






在没有数据之前进行理论推测是一个严重的错误。不知不觉中,人们开始扭曲事实以适应理论,而不是调整理论以适应事实。
阿瑟·柯南·道尔爵士的《波西米亚丑闻》中的福尔摩斯警句
当面临性能下降和复杂的系统环境时,首要挑战是确定从哪里开始分析、收集哪些数据以及如何进行分析。正如我在第一章中所说,性能问题可能来自任何地方,包括软件、硬件和数据路径上的任何组件。方法论可以帮助性能分析人员处理复杂的系统,指导他们从何处开始,并采取哪些步骤来定位和分析性能问题。对于初学者,方法论指明了起点并提供了详细的步骤。对于普通用户或专家,它们可以作为检查清单,以确保不会错过细节。它们包括量化和确认发现的方法,识别最重要的性能问题。
本章分为三个部分:
- 背景介绍术语、基本模型、关键性能概念和观点。
- 方法论讨论性能分析方法论,包括观察和实验方法;建模;以及容量规划。
- 指标介绍性能统计、监控和可视化。
这里介绍的许多方法论在后面的章节中会进行更详细的探讨,包括第5到第10章的方法论部分。
2.1 Terminology
以下是系统性能的关键术语。后面的章节提供了更多的术语,并在不同的上下文中对其中一些进行了描述。
- IOPS:每秒输入/输出操作是数据传输操作的速率衡量单位。对于磁盘I/O,IOPS指的是每秒的读取和写入次数。
- 吞吐量:工作执行的速率。特别是在通信中,该术语用于表示数据速率(每秒字节数或每秒比特数)。在某些情况下(例如数据库),吞吐量可以指操作速率(每秒操作次数或每秒事务数)。
- 响应时间:操作完成所需的时间。这包括等待时间和服务时间(服务时间包括传输结果的时间)。
- 延迟:延迟是指一个操作等待服务的时间。在某些情况下,它可以指整个操作所花费的时间,相当于响应时间。有关示例,请参见第2.3节中的概念部分。
- 利用率:对于为请求提供服务的资源,利用率是基于在给定时间间隔内资源处于主动执行工作状态的时间的度量。对于提供存储的资源,利用率可能指已使用的容量(例如内存利用率)。
- 饱和度:资源无法处理的排队工作的程度。
- 瓶颈:在系统性能中,瓶颈是限制系统性能的资源。识别和消除系统性瓶颈是系统性能的关键活动。
- 工作负载:输入到系统或施加的负载即为工作负载。对于数据库而言,工作负载由客户端发送的数据库查询和命令组成。
- 缓存:快速存储区域,可以复制或缓冲有限量的数据,以避免直接与较慢的存储层通信,从而提高性能。出于经济原因,缓存的大小小于较慢的存储层。
需要时,附录中包含了基本术语以供参考。
2.2 Models
以下简单模型说明了系统性能的一些基本原理。
2.2.1 System under Test
系统测试下的性能展示如图2.1所示。
//Perturbations:干扰
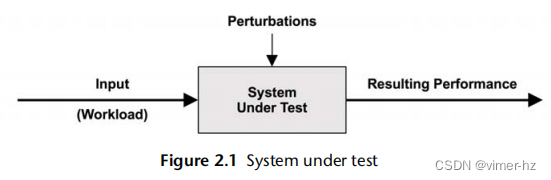
需要意识到,干扰(干涉)可能会影响结果,其中包括由系统定期活动、系统其他用户以及其他工作负载引起的干扰。这些干扰的来源可能不太清晰,可能需要仔细研究系统性能来确定。在一些云环境中,这可能特别困难,因为在客户SUT内部无法观察到物理主机系统上其他租户的活动(由客户租户进行的其他活动)。现代环境的另一个困难在于,它们可能由几个网络化组件组成,用于处理输入工作负载,包括负载均衡器、Web 服务器、数据库服务器、应用服务器和存储系统。仅是对环境进行映射可能有助于揭示先前被忽视的干扰源。该环境也可以被建模为队列系统的网络,进行分析性研究。
2.2.2 Queueing System
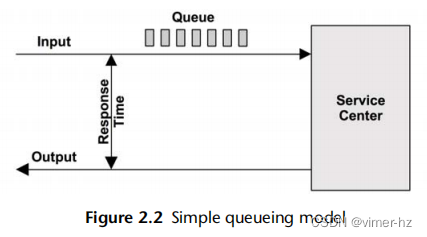
一些组件和资源可以被建模为队列系统。图2.2展示了一个简单的队列系统。
队列论是在第2.6节“建模”中介绍的,它研究队列系统和队列系统网络。
2.3 Concepts
以下是系统性能的重要概念,假设读者在本章和本书的其余部分已经具备相关知识。这些主题以一种通用的方式进行描述,然后在后面章节的架构和分析部分引入具体的实现细节。
2.3.1 Latency
对于某些环境而言,延迟是性能的唯一关注点。对于其他环境,延迟是分析的首要或前两个关键领域之一,与吞吐量一起。
以延迟为例,图2.3展示了一个网络传输的示例,比如一个HTTP GET请求,将时间分为延迟和数据传输组成部分。

延迟是指在执行操作之前花费的等待时间。在这个例子中,该操作是一个网络服务请求,用于传输数据。在进行这个操作之前,系统必须等待建立网络连接,这就是该操作的延迟。响应时间跨越了这个延迟和操作时间。
由于延迟可以从不同的位置进行测量,因此通常会与测量的目标一起表示。例如,网站的加载时间可能由从不同位置测得的三个不同的时间组成:DNS延迟、TCP连接延迟,以及TCP数据传输时间。DNS延迟涉及整个DNS操作。TCP连接延迟仅涉及初始化(TCP握手)。
在更高的层次上,所有这些,包括TCP数据传输时间,都可以被视为其他某种东西的延迟。例如,从用户点击网站链接到结果页面完全加载完成的时间可以称为延迟,其中包括浏览器渲染网页所需的时间。
由于延迟是一种基于时间的度量,可以进行各种计算。通过使用延迟来量化性能问题,然后对其进行排序,因为它们使用相同的单位(时间)进行表示。也可以通过考虑何时可以减少或消除延迟来计算预测的加速比。例如,使用IOPS指标无法准确执行这两种计算。
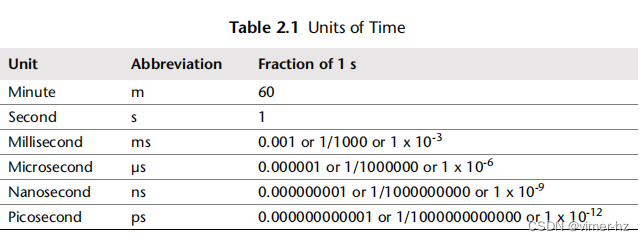
供参考,时间量级及其缩写列在表2.1中。
在可能的情况下,可以将其他类型的指标转换为延迟或时间,以便进行比较。如果你必须在100个网络I/O和50个磁盘I/O之间进行选择,你如何知道哪一个性能更好?这将是一个复杂的选择,涉及许多因素:网络跳数、网络丢包和重新传输的速率、I/O大小、随机或顺序I/O、磁盘类型等等。但是,如果你比较总共100毫秒的网络I/O和总共50毫秒的磁盘I/O,差异是明显的。
2.3.2 Time Scales
虽然时间可以通过数字进行比较,但对时间有一种本能感觉,并且对来自不同来源的延迟有期望也很有帮助。系统组件在时间尺度上(数量级)的操作差异巨大,以至于很难理解这些差异有多大。在表2.2中,提供了示例延迟,从3.3 GHz处理器的CPU寄存器访问开始。为了展示我们正在使用的时间尺度之间的差异,该表显示了每个操作可能需要的平均时间,按比例缩放到一个想象中的系统中,在该系统中,寄存器访问(在现实生活中为0.3纳秒,约为十亿分之一秒)需要一秒钟的时间。

正如你所看到的,CPU周期的时间尺度非常小。光线传播0.5米的时间,也许就是从你的眼睛到这个页面的距离,大约是1.7纳秒。在同样的时间内,一颗现代CPU可能已经执行了五个CPU周期并处理了几条指令。
关于CPU周期和延迟的更多信息,请参阅第6章《CPU》,有关磁盘I/O延迟,请参阅第9章《磁盘》。包含的互联网延迟来自第10章《网络》,其中还有更多例子。
2.3.3 Trade-offs
你应该意识到一些常见的性能权衡。好/快/便宜的“选择两个”权衡如图2.4所示,同时还有为IT项目调整过的术语。
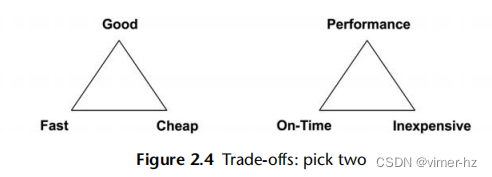
许多IT项目在时间和成本上都把控得很好,但却将性能修复留到后期。当早期的决策阻碍了提高性能时,这个选择可能会变得有问题,比如选择和填充次优的存储架构,或者使用缺乏全面性能分析工具的编程语言或操作系统。
性能调整中常见的权衡是CPU和内存之间的权衡,因为内存可以用于缓存结果,减少CPU使用量。在现代系统中,由于CPU充足,这种权衡可能会反过来:CPU可以用来压缩数据以减少内存使用量。
可调参数通常伴随着权衡。以下是一些例子:
文件系统记录大小(或块大小):接近应用程序I/O大小的小记录大小对于随机I/O工作负载表现更好,并且在应用程序运行时更有效地利用文件系统缓存。大记录大小将改善流式工作负载,包括文件系统备份。
网络缓冲区大小:小缓冲区大小将减少每个连接的内存开销,帮助系统扩展。大尺寸将提高网络吞吐量。
在对系统进行更改时,请寻找这样的权衡。
2.3.4 Tuning Efforts
//调优工作
性能调优最有效的时候是在工作执行的最近位置进行。对于由应用程序驱动的工作负载,这意味着在应用程序本身内部进行调优。表2.3展示了一个软件栈的示例,其中包含了调优的可能性。

通过在应用程序级别进行调优,可能可以消除或减少数据库查询,并将性能大幅提高(例如,20倍)。将调优降至存储设备级别可能会消除或改善存储I/O,但已经执行了较高级别的操作系统堆栈代码,因此这可能仅会将结果应用程序的性能提高百分之几(例如,20%)。
在应用程序级别找到大幅度的性能提升还有另一个原因。如今,许多环境都以快速部署功能和功能为目标。因此,在生产部署之前,应用程序的开发和测试往往集中在正确性上,几乎没有时间进行性能测量或优化。这些活动通常在性能成为问题时才进行。
虽然应用程序可能是最有效的调优级别,但不一定是最有效的观察级别。慢查询可能最好通过它们在 CPU 上花费的时间或它们执行的文件系统和磁盘 I/O 来理解。这些可以通过操作系统工具进行观察。
在许多环境中(尤其是云计算环境),应用程序级别处于不断开发的状态,每周甚至每天都会推送软件更改到生产环境。在应用程序代码发生变化时,通常会找到大的性能优化,包括修复回归问题。在这些环境中,很容易忽视针对操作系统的调优和从操作系统进行观测。
请记住,操作系统性能分析也可以识别应用程序级别的问题,而不仅仅是操作系统级别的问题,在某些情况下比仅从应用程序中更容易识别。
2.3.5 Level of Appropriateness
不同的组织和环境对性能有不同的要求。你可能加入了一个组织,在这个组织中,深度分析的程度超出了你以前见过的范围,甚至是你所知道的可能范围。或者你可能会发现,你认为基本的分析被视为高级分析,并且以前从未执行过(好消息是:很容易获得成果!)。
这并不意味着某些组织做得对,而某些组织做得错。这取决于性能专业知识的投资回报率(ROI)。拥有大型数据中心或云环境的组织可能需要一个性能工程师团队,他们分析一切,包括内核内部和CPU性能计数器,并经常使用动态跟踪。他们还可能正式建模性能,并为未来的增长制定准确的预测。小型初创公司可能只有时间进行表面检查,信任第三方监控解决方案来检查他们的性能并提供警报。
最极端的环境包括股票交易所和高频交易者,性能和延迟至关重要,并且可以证明需要投入巨大的努力和费用。作为一个例子,目前计划在纽约和伦敦交易所之间建立一条新的跨大西洋电缆,耗资3亿美元,以减少传输延迟6毫秒[1]。
2.3.6 Point-in-Time Recommendations
环境的性能特性随着时间的推移而变化,这是由于增加了更多的用户、更新的硬件和软件或固件所导致的。一个目前受限于1 Gbit / s网络基础设施的环境,在升级到10 Gbit / s后可能会开始感到磁盘或CPU性能不足。
性能建议,特别是可调参数的值,仅在特定时间点有效。一个星期内的性能专家给出的最佳建议,一个星期后可能因软件或硬件升级或添加更多用户而失效。
在互联网上搜索到的可调参数值可以在某些情况下提供快速解决方案。但是,如果它们对于您的系统或工作负载不合适,曾经适用但现在不适用,或者只适用于软件漏洞的临时解决方法,这些参数值也可能会损害性能。这就像搜刮别人的药柜并服用可能不适合您的药物,或者已经过期,或者只应该短期服用一样。
浏览此类建议可以很有用,只是为了了解哪些可调参数存在并且过去需要更改。然后的任务就是看看这些参数是否适合您的系统和工作负载,以及如何调整它们。但是,如果其他人以前没有需要调整该参数,或者已经调整了该参数但没有在任何地方分享他们的经验,您仍然可能会忽略一个重要的参数。
2.3.7 Load versus Architecture
应用程序的性能不佳可能是由于软件配置和运行的硬件(即其架构)存在问题。然而,应用程序也可能由于负载过大而导致排队和延迟过长而表现不佳。负载和架构如图2.5所示。
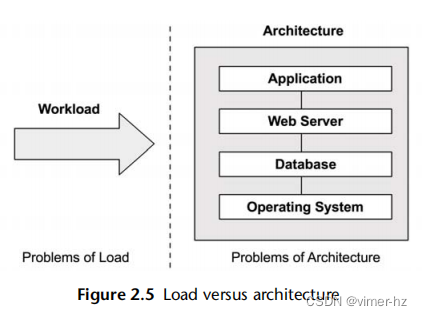
如果架构分析显示工作正在排队,但没有关于工作执行方式的问题,那么问题可能是负载过多。在云计算环境中,这时可以引入更多节点来处理工作。
例如,架构问题可能是一个繁忙的单线程应用程序,请求在排队,而其他CPU可用且空闲。在这种情况下,性能受限于应用程序的单线程架构。
