







目录
1.5 std::function和std::bind绑定器
5.6 异步操作类 std::future,std::promise,std::package_task
10 使用C++11开发一个轻量级的AOP库(代理模式的应用)
11 使用C++11开发一个轻量级的IoC容器(工厂模式的应用及优化)
12 使用C++11开发一个对象的消息总线(观察者模式和中介者模式的应用及优化)
16 使用C++11开发一个简单的通信程序(Proactor模式)
16.1 Reactor反应器模式和Proactor主动器模式介绍
1 使用C++11让程序更简洁
1.1 类型推导(auto和decltype)
1.1 类型推导
1.1.1 auto类型推导
3. auto的限制
void func(auto a =1) {} //error: auto不能用于函数参数
struct Foo
{
auto var = 0; //error: auto不能用于非静态成员变量
static const auto var1 = 0; //ok
}
template <typename T>
struct Bar {};
int main()
{
int arr[10] = {0};
auto a = arr; //ok
auto r[10] = arr; //error: auto无法定义数组
Bar<int> bar;
Bar<auto> bb = bar; //error: auto无法推导出模板参数
return 0;
}4. 何时使用auto
(1)遍历stl容器
int main()
{
std::map<double, double> result;
std::map<double, double>::iterator it = result.begin();
for(; it != result.end(); ++it)
{
//...
}
return 0;
}
使用auto后:
int main()
{
std::map<double, double> result;
for(auto it = result.begin(); it != result.end(); ++it)
{
//...
}
return 0;
}
(2)在unordermap中查找范围
int main()
{
std::unordered_multimap<int, int> res;
...
std::pair<std::unordered_multimap<int, int>::iterator,
std::unordered_multimap<int, int>::iterator>
range = res.equal_range(key);
return 0;
}
使用auto后:
int main()
{
std::unordered_multimap<int, int> res;
...
auto range = res.equal_range(key);
return 0;
}(3)无法知道变量应该被定义成什么类型的情况
template <class A>
void func()
{
auto val = A::get();
// ...
}
class Foo
{
public:
static int get()
{
return 0;
}
};
class Bar
{
public:
static const char* get()
{
return "0";
}
};
int main()
{
func<Foo>();
func<Bar>();
return 0;
}若不适用auto,就不得不对func再增加一个模板参数,并在外部调用时手动指定get的返回类型。
1.1.2 decltype关键字
auto修饰的变量必须被初始化,编译器需要通过初始化来确定auto的类型。
若仅需要得到类型,而不需要定义变量时,用decltype关键字。
decltype(exp)
1.1.3 返回类型后置语法----auto和decltype结合使用
泛型编程中,可能需要通过参数的运算来得到返回值的类型。
template <typename R, typename T, typename U>
R add(T t, U u)
{
return t + u;
}
int a = 1;
float b = 2.0;
auto c = add<decltype(a + b)>(a, b);我们并不关心a+b的类型,因此只需要通过decltype(a + b)得到返回值类型即可。但如上使用十分不方便。尝试修改:
template <typename T, typename U>
decltype(t + u) add(T u, U u)
{
return t + u;
}像上面写编译不过。因为t,u在参数列表里,而C++返回值时前置语法,在返回值定义的时候参数变量还没存在。在C++11中增加了返回类型后置语法,将auto和decltype结合起来完成返回类型的推导。
template <typename T, typename U>
auto add(T t, U u) -> decltype(t + u)
{
return t + u;
}再举个例子:
int foo(int& i);
float foo(float& i);
template <typename T>
auto func(T& val) -> decltype(foo(val))
{
return foo(val);
}返回值类型后置语法,是为了解决函数返回值类型依赖于参数而导致难以确定返回值类型的问题。
1.2 模板的细节改进(using别名)
1.2.2 模板的别名
typedef重定义类型:
typedef unsigned int uint_t但它有一些限制,例如,定义一个模板很丑陋:
typedef std::map<std::string, int> map_int_t;
typedef std::map<std::string, std::string> map_str_t;
// 我们需要一个key为std::string的map模板,用typedef写法如下
template <typename Val>
struct str_map
{
typedef std::map<std::string, Val> type;
};
str_map<int>::type map1;代码很烦琐。使用C++11 using别名语法修改如下,简洁了很多。
template <typename Val>
using str_map_t = std::map<std::string, Val>;
str_map_t<int> map;使用场景:
1 定义普通类型别名
typedef unsigned int uint_t;
using uint_t = unsigned int;
typedef std::map<std::string int> map_int_t;
using map_int_t = std::map<std::string int>;2 定义语法别名
typedef void (*func_t)(int, int);
using func_t = void (*)(int, int);3 定义模板别名
template <typename T>
struct func_t
{
typedef void (*type)(T, T);
};
// 使用func_t模板
func_t<int>::type x1;
template <typename T>
using func_t = void (*type)(T, T);
// 使用func_t模板
func_t<int> x2;1.2.3 函数模板的默认模板参数
C++03类模板支持默认参数,函数模板不支持默认参数
template <typename T, typename U = int, U N = 0>
struct Foo
{
//...
};
// error
template <typename T = int>
void func(void)
{
//...
