序,以优化数据的局部性,并提高缓存效率。循环分块通过将大循环分割成小的块,可以减少对主存的访问次数,以及提高数据重用和并行性。循环融合和分布可以将多个循环合并或拆分,以减少内存访问次数,并提高数据的局部性。
由于进行高级循环变换是非常困难的,因此开发人员通常需要手动进行这些变换,以在特定代码段中实现性能优化。他们需要评估和验证变换的合法性,并权衡所带来的性能提升是否值得投入。编译器很难在所有情况下自动进行这些变换,因此开发人员的角色仍然非常重要。
Loop Interchange.
循环交换是指交换嵌套循环的循环顺序。内部循环中使用的归纳变量切换到外部循环,反之亦然。清单32展示了一个关于i和j的嵌套循环交换的示例。循环交换的主要目的是对多维数组的元素进行顺序内存访问。通过按照内存中元素布局的顺序进行访问,我们可以提高内存访问的空间局部性,并使我们的代码更加缓存友好(见第8.1.1节)。这种转换有助于消除内存带宽和内存延迟的瓶颈。

Loop Blocking (Tiling).
循环分块(瓦片化)的思想是将多维执行范围分割成较小的块(块或瓦片),以便每个块都适合CPU缓存210。如果算法使用大型多维数组,并对其元素进行跨步访问,那么缓存利用率可能很低。每次这样的访问都可能将未来访问所需的数据推出缓存(缓存驱逐)。通过将算法划分为较小的多维块,我们可以确保在循环中使用的数据保持在缓存中直到被重复使用。
在清单33所示的例子中,算法对数组a的元素进行行主序遍历,同时对数组b进行列主序遍历。循环嵌套可以分割为较小的块,以最大程度地重用数组b的元素。

循环分块是一种广为人知的优化一般矩阵乘法(General Matrix Multiplication,GEMM)算法的方法。它增强了内存访问的缓存重用,并改善算法的内存带宽和内存延迟。
Loop Fusion and Distribution (Fission).
当两个循环迭代相同范围并且彼此不引用对方的数据时,可以将它们合并为一个循环。循环融合是将两个独立的循环合并为一个循环的过程。在第34段代码示例中展示了循环融合的例子。另一种相反的操作称为循环分配(分裂),即将循环拆分成多个独立的循环。

循环融合有助于减少循环开销(参见循环展开讨论),因为两个循环可以使用相同的归纳变量。此外,循环融合可以提高内存访问的时间局部性。在第34段代码示例中,如果结构体的 x 和 y 成员恰好位于同一缓存行上,最好将两个循环融合起来,因为我们可以避免重复加载同一缓存行。这将减少缓存占用,并提高内存带宽利用率。
然而,并非总是循环融合能够提高性能。有时候将一个循环拆分为多个阶段、预先过滤数据、排序和重组数据等操作会更好。通过将大循环分割成多个较小的循环,可以限制每次循环迭代所需的数据量,从而有效地增加内存访问的时间局部性。这对于存在高缓存争用的情况特别有帮助,而这通常发生在大型循环中。循环分配还可以减少寄存器压力,因为在每次循环迭代中执行的操作更少。此外,将大循环拆分为多个较小的循环还有助于CPU前端的性能,因为可以更好地利用指令缓存(参见第7节)。最后,分布式后,编译器可以单独对每个小循环进行进一步优化。