负载问题可能是一个多线程应用程序,它在所有可用的CPU上都很繁忙,但请求仍在排队。在这种情况下,性能受限于可用的CPU容量,或者换句话说,是负载超过了CPU可以处理的负荷。
2.3.8 Scalability
在负载增加的情况下,系统的性能表现为可扩展性。图2.6展示了系统负载增加时的典型吞吐量曲线。
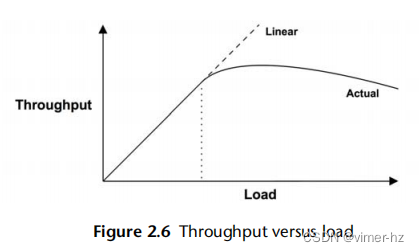
在某个阶段,观察到线性可扩展性。然后达到一个点,用虚线标记,资源争用开始影响性能。这一点可以被描述为拐点,因为它是两个曲线之间的边界。超过这一点,随着资源争用的增加,吞吐量曲线偏离线性可扩展性。最终,由于更多资源争用和一致性导致完成的工作减少,吞吐量减少。
当一个组件达到100%利用率时,即饱和点时,这一点可能会出现。它也可能在一个组件接近100%利用率时发生,排队开始变得频繁和显著。
一个可能表现出这种曲线的系统是一个执行重计算的应用程序,随着线程的增加,负载越来越大。当CPU接近100%利用率时,性能开始下降,因为CPU调度器延迟增加。在达到最高性能后,即100%利用率时,随着添加更多线程,吞吐量开始降低,导致更多的上下文切换,消耗CPU资源并导致完成的实际工作减少。
如果将x轴上的“负载”替换为CPU核心等资源,则可以看到相同的曲线。有关此主题的更多信息,请参见第2.6节,“建模”。
非线性可扩展性的性能退化,以平均响应时间或延迟为基础,可以在图2.7 [Cockcroft 95]中绘制出来。
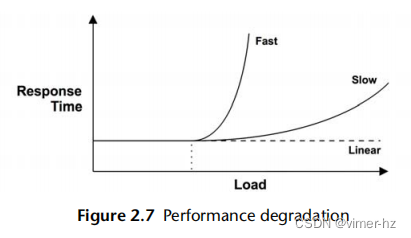
较高的响应时间当然是不好的。当系统开始进行分页(或交换)以补充主内存时,可能会出现"快速"退化的内存负载情况。而对于CPU负载,则可能会出现"缓慢"退化的情况。
另一个"快速"退化的示例是磁盘I/O。随着负载(及其导致的磁盘利用率)的增加,I/O更有可能排队等待其他I/O完成。一个空闲的旋转磁盘可能在大约1毫秒的响应时间内提供I/O服务,但当负载增加时,这个时间可能接近10毫秒。这在第2.6.5节的M/D/1和60%利用率中有所建模。
如果应用程序在资源不可用时开始返回错误而不是将工作排队,那么响应时间的线性可扩展性可能会发生。例如,Web服务器可能会返回503“服务不可用”而不是将请求添加到队列中,以便那些已经得到服务的请求可以以一致的响应时间执行。
2.3.9 Known-Unknowns
在前言中介绍的已知已知、已知未知和未知未知的概念对于性能领域非常重要。以下是分类说明,以系统性能分析为例:
已知已知:这些是你已经知道的事情。你知道你应该检查性能指标,也知道它的当前值。例如,你知道应该检查CPU利用率,并且知道平均值为10%。
已知未知:这些是你知道自己不知道的事情。你知道可以检查指标或子系统的存在,但尚未观察到。例如,你知道可以通过使用剖面来检查使CPU繁忙的原因,但尚未这样做。
未知未知:这些是你不知道自己不知道的事情。例如,你可能不知道设备中断会成为严重的CPU消耗者,因此没有对其进行检查。
性能是一个“你知道得越多,你不知道得就越多”的领域。这是相同的原则:你学到的关于系统的越多,你就会意识到更多的未知未知,然后可以将其作为已知未知进行检查。
2.3.10 Metrics
性能指标是由系统、应用程序或附加工具生成的统计数据,用于测量感兴趣的活动。它们被用于性能分析和监控,可以通过命令行数字或使用可视化图形进行研究。
常见的系统性能指标类型包括:
IOPS:每秒I/O操作次数
吞吐量:每秒操作或每秒传输的容量
利用率
延迟
吞吐量的使用取决于其上下文。数据库吞吐量通常是每秒查询或请求(操作)的衡量标准。网络吞吐量是每秒比特或字节(容量)的衡量标准。
IOPS是一种吞吐量测量,但仅适用于I/O操作(读取和写入)。同样,上下文很重要,定义可能因情况而异。
Overhead
//开销
性能指标并非免费;在某些时候,必须花费CPU周期来收集和存储它们。这会导致开销,可能会对测量目标的性能产生负面影响。这被称为观察效应。(它经常与海森堡的不确定性原理混淆,后者描述了物理属性对,如位置和动量,可以被知道的精度限制。)
Issues
//问题
人们往往会认为软件供应商提供的指标选择得当、没有错误,并提供完整的可见性。实际上,指标可能令人困惑、复杂、不可靠、不准确,甚至完全错误(由于错误)。有时,某个指标在一个软件版本上是正确的,但没有更新以反映新代码和代码路径的添加。
有关指标问题的更多信息,请参见第4章Observability Tools的第4.6节“观察可观性”。
2.3.11 Utilization
术语“利用率”通常用于操作系统中描述设备的使用情况,比如CPU和磁盘设备。利用率可以基于时间或容量来衡量。
Time-Based
基于时间的利用率在排队论中有正式定义。例如 [Gunther 97]:
服务器或资源繁忙的平均时间量
以及比率
U = B/T
其中,U表示利用率,B表示系统在观察期间T内繁忙的总时间。
这也是操作系统性能工具中最常见的“利用率”。磁盘监控工具iostat(1)将此指标称为“%b”,表示百分比繁忙,这个术语更能传达出底层的指标:B/T。
该利用率指标告诉我们组件有多忙:当组件接近100%利用率时,资源争用时性能可能严重下降。可以检查其他指标来确认并查看该组件是否成为系统瓶颈。
某些组件可以并行地处理多个操作。对于它们来说,在100%利用率时性能可能不会严重下降,因为它们可以接受更多的工作负载。
为了理解这一点,考虑一个大楼的电梯。当电梯在楼层之间移动时,它被认为是被利用的;当它处于空闲等待状态时,它被认为是未被利用的。然而,即使电梯在100%的时间里都在忙碌地响应呼叫,它可能仍然能够接受更多的乘客,也就是说,它处于100%的利用率。
一个100%繁忙的磁盘也可能能够接受和处理更多的工作负载,例如通过将写操作缓冲到磁盘缓存中以便稍后完成。存储阵列通常以100%的利用率运行,因为某些磁盘在100%的时间内都很忙,但阵列中有很多空闲磁盘,可以接受更多的工作负载。
Capacity-Based
另一个关于利用率的定义是由 IT 专业人员在容量规划的背景下使用的 [Wong 97]:
一个系统或组件(例如磁盘驱动器)能够提供一定数量的吞吐量。在任何性能水平下,系统或组件都在其容量的某个比例上工作。这个比例被称为利用率。
这种定义是基于容量而不是时间来定义利用率。它意味着100%利用率的磁盘无法接受更多的工作负载。根据基于时间的定义,100%利用率仅表示它在100%的时间内处于繁忙状态。
100%繁忙并不意味着100%容量。
以电梯为例,100%容量可能意味着电梯已达到最大载重量,无法接受更多乘客。
在理想的情况下,我们能够同时测量设备的这两种利用率。例如,你可以知道磁盘是否100%繁忙并且由于争用而性能开始下降,以及它是否已达到100%容量无法接受更多工作。然而,很遗憾,通常情况下这是不可能的。对于磁盘来说,需要了解磁盘上的控制器正在做什么,并对容量进行预测。目前,磁盘并不提供这些信息。
在本书中,利用率通常指的是基于时间的版本。容量版本用于一些基于容量的指标,例如内存使用情况。
Non-Idle Time
在我们公司开发云监控项目期间,定义利用率的问题浮现出来。首席工程师 Dave Pacheco 叫我定义利用率。我照上面的定义给了他。然而,他对可能引起混淆的可能性不满意,因此提出了一个不同的术语,以使其不言自明:非空闲时间。
虽然这更准确,但它目前还没有广泛使用(通常将此指标称为百分比繁忙,就像之前所描述的)。
2.3.12 Saturation
当对资源请求的工作量超过其处理能力时,饱和度就会发生。在100%利用率(基于容量)时开始出现饱和,因为无法处理额外的工作负载并且开始排队。这在图2.8中有所描述。
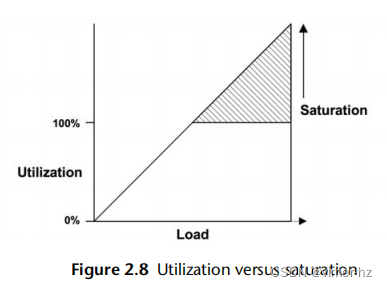
该图显示了饱和度随着负载的增加而线性增加,超过了基于100%容量的利用率标记。任何程度的饱和度都是一个性能问题,因为时间被浪费在等待上(延迟)。对于基于时间的利用率(百分比繁忙),排队和因此饱和可能不会在100%利用率标记处开始,这取决于资源可以并行处理工作的程度。
2.3.13 Profiling
性能剖析构建了一个可以被研究和理解的目标的画像。在计算机性能领域,性能剖析通常通过定时采样系统状态,然后研究采样集来完成。与之前涉及的指标(包括IOPS和吞吐量)不同,采样提供了目标活动的粗略视图,具体取决于采样频率。
例如,通过在频繁间隔采样CPU程序计数器或堆栈回溯,收集消耗CPU资源的代码路径的统计信息,可以相对详细地了解CPU使用情况。这个话题在第6章“CPU”中有所涉及。
2.3.14 Caching
缓存经常被用来提高性能。缓存将较慢存储层的结果存储在更快的存储层中以供参考。一个例子是将磁盘块缓存到主内存(RAM)中。
可以使用多个级别的缓存。CPU通常使用多个硬件缓存来处理主内存(第1、2和3级),从一个非常快速但较小的缓存(第1级)开始,随着存储容量和访问延迟的增加而增加。这是密度和延迟之间的经济权衡;级别和大小是为可用芯片空间的最佳性能而选择的。
系统中还有许多其他缓存,其中许多是使用主内存作为存储器实现的。请参见第3章“操作系统”的3.2.11节“缓存”中的缓存层列表。
了解缓存性能的一种指标是每个缓存的命中率-所需数据在缓存中被找到的次数(命中)与未找到的次数(未命中)之比:
命中率= 命中次数/总访问次数(命中次数+未命中次数)
命中率越高越好,因为更高的比率反映了从更快的媒体中成功访问的数据更多。图2.9显示了随着缓存命中率的增加,性能改善的预期情况。
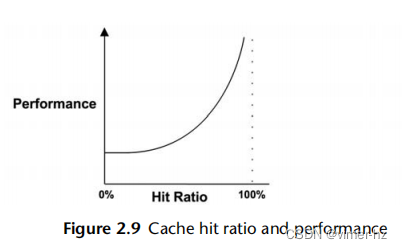
98%和99%之间的性能差异要大于10%和11%之间的差异。这是一个非线性的情况,因为缓存命中和未命中之间的速度差异-两个不同的存储层。差异越大,斜率就越陡。
另一个了解缓存性能的指标是每秒的缓存未命中率。这与每个未命中的性能惩罚成正比(线性关系),并且更容易解释。
例如,工作负载A和B使用不同的算法执行相同的任务,并使用主内存缓存来避免从磁盘读取。工作负载A的缓存命中率为90%,工作负载B的缓存命中率为80%。仅凭这些信息,可以推断工作负载A的性能更好。如果工作负载A的未命中率为200/s,而工作负载B为20/s呢?以这种方式计算,工作负载B的磁盘读取次数要比A少10倍,这可能比A更早完成任务。为确保准确,可以计算每个工作负载的总运行时间:
运行时间=(命中率×命中延迟)+(未命中率×未命中延迟)
该计算使用了平均命中延迟和未命中延迟,并假设工作负载是串行执行的。
Algorithms
缓存管理算法和策略决定了在有限的缓存空间中存储什么内容。
最近最常使用(MRU)是指缓存保留策略,它决定在缓存中保留哪些对象:最近被使用的对象。最不常使用(LRU)可以指等效的缓存驱逐策略,决定在需要更多空间时从缓存中删除哪些对象。还有最常使用(MFU)和最不常使用(LFU)的策略。
您可能会遇到不经常使用(NFU),它可能是LRU的一种廉价但不太彻底的版本。
Hot, Cold, and Warm Caches
以下是描述缓存状态常用的词汇:
冷缓存:一个冷缓存是空的,或者被不需要的数据占据。对于一个冷缓存来说,命中率为零(或者在开始变暖时接近零)。
热缓存:一个热缓存被常请求的数据所占据,并且有很高的命中率,例如超过99%。
温缓存:一个温缓存被有用的数据所占据,但它的命中率不够高以被认为是热缓存。
温度:缓存温度描述了一个缓存是热还是冷的程度。提高缓存命中率的活动被称为提高缓存温度的活动。当缓存首次被初始化时,它们开始冷,然后随着时间的推移变暖。
当缓存很大或下一级存储速度很慢(或两者都是),缓存可能需要很长时间才能被填充和变暖。
例如,我曾经在一个存储设备上工作,该设备有128 G字节的DRAM作为文件系统缓存,600 G字节的闪存作为二级缓存,并使用旋转磁盘进行存储。在随机读取的工作负载下,磁盘的读取速度大约为每秒2,000个。以8 K字节的IO大小计算,这意味着缓存只能以16 M字节/秒(2,000 x 8 K字节)的速度变暖。当两个缓存都开始变冷时,DRAM缓存需要超过2小时才能变暖,闪存缓存需要超过10小时。
2.4 Perspectives
性能分析有两种常见的视角,每种视角都有不同的受众、指标和方法。它们分别是工作负载分析和资源分析。可以将它们看作对操作系统软件栈进行自上而下或自下而上的分析,如图2.10所示。