}C++11后函数模板也支持了默认参数。
注意,函数模板的默认填充顺序是从左向右的:
template <typename R = int, typename U>
R func(U val)
{
// val
}
int main()
{
func<long>(123);
return 0;
}函数模板的返回值类型为long,不是int。
1.3 列表初始化
为了统一C++03的初始化方式,C++11提出了列表初始化。
1.3.1 统一的初始化
对于普通数组和POD类型(plain old data类型,即可以直接使用memcpy复制的对象),C++03是可以使用初始化列表进行初始化的:
int arr[] = {1, 2, 3};
struct A
{
int x;
int y;
} a = {1, 2};C++11可以用于任何类型对象的初始化列表:
class Foo
{
public:
Foo(int) {}
private:
Foo(const Foo &);
};
int main()
{
// 直接初始化
Foo a1(123);
// 拷贝初始化
Foo a2 = 123; //error, private 拷贝构造函数
// 列表初始化
Foo a3 = { 123 };
Foo a4 { 123 };
int a5 = { 3 };
int a6 { 3 };
return 0;
}new操作符对象也可以使用初始化列表:
int* a = new int { 123 };
int* arr = new int[3] {1, 2, 3};
函数返回值也可以使用列表初始化:
struct Foo
{
Foo(int, double) {}
};
Foo func()
{
return {123, 321.0}
}如同返回了一个Foo(123, 321.0);
1.3.2 列表初始化的使用细节
对于一个自定义类型,初始化列表可能有两种执行结果:
struct A
{
int x;
int y;
} a = { 123, 321 };
// a.x = 123, a.y = 321
struct B
{
int x;
int y;
B(int, int) : x(0), y(0) {}
} b = { 123, 321 };
// b.x = 0, b.y = 0
a的初始化是聚合类型的列表初始化。
struct B由于自定义了一个构造函数,不再是聚合类型,b的初始化是以构造函数进行的。
聚合函数的定义如下:
(1)类型是一个普通数组(如int[10])
(2)类型是一个类(如class,struct,union),且
【1】无用户自定义的构造函数
【2】无私有或保护的非静态数据成员
【3】无基类
【4】无虚函数
那么,对于非聚合类型,要使用列表初始化时就需要自定义一个构造函数:
struct ST
{
int x;
double y;
virtual void F(){}
private:
int z;
public:
ST(int i, double j, int k) : x(i), y(j), z(k) {}
};
ST s { 1, 2.5, 2 };
1.3.3 初始化列表(std::initializer_list<>)
1. 任意长度的初始化列表
stl容器可以和没有设置长度的数组一样,列表初始化:
int arr[] = { 1, 2, 3 };
std::vector<int> arr = { 1, 2, 3, 4, 5 };
std::set<int> ss = { 1, 2, 3, 4, 5 };
std::map<std::string, int> mm =
{
{"1", 1},
{"2", 2},
{"3", 3}
};Foo不能任意长度的初始化,只能按照构造函数初始化。
class Foo
{
int x;
double y;
int z;
Foo(int ,int) {}
};只需要为Foo添加一个std::initializer_list构造函数,就可以任意长度初始化:
class Foo
{
public:
Foo(std::initializer_list<int>) {}
};
Foo foo = { 1, 2, 3 };自定义容器赋值:
class FooVector
{
std::vector<int> content_;
public:
FooVector<std::initializer_list<int> list>
{
for (auto it = list.begin(); it != list.end(); ++it)
{
content_.push_back(*it);
}
}
};
class FooMap
{
std::map<int, int> content_;
using pair_t = std::map<int, int>::value_type;
public:
FooMap(std::initializer_list<pair_t> list)
{
for (auto it = list.begin(); it != list.end(); it++)
{
content_.insert(*it);
}
}
};
FooVector foo_1 = { 1, 2, 3 };
FooMap foo_2 = { {1, 2}, {3, 4}, {5, 6} };这两个自定义容器的构造函数中,std::initialize_list负责接收初始化列表。并通过for循环,将每个元素取出,存入内部的存储空间中。
2. std::initialize_list的一些细节
对std::initialize_list的访问只能通过begin()和end()进行循环遍历,遍历时迭代器是只读的。因此,无法修改std::initializer_list中某一个元素的值,但可以通过初始化列表的复制对std::initializer_list做整体修改。
std::initialize_list<int> list;
size_t n = list.size(); // n = 0
list = { 1, 2, 3, 4, 5 };
n = list.size(); // n = 5
list = { 1, 2, 3, 4 };
n = list.size(); // n = 4
std::initializer_list是高效的,它不像vector之类的容器一样,把每个元素都复制了一遍。它的内部并不保存初始化列表中元素的拷贝,仅仅存储了列表中元素的引用而已。
所以,不应该如下使用:
std::initialize_list<int> func()
{
int a = 1 , b = 2;
return { a, b };
}
函数结束后,a和b的生存期结束,返回的将是不确定的值。
应该如下:
std::vector<int> func()
{
int a = 1, b = 2;
return { a, b };
}我们应当总是把std::initialize_list看做保存对象的引用,并在它持有对象的生存期结束之前完成传递。
1.3.4 防止类型收窄
类型收窄指的是数据内容发生变化或精度丢失的隐式类型转换。例如:
int a = 1.1;
C++03对于类型收窄的情况,编译器不会报错。C++11,编译时可通过列表初始化来检查及防止类型收窄。
int a = 1.1; // ok
int b = { 1.1 }; // error1.5 std::function和std::bind绑定器
1.5.1 可调用对象
可调用对象有如下定义:
(1)一个函数指针。
(2)一个具有opetator()成员函数的类对象(仿函数)。
(3)一个可被转换为函数指针的类对象。
(4)一个类成员指针。
void func(void)
{
// ...
}
struct Foo
{
void operator()(void)
{
// ...
}
};
struct Bar
{
using fr_t = void(*)(void);
static void func(void)
{
// ...
}
operator fr_t(void)
{
return func;
}
};
struct A
{
int a_;
void mem_func(void)
{
// ...