8.2.2.3 Discovering loop optimization opportunities.
正如我们在本节开头讨论的那样,编译器将承担优化循环的繁重工作。您可以依靠它们来对循环代码进行所有明显的改进,比如消除不必要的工作、进行各种peephole优化等。有时候编译器足够聪明,可以默认生成快速版本的循环,而其他情况下我们需要自己进行一些重写来帮助编译器。正如之前所说,从编译器的角度来看,合法且自动地进行循环转换是非常困难的。通常,当编译器无法证明变换的合法性时,它必须保守处理。
考虑列表35中的代码。编译器无法将表达式strlen(a)移出循环体。因此,循环在每次迭代中检查字符串是否到达末尾,这显然是慢速的。编译器不能提升这个调用的原因是,数组a和b的内存区域可能重叠。在这种情况下,将strlen(a)移出循环体是不合法的。如果开发者确信内存区域不会重叠,他们可以在foo函数的两个参数上使用restrict关键字声明,即char* __restrict__ a。

有时候,编译器可以通过编译优化备注(参见第5.7节)告知我们转换失败的情况。然而,在这种情况下,无论是Clang 10.0.1还是GCC 10.2都无法明确告知表达式strlen(a)未被提升出循环。唯一的方法是根据应用程序的配置文件查看生成的汇编代码的热点部分。分析机器代码需要基本的汇编语言阅读能力,但这是一项非常有价值的活动。
首先尝试获取最容易的优化是一个合理的策略。开发者可以使用编译器优化报告或检查循环的机器代码以寻找简单的改进方法。有时候,我们可以通过使用用户指令来调整编译器的转换。例如,当我们发现编译器将我们的循环展开了4倍时,我们可以检查是否使用更高的展开系数会提高性能。大多数编译器都支持#pragma unroll(8),它会指示编译器使用用户指定的展开系数。还有其他的指令来控制特定的转换,比如循环向量化、循环分布等。有关完整的用户指令列表,请查阅编译器的手册。
接下来,开发者应该确定循环中的瓶颈,并根据硬件的理论最大性能进行评估。可以首先使用Roofline性能模型(第5.5节),它将揭示开发者应该尝试解决的瓶颈。循环的性能受以下因素之一或多个因素的限制:内存延迟、内存带宽或机器的计算能力。一旦确定了循环的瓶颈,开发者可以尝试应用本节前面讨论过的转换技术之一。
个人经验:尽管针对特定的计算问题有众所周知的优化技术,但在很大程度上,循环优化是一种需要经验的“黑魔法”。我建议您依靠编译器,只有在必要时才进行必要的转换。最后,保持代码尽可能简单,如果性能提升微不足道,不要引入过于复杂的改变。
8.2.2.4 Use Loop Optimization Frameworks
在过去的几年中,研究人员们开发了一些技术来确定循环转换的合法性并自动对循环进行转换。其中一个创新是多面体框架(polyhedral framework)。GRAPHITE是最早集成到生产编译器中的多面体工具之一。GRAPHITE基于从GCC的低级中间表示GIMPLE中提取的多面体信息,执行一系列经典的循环优化。GRAPHITE证明了该方法的可行性。
基于LLVM的编译器使用自己的多面体框架:Polly。Polly是一个面向LLVM的高级循环和数据局部性优化器及优化基础设施。它使用基于整数多面体的抽象数学表示来分析和优化程序的内存访问模式。Polly执行经典的循环转换,特别是瓦片化和循环合并,以改善数据局部性。该框架在许多著名基准测试中实现了显著的加速(Grosser等人,2012年)。下面是一个示例,展示了Polly如何将Polybench 2.0基准套件中的GEneral Matrix-Multiply(GEMM)核心的速度提升近30倍:
$ clang -O3 gemm.c -o gemm.clang
$ time ./gemm.clang
real 0m6.574s
$ clang -O3 gemm.c -o gemm.polly -mllvm -polly
$ time ./gemm.polly
real 0m0.227sPolly是一个强大的循环优化框架,然而它仍然无法处理一些常见且重要的情况。在LLVM基础设施的标准优化流程中,Polly并未启用,并且需要用户显式地提供编译器选项来使用它(-mllvm -polly)。当寻找加速循环的方法时,使用多面体框架是一个可行的选择。