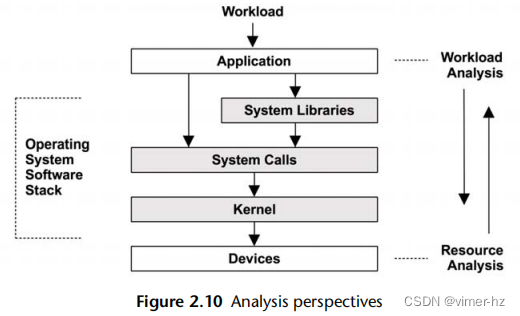
第2.5节"方法论"提供了针对每种视角应用的具体策略。这里更详细地介绍了这些视角。
2.4.1 Resource Analysis
资源分析始于对系统资源的分析:包括CPU、内存、磁盘、网络接口、总线和互连。这通常由系统管理员执行,他们负责物理环境资源。活动包括:
1. 性能问题调查:查看特定类型的资源是否负责性能问题。
2. 容量规划:用于确定新系统的大小,并查看现有系统资源何时可能耗尽。
这个视角侧重于利用率,以确定资源是否达到或接近其限制。某些资源类型,如CPU,具有易于获取的利用率指标。其他资源的利用率可以根据可用指标进行估算,例如,通过比较发送和接收的兆位每秒(吞吐量)与已知的最大带宽来估算网络接口的利用率。
最适合资源分析的指标包括:
1. IOPS(每秒输入输出操作数)
2. 吞吐量
3. 利用率
4. 饱和度
这些指标衡量了资源被要求执行的任务,以及在给定负载下它的利用率或饱和度。其他类型的指标,包括延迟,也可以用于查看资源在给定工作负载下的响应情况。
资源分析是性能分析的常见方法,部分原因是因为该主题有广泛可用的文档。这样的文档集中在操作系统的“stat”工具上:vmstat(1)、iostat(1)、mpstat(1)。阅读这样的文档时,重要的是要理解这只是一种视角,而不是唯一的视角。
2.4.2 Workload Analysis
工作负载分析(见图2.11)研究应用程序的性能:应用的工作负载以及应用程序的响应情况。它最常由应用程序开发人员和支持人员使用,他们负责应用程序软件和配置。
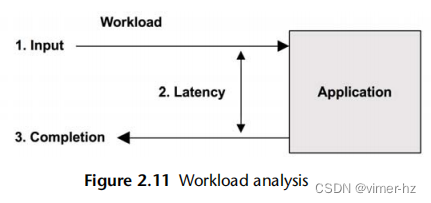
工作负载分析的目标包括:
请求:所应用的工作负载
延迟:应用程序的响应时间
完成:查找错误
研究工作负载请求通常涉及检查和总结其属性,即工作负载表征的过程(在第2.5节的方法论中更详细地描述)。对于数据库而言,这些属性可能包括客户端主机、数据库名称、表格和查询字符串。这些数据可以帮助识别不必要的工作或工作不平衡的情况。虽然工作可能表现良好(延迟低),但通过检查这些属性可能会找到减少或消除所应用工作的方法。(最快的查询是根本不进行查询。)
延迟(响应时间)是表达应用程序性能最重要的指标。对于MySQL数据库来说,它是查询延迟;对于Apache来说,它是HTTP请求延迟;等等。在这些情境中,延迟一词被用来表示与响应时间相同的含义(有关上下文的更多信息,请参阅第2.3.1节“延迟”)。工作负载分析的任务包括识别和确认问题,例如通过查找超出可接受阈值的延迟,然后找到延迟的来源(深入分析),并确认在应用修复后延迟是否得到改善。请注意,起点是应用程序。调查延迟通常涉及更深入地分析应用程序、库和操作系统(内核)。
通过研究与事件完成相关的特征,包括其错误状态,可以确定系统问题。虽然一个请求可能很快完成,但如果以错误状态完成,会导致请求被重试,从而累积延迟。
最适合工作负载分析的指标包括:
吞吐量(每秒事务数)
延迟
这些指标衡量请求的速率和结果性能。
2.5 Methodology
本节介绍了系统性能分析和调优的许多方法论和程序,并引入了一些新的方法,特别是USE方法。还包括了一些反方法论。
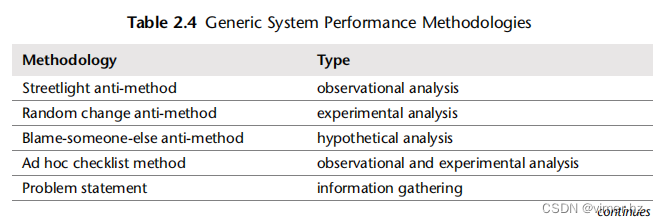
为了帮助总结它们的作用,这些方法论被归类为不同类型,例如观察分析和实验分析,如表2.4所示。
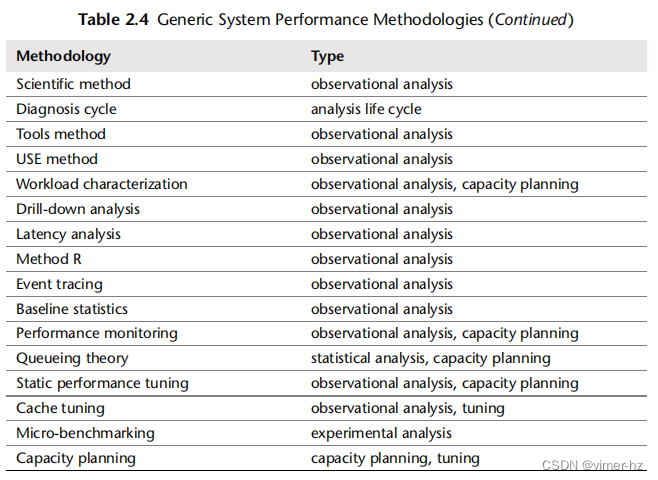
性能监控、排队理论和容量规划将在本章后面进行介绍。后面的章节还将在不同的上下文中重新解释其中一些方法,并提供一些特定于性能分析领域的附加方法。
下面的几节以常用但较弱的方法作为比较的起点,包括反方法论。在进行性能问题分析时,你应该首先尝试使用问题陈述方法,然后再尝试其他方法。
2.5.1 Streetlight Anti-Method
这种方法实际上是缺乏明确方法论的一种做法。用户通过选择熟悉的、在互联网上找到的或随意选择的可观测工具来分析性能,以查看是否有明显的问题。这种方法是凭运气的,可能会忽视许多类型的问题。
类似地,调优性能也可以尝试使用试错的方式,将已知和熟悉的可调参数设置为不同的值,以查看是否有所帮助。
即使这种方法揭示了一个问题,由于工具或调整与问题无关,因为它们是熟悉的,所以可能会很慢。因此,这种方法学被命名为街灯效应,它是以一个寓言来说明的:
一天晚上,一名警察看到一个醉汉在路灯下搜索地面,他问他在找什么。醉汉说他丢了钥匙。警察也找不到,问道:“你确定是在这儿丢的,就在路灯下?”醉汉回答:“不,但这里的光最亮。”
在性能方面,这相当于查看top(1),不是因为它有道理,而是因为用户不知道如何阅读其他工具。
这种方法找到的问题可能是一个问题,但不是真正的问题。其他方法可以对发现进行量化,以便更快地排除错误的结果。
2.5.2 Random Change Anti-Method
这是一种实验性的反方法论。用户随机猜测问题可能出在哪里,然后不断更改事物直到问题消失。为了确定每次更改是否改善了性能,会研究一项指标,例如应用程序运行时间、操作时间、延迟、操作速率(每秒操作数)或吞吐量(每秒字节数)。具体步骤如下:
1. 随机选择一个要更改的项目(例如一个可调参数)。
2. 在一个方向上进行更改。
3. 测量性能。
4. 在另一个方向上进行更改。
5. 测量性能。
6. 步骤3或步骤5的结果是否比基准线好?如果是,保留该更改并返回到步骤1。
尽管这个过程最终可能会发现适用于经过测试工作负载的调整方法,但它非常耗时,而且长期来看可能会留下没有意义的调整。例如,一个应用程序的更改可能会改善性能,因为它规避了数据库或操作系统的错误,而这个错误之后会被修复。但是应用程序仍将保留那个不再有意义的调整,而且一开始没有人正确理解。
另一个风险是,一个没有被正确理解的更改在生产高峰负载期间导致更严重的问题,并在此期间需要撤销该更改。
//即还是要理解业务之前的写法原理
2.5.3 Blame-Someone-Else Anti-Method
这种反方法论按照以下步骤进行:
1. 找到一个你不负责的系统或环境组件。
2. 假设问题出在那个组件上。
3. 将问题转给负责那个组件的团队。
4. 当证明错误时,返回到步骤1。
也许问题出在网络上。你能否向网络团队确认是否有丢包或其他问题?
使用这种方法论时,用户并不会调查性能问题,而是将问题推给其他人,当问题最终证明并非他们的问题时,可能会浪费其他团队的资源。这种反方法论的特征是缺乏数据支持的假设。
为了避免成为责怪他人的受害者,可以要求控告者提供截图,显示运行了哪些工具以及如何解释输出。你可以将这些截图和解释带给其他人进行第二意见。
//在阅读这些方法论时感觉像是自己的职业经历...
2.5.4 Ad Hoc Checklist Method
当被要求检查和调优系统时,通过按照一个预设的检查清单逐步进行是支持专业人员常用的方法论,通常在较短的时间内完成。一个典型的场景涉及将新的服务器或应用程序部署到生产环境中,支持专业人员花费半天时间检查系统在真实负载下的常见问题。这些检查清单是临时性的,根据最近的经验和该类型系统的问题建立起来。
以下是一个检查清单条目的示例:
运行iostat -x 1,并检查等待时间(await)列。如果负载期间该值持续超过10毫秒,则表示磁盘要么速度慢,要么超负荷。
一个检查清单可能包含十几个这样的检查。
尽管这些检查清单可以在最短时间内提供最大价值,但它们只是针对特定时刻的建议(参见第2.3节,概念),需要经常更新以保持最新。它们也倾向于关注已知可以轻松记录的问题的解决方法,如可调参数的设置,而不是源代码或环境的定制修复方法。
如果你管理一个支持专业人员团队,一个临时性的检查清单可以是确保每个人都知道如何检查最严重问题的有效方式,并且已经检查了所有明显的问题。检查清单可以编写得清晰明确,展示如何识别每个问题以及解决方法是什么。但当然,这个清单必须不断更新。
2.5.5 Problem Statement
当支持人员首次响应问题时,定义问题陈述是一项例行任务。这是通过问客户以下问题来完成的:
1. 什么让你觉得有性能问题?
2. 这个系统以前表现良好吗?
3. 最近有什么变化?软件?硬件?负载?
4. 问题可以用延迟或运行时间来表达吗?
5. 问题是否影响其他人或应用程序(还是只有你)?
6. 环境如何?使用了哪些软件和硬件?版本?配置?
只需问这些问题并回答它们通常就能指向一个即时的原因和解决方案。因此,问题陈述被包含在这里作为自己的方法论,并且应该是你解决新问题时使用的第一种方法。
2.5.6 Scientific Method
科学方法通过提出假设并进行测试来研究未知领域。它可以总结为以下步骤:
1. 问题
2. 假设
3. 预测
4. 测试
5. 分析
问题是性能问题陈述。基于这个问题陈述,你可以假设导致性能不佳的原因是什么。然后,你构建一个测试,这个测试可以是观察性的或实验性的,它测试了基于假设的预测。最后,对收集到的测试数据进行分析。
例如,你可能会发现在迁移到内存较少的系统后,应用程序性能下降了,并且你假设性能不佳的原因是较小的文件系统缓存。你可以使用观察性测试来测量两个系统上的缓存未命中率,预测较小系统上的缓存未命中率会更高。实验性测试可以是增加缓存大小(添加RAM),预测性能会提升。另一个可能更简单的实验性测试是人为减少缓存大小(使用可调参数),预测性能会变差。
/*有什么指标可以查看系统的内存命中率?
1. 缺页率(Page Fault Rate):缺页率是指在内存中无法找到所需数据或指令,需要从磁盘中加载的比例。较高的缺页率表示内存命中率较低。
2. 页面命中率(Page Hit Rate):页面命中率是指在虚拟内存系统中,将页面从磁盘加载到内存中时成功找到并加载到内存的页面的比例。较高的页面命中率表示内存命中率较高。
*/
/*
Minor Page Fault和Major Page Fault的区别:
Minor Page Fault和Major Page Fault是两种不同类型的页面错误(Page Fault),它们在内存管理中具有不同的含义和影响。
1. Minor Page Fault(次要页面错误):
- 当进程访问的页面在物理内存中存在,但没有映射到进程的虚拟地址空间时,会发生次要页面错误。
//进程的虚拟地址空间,不会映射所有的物理内存
- 次要页面错误通常是由分页机制中的页面置换策略引起的,用于将最近不活跃的页交换出去,以便为新的页腾出空间。
- 当发生次要页面错误时,操作系统只需更新页表,将正确的物理页面映射到进程的虚拟地址空间中,而无需从磁盘加载数据,因此通常速度较快。
2. Major Page Fault(主要页面错误):
- 主要页面错误通常是由于所需的页面不在物理内存中,需要从磁盘加载到内存中才能满足进程的访问需求。
- 当发生主要页面错误时,操作系统必须从磁盘读取相应的页面数据,然后更新页表,将该页面映射到进程的虚拟地址空间中。这个过程涉及磁盘访问,因此速度相对较慢。
*/
以下是一些更多的示例:
Example (Observational)
1. 问题:是什么导致数据库查询变慢?
2. 假设:嘈杂的邻居(其他云计算租户)正在执行磁盘I/O,与数据库的磁盘I/O竞争(通过文件系统)。
3. 预测:如果在查询期间测量文件系统的I/O延迟,将会发现文件系统是导致查询变慢的原因。
4. 测试:跟踪数据库文件系统延迟作为查询延迟的比例,显示只有不到5%的时间花在等待文件系统上。
5. 分析:文件系统和磁盘并不是导致查询变慢的原因。虽然问题仍未解决,但已经排除了一些重要的环境组件。进行此调查的人可以返回第2步,提出新的假设。
Example (Experimental)
1. 问题:为什么从主机A到主机C的HTTP请求比从主机B到主机C花费的时间更长?
2. 假设:主机A和主机B位于不同的数据中心。
3. 预测:将主机A移动到与主机B相同的数据中心将解决问题。
4. 测试:移动主机A并测量性能。
5. 分析:性能已经得到改善,与假设一致。如果问题没有得到解决,在开始新的假设之前,应撤销实验性的改变(在这种情况下将主机A移回原来的位置)。
Example (Experimental)
1. 问题:为什么随着文件系统缓存的增大,文件系统性能会下降?