}
};
int main(void)
{
//1. 函数指针
void(* func_ptr)(void) = &func;
func_ptr();
//2. 仿函数
Foo foo;
foo();
//3. 可被转换为函数指针的类对象
Bar bar;
bar();
//4. 类成员函数指针和类成员指针
void (A::*mem_func_ptr)(void) = &A::mem_func;
int A::*mem_obj_ptr = &A::a_;
A aa;
(aa.*mem_func_ptr)();
aa.*mem_obj_ptr = 123;
return 0;
}C++11提供std::function和std::bind统一了可调用对象的各种操作。
1.5.2 可调用对象包装器----std::function
std::function是可调用对象的包装器。它是一个类模板,可以容纳除了类成员函数指针之外的所有可调用对象。
1 std::function的基本用法
#include <iostream>
#include <functional>
void func(void)
{
std::cout << __FUNCTION__ << std::endl;
}
class Foo
{
public:
static int foo_func(int a)
{
return a;
}
};
class Bar
{
public:
int operator()(int a)
{
return a;
}
};
int main()
{
// 1.绑定一个普通函数
std::function<void(void)> fr1 = func;
fr1();
// 2.绑定一个类的静态函数
std::function<int(int)> fr2 = Foo::foo_func;
fr2(123);
// 3.绑定一个仿函数
Bar bar;
fr3 = bar;
fr3(123);
return 0;
}基本用法:函数包装器。
2 std::function作为回调函数
#include <iostream>
#include <functional>
class A
{
std::function<void(void)> callback_;
public:
A(const std::function<void(void)>& f):callback_(f)
{}
void notify()
{
callback_();
}
};
class Foo
{
public:
void operator()(void)
{
std::cout << __FUNCTION__ << std::endl;
}
};
int main()
{
Foo foo;
A aa(foo);
aa.notify();
return 0;
}可以保存函数,延迟执行。适合作为回调函数。
3 std::function作为函数入参
#include <iostream>
#include <functional>
void call_when_even(int x, const std::function<void(int)>& f)
{
if (x % 2 == 0) {
f(x);
}
}
void output(int x)
{
std::cout<< x << "";
}
int main()
{
for (int i = 0;i < 10; ++i) {
call_when_even(i, output);
}
return 0;
}下一节可看到当std::function和std::bind配合使用时,所有可调用对象都具有统一的调用方式。(包括类成员函数指针和类成员指针)
1.5.3 std::bind绑定器
两大作用:
(1)将可调用对象和参数一起绑定成一个仿函数。
(2)绑定部分参数。
1 std::bind的基本用法
#include <iostream>
#include <functional>
void call_when_even(int x, const std::function<void(int)>& f)
{
if (x % 2 == 0) {
f(x);
}
}
void output(int x)
{
std::cout<< x << "";
}
int main()
{
auto fr = std::bind(output, std::placeholders::_1);
for(int i=0;i < 10; ++i) {
call_when_even(i, fr);
}
return 0;
}std::bind返回类型是一个仿函数,可以直接赋值给std::function。
std::placeholders::_1是一个占位符,表示在函数调用时,这个位置被传入的第一个参数替代。
2 std::bind的占位符
绑定部分参数
#include <iostream>
#include <functional>
void output(int x, int y)
{
std::cout << x << " " << y << std::endl;
}
int main()
{
// 输出:1,2
std::bind(output, 1 , 2)();
// 1,2
std::bind(output, std::placeholders::_1, 2)(1);
// 2,1
std::bind(output, 2, std::placeholders::_1)(1);
// error,没有第2个参数
std::bind(output, 2, std::placeholders::_2)(1);
// 2,2
std::bind(output, 2, std::placeholders::_2)(1, 2);
// 1,2
std::bind(output, std::placeholders::_1, std::placeholders::_2)(1, 2);
// 2,1
std::bind(output, std::placeholders::_2, std::placeholders::_1)(1, 2);
return 0;
}3 std::bind和std::function配合使用
#include <iostream>
#include <functional>
class A
{
public:
int i_ = 0;
void output(int x, int y)
{
std::cout << x << "" << y << std::endl;
}
};
int main()
{
A a;
std::function<void(int, int)> fr = std::bind(&A::output, &a, std::placeholders::_1, std::placeholders::_2);
fr(1,2);
std::function<int&(void)> fr_i = std::bind(&A::i_, &a);
fr_i() = 123;
std::cout << a.i_ << std::endl;
return 0;
}std::bind将A的成员函数output的指针和a绑定,并转换为一个仿函数存入fr中。
std::bind将A的成员i_的指针和a绑定,并转换为一个仿函数存入fr_i中。
1.6 lambda表达式
来源于函数式编程的概念,优点如下:
1 声明式编程风格,就地匿名定义目标函数或函数对象,不需要额外写一个命名函数或函数对象。
2 简洁。
1.6.1 lambda表达式的概念和基本用法
表达式语法:
[ capture ] ( params ) opt -> ret { body; };
capture是捕获列表;params是参数表;opt是函数选项;ret是返回值类型;body是函数体。
举例:
auto f = [](int a) -> int { return a+1; };
// 2
std::cout << f(1) << std::endl;C++11中允许省略lambda表达式的返回值定义,可自动推导:
auto x1 = [](int i){ return i; };注意,初始化列表不能用于返回值的推导:
// error
auto x2 = []() { return {1, 2}; };另外,lambda表达式在没有参数列表时,可以省略参数列表。
auto f1 = []() { return 1; };
auto f2 = [] { return 1; };捕获列表:
[] 不捕获任何变量
[&] 捕获外部作用域中所有变量,作为引用在函数体内使用
[=] 捕获外部作用域中所有变量,作为副本在函数体内使用
[=,&foo] 按值捕获外部作用域中所有变量,并按引用捕获foo变量
[bar] 按值捕获bar变量,不捕获其他变量
[this] 捕获类中的this指针,目的是可以在lambda中使用当前类的成员函数和变量,如果已经使用了&或=,则默认添加此选项
class A
{
public:
int i_ = 0;
void func(int x, int y)
{
// error,没有捕获i_
auto x1 = []{ return i_; };
// ok,捕获所有外部变量
auto x2 = [=]{ return i_ + x + y; };
// ok,捕获所有外部变量
auto x3 = [&]{ return i_ + x + y; };