8.2.3 Vectorization //向量化
在现代处理器上,使用SIMD指令可以比常规的非矢量化(标量)代码实现显著加速。在进行性能分析时,软件工程师最重要的任务之一是确保热点代码由编译器进行向量化处理。本节旨在引导工程师发现向量化的机会。回顾一下关于现代CPU的SIMD能力的一般信息,读者可以参考第3.7节。
大多数向量化都是自动完成的,无需用户干预(自动向量化)。也就是说,编译器会自动识别源代码中产生SIMD机器代码的机会。依赖自动向量化是一个很好的策略,因为现代编译器可以为各种源代码输入生成快速的向量化代码。正如前面给出的建议一样,作者建议让编译器完成其工作,只有在必要时才进行干预。
在一些罕见的情况下,软件工程师需要根据从编译器或分析数据中获得的反馈来调整自动向量化。在这种情况下,程序员需要告诉编译器某个代码区域是可向量化的,或者向量化是有益的。现代编译器具有扩展功能,允许高级用户直接控制向量化器,并确保代码的某些部分得到高效的向量化处理。后续章节将提供使用编译器提示的几个示例。
需要注意的是,在一些问题中,SIMD具有无可替代的价值,而自动向量化并不起作用,并且在不久的将来也不太可能起作用(可以参考[Muła和Lemire, 2019]中的一个示例)。如果编译器无法生成所需的汇编指令,可以借助编译器内置函数来重写代码片段。在大多数情况下,编译器内置函数提供了与汇编指令的一对一映射(请参见第10.2节)。
个人意见:尽管在某些情况下开发人员需要使用编译器内置函数,但我建议主要依赖编译器的自动向量化,只有在必要时才使用内置函数。使用编译器内置函数的代码类似于内联汇编,很快就会变得难以理解。编译器的自动向量化通常可以通过pragma和其他提示进行调整。
一般来说,编译器会进行三种类型的向量化:内部循环向量化、外部循环向量化和SLP(超级字级并行)向量化。本节主要讨论内部循环向量化,因为这是最常见的情况。关于外部循环和SLP向量化,我们在附录B中提供了一般信息。
8.2.3.1 Compiler Autovectorization.
许多因素可能阻碍自动向量化,其中一些因素与编程语言的语义相关。例如,编译器必须假设无符号循环索引可能会溢出,这可能会阻止某些循环转换。另一个例子是C语言的假设:程序中的指针可以指向重叠的内存区域,这会使程序的分析变得非常困难。另一个主要障碍是处理器本身的设计。在某些情况下,处理器对于某些操作没有高效的向量指令。例如,在大多数处理器上不支持执行受位掩码控制的加载和存储操作。另一个例子是有符号整数到双精度浮点数的向量宽度格式转换,因为结果涉及不同大小的向量寄存器。
尽管存在所有这些挑战,软件开发人员可以解决其中许多问题并启用向量化。在本节的后面部分,我们将提供如何与编译器合作并确保热点代码由编译器进行向量化的指导。
向量化器通常分为三个阶段:合法性检查、盈利性检查和转换本身:
- 合法性检查:在此阶段,编译器检查是否可以将循环(或其他代码区域)转换为使用向量。循环向量化器检查循环的迭代是否连续,即循环按线性方式进行。向量化器还确保循环中的所有内存和算术操作可以扩展为连续操作,循环的控制流在所有通道上都是统一的,并且内存访问模式是统一的。编译器必须检查或确保生成的代码不会触及不应该触及的内存,并且操作的顺序将被保留。编译器需要分析指针的可能范围,如果有一些缺失的信息,它必须假设转换是非法的。合法性阶段收集了一系列必须满足的要求,以使循环向量化合法。
- 盈利性检查:然后,向量化器检查转换是否具有盈利性。它比较不同的向量化因素,并确定哪个向量化因素执行速度最快。向量化器使用成本模型来预测不同操作(例如标量加法或向量加载)的成本。它需要考虑将数据洗牌到寄存器中的附加指令,预测寄存器压力,并估算确保满足允许向量化的前提条件的循环保护的成本。检查盈利性的算法很简单:1)累加代码中所有操作的成本,2)比较每个代码版本的成本,3)将成本除以预期执行计数。例如,如果标量代码花费8个周期,而向量化代码花费12个周期,但一次执行4个循环迭代,则向量化版本的循环可能更快。
- 转换:最后,在向量化器确定转换是合法且具有盈利性之后,它们会转换代码。这个过程还包括插入启用向量化的保护。例如,大多数循环使用未知的迭代计数,因此编译器必须生成循环的标量版本以及向量化的版本,以处理最后几次迭代。编译器还必须检查指针是否重叠等。所有这些转换都使用在合法性检查阶段收集的信息进行。