2. 假设:较大的缓存存储更多的记录,相比较较小的缓存,管理较大的缓存需要更多的计算资源。
3. 预测:使记录大小逐渐变小,因此需要使用更多的记录来存储相同数量的数据,将导致性能逐渐变差。
4. 测试:使用逐渐减小的记录大小进行相同的工作负载测试。
5. 分析:结果被绘制成图表,并与预测一致。现在对缓存管理例程进行详细分析。
这是一个反向测试的示例——故意损害性能以了解目标系统更多信息的方法。
2.5.7 Diagnosis Cycle
类似于科学方法的是诊断循环:
假设 → 仪器检测 → 数据收集 → 假设
像科学方法一样,这种方法也通过收集数据有意地测试假设。该循环强调数据能够迅速引出新的假设,并对其进行测试和改进。这类似于医生通过一系列小型测试来诊断患者,并根据每个测试结果来完善假设。
这两种方法都在理论和数据之间取得了良好的平衡。试图快速从假设转向数据,以便能够及早识别并丢弃错误的理论,并发展出更好的理论。
2.5.8 Tools Method
一个以工具为导向的方法如下:
1. 列出可用的性能工具(可选择安装或购买更多)。
2. 对于每个工具,列出其提供的有用指标。
3. 对于每个指标,列出可能的解读规则。
这样得到的结果是一份规定性的清单,显示了应该运行哪个工具,阅读哪些指标以及如何解读它们。虽然这种方法可能相当有效,但它完全依赖于可用(或已知的)工具,这可能会提供对系统的不完整视图,类似于路灯反方法。更糟糕的是,用户并不知道自己的视图是不完整的,也可能一直不知道。需要自定义工具(例如动态追踪)解决的问题可能永远不会被识别和解决。
在实践中,工具方法确实可以识别出一些资源瓶颈、错误和其他类型的问题,尽管通常不够高效。
当有大量的工具和指标可用时,遍历它们可能需要很长时间。当多个工具具有相同功能时,情况会变得更糟,您需要额外的时间来了解每个工具的优缺点。在某些情况下,例如文件系统微基准测试工具,可能会有十多个可供选择的工具,而您可能只需要其中一个。
2.5.9 The USE Method
利用率、饱和度和错误(USE)方法应该在性能调查的早期使用,以识别系统瓶颈[Gregg 13]。它可以总结如下:
对于每个资源,检查其利用率、饱和度和错误。
这些术语的定义如下:
- 资源:所有物理服务器的功能组件(CPU、总线等)。一些软件资源也可以被检查,前提是指标具有意义。
- 利用率:在一个固定时间间隔内,资源忙于处理工作的时间百分比。在繁忙状态下,资源可能仍然能够接受更多的工作;不能接受更多工作的程度由饱和度确定。
- 饱和度:资源具有无法处理的额外工作量,通常在等待队列中等待。
- 错误:错误事件的数量。
对于一些资源类型,包括主存储器,利用率是已使用资源的容量。这与基于时间的定义不同,并且在第2.3.11节“利用率”中已经解释过。一旦一个容量资源达到100%的利用率,就无法接受更多的工作,资源要么排队等待工作(饱和),要么返回错误,这也是利用USE方法确定的。应该调查错误,因为它们可能会降低性能,并且在故障模式可恢复时可能不会立即被注意到。这包括操作失败并重试以及在冗余设备池中失败的设备。
与工具方法相比,USE方法涉及迭代系统资源而不是工具。这有助于您创建一个完整的问题清单,并且只有在这之后才去寻找工具来回答这些问题。即使找不到工具来回答问题,知道这些问题没有得到解答的信息对性能分析师来说也是非常有用的:现在它们成为了“已知的未知”。
USE方法还将分析引向少数关键指标,以便尽快检查所有系统资源。在此之后,如果没有发现问题,可以使用其他方法论。
Procedure
//流程
USE方法的流程图如图2.12所示。在检查利用率和饱和度之前,首先检查错误。错误通常很快且易于解释,在调查其他指标之前排除错误可能是节省时间的做法。
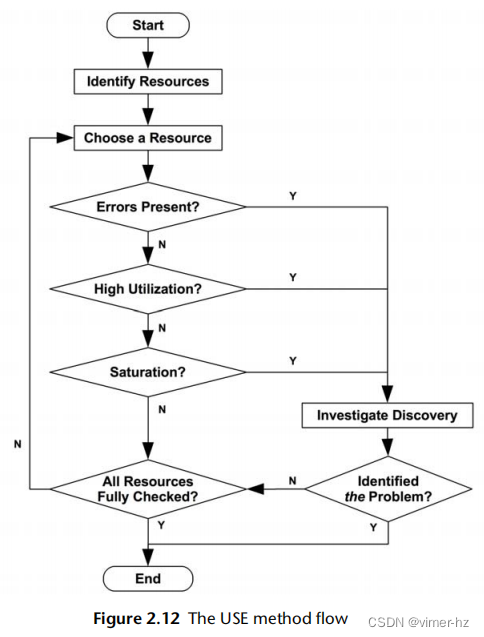
该方法识别出可能是系统瓶颈的问题。不幸的是,系统可能受到多个性能问题的困扰,因此你找到的第一个问题可能只是一个问题,而不是真正的问题。每个发现都可以使用进一步的方法进行调查,然后根据需要返回到USE方法以迭代更多资源。
Expressing Metrics
//指标表达
USE方法的指标通常表示如下:
- 利用率: 在时间间隔内的百分比(例如,“一个CPU运行在90%的利用率”)
- 饱和度: 作为等待队列长度(例如,“CPU平均运行队列长度为4”)
- 错误: 报告的错误数量(例如,“这个网络接口有50个迟到冲突”)
虽然这似乎不符合直觉,但短时间内的高利用率可能会导致饱和和性能问题,即使长时间内的总体利用率很低。一些监控工具报告5分钟平均值的利用率。例如,CPU利用率可能每秒钟变化很大,因此5分钟的平均值可能掩盖了短时间的100%利用率和饱和。
/*
CPU的饱和度详细解释下:
CPU的饱和度指的是CPU处理器的负载情况。当CPU的负载达到极限时,它就会变得饱和,无法再承载更多的工作负载。这通常会导致系统响应变慢甚至崩溃。
CPU饱和度可以通过检查等待队列的长度来确定。当CPU无法及时处理任务时,任务就会在等待队列中排队等待被处理,这就会导致等待队列的长度增加。长时间的高CPU饱和度可能会导致系统性能下降和延迟增加,因此需要进行监控和管理以确保系统正常运行。
"CPU饱和度可以通过检查等待队列的长度来确定"具体怎么做?
在Linux系统中,可以使用命令行工具top或htop来查看CPU的饱和度和等待队列的长度。
打开终端窗口,输入top或htop命令,按下回车键。这会显示一个实时监控系统的进程列表和性能指标。
在top或htop中,饱和度通常用si、so、%si、%so等指标表示。这些指标显示了内存交换的情况,如果这些值非常高,则表示CPU可能正在经历饱和状态。
等待队列的长度显示在进程列表中,它表示当前在CPU等待处理的进程数。在top或htop中,等待队列通常用D”(Interruptible sleep)状态来表示。如果大量的进程处于等待状态,则表明CPU正在经历饱和状态。
总之,在Linux系统中,可以通过top或htop等工具来检查CPU的饱和度和等待队列的长度,以及其他有关系统性能的指标,以便及时发现并解决问题。
“R”(Running)“表示进程处于运行状态。
*/
考虑高速公路上的一个收费站。利用率可以定义为有多少个收费亭正在为一辆车提供服务。100%的利用率意味着你找不到空的亭子,必须排队等候(饱和)。如果我告诉你,在整个一天中,收费亭的利用率为40%,你能告诉我在那一天的任何时间是否有任何车辆排队等候吗?在交通高峰期,利用率为100%,所以他们可能在那段时间内排队等候,但这在每日平均值中是看不出来的。
//这个举例很好
Resource List
USE方法的第一步是创建资源列表。尽量完整地列出所有资源。下面是一个通用的服务器硬件资源列表,以及具体的例子:
- CPUs(中央处理器):插槽(sockets)、内核(cores)、硬件线程(虚拟CPU)
- 主存储器:DRAM(动态随机存取存储器)
- 网络接口:以太网端口
- 存储设备:磁盘
- 控制器:存储、网络
- 互连设备:CPU、存储器、I/O(输入/输出)
每个组件通常作为单个资源类型。例如,主存储器是容量资源,网络接口是I/O资源(可以是IOPS或吞吐量)。一些组件可以作为多个资源类型的行为:例如,存储设备既是I/O资源,也是容量资源。考虑所有可能导致性能瓶颈的类型。另外要注意,I/O资源可以进一步研究为队列系统,用于排队和处理这些请求。
某些物理组件(例如硬件缓存,如CPU缓存)可以从检查清单中剔除。 USE方法最适合那些在高利用率或饱和下性能降级,导致瓶颈的资源,而缓存在高利用率下提高性能。可以使用其他方法来检查这些资源。如果您不确定是否包含某个资源,请将其包含在内,然后看在实践中指标如何运作。
Functional Block Diagram
//功能块图
另一种迭代资源的方法是找到或绘制系统的功能块图,例如图2.13所示。这样的图表还显示了关系,当寻找数据流中的瓶颈时,这些关系非常有用。
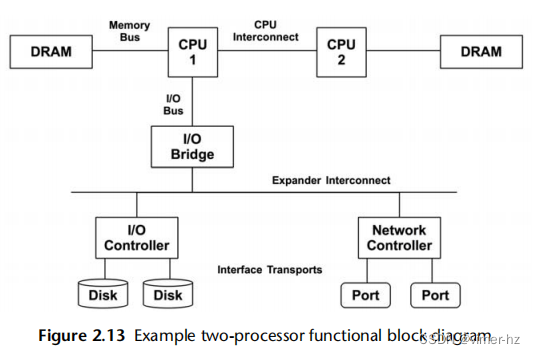
//Disk和CPU之间不是DRAM呀?
CPU、内存和I/O互连和总线通常被忽视。幸运的是,它们通常不是常见的系统瓶颈,因为它们通常被设计为提供足够的吞吐量。不幸的是,如果它们成为瓶颈,问题可能很难解决。也许您可以升级主板或减轻负载;例如,“零拷贝”项目可以减少内存总线负荷。
要调查互连设备,请参阅第6章“CPU”的6.4.1节中的“CPU性能计数器”部分。
Metrics
一旦您列出资源清单,考虑指标类型:利用率、饱和度和错误。表2.5显示了一些示例资源和指标类型,以及可能的指标(通用操作系统)。
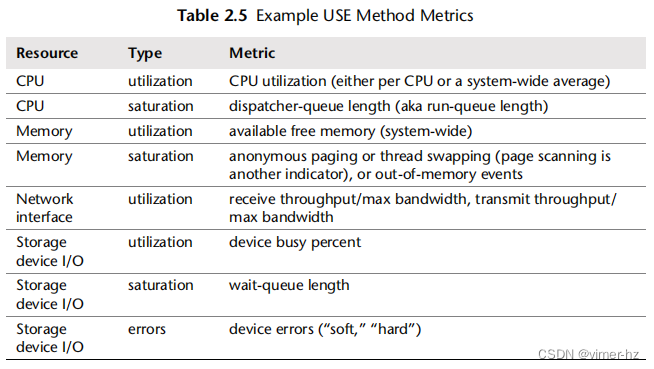
CPU saturation dispatcher-queue length (aka run-queue length)
CPU饱和度:调度器队列长度(也称为运行队列长度)
Memory saturation anonymous paging or thread swapping (page scanning is another indicator), or out-of-memory events
内存饱和度:匿名分页或线程交换(页面扫描是另一个指标),或内存不足事件
/*
内存饱和度详细解释下:
匿名分页是一种内存管理技术,用于在物理内存不足时将部分内存页面从内存中转移到磁盘上,以释放空间给其他进程使用。当系统中出现频繁的匿名分页活动时,这可能是内存饱和的一个指示。
线程交换是另一种内存管理技术,在物理内存不足时,将部分线程的数据和状态从内存中交换到磁盘上,以便为其他线程腾出空间。当系统中发生频繁的线程交换时,也可能是内存饱和的一个迹象。
此外,当系统中的内存资源不足时,可能会触发内存不足事件,导致系统性能下降或应用程序崩溃。
*/
这些指标可以是每个间隔的平均值或计数。
针对所有组合重复此过程,并包含获取每个指标的说明。
注意当前不可用的指标;这些是已知的未知因素。您最终将得到大约30个指标的列表,其中一些很难测量,有些根本无法测量。幸运的是,通常使用较简单的指标(例如CPU饱和度、内存容量饱和度、网络接口利用率、磁盘利用率)可以发现最常见的问题,因此可以首先检查这些指标。
表2.6提供了一些更困难的组合示例。
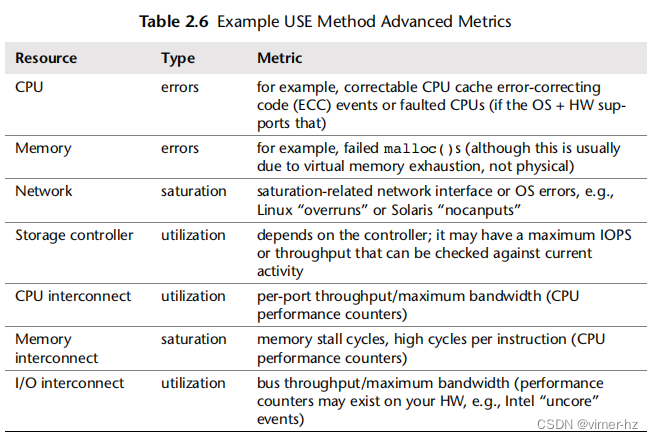
CPU interconnect utilization per-port throughput/maximum bandwidth (CPU performance counters)
CPU互连利用率:每端口吞吐量/最大带宽(CPU性能计数器)
Memory interconnect saturation memory stall cycles, high cycles per instruction (CPU performance counters)
内存互连饱和度:内存停滞周期,每条指令的高周期数(CPU性能计数器)
I/O interconnect utilization bus throughput/maximum bandwidth (performance counters may exist on your HW, e.g., Intel “uncore” events)
I/O互连利用率:总线吞吐量/最大带宽(您的硬件上可能存在性能计数器,例如Intel的“uncore”事件)
其中一些可能无法从标准操作系统工具中获取,并可能需要使用动态跟踪或CPU性能计数器功能。
附录A是Linux系统的USE方法清单示例,迭代使用Linux可观察性工具集对硬件资源进行检查。
附录B提供了基于Solaris系统的相同内容。这两个附录还包括一些软件资源。
Software Resources
软件资源
一些软件资源可以进行类似的检查。通常适用于软件的较小组件,而不是整个应用程序,例如:
- 互斥锁:利用率可以定义为持有锁的时间,饱和度则由排队等待锁的线程决定。
- 线程池:利用率可以定义为线程忙于处理工作的时间,饱和度由等待线程池服务的请求数量决定。
- 进程/线程容量:系统可能有限制的进程或线程数量,当前使用情况可以定义为利用率;等待分配则表示饱和度;错误发生在分配失败时(例如,“无法fork”)。
- 文件描述符容量:与进程/线程容量类似,但是针对文件描述符。
如果这些指标在您的情况下有效,请使用它们;否则,可以应用其他方法,如延迟分析。
Suggested Interpretations
//建议的解释
下面是一些关于指标类型的一般建议:
利用率:通常,100%的利用率是瓶颈的一个迹象(检查饱和度及其影响以确认)。超过60%的利用率可能会出现问题,原因有两个:根据间隔的不同,它可能会隐藏短暂的100%利用率。此外,一些资源(如硬盘,但不包括CPU)通常在操作期间无法中断,即使对于优先级较高的工作也是如此。随着利用率的增加,排队延迟会变得更加频繁和明显。有关60%利用率的更多信息,请参阅第2.6.5节《排队论》。
饱和度:任何程度的饱和度都可能是一个问题(非零)。可以将其测量为等待队列的长度,或者作为在队列上等待的时间。
错误:非零的错误计数器值值得调查,特别是如果它们在性能差的情况下不断增加。
解释负面情况很容易:低利用率,无饱和度,无错误。这比听起来更有用——缩小调查的范围可以帮助您迅速专注于问题区域,并确定它可能不是资源问题。这是排除法的过程。
Cloud Computing
//云计算
在云计算环境中,可能会实施软件资源控制,以限制或限制共享一个系统的租户。在Joyent,我们主要使用操作系统虚拟化(SmartOS Zones),它施加了内存限制、CPU限制和存储I/O限制。每个这些资源限制都可以使用类似于检查物理资源的USE方法进行检查。
例如,“内存容量利用率”可以是租户的内存使用量与其内存上限的比较。“内存容量饱和度”可以通过匿名分页活动来观察,即使传统的页面扫描程序可能处于空闲状态。
2.5.10 Workload Characterization
工作负载特征化是一种简单而有效的方法,用于识别一类问题:由于负载过重而引起的问题。它关注系统的输入,而不是结果性能。你的系统可能没有架构或配置问题,但承受的负载超出了其合理处理的范围。
通过回答以下问题可以对工作负载进行特征化:
- 谁造成了负载?进程ID、用户ID、远程IP地址?