// ok,捕获this指针
auto x4 = [this]{ return i_; };
// error,没有捕获x,y
auto x5 = [this]{ return i_ + x + y; };
// ok,捕获this,x,y
auto x6 = [this,x,y]{ return i_ + x + y; };
// ok,捕获this,并修改了i_成员的值
auto x7 = [this]{ return i_++; };
}
};容易出错的例子:
int a = 0;
auto f = [=]{ return a; };
a += 1;
// 输出:0
std::cout << f() << std::endl;捕获时,a的值已经复制到f中了,之后f中存储的a仍然是捕获时的值。如果希望lambda表达式在调用时能够即时访问外部变量,应当使用引用方式捕获。
如果希望修改按值捕获的外部变量,需要显式指明lambda表达式为mutable:
int a = 0;
//error, 修改按值捕获的外部变量
auto f1 = [=]{ return a++; };
//ok, mutable
auto f2 = [=]() mutable { return a++; }注意,被mutable修饰的lambda表达式就算没有参数也要写明参数列表。
lambda表达式类型在C++11中被称为"闭包类型",可以认为它是一个带有operator()的类,即仿函数。因此,我们可以用std::function和std::bind来操作lambda表达式:
std::function<int(int)> f1 = [](int a){ return a; };
std::function<int(void)> f2 = std::bind([](int a){ return a; }, 123);另外,对于没有捕获任何变量的lambda表达式,可以被转换为一个普通的函数指针:
using func_t = (int)(*)(int);
func_t f = [](int a){ return a };
f(123);解释下为何按值捕获无法修改捕获的外部变量。因为lambda表达式额operator()默认是const的,一个const成员函数是无法修改成员变量的值的。而mutable的作用是取消operator()的const。
1.6.2 声明式编程风格,简洁
简化了标准库算法的调用,例如在C++11之前,要调用for_each函数将vector中的偶数打印出来:
class CountEven
{
int& count_;
public:
CountEven(int& count_): count_(count)
{}
void operator()(int val)
{
if (val % 2 ==0)
{
++count_;
}
}
};
std::vector<int> v = { 1, 2, 3, 4, 5, 6 };
int even_count = 0;
for_each(v.begin(), v.end(), CountEven(even_count));
std::cout << even_count << std::endl;使用lambda后:
std::vector<int> v = { 1, 2, 3, 4, 5, 6 };
int even_count = 0;
for_each(v.begin(), v.end(), [&even_count](int val)
{
if (val % 2 ==0)
{
++even_count;
}
});
std::cout << even_count << std::endl;2 使用C++11改进程序性能
2.1 右值引用
C++11中引入右值引用和移动语义,可以避免无谓的复制,提高程序性能。
2.1 右值引用
C++11新增类型,右值引用,标记为T &&。左值是指表达式结束后依然存在的持久对象,右值是指表达式结束时就不再存在的临时对象。一个区分左值和右值的方法是能不能对表达式取地址,如果能,则为左值,如果不能,则为右值。所有具名变量都是左值。
C++11中右值有将亡值和纯右值。将亡值是与右值引用有关的表达式,如要被移动的对象,T&&函数返回值,std::move返回值和转换为T&&的类型的转换函数的返回值。纯右值包括非引用返回的临时变量,运算表达式产生的临时变量,原始字面量和lambda表达式等。
// i是左值,0是右值(字面量)
int i = 0;2.1.1 &&的特性
右值引用就是对一个右值进行引用的类型。因为右值不具名,所以只能通过引用的方式找到它。
无论声明左值引用还是右值引用,都必须立即进行初始化。通过右值引用的声明,其生命周期与右值引用变量的生命周期一样,只要该变量还活着,该右值临时量将会存活下去。
int g_constructCount = 0;
int g_copyConstructCount = 0;
int g_destructCount = 0;
struct A
{
A()
{
cout << "construct: " << ++g_constructCount << endl;
}
A(const A& a)
{
cout << "copy construct: " << ++g_copyConstructCount << endl;
}
~A()
{
cout << "destruct: " << ++g_destructCount << endl;
}
};
A GetA()
{
return A();
}
int main()
{
A a = GetA();
return 0;
}为了清楚观察结果,gcc编译时设置编译选项-fno-elide-constructors来关闭返回值优化。输出结果:
construct: 1
copy construct: 1
destruct: 1
copy construct: 2
destruct: 2
destruct: 3拷贝构造函数调用了两次,一次是GetA() return A(); 一次是main A a=;
通过右值引用来延长临时右值的声明周期:
int main() {
A&& a = GetA();
return 0;
}
输出结果:
construct: 1
copy construct: 1
destruct: 1
destruct: 2通过右值引用,比之前减少了一次拷贝构造和一次析构,原因是右值引用让临时右值的声明周期延长了。我们可以利用这个做性能优化,即避免临时对象的拷贝构造和析构。
事实上,C++03通过常量左值引用也可以做性能优化:
const A& a = GetA();常量的左值引用是一个"万能"的引用类型,可以接受左值,右值,常量左值和常量右值。
注意,普通左值引用不能接受右值:
// error
A& a = GetA();注意,T&&并不一定表示右值,它绑定的类型是未定的,既可能是左值又可能是右值。例子如下:
template<typename T>
void f(T&& param);
f(10); //10右值
int x = 10;
f(x); //x左值2.1.2 右值引用优化性能,避免深拷贝
对于含有堆内存的类,我们需要提供深拷贝的拷贝构造函数,如果使用默认构造函数,会导致堆内存的重复删除,运行错误。
class A
{
public:
A(): m_ptr(new int(0))
{
}
~A()
{
delete m_ptr;
}
private:
int *m_ptr;
};
A Get(bool flag)
{
A a;
A b;
if (flag)
return a;
else
return b;
}
int main()
{
// 运行报错
A a = Get(false);
}上面的代码,默认构造函数是浅拷贝,a和b会指向同一个指针m_ptr,析构的时候会导致重复删除,运行出错。正确的做法是提供深拷贝的构造函数:
class A
{
public:
A():m_ptr(new int(0))
{
cout << "construct" << endl;
}
// 深拷贝
A(const A& a):m_ptr(new int(*a.m_ptr))
{
cout << "copy construct" << endl;
}
~A()
{
cout << "destruct " << endl;
delete m_ptr;
}
private:
int* m_ptr;
};
A Get(bool flag)
{
A a;
A b;
if (flag)
return a;
else
return b;
}
int main()
{
A a = Get(false);
}
上面的代码输出:
construct //Get: A b
construct //Get: return b
copy construct //main: A a =
destruct
destruct
destruct上面代码中的Get函数会返回临时变量,然后通过临时变量拷贝构造了一个新的对象b,临时变量在拷贝构造完成之后就销毁了,如果堆内存很大,那么性能代价很大。如下代码可以避免临时对象的拷贝构造:
class A
{
public:
A():m_ptr(new int(0))
{
cout << "construct" << endl;
}
A(const A& a):m_ptr(new int(*a.m_ptr))
{
cout << "copy construct" << endl;
}