8.2.3.2 Discovering vectorization opportunities.
Amdahl定律告诉我们,在程序执行过程中,我们应该花时间仅分析那些最常使用的代码部分。因此,性能工程师应该专注于通过分析工具(见5.4节)突出显示的热点代码部分。正如前面提到的,向量化最常用于循环。
发现改进向量化的机会应该从分析程序中的热点循环开始,并检查编译器对它们进行了哪些优化。检查编译器的向量化备注(见5.7节)是了解这一点的最简单方法。现代编译器可以报告一个特定循环是否被向量化,并提供额外的细节,例如向量化因子(VF)。如果编译器无法将一个循环向量化,它也能告诉失败的原因。
使用编译器优化报告的另一种方法是检查汇编输出。最好分析来自性能分析工具的输出,该工具显示给定循环的源代码与生成的汇编指令之间的对应关系。然而,这种方法需要具备读取和理解汇编语言的能力。想要弄清楚编译器生成的指令的语义可能需要一些时间218。但是这种技能是非常有价值的,并且通常可以提供额外的见解。例如,我们可以发现生成的代码存在不够优化的问题,比如缺乏向量化、向量化因子不够优化、执行不必要的计算等。
在尝试加速可向量化代码时,开发人员经常遇到几种常见情况。下面我们介绍四个典型场景,并给出在每种情况下的一般指导。
8.2.3.3 Vectorization is illegal.
在某些情况下,遍历数组元素的代码可能无法进行向量化。向量化备注非常有效地解释了出现问题的原因,以及编译器无法对代码进行向量化的原因。第36条示例展示了一个循环内的依赖关系,阻止了向量化。
Listing 36 Vectorization: read-after-write dependence.
void vectorDependence(int *A, int n) {
for (int i = 1; i < n; i++)
A[i] = A[i-1] * 2;
}虽然由于上述的硬性限制,有些循环无法进行向量化,但在某些约束条件放宽的情况下,其他循环可能是可以进行向量化的。有些情况下,编译器无法对循环进行向量化,是因为它无法证明向量化是合法的。编译器通常非常保守,只有在确保不会破坏代码的情况下才进行转换。通过向编译器提供额外的提示,可以放宽这种软性限制。例如,在转换执行浮点算术运算的代码时,向量化可能会改变程序的行为。浮点加法和乘法是可交换的,也就是说,可以交换左操作数和右操作数而不改变结果:(a + b == b + a)。然而,这些操作不是可结合的,因为舍入发生的时间不同:((a + b) + c) != (a + (b + c))。第37条示例中的代码无法通过编译器自动进行向量化。原因是向量化会将变量sum转换为向量累加器,这会改变操作的顺序,并可能导致不同的舍入决策和不同的结果。
Listing 37 Vectorization: flfloating-point arithmetic.
1 // a.cpp
2 float calcSum(float* a, unsigned N) {
3 float sum = 0.0f;
4 for (unsigned i = 0; i < N; i++) {
5 sum += a[i];
6 }
7 return sum;
8 }然而,如果程序在最终结果上可以容忍一点不准确性(通常是这种情况),我们可以将这个信息传递给编译器以启用向量化。Clang和GCC编译器提供了一个标志 -ffast-math220,允许进行此类转换:
$ clang++ -c a.cpp -O3 -march=core-avx2 -Rpass-analysis=.*
...
a.cpp:5:9: remark: loop not vectorized: cannot prove it is safe to reorder
floating-point operations; allow reordering by specifying '#pragma clang
loop vectorize(enable)' before the loop or by providing the compiler
option '-ffast-math'. [-Rpass-analysis=loop-vectorize]
...