- 为什么会发生负载调用?代码路径、堆栈跟踪?
- 负载的特征是什么?IOPS(每秒输入/输出操作数)、吞吐量、方向(读/写)、类型?在适当的情况下包括方差(标准偏差)。
- 负载如何随时间变化?是否存在每日模式?
即使你对这些问题的答案有很强的预期,检查所有这些问题也可能很有用,因为你可能会感到惊讶。
考虑以下情景:你的数据库存在性能问题,其客户端是一组Web服务器。你应该检查谁在使用数据库的IP地址吗?根据配置,你已经预期它们应该是Web服务器。尽管如此,你还是进行了检查,并发现整个互联网似乎都在向数据库投放负载,破坏了它们的性能。事实上,你正在遭受拒绝服务(DoS)攻击!
最佳的性能优化通常是通过消除不必要的工作来实现的。有时,不必要的工作是由应用程序故障引起的,例如,线程陷入循环会创建不必要的CPU负担。它也可能是由于错误的配置,例如在白天运行的系统备份,或者正如之前所述的DoS攻击。特征化工作负载可以识别这些问题,并通过维护或重新配置来消除它们。
如果无法消除已经识别的工作负载,另一种方法可能是使用系统资源控制来限制它。例如,系统备份任务可能通过使用CPU资源压缩备份,然后使用网络资源传输备份来干扰生产数据库。可以使用资源控制(如果系统支持)来限制CPU和网络使用,以便备份仍然进行(速度更慢),而不会损害数据库。
除了识别问题外,工作负载特征化还可以为模拟基准测试的设计提供输入。如果工作负载测量是平均值,理想情况下,你还需要收集分布和变化的详细信息。这对于模拟预期的多样化工作负载非常重要,而不仅仅是测试平均工作负载。有关平均值和变化(标准偏差)的更多信息,请参见第2.8节“统计”和第12章“基准测试”。
工作负载分析还有助于通过识别前者来区分负载问题和架构问题。负载与架构的对比在第2.3节“概念”中介绍过。
执行工作负载特征化的具体工具和指标取决于目标。某些应用程序记录客户端活动的详细日志,这可以是统计分析的源。它们也可能已经提供了关于客户端使用情况的每日或每月报告,可以挖掘其中的细节。
2.5.11 Drill-Down Analysis
钻取分析始于对问题进行高层次的检查,然后根据先前的发现缩小焦点,舍弃那些看似无趣的领域,并深入挖掘那些有趣的领域。这个过程可以涉及深入到软件堆栈的更深层次,如果需要的话,甚至可以涉及硬件,以找到问题的根本原因。
Solaris Performance and Tools [McDougall 06b] 提供了一种用于系统性能的钻取分析方法,包括三个阶段:
1. 监测:用于持续记录随时间变化的高级统计数据,并在可能存在问题时进行识别或警报。
2. 识别:在怀疑存在问题的情况下,将调查范围缩小到特定的资源或感兴趣的领域,识别可能存在的瓶颈。
3. 分析:进一步检查特定的系统领域,试图找出问题的根本原因并量化它。
监控可以在整个公司范围内进行,将所有服务器或云实例的结果进行汇总。传统的方法是使用简单网络管理协议(SNMP),它可用于监控支持该协议的任何网络连接设备。所得到的数据可能会显示出长期模式,而在短时间内使用命令行工具时可能会被忽略。许多监控解决方案在怀疑存在问题时提供警报,促使分析转入下一阶段。
在服务器上,识别是通过交互方式进行的,使用标准的可观测性工具来检查系统组件:CPU、磁盘、内存等。通常是通过使用诸如vmstat(1)、iostat(1)和mpstat(1)等工具的命令行会话来完成的。一些较新的工具允许通过图形用户界面进行实时交互式性能分析(例如,Oracle ZFS存储设备分析)。
分析工具包括基于跟踪或分析的工具,用于对可疑区域进行更深入的检查。这种更深入的分析可能涉及创建自定义工具,并检查源代码(如果有的话)。这就是大部分钻取的地方,根据需要剥离软件堆栈的各层,以找到根本原因。执行此操作的工具包括strace(1)、truss(1)、perf和DTrace。
Five Whys
在分析阶段,您还可以使用五个为什么的技术:问自己“为什么?”然后回答这个问题,总共重复五次(或更多)。以下是一个示例过程:
1. 数据库对许多查询开始表现不佳。为什么?
2. 这是由于内存分页导致的磁盘I/O延迟。为什么?
3. 数据库内存使用量增长过大。为什么?
4. 分配器消耗的内存超过了应有的数量。为什么?
5. 分配器存在内存碎片问题。
这是一个真实世界的例子,非常出乎意料地导致了系统内存分配库的修复。正是通过持续的质疑和深入挖掘到核心问题,才导致了修复的发现。
2.5.12 Latency Analysis
延迟分析检查完成操作所需的时间,然后将其分解为更小的组件,继续细分具有最高延迟的组件,以便确定和量化根本原因。类似于深入分析,延迟分析可能会通过软件堆栈的各层进行深入挖掘,以找到延迟问题的根源。
分析可以从应用的工作负载开始,检查该工作负载在应用程序中的处理方式,然后深入到操作系统库、系统调用、内核和设备驱动程序中。
例如,对MySQL查询延迟的分析可能涉及回答以下问题(这里给出了示例答案):
1. 是否存在查询延迟问题?(是)
2. 查询时间主要是花费在CPU上还是等待CPU之外?(等待CPU之外)
3. 等待CPU之外的时间是用来等待什么的?(文件系统I/O)
4. 文件系统I/O时间是由于磁盘I/O还是锁争用?(磁盘I/O)
5. 磁盘I/O时间很可能是由于随机寻道还是数据传输时间?(传输时间)
对于这个例子,每个步骤都提出了一个问题,将延迟分成两部分,然后继续分析较大的部分:如果你愿意,可以将其视为延迟的二进制搜索。该过程如图2.14所示。
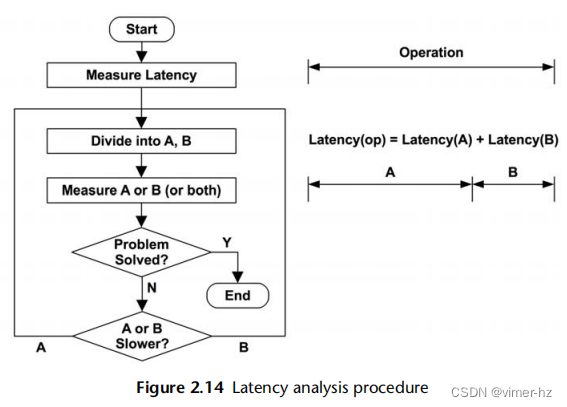
当A或B中较慢的部分被确定后,它会进一步分成A或B,并进行分析等操作。
方法R的目标是对数据库查询进行延迟分析。
2.5.13 Method R
Method R是针对Oracle数据库开发的一种性能分析方法,重点是基于Oracle跟踪事件找到延迟的来源[Millsap 03]。它被描述为“一种基于响应时间的性能改进方法,为您的业务带来最大的经济价值”,并且专注于识别和量化查询过程中的时间消耗。尽管该方法用于数据库的研究,但其方法也可以应用于任何系统,并且值得在这里提及作为一个可能的研究途径。
2.5.14 Event Tracing
系统通过处理离散事件来运行。这些事件包括CPU指令、磁盘I/O和其他磁盘命令、网络数据包、系统调用、库调用、应用程序事务、数据库查询等等。性能分析通常研究这些事件的摘要,例如每秒操作次数、每秒字节数或平均延迟。有时,在摘要中会丢失重要的细节,最好在逐个事件进行检查时对其进行理解。
网络故障排除通常需要逐个数据包的检查,使用诸如tcpdump(1)之类的工具。这个例子将数据包总结为单行文本:
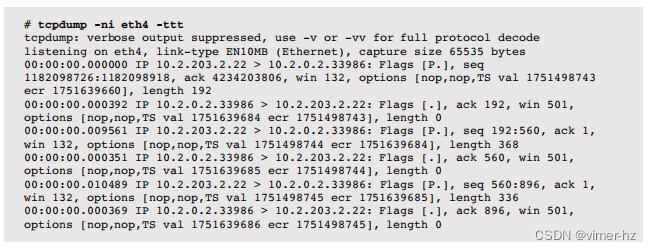
根据需要,tcpdump(1)可以打印不同数量的信息(请参阅第10章“网络”)。
可以使用iosnoop(1M)(基于DTrace)来跟踪块设备层的存储设备I/O(请参阅第9章“磁盘”):
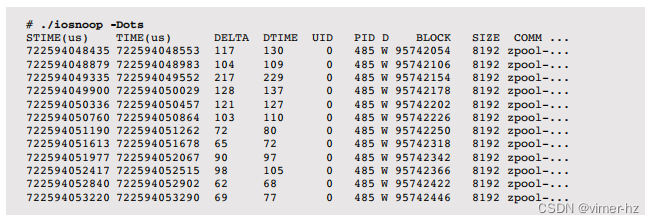
这里打印了多个时间戳,包括开始时间(STIME)、结束时间(TIME)、请求和完成之间的时间差(DELTA)以及估算的服务此I/O所需的时间(DTIME)。
系统调用层也是常见的跟踪位置,工具包括Linux上的strace(1)和基于Solaris的系统上的truss(1)(请参阅第5章“应用程序”)。这些工具也有选项来打印时间戳。
在执行事件跟踪时,寻找以下信息:
输入:事件请求的所有属性:类型、方向、大小等。
时间:开始时间、结束时间、延迟(差异)。
结果:错误状态、事件结果(大小)。
有时,通过检查事件的请求或结果的属性,可以理解性能问题。使用事件跟踪工具,可以通过事件时间戳特别有助于分析延迟,并且通常可以包含在内。
前面的tcpdump(1)输出包括Delta时间戳,测量数据包之间的时间,使用-ttt。
对先前事件的研究提供了更多信息。特别糟糕的延迟事件,称为延迟异常值,可能是由以前的事件而不是事件本身引起的。例如,队列尾部的事件可能具有高延迟,但是是由前面的队列事件引起的,而不是其自身属性引起的。可以从跟踪事件中识别此类情况。
2.5.15 Baseline Statistics
将当前的性能指标与过去的数值进行比较通常是很有启发性的。
可以识别负载或资源使用的变化,并追溯问题的首次出现。一些可观测性工具(基于内核计数器的工具)可以显示自引导以来的摘要,以便与当前活动进行比较。这虽然粗糙,但总比没有好。另一种方法是收集基准统计数据。
这可能涉及执行各种系统可观测性工具,并记录输出以供将来参考。与自引导以来的摘要不同,它可以包括每秒的统计数据,以便看到变化。
在系统或应用程序更改之前和之后可能会收集基线统计数据,以便分析性能变化。它也可以不定期地收集,并包含在站点文档中,以便管理员可以了解“正常”情况。每天定期执行此任务是性能监控的一项活动(参见第2.9节“监控”)。
2.5.16 Static Performance Tuning
静态性能调整关注的是配置体系结构方面的问题。其他方法则关注应用负载的性能:动态性能[Elling 00]。当系统处于静止状态且没有负载时,可以进行静态性能分析。
对于静态性能分析和调整,请逐个检查系统的所有组件并检查以下内容:
- 组件是否合理?
- 配置是否符合预期的工作负载?
- 是否自动配置了最适合预期工作负载的组件?
- 组件是否遇到错误并处于降级状态?
以下是使用静态性能调整可能找到的一些问题示例:
- 网络接口协商:选择100 Mbits/s而不是1 Gbit/s
- RAID池中的损坏磁盘
- 使用旧版本操作系统、应用程序或固件
- 文件系统记录大小与工作负载I/O大小不匹配
- 服务器意外配置为路由器
- 配置服务器以从远程数据中心而不是本地使用资源(如身份验证)
幸运的是,这些类型的问题很容易检查。难点在于记得去做!