A(A&& a):m_ptr(a.m_ptr)
{
a.m_ptr = nullptr;
cout << "move construct" << endl;
}
~A()
{
cout << "destruct" << endl;
delete m_ptr;
}
private:
int* m_ptr;
};
A Get(bool flag)
{
A a;
A b;
if (flag)
return a;
else
return b;
}
int main()
{
A a = Get(false);
}
上面的代码将输出:
construct //Get: A b
construct //Get: return b
move construct //main: A a =
destruct
destruct
destruct
移动语义可以将资源通过浅拷贝的方式从一个对象转移到另一个对象,这样能够减少不必要临时对象的创建,拷贝和销毁。需要注意的是,我们一般在提供右值引用的构造函数的同时,也会提供常量左值引用的拷贝构造函数,以保证移动不成还可以使用拷贝构造。
2.2 move语义
std::move方法来讲左值转换为右值。move是将对象的状态或所有权从一个对象转移到另一个对象,只是转移,没有内存拷贝。
move语义的作用:对于一个对象中有一些指针资源,在对象的复制或拷贝时就不需要拷贝这些资源了。
C++11之前赋值函数:
A& A::operator=(const A& rhs)
{
// 销毁m_ptr指向的资源
// 复制rhs.m_ptr指向的资源,并使m_ptr指向它
}move语义:
A& A::operator=(const A&& rhs)
{
// 转移资源的控制权,无需复制
}
举一个例子,假设一个临时容器很大,赋值给另一个容器:
// 拷贝构造
std::list<std::string> tokens;
std::list<std::string> t = tokens;
// 移动构造
std::list<std::string> tokens;
std::list<std::string> t = std::move(tokens);应用move语义,避免了拷贝,提高了性能。事实上,前提条件是C++11中所有容器实现了move语义。如果是一些基本类型,如int,char[]数组,如果使用move,仍然会拷贝构造,因为没有对应的移动构造函数。
其他参考网址:
c++ 之 std::move 原理实现与用法总结_ppipp1109的博客-CSDN博客
2.3 forward
forward完美转发,是指在函数模板中,完全依照模板的参数类型(即保持参数的左值,右值特征),将参数传递给函数模板中的另一个函数。
void PrintT(int &t)
{
cout << "lvalue" << endl;
}
template<typename T>
void PrintT(int &t)
{
cout << "rvalue" << endl;
}
template<typename T>
void TestForward(T&& v)
{
PrintT(v);
PrintT(std::forward<T>(v));
PrintT(std::move(v));
}
Test()
{
TestForward(1);
int x = 2;
TestForward(x);
}
测试结果:
lvalue
rvalue
rvalue
lvalue
lvalue
rvalueTestForward(1):
1是右值,调用PrintT(v)时,v变为左值,---->lvalue。
1是右值,调用PrintT(std::forward(v))时,v保持原来类型,v为右值,---->rvalue。
1是右值,调用PrintT(std::move(v))时,v为右值,---->rvalue。
TestForward(x):
x是左值,调用PrintT(v)时,v为左值,---->lvalue。
x是左值,调用PrintT(std::forward(v))时,v保持原来类型,v为左值,---->lvalue。
x是左值,调用PrintT(std::move(v))时,v变为右值,---->rvalue。
2.4 emplace_back
emplace_back能直接通过参数构造对象,避免了内存的拷贝,相比push_back性能有提升。大多数情况下,应优先使用emplace_back代替push_back。
标准库容器(array除外,长度不可改变,不能插入元素)都增加了类似方法:emplace,emplace_hint,emplace_front,emplace_after和emplace_back等。
vector的emplace_back的基本用法:
#include <vector>
#include <iostream>
using namespace std;
struct A
{
int x;
double y;
A(int a, double b):x(a),y(b) {}
};
int main() {
vector<A> v;
v.emplace_back(1, 2);
cout << v.size() << endl;
return 0;
}需要有对应的构造函数,如果没有对应的构造函数,编译器会报错。
emplace_back和push_back的比较:
#include <vector>
#include <map>
#include <string>
#include <iostream>
using namespace std;
struct Complicated
{
int year;
double country;
std::string name;
// 对应的构造函数
Complicated(int a, double b, string c):year(a),country(b),name(c)
{
cout << "is constructed" << endl;
}
// "拷贝"构造函数
Complicated(const Complicated& other):year(other.year),country(other.country),name(std::move(other.name))
// std::move()将左值变为右值引用,应用move语义调用构造函数,避免了拷贝
{
cout << "is moved" << endl;
}
};
int main() {
std::map<int, Complicated> m;
int anInt = 4;
double aDouble = 5.0;
std::string aString = "C++";
cout << "insert:" << endl;
m.insert(std::make_pair(1, Complicated(anInt, aDouble, aString)));
cout << "emplace" << endl;
m.emplace(4, Complicated(anInt, aDouble, aString));
cout << "emplace_back:" << endl;
vector<Complicated> v;
v.emplace_back(anInt, aDouble, aString);
cout << "push_back:" << endl;
v.push_back(Complicated(anInt, aDouble, aString));
return 0;
}
输出:
insert:
is constructed
is moved
is moved
emplace:
is constructed
is moved
emplace_back:
is constructed
push_back:
is constructed
is moved
is moved
可以看出,emplace/emplace_back的性能比insert/push_back的性能提高很多。注意,不能完全用emplace_back代替push_back,前提是要有对应的构造函数。
2.5 unordered container
C++11新增无序容器unordered_map/unordered_multimap和unordered_set/unordered_multiset,因为无需排序,比有序容器map/multimap和set/multiset效率高。
map和set底层实现是红黑树,插入元素时会自动排序;unordered_map和unordered_set底层是哈希表,通过哈希来操作元素,效率更高。
因为无序容器底层实现是哈希表,所以对于自定义的key,需要提供Hash函数和比较函数;对于基本类型已实现,无需提供。
unordered_map的基本用法:
#include <unordered_map>
#include <vector>
#include <bitset>
#include <string>
#include <utility>
struct Key {
std::string first;
std::string second;
};
struct KeyHash {
std::size_t operator()(const Key& k) const
{
return std::hash<std::string>()(k.first) ^
(std::hash<std::string>()(k.second) << 1);