$ clang++ -c a.cpp -O3 -ffast-math -Rpass=.*
...
a.cpp:4:3: remark: vectorized loop (vectorization width: 4, interleaved
count: 2) [-Rpass=loop-vectorize]
...让我们再来看另一个典型情况,当编译器无法证明循环在非重叠内存区域上操作时,它通常选择保守一点。让我们回顾一下第5.7节中提供的第9条示例。当编译器尝试对第38条示例中的代码进行向量化时,通常无法做到这一点,因为数组a、b和c的内存区域可能重叠。
Listing 38 a.c
1 void foo(float* a, float* b, float* c, unsigned N) {
2 for (unsigned i = 1; i < N; i++) {
3 c[i] = b[i];
4 a[i] = c[i-1];
5 }
6 }这是由GCC 10.2提供的优化报告(使用-fopt-info启用):
$ gcc -O3 -march=core-avx2 -fopt-info
a.cpp:2:26: optimized: loop vectorized using 32 byte vectors
a.cpp:2:26: optimized: loop versioned for vectorization because of possible
aliasingGCC已经识别出数组a、b和c的内存区域可能存在重叠,并创建了同一个循环的多个版本。编译器插入了运行时检查来检测内存区域是否重叠。根据这些检查,它在向量化和标量化版本之间进行调度。在这种情况下,向量化带来了插入潜在昂贵的运行时检查的成本。如果开发人员知道数组a、b和c的内存区域不重叠,可以在循环前面插入#pragma GCC ivdep或使用__restrict__关键字,如第10条示例中所示。这样的编译器提示将消除GCC编译器插入之前提到的运行时检查的需要。
由于编译器的本质是静态工具,它们只根据它们处理的代码进行推理。例如,一些动态工具(如Intel Advisor)可以检测给定循环中是否实际发生了跨迭代依赖或对具有重叠内存区域的数组的访问等问题。但请注意,这类工具只提供建议。轻率地插入编译器提示可能会引起真正的问题。
8.2.3.4 Vectorization is not beneficial.
在某些情况下,编译器可以对循环进行向量化,但认为这样做并不划算。在第39条示例中的代码中,编译器可以对数组A的内存访问进行向量化,但需要将对数组B的访问拆分为多个标量加载。散射/聚集模式相对昂贵,而能够模拟操作成本的编译器通常决定避免向具有这种模式的代码进行向量化。
Listing 39 Vectorization: not benefificial.
1 // a.cpp
2 void stridedLoads(int *A, int *B, int n) {
3 for (int i = 0; i < n; i++)
4 A[i] += B[i * 3];
5 }以下是第39条代码的编译器优化报告:
$ clang -c -O3 -march=core-avx2 a.cpp -Rpass-missed=loop-vectorize
a.cpp:3:3: remark: the cost-model indicates that vectorization is not
beneficial [-Rpass-missed=loop-vectorize]
for (int i = 0; i < n; i++)
^用户可以使用#pragma hint指令来强制Clang编译器对循环进行向量化,如第40条示例所示。然而,请记住,向量化是否具有盈利性在很大程度上取决于运行时数据,例如循环的迭代次数。编译器没有这些信息可用,因此它们通常倾向于保守处理。开发人员可以在寻找性能提升空间时使用这类提示。
Listing 40 Vectorization: not benefificial.