2.5.17 Cache Tuning
应用程序和操作系统可能会使用多个缓存来提高I/O性能,从应用程序到磁盘。有关完整列表,请参见第3章“操作系统”中的第3.2.11节“缓存”。以下是针对每个缓存级别的一般性调整策略:
1. 旨在尽可能高地在堆栈中缓存,靠近执行工作的位置,减少缓存命中的操作开销。
2. 检查缓存是否已启用并正常工作。
3. 检查缓存命中/未命中比率和未命中率。
4. 如果缓存大小是动态的,请检查其当前大小。
5. 针对工作负载调整缓存。此任务取决于可用的缓存可调参数。
6. 针对缓存调整工作负载。这包括减少不必要的缓存消费者,为目标工作负载释放更多空间。
注意双重缓存,例如消耗主内存并将相同数据缓存两次的两个不同缓存。
还应考虑每个缓存调整级别的整体性能增益。调整CPU一级缓存可能会节省纳秒时间,因为缓存未命中可以由二级缓存服务。但是改进CPU三级缓存可能避免更慢的DRAM访问,并导致更大的整体性能增益。(这些CPU缓存在第6章“CPU”中描述。)
2.5.18 Micro-Benchmarking
微基准测试评估简单和人为工作负载的性能。它可以用于支持科学方法,验证假设和预测,也可以是容量规划的一部分。
这与通常旨在测试真实世界和自然工作负载的行业基准测试不同。此类基准测试通过运行工作负载模拟来进行,可能变得复杂以进行和理解。
微基准测试较为简单,因为涉及的因素较少。可以通过应用工作负载并测量性能的微基准工具来执行,或者可以使用仅应用工作负载而将性能测量留给标准系统工具的负载生成器工具。两种方法都可以,但最安全的方法可能是使用微基准工具,并使用标准系统工具再次检查性能。
微基准测试的一些示例目标,包括测试的第二个维度,是:
- 系统调用时间:对于fork()、exec()、open()、read()、close()
- 文件系统读取:从缓存文件中读取,将读取大小从1字节变化到1兆字节
- 网络吞吐量:在TCP端点之间传输数据,对于不同的套接字缓冲区大小
微基准测试通常尽可能快地执行目标操作,并测量完成大量操作所需的时间。然后可以计算平均时间(平均时间 = 运行时间/操作计数)。后面的章节中将介绍具体的微基准测试方法,列出要测试的目标和属性。有关基准测试的主题将在第12章“基准测试”中详细讨论。
2.6 Modeling
对系统进行分析建模可以用于多种目的,特别是可扩展性分析:研究随着负载或资源的扩展而性能如何扩展。资源可以是硬件,例如CPU核心,也可以是软件,例如进程或线程。
分析建模可以被视为第三种性能评估活动,与生产系统的可观察性("测量")和实验性测试("模拟")一同存在[Jain 91]。只有在至少进行两个这些活动时,性能才能得到最好的理解:分析建模和模拟,或者模拟和测量。
如果分析是针对现有系统的,可以从测量开始:描述负载和相应的性能。如果系统尚未具备生产负载,或者要测试超出生产中所见负载的工作负载,可以使用试验性分析,通过测试工作负载模拟来进行。分析建模可用于预测性能,并且可以基于测量或模拟的结果。
可扩展性分析可能会揭示性能在某个点(称为拐点)停止线性扩展,这是由于资源限制所致。找出是否存在这些点,以及它们位于何处,可以引导对抑制可扩展性的性能问题进行调查,以便在生产中遇到之前修复它们。
有关这些步骤的更多信息,请参阅第2.5.10节"工作负载描述"和第2.5.18节"微基准测试"。
2.6.1 Enterprise versus Cloud
虽然建模使我们能够模拟大规模企业系统,而无需拥有实际系统,但大规模环境的性能往往复杂且难以准确建模。
通过云计算,可以租用任何规模的环境进行短期使用——例如基准测试的时长。与创建数学模型以预测性能不同,工作负载可以被描述、模拟,然后在不同规模的云端进行测试。一些发现,如拐点,可能是相同的,但现在是基于实测数据而不是理论模型,并通过测试真实环境,您可能会发现未包含在您的模型中的限制因素。
2.6.2 Visual Identification
当实验收集到足够的结果时,将它们作为交付性能与缩放参数的关系绘制出来,可能会揭示出一种模式。
图2.15显示了应用程序的吞吐量随线程数量的缩放而变化。在大约八个线程处出现了一个拐点,斜率发生了变化。现在可以对此进行进一步研究,例如查看应用程序和系统配置是否存在接近八的设置值。
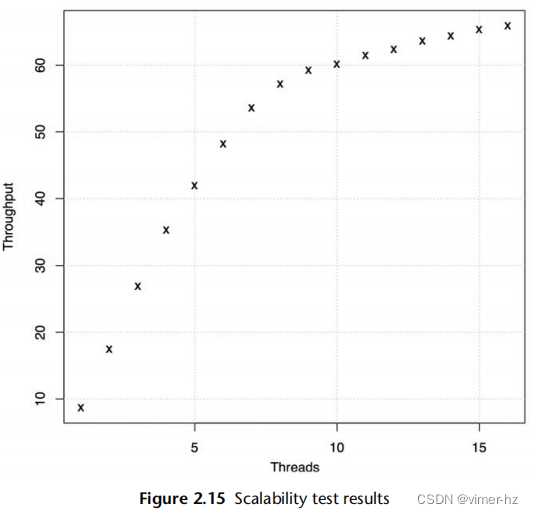
在这种情况下,系统是一个具有八个核心的系统,每个核心具有两个硬件线程。为了进一步确认这与CPU核心数有关,可以调查并比较少于八个和多于八个线程时的CPU影响(例如,CPI;参见第6章,CPU)。或者,可以通过在具有不同核心数的系统上重复进行缩放测试,并确认拐点按预期移动来进行实验性的研究。
有许多可视化识别的可扩展性配置文件,而无需使用正式模型。这些显示在图2.16中。
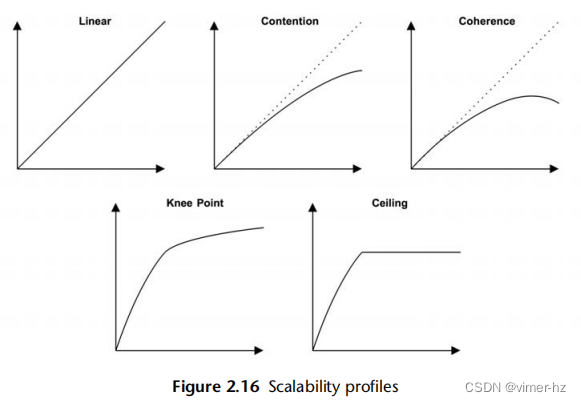
Contention/Coherence/Knee Point/Ceiling
竞争/一致性/拐点/上限
对于每个情况,x轴是可扩展性维度,y轴是结果性能(吞吐量、每秒事务数等)。以下是这些模式:
线性可扩展性:随着资源的扩展,性能成比例增加。这种趋势可能不会一直持续下去,而是可能是另一种可扩展性模式的早期阶段。
竞争:体系结构的某些组件是共享的,并且只能串行使用,对于这些共享资源的竞争开始降低扩展性的效果。
一致性:为了保持数据的一致性,包括传播变化的开销开始超过扩展的好处。
拐点:在某个可扩展性点遇到一个因素,改变了可扩展性配置文件。
可扩展性上限:达到了一个硬性限制。这可能是设备瓶颈,例如总线或互连达到最大吞吐量,或者是软件施加的限制(系统资源控制)。
虽然通过可视化识别可以简单有效,但使用数学模型可以更详细地了解系统的可扩展性。模型可能以意想不到的方式偏离数据,这对于调查很有用:要么模型存在问题,因此您对系统的理解存在问题,要么问题在于系统的实际可扩展性。接下来的章节介绍了Amdahl's Law of Scalability(阿姆达尔定律)、Universal Scalability Law(通用可扩展性定律)和排队理论。
2.6.3 Amdahl’s Law of Scalability
//阿姆达尔可扩展性定律
这条定律以计算机架构师Gene Amdahl [Amdahl 67]的名字命名,它模拟系统的可扩展性,考虑到不以并行方式扩展的串行工作负载组件。它可以用于研究CPU、线程、工作负载等的扩展性。Amdahl's Law of Scalability在之前的可扩展性配置文件中被描述为竞争,描述了对串行资源或工作负载组件的竞争。它可以定义为[Gunther 97]:
C(N) = N/1 + α(N - 1)
其中,相对容量为C(N),N是扩展维度,例如CPU数量或用户负载。参数α(其中0 <= α <= 1)表示串行度的程度,即与线性可扩展性的偏差程度。
可以通过以下步骤应用Amdahl's Law of Scalability:
1. 收集一系列N的数据,可以通过观察现有系统或使用微基准测试或负载生成器进行实验来收集数据。
2. 进行回归分析以确定Amdahl参数(D);可以使用统计软件如gnuplot或R来完成此步骤。
3. 提供结果以进行分析。可以将收集的数据点与模型函数绘制在一起,以预测扩展性并揭示数据与模型之间的差异。这也可以使用gnuplot或R来完成。以下是Amdahl's Law of Scalability回归分析的示例gnuplot代码,以提供执行此步骤的思路:

在R中处理这个类似的代码需要相同的量级,涉及到使用nls()函数进行非线性最小二乘拟合以计算系数,然后在绘图过程中使用这些系数。在本章末尾的参考资料中,可以找到完整的gnuplot和R代码的性能可扩展性模型工具包[2]。下一节将展示一个Amdahl's Law of Scalability函数的示例。
2.6.4 Universal Scalability Law
//通用可扩展性定律
通用可扩展性定律(USL),之前称为超级串行模型[Gunther 97],是由Neil Gunther博士开发的,包括一种相干延迟参数。这在先前被描绘为相干可扩展性配置文件,包括竞争效应。
USL可以定义为
C(N) = N/1 + α(N - 1) + EN(N - 1)
其中,C(N), N和α与Amdahl's Law of Scalability相同。E是相干参数。当E == 0时,这变成了Amdahl's Law of Scalability。
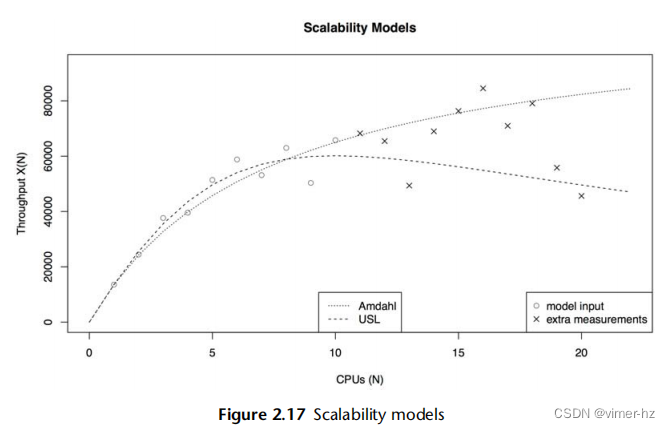
图2.17展示了USL和Amdahl's Law of Scalability分析的示例。输入数据集具有高度的方差,使得难以直观地确定可扩展性配置文件。前十个数据点以圆圈的形式呈现,并提供给模型。还绘制了另外十个数据点,以叉的形式呈现,用于检查模型预测与实际情况之间的差异。
有关USL分析的更多信息,请参见[Gunther 97]和[Gunther 07]。
2.6.5 Queueing Theory
排队论是对具有队列的系统进行数学研究的学科,提供了分析队列长度、等待时间(延迟)和利用率(基于时间)的方法。计算机中的许多组件,包括软件和硬件,都可以建模为排队系统。对多个排队系统进行建模称为排队网络。
本节总结了排队论的作用,并提供了一个示例,以帮助您理解其作用。排队论是一个广泛的研究领域,在其他文献中有详细介绍([Jain 91],[Gunther 97]),如果有需要的话,可以深入学习。
排队论建立在数学和统计学的各个领域基础上,包括概率分布、随机过程、Erlang的C公式(Agner Krarup Erlang发明了排队论)和Little's Law。Little's Law可以表示为
L = λW
其中,L确定系统中的平均请求数,λ是平均到达率,W是平均服务时间,它们相乘得到。
排队系统可以用来回答各种问题,包括以下几个:
- 如果负载加倍,平均响应时间将是多少?
- 添加一个额外的处理器后,平均响应时间会有什么影响?
- 在负载加倍的情况下,系统能否提供小于100毫秒的90th百分位响应时间?
除了响应时间,还可以研究其他因素,包括利用率、队列长度和常驻作业数量。
图2.18显示了一个简单的排队系统模型。
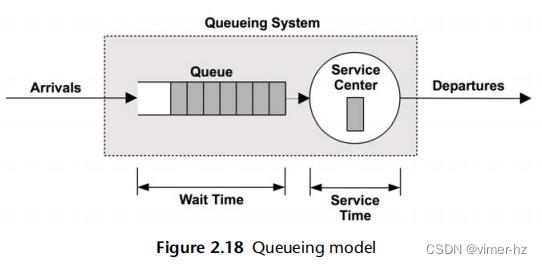
这个系统有一个单一的服务中心,负责处理队列中的作业。排队系统也可以拥有多个并行处理工作的服务中心。在排队论中,这些服务中心通常被称为服务器。
排队系统可以根据三个因素进行分类:
- 到达过程:描述请求到达队列系统的间隔时间,可能是随机的、固定的或者遵循泊松过程(使用指数分布表示到达时间)等。
- 服务时间分布:描述服务中心的服务时间。它们可能是固定的(确定性的)、指数分布的,或者其他类型的分布。
- 服务中心的数量:一个或多个。
这些因素可以用Kendall符号表示。
Kendall’s Notation
这个符号为每个属性分配了代码。它的形式是 A/S/m。这些属性分别表示到达过程 (A)、服务时间分布 (S) 和服务中心的数量 (m)。还有一种扩展形式的Kendall符号,包括更多的因素:系统中的缓冲区数量、总人数和服务纪律。
常见的研究排队系统的例子有:
- M/M/1:马尔可夫到达(指数分布的到达时间)、马尔可夫服务时间(指数分布)、一个服务中心。
- M/M/c:与M/M/1相同,但是有多个服务器。
- M/G/1:马尔可夫到达,服务时间的分布是一般的(可以是任意分布),一个服务中心。
- M/D/1:马尔可夫到达,服务时间是确定性的(固定时间),一个服务中心。
M/G/1常用于研究旋转硬盘的性能。
M/D/1 and 60% Utilization
作为排队论的一个简单例子,考虑一个以确定性方式响应工作负载的硬盘(这是一个简化)。该模型是M/D/1。
提出的问题是:随着利用率的增加,硬盘的响应时间如何变化?