}
};
struct KeyEqual {
bool operator()(const Key& lhs, const Key& rhs) const
{
return lhs.first == rhs.first && lhs.second == rhs.second;
}
};
int main()
{
//default constructor: empty map
std::unordered_map<std::string, std::string> m1;
//list constructor
std::unordered_map<int, std::string> m2 =
{
{1, "foo"},
{3, "bar"},
{2, "baz"},
};
//copy constructor
std::unordered_map<int, std::string> m3 = m2;
//move constructor
std::unordered_map<int, std::string> m4 = std::move(m2);
//range constructor
std::vector<std::pair<std::bitset<8>, int>> v = { {0x12, 1}, {0x01, -1} };
std::unordered_map<std::bitset<8>, int> m5(v.begin(), v.end());
//constructor of a custom type
std::unordered_map<Key, std::string, KeyHash, KeyEqual> m6 =
{
{ {"John", "Doe"}, "example" },
{ {"Mary", "Sue"}, "another" }
};
return 0;
}4 使用C++11解决内存泄漏问题
智能指针是存储指向动态分配(堆内存)对象指针的类。
通用实现技术是使用引用计数。每使用它一次,引用计数加1,每析构一次,引用计数减1,减为0时,删除所指向的堆内存。
C++11提供三种智能指针,std::shared_ptr,std::unique_prt和std::weak_ptr。需引用头文件。
4.1 shared_ptr共享的智能指针
shared_ptr使用引用计数,每一个shared_ptr的拷贝都指向相同的内存。在最后一个shared_ptr析构时,内存被释放。
4.1.1 shared_ptr基本用法
1.初始化
[1]构造函数
std::shared_ptr<int> p(new int(10));[2]std::make_shared辅助函数
auto p = std::make_shared<int>(10);优先使用,更高效
[3]reset方法
std::shared_ptr p;
p.reset(new int(10));2.获取原始指针
auto p = std::make_shared<int>(10);
int *ptr = p.get();
// 智能指针不能打印,打印智能指针的原始指针地址
cout << "ptr:" << ptr << endl;3.指定删除器
智能指针初始化时可以指定删除器:
void DeleteIntPtr(int *p) {
delete p;
}
std::shared_ptr<int> p(new int, DeleteIntPtr);当p的引用计数为0时,会自动调用DeleteIntPtr删除器来释放对象的内存。
删除器可以写为lamda表达式:
std::shared_ptr<int> p(new int, [](int *p){ delete p; });注意:
shared_ptr管理动态数组时,需要指定删除器。因为shared_ptr的默认删除器不支持数组对象:
std::shared_ptr<int> p(new int[10], [](int *p){ delete[] p; }); //delete[]4.1.2 使用shared_ptr注意的问题
1.不要用一个原始指针初始化多个shared_ptr
int *p = new int;
shared_ptr<int> ptr1(p);
shared_ptr<int> ptr2(p);会导致重复析构
2.不要在函数实参中创建shared_ptr
f(shared_ptr<int>(new int), g())函数参数的执行顺序是由编译器决定的,上述参数的执行顺序可能是,
new int,g(),shared_ptr,此时如果g()发生异常shared_ptr没有执行,则出现内存泄漏。
解决方法:
shard_ptr<int> p(new int);
f(p, g());3.不要将this指针作为shared_ptr直接返回出来,应该使用shared_from_this()返回this指针
this指针是裸指针,直接返回出来可能导致重复析构:
class A {
shared_ptr<A> GetSelf() {
return shared_ptr<A>(this);
}
};
int main() {
shared_ptr<A> sp1(new A);
shared_ptr<A> sp2 = sp1->GetSelf();
return 0;
}离开作用域后,this将会被构造的两个智能指针各自析构,导致重复析构。
解决方法:
class A:public std::enable_shared_from_this<A> {
shared_ptr<A> GetSelf() {
return shared_from_this();
}
};
int main() {
shared_ptr<A> sp1(new A);
shared_ptr<A> sp2 = sp1->GetSelf();
return 0;
}使用shared_from_this()原因见4.3.2。
4.避免循环引用,循环引用会导致内存泄漏
典型场景:
class A;
class B;
class A {
std::shared_ptr<B> ptrb;
~A() {
cout << "A is deleted!" << endl;
}
}
class B {
std::shared_ptr<A> ptra;
~B() {
cout << "B is deleted!" << endl;
}
}
void TestPtr() {
std::shared_ptr<A> pa(new A);
std::shared_ptr<B> pb(new B);
pa->ptrb = pb;
pb->ptra = pa;
}测试结果是A和B都不会被析构,存在内存泄漏。循环引用导致pa和pb的引用计数为2,离开作用域后,pa和pb的引用计数减为1,不会被析构。
解决方法:
把A和B任何一个成员变量改为weak_ptr,见4.3.3。
4.2 unique_ptr独占的智能指针
unique_ptr不允许其他智能指针来共享其内部的指针,不允许赋值(复制)操作。
unique_ptr<T> p(new T);
unique_ptr<T> p1 = p; //错误,不能复制unique_ptr不允许复制,但允许转移,这样它本身就不再拥有原来指针的所有权了。
unique_ptr<T> p(new T);
unique_ptr<T> p1 = std::move(p); //正确C++14提供了make_unique来创建unique_ptr。
unique_ptr可以指向一个数组,shared_ptr不可以。
std::unique_ptr<int []> p(new int[10]); //正确
p[9] = 9;
std::shared_ptr<int []> p(new int[10]); //错误std::unique_ptr指定删除器的时候和std::shared_ptr不一样,需要确定删除器的类型。
std::shared_ptr<int> ptr(new int(1), [](int *p){ delete p;}); //正确
std::unique_ptr<int> ptr(new int(1), [](int *p){ delete p;}); //错误
std::unique_ptr<int, void(*)(int *)> ptr(new int(1), [](int *p){ delete p;}); //错误使用场景:
如果希望只有一个智能指针管理资源或数组则用unique_ptr,希望多个智能指针管理资源则用shared_ptr。
4.3 weak_ptr弱引用的智能指针
weak_ptr,它的构造不会增加引用计数,它的析构不会减少引用计数。它不共享指针,所以没有重载*和->操作符。
主要目的是通过shared_ptr获得资源的监视权,来监视shared_ptr中管理的资源是否存在。
4.3.1 weak_ptr基本用法
1.通过use_count()来获得当前观测资源的引用计数
shared_ptr<int> sp(new int(10));
weak_ptr<int> wp(sp);
cout << wp.use_count() << endl; //12.通过expired()来判断当前观测资源是否已经释放
shared_ptr<int> sp(new int(10));
weak_ptr<int> wp(sp);
if(wp.expired()) {
cout << "监测指针被释放,weak_ptr无效!"