1 // a.cpp
2 void stridedLoads(int *A, int *B, int n) {
3 #pragma clang loop vectorize(enable)
4 for (int i = 0; i < n; i++)
5 A[i] += B[i * 3];
6 }开发人员应该意识到使用向量化代码的隐藏成本。使用AVX和尤其是AVX512向量指令会导致频率大幅降低。代码的向量化部分应该足够热门,以证明使用AVX512是合理的。
8.2.3.5 Loop vectorized but scalar version used. //循环被向量化,但使用了标量版本。
在某些情况下,编译器可以成功地对代码进行向量化,但向量化代码在分析器中不可见。当检查循环的相应汇编代码时,通常很容易找到循环主体的向量化版本,因为它使用了向量寄存器,这在程序的其他部分通常不常见,并且代码被展开并填充了检查和多个版本,以适应不同的边缘情况。
如果生成的代码没有被执行,可能的原因之一是编译器生成的代码假设循环的迭代次数比程序实际使用的要高。例如,在现代CPU上有效地进行向量化,程序员需要使用AVX2进行向量化,并将循环展开4-5次,以便为流水线化的FMA单元生成足够的工作。这意味着每次循环迭代需要处理大约40个元素。许多循环的迭代次数可能低于此值,并且可能回退到使用标量的剩余循环。通过分析器可以轻松发现这些情况,标量的剩余循环会变得明显,而向量化代码则保持不活跃。
解决这个问题的方法是强制向量化器使用较低的向量化因子或展开次数,以减少循环处理的元素数量,并使更多迭代次数较低的循环访问快速向量化的循环主体。开发人员可以通过#pragma hints指令来实现这一点。对于Clang编译器,可以使用#pragma clang loop vectorize_width(N),如easyperf博客中所示。
8.2.3.6 Loop vectorized in a suboptimal way
当你看到一个循环被向量化并在运行时执行时,通常意味着程序的这部分已经表现良好。然而,也有例外情况。有时候人工专家可以提出比编译器生成的代码更高效的代码。
最优的向量化因子可能不直观,原因有几个。首先,对于人类来说,想象CPU内部的操作是困难的,除了实际尝试多种配置外别无选择。涉及多个向量通道的向量重组操作可能比预期的更加昂贵,这取决于许多因素。其次,在运行时,程序可能以不可预测的方式行为,这取决于端口压力和许多其他因素。建议是尝试强制向量化器选择特定的向量化因子和展开因子,并测量结果。向量化指令可以帮助用户枚举不同的向量化因子,并找出最高性能的一种。
对于每个循环来说,可能的配置相对较少,而在典型输入上运行循环是人类能做到而编译器无法做到的。
最后,有些情况下,标量的未向量化版本的循环性能比向量化版本好。这可能是因为向量操作(如gather/scatter加载、掩码、重组等)很耗费资源,而编译器为了实现向量化必须使用这些操作。性能工程师也可以尝试以不同的方式禁用向量化。对于Clang编译器,可以通过编译选项-fno-vectorize和-fno-slp-vectorize来禁用,或者使用特定于特定循环的提示,例如#pragma clang loop vectorize(enable)。