排队论可以计算M/D/1的响应时间:
r = s(2 - U)/2(1 - U)
其中,响应时间 r 是以服务时间 s 和利用率 U 来定义的。
对于服务时间为1毫秒和利用率从0到100%的情况,这个关系已经在图2.19中绘制出来。
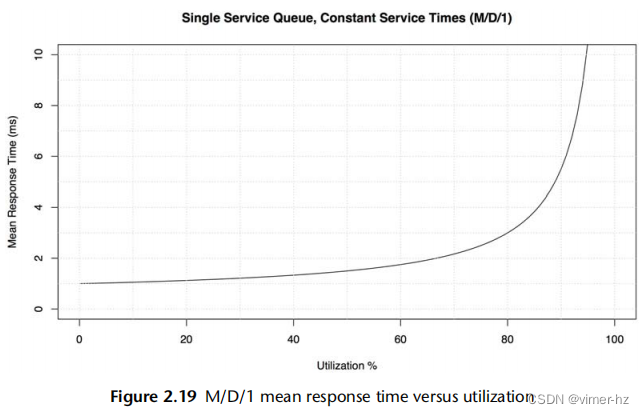
超过60%的利用率后,平均响应时间翻倍。当达到80%时,它会增加三倍。由于磁盘I/O延迟通常是应用程序的限制资源,将平均延迟增加一倍或更多可能会对应用程序性能产生显著的负面影响。这就是为什么磁盘利用率在达到100%之前就可能成为一个问题的原因,因为它是一个排队系统,请求(通常)无法中断,必须等待它们的顺序。这与例如CPU不同,CPU可以进行高优先级的抢占。
这个图形可以直观地回答之前的一个问题:当负载加倍时,平均响应时间将是多少?—这是相对于负载的利用率。
这个模型是简单的,从某种程度上展示了最好的情况。服务时间的变化可能会使平均响应时间增加(例如使用M/G/1或M/M/1)。还有一个响应时间的分布,图2.19中没有显示出来,当利用率超过60%时,第90百分位数和第99百分位数的退化速度要快得多。
与之前关于Amdahl的可扩展性定律的gnuplot示例一样,展示一些实际代码可能有助于了解可能涉及的内容。这次使用了R统计软件[3]:

之前的M/D/1方程已经传递给plot()函数。该代码的大部分部分用于指定图形的限制、线条属性和坐标轴标签。
2.7 Capacity Planning
容量规划(Capacity Planning)考察系统在处理负载时的能力以及随着负载增加而扩展的能力。可以通过多种方式进行容量规划,包括研究资源限制和因素分析(在此介绍),以及建模(如前所述)。本节还包括了扩展的解决方案,包括负载均衡器和分片。有关更多信息,请参阅《容量规划的艺术》[Allspaw 08]。
对于特定应用程序的容量规划,有一个明确的性能目标会有所帮助。在第5章的早期部分讨论了如何确定这个目标。
2.7.1 Resource Limits
这种方法是寻找在负载下将成为瓶颈的资源。其中的步骤如下:
1.测量服务器请求速率,并随时间监控此速率。
2.测量硬件和软件资源使用情况,并随时间监控此速率。
3.以所使用的资源为基础来表达服务器请求。
4.将服务器请求外推到每个资源的已知(或经过实验确定的)限制。
首先要确定服务器的角色和它所服务的请求类型。例如,Web服务器提供HTTP请求服务,网络文件系统(NFS)服务器提供NFS协议请求(操作)服务,数据库服务器提供查询请求服务(或者是命令请求,而查询是其中的一个子集)。
下一步是确定每个请求对系统资源的消耗量。对于现有系统,可以测量当前请求速率以及资源利用情况。然后可以使用外推法来确定哪个资源将首先达到100%利用率以及请求速率是多少。
对于未来的系统,可以使用微基准测试或负载生成工具在测试环境中模拟预期的请求,同时测量资源利用情况。在足够的客户端负载下,您可以通过实验找到极限。
需要监控的资源包括:
硬件:CPU利用率、内存使用情况、磁盘IOPS、磁盘吞吐量、磁盘容量(已使用的卷)、网络吞吐量
软件:虚拟内存使用情况、进程/任务/线程、文件描述符
假设您正在查看一个目前每秒执行1,000个请求的现有系统。最繁忙的资源是16个CPU,平均利用率为40%;您预测一旦它们达到100%利用率,它们将成为这个工作负载的瓶颈。问题是:此时请求每秒的速率是多少?
每个请求的CPU% = 总CPU%/请求数 = 16 x 40%/1,000 = 0.64% CPU per request
最大请求速率 = 100% x 16 CPUs/CPU% per request = 1,600 / 0.64 = 2,500 requests/s
预测结果是每秒2,500个请求,此时CPU将达到100%利用率。这是容量的一个粗略的最佳估计,因为在请求达到该速率之前可能会遇到其他限制因素。
此次演习仅使用了一个数据点:1,000个应用程序吞吐量(每秒请求数)与40%的设备利用率。如果启用随时间的监控,可以包括不同吞吐量和利用率的多个数据点,以提高估计的准确性。图2.20展示了一种用于处理这些数据并推断最大应用程序吞吐量的可视化方法。
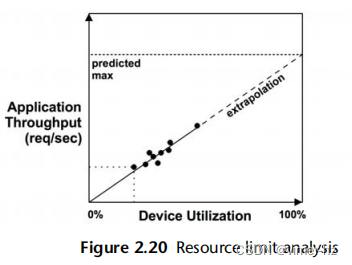
2,500个请求/秒足够吗?回答这个问题需要了解峰值工作负载,它显示在每日访问模式中。对于您经过一段时间监控的现有系统,您可能已经知道峰值会是什么样子。
考虑一个处理每天10万个网站点击的Web服务器。这听起来很多,但平均每秒只有约1个请求,不算多。然而,可能大多数的10万个网站点击发生在发布新内容后的几秒钟内,所以峰值是显著的。
2.7.2 Factor Analysis
在购买和部署新系统时,通常有许多因素可以改变以实现所需的性能。这些因素可能包括磁盘和CPU的数量、内存的大小、闪存设备的使用、RAID配置、文件系统设置等等。任务通常是以最低成本实现所需的性能。
测试所有组合将确定哪种组合具有最佳的性价比;然而,这很容易失控:八个二进制因素将需要进行256次测试。
一种解决方法是测试一组有限的组合。以下是一种基于已知最大系统配置的方法:
1. 将所有因素配置为最大值进行性能测试。
2. 逐个更改因素,测试性能(每次测试应该会降低)。
3. 根据测量结果,将性能下降的百分比归因于每个因素,以及与成本节省相关的情况。
4. 从最大性能(和成本)开始,选择要节省成本的因素,同时基于它们的综合性能下降来保持所需的每秒请求数。
5. 对计算得到的配置进行重新测试,以确认所提供的性能。
对于一个八因素系统,这种方法可能只需要进行十次测试。
以一个新存储系统的容量规划为例,要求读取吞吐量为1 Gbyte/s,工作集大小为200 Gbyte。最大配置可实现2 Gbytes/s,并包括四个处理器、256 Gbytes的DRAM、2个双端口10 GbE网络卡、巨型帧,并禁用压缩和加密(启用这些功能会增加成本)。切换到两个处理器将使性能下降30%,一个网络卡下降25%,非巨型帧下降35%,加密下降10%,压缩下降40%,DRAM减少90%,因为工作负载不再被预期完全缓存。根据这些性能下降和已知的节省情况,现在可以计算出满足要求的最佳性价比系统;可能是一个具有两个处理器和一个网络卡的系统,达到所需的吞吐量:2 × (1 - 0.30) × (1 - 0.25) = 1.04 Gbytes/s 的估计值。然后明智的做法是测试这个配置,以防这些组件在一起使用时的实际性能与预期性能不同。
2.7.3 Scaling Solutions
满足更高的性能需求通常意味着使用更大的系统,这种策略被称为纵向扩展。将负载分布在多个系统上,通常通过称为负载均衡器的系统来实现,使它们看起来像一个系统,这被称为横向扩展。
云计算进一步发展了横向扩展,通过基于较小的虚拟化系统而不是整个系统来构建。这在购买用于处理所需负载的计算资源时提供了更细粒度的控制,并允许以小而高效的增量进行扩展。由于不需要像企业主机那样进行初始的大规模采购(包括支持合同承诺),因此在项目的早期阶段不需要进行严格的容量规划。
云上数据库的常见扩展策略是分片,即将数据分割为逻辑组件,每个组件由自己的数据库(或冗余数据库组)管理。例如,可以按照客户名称的字母范围将客户数据库分割为多个部分。
可扩展性设计非常依赖于您需要处理的工作负载和希望使用的应用程序。有关更多信息,请参阅《可扩展的互联网架构》[Schlossnagle 06]。
2.8 Statistics
了解如何使用统计数据以及它们的局限性非常重要。本节将讨论使用统计数据(指标)和统计类型来量化性能问题,包括平均值、标准差和百分位数。
2.8.1 Quantifying Performance
量化问题及其潜在的性能改进,可以对它们进行比较和优先排序。这项任务可以使用观察或实验来完成。
基于观察的方法
使用观察来量化性能问题的步骤如下:
1. 选择一个可靠的指标。
2. 估计解决该问题后的性能提升。
例如:
观察到:应用程序请求需要10毫秒。
观察到:其中9毫秒用于磁盘I/O操作。
建议:配置应用程序将I/O缓存在内存中,预计DRAM延迟约为10微秒。
预计的改进:10毫秒÷1.01毫秒(10毫秒-9毫秒+10微秒)≈ 9倍的改进。
正如在第2.3节“概念”中介绍的那样,延迟(时间)非常适合这个场景,因为可以直接在组件之间进行比较,从而使得这种计算成为可能。
在使用延迟时,请确保将其作为应用程序请求的同步组件进行测量。某些事件是异步发生的,例如后台磁盘I/O(写入刷新到磁盘),并不直接影响应用程序性能。
基于实验的方法
使用实验来量化性能问题的步骤如下:
1. 应用修复措施。
2. 使用可靠的指标量化修复前后的性能差异。
例如:
观察到:应用程序事务延迟平均为10毫秒。
实验:增加应用程序线程数以允许更多并发而不是排队。
观察到:应用程序事务延迟平均为2毫秒。
改进:10毫秒÷2毫秒 = 5倍的提升。
如果修复在生产环境中尝试成本过高,则此方法可能不适用!