} else {
cout << "监测指针未被释放,weak_ptr有效!"
}3.通过lock()来获取所监视的shared_ptr
shared_ptr<int> sp(new int(10));
weak_ptr<int> wp(sp);
auto spt = wp.lock();
cout << *spt << endl; //104.3.2 weak_ptr返回this指针
解释4.1.2第3点,3.不要将this指针作为shared_ptr直接返回出来,应该使用shared_from_this()返回this指针
class A:public std::enable_shared_from_this<A> {
shared_ptr<A> GetSelf() {
return shared_from_this();
}
};
int main() {
shared_ptr<A> sp1(new A);
shared_ptr<A> sp2 = sp1->GetSelf();
return 0;
}std::enable_shared_from_this类中有一个weak_ptr,调用shared_from_this()时会调用这个weak_ptr的lock(),返回监测的shared_ptr。
weak_ptr不会增加引用计数,所以不会出现重复析构的问题。
4.3.3 weak_ptr解决循环引用问题
解释4.1.2第4点,4.避免循环引用,循环引用会导致内存泄漏
解决方法:
class A;
class B;
class A {
std::shared_ptr<B> ptrb;
~A() {
cout << "A is deleted!" << endl;
}
}
class B {
std::weak_ptr<A> ptra; //改为weak_ptr
~B() {
cout << "B is deleted!" << endl;
}
}
void TestPtr() {
std::shared_ptr<A> pa(new A);
std::shared_ptr<B> pb(new B);
pa->ptrb = pb;
pb->ptra = pa;
}解释:
ptra时weak_ptr,引用计数不会增加,所以pa的引用计数为1.析构时pa的引用计数减少为0,对象A正常析构。
pa析构后,ptrb引用计数2减为1,离开作用域后,pb的引用计数1减为0,对象B正常析构。
4.4 通过智能指针管理第三方库分配的内存
void *p = GetHandle()->Create();
//do something...
GetHandle()->Release();优化为:
void *p = GetHandle()->Create();
std::shared_ptr<void> sp(p, [this](void *p){ GetHandle()->Release(p);});上述代码可以保证任何时候能正确释放第三方库分配的内存。
5 使用C++11让多线程开发变得简单
5.1 线程
std::thread创建线程很简单,只需提供线程函数或函数对象,同时指定线程函数的参数。
创建线程示例:
#include <thread>
void func()
{
}
int main()
{
std::thread t(func);
t.join();
return 0;
}join函数会阻塞主线程,直到子线程执行结束。
如果不希望主线程被阻塞,可用detach()方法,将主线程和子线程分离。
#include <thread>
void func()
{
}
int main()
{
std::thread t(func);
t.detach();
return 0;
}子线程和主线程分离,让子线程作为后台线程运行了,detach后子线程不再受主线程控制。
线程可以接受参数:
void func(int i, double d, const std::string& s)
{
std::cout << i << ", " << d << ", " << s << std::endl;
}
int main()
{
std::thread t(func, 1, 2, "test");
t.join();
return 0;
}
输出:
1, 2, test线程不能复制,但可以移动:
#include <thread>
void func()
{
}
int main()
{
std::thread t(func);
std::thread t1(std::move(t));
t.join();
t1.join();
return 0;
}还可以通过std::bind或lambda表达式来创建线程:
void func(int a, double b)
{
}
int main()
{
std::thread t1(std::bind(func, 1, 2));
std::thread t2([](int a, double b){}, 1,2);
t1.join();
t2.join();
return 0;
}需要注意线程对象的生命周期:
#include <thread>
void func()
{
}
int main()
{
std::thread t(func);
return 0;
}上面代码可能抛出异常,如果线程对象t先于线程函数析构了,则会异常。可通过join方式阻塞或detach方式后台运行来解决。
获取线程当前信息,如线程ID,CPU数量;和线程休眠:
void f()
{
std::this_thread::sleep_for(std::chrono::seconds(3));
cout << "time out" << endl;
}
int main()
{
std::thread t(f);
t.join();
cout << t.get_id() << endl;
cout << std::thread::hardware_concurrency() << endl;
return 0;
}5.2 互斥量
C++11提供如下4中语义的互斥量:
std::mutex:独占互斥量,不能递归使用。
std::timed_mutex:带超时的独占互斥量,不能递归使用。
std::recursive_mutex:递归互斥量。
std::recursive_timed_mutex:带超时的递归互斥量。
5.2.1 独占互斥量std::mutex
lock阻塞的;try_lock非阻塞的,尝试锁定互斥量,成功返回true,失败返回false。
std::mutex的基本用法:
#include <iostream>
#include <thread>
#include <mutex>
#include <chrono>
std::mutex g_lock;
void func()
{
g_lock.lock();
std::cout << "entered thread " << std::this_thread::get_id() << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(1));
std::cout << "leaving thread " << std::this_thread::get_id() << std::endl;
g_lock.unlock();
}
int main()
{
std::thread t1(func);
std::thread t2(func);
std::thread t3(func);
t1.join();
t2.join();
t3.join();
return 0;
}
输出:
entered thread 10144
leaving thread 10144
entered thread 4188
leaving thread 4188
entered thread 3424
leaving thread 3424
使用lock_guard可以简化lock/unlock写法,且更安全。构造时加锁,析构时解锁。修改后如下:
void func()
{
std::lock_guard<std::mutex> locker(g_lock);
std::cout << "entered thread " << std::this_thread::get_id() << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(1));
std::cout << "leaving thread " << std::this_thread::get_id() << std::endl;
}5.2.2 递归互斥量std::recursive_mutex
递归锁允许同一个线程多次获得互斥锁,可以用来解决同一个线程多次获取互斥锁时死锁的问题。
使用std::mutex发生死锁的示例:
struct Complex {
std::mutex mutex;
int i;
Complex(): i(0) {}
void mul(int x) {
std::lock_guard<std::mutex> lock(mutex);
i *= x;
}
void div(int x) {