8.2.3.7 Use languages with explicit vectorization.
向量化也可以通过使用专门用于并行计算的编程语言重写程序的部分来实现。这些语言使用特殊的结构和对程序数据的了解,将代码高效地编译成并行程序。最初,这些语言主要用于将工作转移到特定的处理单元,例如图形处理单元(GPU)、数字信号处理器(DSP)或可编程门阵列(FPGA)。然而,一些编程模型也可以针对CPU进行优化(例如OpenCL和OpenMP)。
其中一种并行语言是Intel® Implicit SPMD Program Compiler(ISPC),我们将在本节中介绍一些。ISPC语言基于C编程语言,并使用LLVM编译器基础架构为许多不同的体系结构生成优化代码。ISPC的关键特性是"接近底层"的编程模型和在SIMD体系结构上的性能可移植性。它要求从传统的编程思维方式转变,但给程序员更多控制CPU资源利用的权力。
ISPC的另一个优点是其互操作性和易用性。ISPC编译器生成的是标准的目标文件,可以与传统的C/C++编译器生成的代码链接。由于使用ISPC编写的函数可以像使用C代码一样调用,因此ISPC代码可以轻松地插入任何本地项目中。
在 ISPC 中,我们可以使用类似于程序清单 37 中展示的简单函数的示例来重写代码。ISPC将程序视为基于目标指令集的并行实例运行。例如,当使用 SSE 和浮点数时,它可以同时计算 4 个操作。每个程序实例将对向量值 i 进行操作,如 (0,1,2,3),然后是 (4,5,6,7),以此类推,从而一次有效地计算出 4 个和。正如您所看到的,使用了一些不典型于 C 和 C++ 的关键字:
• export 关键字表示该函数可以从与 C 兼容的语言中调用。
• uniform 关键字表示变量在程序实例之间共享。
• varying 关键字表示每个程序实例都有自己的变量副本。
• foreach 关键字与经典的 for 循环相同,只是它将工作分布在不同的程序实例之间。
Listing 41 ISPC version of summing elements of an array.
export uniform float calcSum(const uniform float array[],
uniform ptrdiff_t count)
{
varying float sum = 0;
foreach (i = 0 ... count)
sum += array[i];
return reduce_add(sum);
}由于函数 calcSum 必须返回一个单一值(一个 uniform 变量),而我们的 sum 变量是 varying 类型的,因此我们需要使用 reduce_add 函数来收集每个程序实例的值。ISPC还会根据需要生成 peeled 循环和余数循环,以考虑那些没有正确对齐或不是向量宽度的倍数的数据。
“贴近底层”的编程模型。传统的 C 和 C++ 语言存在一个问题,即编译器并不总是对代码的关键部分进行向量化优化。通常情况下,程序员会使用编译器内置函数(参见第10.2节),这绕过了编译器的自动向量化,但一般而言比较困难,并且需要在新的指令集出现时进行更新。ISPC通过默认将每个操作都视为SIMD操作来帮助解决这个问题。例如,ISPC 语句 sum += array[i] 在隐式中被视为一个并行进行多次相加的SIMD操作。ISPC不是一个自动向量化的编译器,它不会自动发现向量化的机会。由于 ISPC 语言与 C 和 C++ 非常相似,相比使用内置函数,ISPC 更好地允许您专注于算法而不是低级指令。此外,据报道,在性能方面,ISPC 的性能与手写的内置函数代码相媲美[Pharr 和 Mark 2012]或超越[228]。
性能可移植性。ISPC 可以自动检测 CPU 的特性,以充分利用所有可用的资源。程序员可以编写一次 ISPC 代码,然后编译为许多矢量指令集,如 SSE4、AVX 和 AVX2。ISPC 还可以为不同的架构生成代码,如 x86 CPU、ARM NEON,并且还具有实验性的对 GPU 卸载的支持。
8.3 Chapter Summary
• 大多数实际应用程序经历的性能瓶颈与 CPU 后端相关。这并不奇怪,因为与内存相关的问题以及低效的计算都属于这个类别。
• 内存子系统的性能增长速度不及 CPU 的性能增长速度。然而,在许多应用程序中,内存访问是性能问题的常见来源。加速这类程序需要重新审查它们访问内存的方式。
• 在第8.1节中,我们讨论了一些常见的缓存友好数据结构、内存预取和利用大内存页面来改善 DTLB 性能的技巧。
• 低效的计算也在实际应用程序的性能瓶颈中占据重要部分。现代编译器非常擅长通过执行许多不同的代码转换来消除不必要的计算开销。然而,我们有很大机会比编译器提供的优化效果更好。
• 在第8.2节中,我们展示了如何通过强制进行某些代码优化来搜索程序中的性能潜力。我们讨论了诸如函数内联、循环优化和向量化等常见的转换方法。
















 2601
2601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