2.8.2 Averages
平均值代表一个数据集的单个值:中心趋势指标。最常用的平均值类型是算术平均值(或简称平均值),它是值的总和除以值的数量。其他类型包括几何平均数和调和平均数。
几何平均数
几何平均数是乘积值的第n个根(其中n是值的数量)。这在[Jain 91]中有描述,其中包括一个使用它进行网络性能分析的示例:如果分别测量内核网络堆栈的每个层的性能改进,那么平均性能改进是多少?由于这些层在同一个数据包上一起工作,性能改进具有“乘法”效应,最好通过几何平均数来总结。
调和平均数
调和平均数是值的数量除以它们的倒数之和。它在计算速率的平均值时可能更合适,例如,在计算800 M字节数据的平均传输速率时,前100 M字节将以50 M字节/秒的速率发送,而剩下的700 M字节将以限速速率10 M字节/秒发送。使用调和平均数,答案是800/(100/50 + 700/10) = 11.1 M字节/秒。
随时间变化的平均值
在性能方面,我们研究的许多指标都是随时间变化的平均值。CPU从来不会处于“50%的利用率”状态;它在某个时间间隔内被利用了50%,这个时间间隔可以是一秒、一分钟或一小时。在考虑平均值时,检查时间间隔非常重要。
例如,我曾遇到一个问题,客户在CPU饱和(调度延迟)引起的性能问题,尽管他们的监控工具显示CPU利用率从未超过80%。监控工具报告的是5分钟的平均值,这掩盖了CPU利用率在某些时刻达到100%的情况。
衰减平均值
在系统性能中,有时会使用衰减平均值。例如,uptime(1)报告的系统“负载平均值”和基于Solaris的系统上的每个进程的CPU利用率。
衰减平均值仍然是在一个时间区间内测量的,但是最近的时间比过去的时间更加重要。这减少(抑制)了平均值中的短期波动。
详细了解这方面内容,请参阅第6章“CPU”中第6.6节“负载平均值”。
2.8.3 Standard Deviations, Percentiles, Median
标准差和百分位数(例如,第99百分位数)是提供有关数据分布的统计技术。标准差是方差的一种度量,较大的值表示与平均值(均值)的差异较大。第99百分位数显示了包括99%的值的分布点。图2.21展示了正态分布中的这些值,以及最小值和最大值。
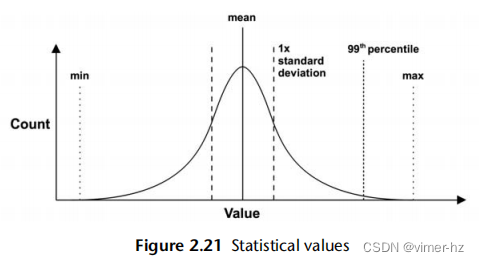
百分位数,例如第99、90、95和99.9百分位数,用于性能监测请求延迟,以量化人群中最慢的部分。这些百分位数也可以在服务级别协议(SLA)中指定,作为衡量大多数用户接受性能的一种方式。
第50百分位数,称为中位数,可以用来显示数据的大部分所在位置。
2.8.4 Coefficient of Variation
由于标准差与均值相关,只有在考虑到标准差和均值时,方差才能被理解。单独一个标准差为50的信息并不多。但是,如果再加上均值为200,那就能得到很多信息。
有一种方法可以将变异性表示为一个单一的度量:标准差与均值的比率,称为变异系数(CV)。对于这个例子,变异系数为25%。较低的变异系数意味着较小的方差。
2.8.5 Multimodal Distributions
对于平均值、标准差和百分位数存在一个问题,这可能从前面的图表中就能明显看出:它们适用于正态分布或单峰分布。系统性能通常是双峰分布的,对于快速代码路径返回低延迟,对于慢速代码路径返回高延迟,或者对于缓存命中返回低延迟,对于缓存未命中返回高延迟。也可能存在多个模式。
图2.22展示了读写混合工作负载下磁盘I/O延迟的分布情况,其中包括随机和顺序I/O。
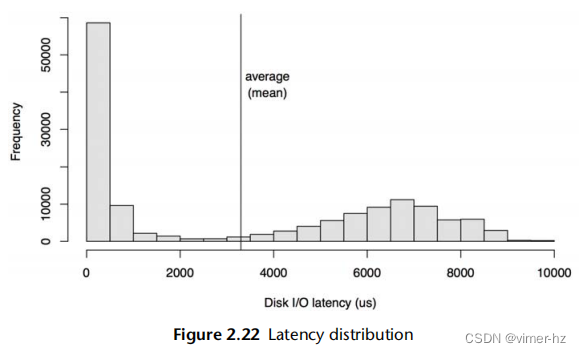
这是一个以直方图形式呈现的数据,显示了两个模式。左边的模式显示了小于1毫秒的延迟,表示磁盘缓存命中。右边的模式,峰值约在7毫秒左右,表示磁盘缓存未命中:随机读取。平均(均值)I/O延迟为3.3毫秒,用一条垂直线表示。这个平均值不是中心趋势指标(如前面所述);实际上,它几乎是相反的。作为一个度量指标,对于这个分布来说,平均值严重误导。
然后有一个人淹死在一个平均水深为六英寸的小溪里。
W. I. E. Gates
每当你看到平均值作为性能指标,尤其是平均延迟时,请问一下:这个分布是怎样的?第2.10节,可视化,提供了另一个例子,展示了不同的可视化和度量指标如何有效地显示这个分布情况。
2.8.6 Outliers
另一个统计问题是离群值的存在:极少量的极高或极低的值,不符合预期的分布(单峰或多峰)。
磁盘I/O延迟离群值就是一个例子——偶尔出现的磁盘I/O可能需要超过1,000毫秒,而大多数磁盘I/O在0到10毫秒之间。像这样的延迟离群值会导致严重的性能问题,但它们的存在很难从大多数度量类型中识别出来,除了最大值之外。
对于正态分布,离群值的存在可能会使均值略微移动,但不会影响中位数(这可能有用)。标准差和99百分位数更有可能识别出离群值,但仍取决于它们的频率。
为了更好地理解多峰分布、离群值和其他复杂的常见行为,可以检查完整的分布,比如使用直方图。有关如何进行此操作的更多方法,请参见第2.10节,可视化。
2.9 Monitoring
系统性能监控会记录随时间变化的性能统计信息(时间序列),以便将过去与现在进行比较,并识别基于时间的使用模式。这对于容量规划、量化增长以及显示峰值使用情况很有用。历史值也可以提供上下文来理解性能指标的当前值,通过显示过去的“正常”范围和平均值。
2.9.1 Time-Based Patterns
图2.23、2.24和2.25展示了基于时间的模式示例,这些图表显示了云计算服务器在不同时间间隔内的文件系统读取情况。这些图形显示了每天的模式,从早上8点左右开始增加,下午稍微下降,然后在夜间逐渐减少。较长时间尺度的图表显示,在周末活动较少。在30天的图表中也可以看到几个短暂的尖峰。
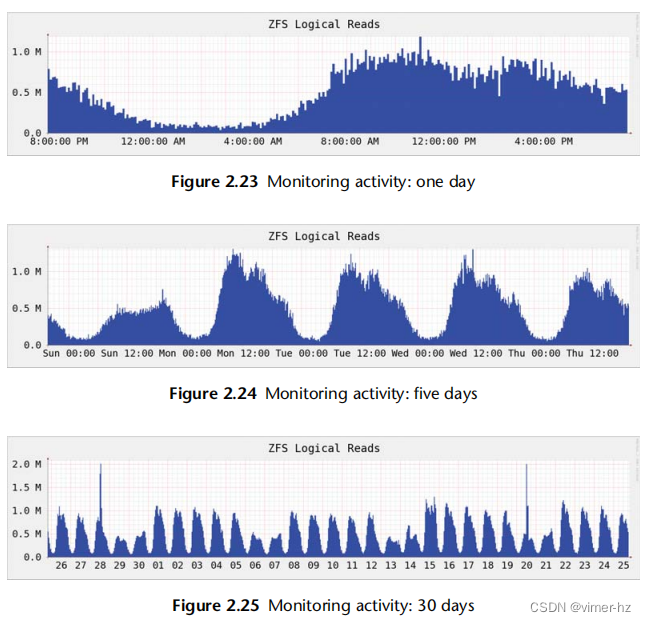
在历史数据中,可以常见地看到各种行为周期,包括图表中显示的周期,例如:
按小时:应用环境可能每小时执行一次活动,如监控和报告任务。这些活动通常以5分钟或10分钟的周期执行。
按天:可能存在与工作时间(上午9点至下午5点)相一致的每日使用模式,如果服务器面向多个时区,则该模式可能会延伸。对于互联网服务器,模式可能会根据全球用户的活动时间而变化。其他每日活动可能包括夜间日志轮换和备份。
按周:除了每日模式外,还可能存在基于工作日和周末的每周模式。
按季度:财务报告按季度进行。其他活动可能会导致负载不规则增加,例如发布网站上的新内容。
2.9.2 Monitoring Products
有许多用于系统性能监控的第三方产品。典型的功能包括将数据存档并以基于浏览器的交互式图形方式呈现,并提供可配置的警报。
其中一些产品通过在系统上运行代理来收集统计信息。这些代理要么执行操作系统的可观察性工具(如sar(1)),然后处理输出(这被认为效率低下,甚至可能导致性能问题!),要么直接链接到操作系统库和接口以直接读取统计信息。
还有一些使用SNMP的监控解决方案。如果系统支持SNMP,则通常无需在系统上运行自定义代理。
随着系统变得更加分布式,并且使用云计算的增长,您可能需要监控大量的系统,甚至可能是数百个或数千个。这就是集中式监控产品尤其有用的地方,它可以允许从一个界面监控整个环境。
一些公司更倾向于开发自己的监控解决方案,以更好地适应其定制环境和需求。
2.9.3 Summary-since-Boot
如果没有进行监控,请检查操作系统是否至少提供了自启动以来的摘要值,这些值可用于与当前值进行比较。
2.10 Visualizations
可视化允许我们查看更多的数据,而不仅仅是在文本显示中能够看到的内容。它们还可以实现模式识别和模式匹配。这是一种有效的方法,可以帮助我们发现不同指标来源之间的相关性,这可能在编程上很难实现,但在视觉上很容易做到。
2.10.1 Line Chart
折线图(也称为线图)是一种众所周知的基本可视化工具。它通常用于随时间变化检查性能指标,将时间显示在x轴上。
图2.26是一个示例,显示了一个20秒周期内的平均磁盘I/O延迟。这是在运行MySQL数据库的生产云服务器上测量的,怀疑磁盘I/O延迟导致查询速度缓慢。
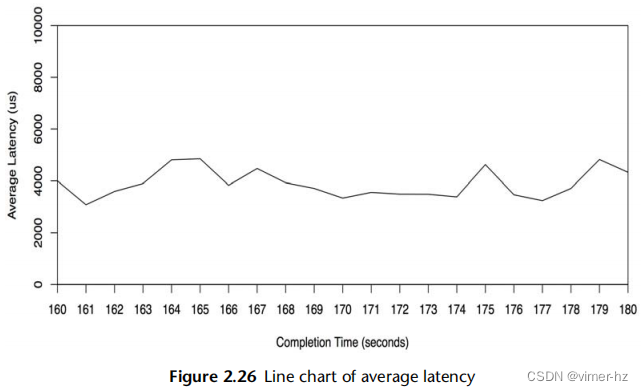
这个折线图显示了大约4毫秒左右的相对一致的平均读取延迟,这高于这些磁盘的预期值。
可以绘制多条线,将相关数据显示在同一组坐标轴上。对于这个示例,可以为每个磁盘绘制单独的线条,以显示它们是否具有类似的性能。
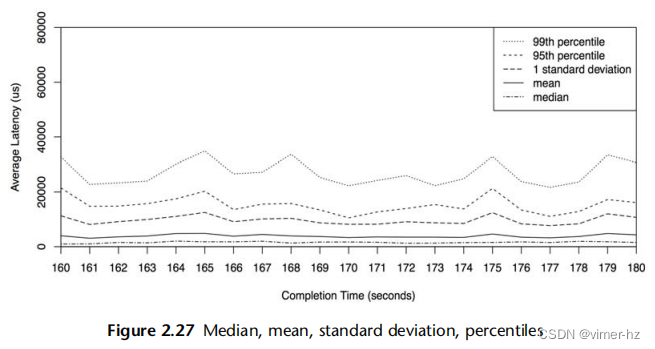
还可以绘制统计值,提供有关数据分布的更多信息。图2.27显示了相同范围的磁盘I/O事件,添加了每秒钟的中位数、标准差和百分位数的线条。请注意,与之前的折线图相比,y轴现在具有更大的范围(扩大了8倍)。
这显示了为什么平均值高于预期:分布中包含了高延迟的I/O操作。具体而言,1%的I/O操作超过20毫秒,由第99百分位数显示。中位数也显示了预期的I/O延迟位置,大约为1毫秒。
2.10.2 Scatter Plots
图2.28以散点图的形式显示了与之前相同时间段内的磁盘I/O事件,这样可以看到所有的数据。每个磁盘I/O操作被绘制为一个点,其完成时间显示在x轴上,延迟显示在y轴上。
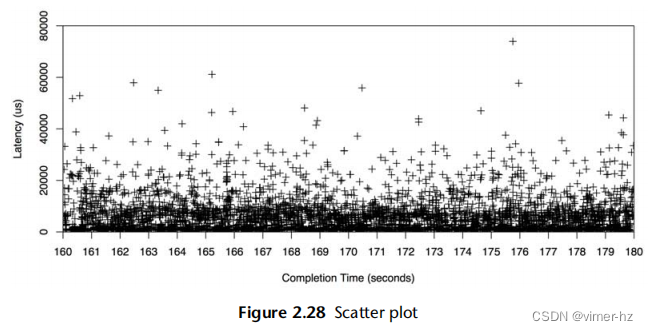
现在可以完全理解高于预期的平均延迟的原因了:存在许多延迟为10毫秒、20毫秒甚至超过50毫秒的磁盘I/O操作。散点图显示了所有的数据,揭示了这些异常值的存在。
许多I/O操作的延迟是亚毫秒级别的,接近x轴。这是散点图分辨率开始成为问题的地方,因为点会重叠在一起,难以区分。随着数据量的增加,问题会变得更加严重:想象一下在一个散点图上绘制来自整个云环境的事件,涉及数百万个数据点。另一个问题是必须收集和处理的数据量:每个I/O操作都需要x和y坐标。
2.10.3 Heat Maps
热力图可以通过将x和y范围量化为称为桶的组来解决散点图的可扩展性问题。这些桶以大像素的形式显示,并根据该x和y范围内的事件数量进行着色。这种量化也解决了散点图的视觉密度限制,使得热力图可以以相同的方式显示来自单个系统或数千个系统的数据。它们可以用于分析延迟、利用率和其他指标【Gregg 10a】。
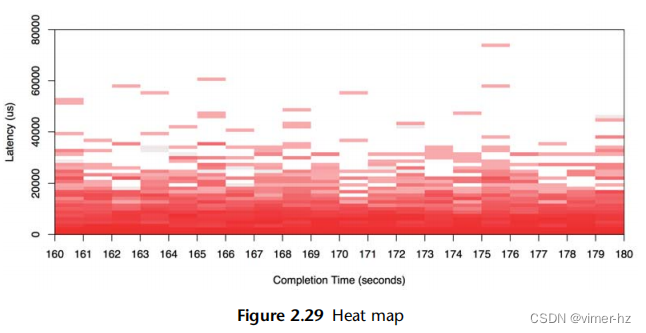
与之前绘制的相同数据集在图2.29中显示为热力图。
高延迟的异常值可以通过热力图中颜色较浅的大块来识别,因为它们跨越很少的I/O操作(通常是单个I/O操作)。数据的主体部分开始出现模式,这些模式在散点图中可能无法看到。
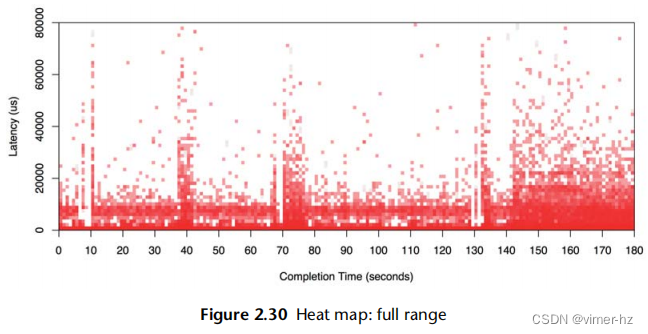
图2.30的热力图显示了此磁盘I/O跟踪的完整秒数范围(之前未显示)。
尽管跨越了九倍的范围,但可视化仍然非常易读。在很大的范围内可以看到双峰分布,其中一些I/O操作的延迟接近于零(可能是磁盘缓存命中),而其他一些I/O操作的延迟略低于1毫秒(可能是磁盘缓存未命中)。
热力图的一个问题是它们还不像折线图那样广为人知,因此用户必须获得一些理解才能有效地使用它们。
本书后面还有各种其他热力图的示例。
2.10.4 Surface Plot
这是一个表示三个维度的三维表面。当第三维的值在相邻点之间不频繁地发生剧烈变化时,它的效果最好,形成了类似起伏山丘的表面。

表面绘图通常以线框模型的形式呈现。图2.31显示了每个CPU利用率的线框表面图。它包含来自许多服务器的60秒每秒值(这是从覆盖了超过300个物理服务器和5,312个CPU的数据中心的图像裁剪出来的)[4]。
每个服务器通过在表面上将其16个CPU作为行进行绘制,将60个每秒的利用率测量作为列,并将表面的高度设置为利用率值。颜色也根据利用率值设置。如果需要,色调和饱和度都可以用来添加第四和第五个维度的数据可视化。(如果分辨率足够高,还可以使用图案来表示第六个维度。)
然后,将这些16 x 60个服务器矩形映射到表面上,形成一个棋盘格。即使没有标记,图像中仍然可以清楚地看到一些服务器矩形。在右侧出现的一个被提升的高原表明其CPU几乎始终处于100%的利用率。
使用网格线突出显示高度的微妙变化。一些淡淡的线条可见,表明一个单独的CPU始终以较低的利用率运行(几个百分比)。
2.10.5 Visualization Tools
由于图形支持有限,Unix性能分析在历史上通常侧重于使用基于文本的工具。这样的工具可以在登录会话中快速执行,并实时报告数据。可视化方面的工具更需要花费时间来获取,并且通常需要进行追踪和报告的循环。在处理紧急性能问题时,您可以访问指标的速度至关重要。
现代的可视化工具提供了系统性能的实时视图,可以从浏览器和移动设备上访问。有许多产品可以实现这一点,包括可以监控整个云端的产品,例如Joyent的Cloud Analytics,这是一个基于DTrace的云端分析工具,可以生成包括延迟热图在内的实时可视化。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