std::lock_guard<std::mutex> lock(mutex);
i /= x;
}
void both(int x, int y) {
std::lock_guard<std::mutex> lock(mutex);
mul(x);
div(y);
}
};
int main()
{
Complex complex;
complex.both(2 , 3);
return 0;
}both先获取锁,没有释放,mul又获取锁时死锁。解决,一个办法是是使用递归锁。
struct Complex {
std::recursive_mutex mutex;
int i;
Complex(): i(0) {}
void mul(int x) {
std::lock_guard<std::recursive_mutex> lock(mutex);
i *= x;
}
void div(int x) {
std::lock_guard<std::recursive_mutex> lock(mutex);
i /= x;
}
void both(int x, int y) {
std::lock_guard<std::recursive_mutex> lock(mutex);
mul(x);
div(y);
}
};
int main()
{
Complex complex;
complex.both(2 , 3);
return 0;
}注意,尽量不要使用递归锁,主要如下原因:
(1)需要递归锁的往往本身可以简化
(2)递归锁比独占锁效率低
(3)递归锁重复获得锁的次数未具体说明,一旦超过一定次数,再lock会抛出std::system错误
5.2.3 带超时的互斥量std::timed_mutex和std::recursive_timed_mutex
std::timed_mutex比std::mutex多了两个超时获取锁的接口:try_lock_for和try_lock_until,这两个接口用来设置获取互斥量的超时时间。
std::timed_mutex的基本用法:
std::timed_mutex mutex;
void work() {
std::chrono::milliseconds timeout(100);
while(ture) {
if (mutex.try_lock_or(timeout)) {
std::cout << std::this_thread::get_id() << ": do work with the mutex" << std::endl;
std::this_thread::sleep_for(std::chrono::milliseconds(250));
mutex.unlock();
} else {
std::cout << std::this_thread::get_id() << ": do work without the mutex" << std::endl;
std::this_thread::sleep_for(std::chrono::milliseconds(100));
}
}
}
int main() {
std::thread t1(work);
std::thread t2(work);
t1.join();
t2.join();
return 0;
}5.3 条件变量
条件变量能阻塞线程(wait),直到收到另一个线程发出的通知或超时,才会唤醒当前阻塞的线程。
C++11提供了两种条件变量:
(1)condition_variable,wait函数需要与std::unique_lock<std::mutex>配合使用
(2)conditon_vatiable_any,可和任意mutex配合使用,更灵活,但效率较低
条件变量的使用过程:
(1)拥有条件变量的线程获取互斥量
(2)循环检查某个条件,如果条件不满足,则阻塞直到条件满足;如果条件满足,则向下执行。
(3)某线程满足条件后,调用notify_one或notify_all唤醒一个或所有的等待线程。
可用条件变量来实现一个同步队列,同步队列作为一个线程安全的数据共享区,用于线程之间读取数据。
有限长度同步队列的实现(condition_variable_any):
#include <mutex>
#include <thread>
#include <condition_variable>
template<typename T>
class SyncQueue
{
bool IsFull() const
{
return m_queue.size() == m_maxSize;
}
bool IsEmpty() const
{
return m_queue.empty();
}
public:
SyncQueue(int maxSize):m_maxSize(maxSize)
{
}
void Put(const T& x)
{
std::lock_guard<std::mutex> locker(m_mutex);
while (IsFull())
{
cout << "缓冲区满了,需要等待..." << endl;
m_notFull.wait(m_mutex);
}
m_queue.push_back(x);
m_notEmpty.notifyone();
}
void Take(T& x)
{
std::lock_guard<std::mutex> locker(m_mutex);
while (IsEmpty())
{
cout << "缓冲区空了,需要等待..." << endl;
m_notEmpty.wait(m_mutex);
}
x = m_queue.front();
m_queue.pop_front();
m_notFull.notify_one();
}
// below three func,just for public func
bool Empty()
{
std::lock_guard<std::mutex> locker(m_mutex);
return m_queue.empty();
}
bool Full()
{
std::lock_guard<std::mutex> locker(m_mutex);
return m_queue.size() == m_maxSize;
}
size_t Size()
{
std::lock_guard<std::mutex> locker(m_mutex);
return m_queue.size();
}
private:
std::list<T> m_queue;
std::mutex m_mutex;
// 队列不为空的条件变量
std::condition_variable_any m_notEmpty;
// 队列没有满的条件变量
std::condition_variable_any m_notFull;
// 同步队列最大长度
int m_maxSize;
};这个同步队列在没有满的时候可以插入数据,如果队列满了,生产线程会在m_notFull.wait阻塞等待(wait中释放锁),等消费线程取出数据后发送notify_one通知,则生产线程被唤醒继续执行;如果队列空了,消费线程会在m_notEmpty.wati阻塞等待(wait中释放锁),等生产线程插入数据后发送notify_one通知,则消费线程被唤醒继续执行。
条件变量的wait函数还有一个重载方法,可以接受一个条件:
std::lock_guard<std::mutex> locker(m_mutex);
while (IsFull())
{
m_notFull.wait(m_mutex);
}
可以改写为:
std::lock_guard<std::mutex> locker(m_mutex);
m_notFull.wait(locker, [this]{return !IsFull();});解释下Take中锁的状态:
首先lock_guard初始化时获取锁。如果队列满了,生产线程的m_notFull.wait会释放锁,然后阻塞。等消费线程发送了notify_one通知后,生产线程被唤醒后会重新获取锁,继续执行。直到Take函数执行完成,locker生命周期结束,再次释放锁。
std::unique_lock和std::lock_guard的差别在于前者可以自由地释放mutex,后者需要等到std::lock_guard变量生命周期结束时才能释放。
无限长度的同步队列(condition_variable,unique_lock):
#include <thread>
#include <condition_variable>
#include <mutex>
#include <list>
#include <iostream>
using namespace std;
template<typename T>
class SimpleSyncQueue
{
public:
SimpleSyncQueue()
{
}
void Put(const T& x)
{
std::lock_guard<std::mutex> locker(m_mutex);
m_queue.push_back(x);
m_notEmpty.notify_one();
}
void Take(T& x)
{
std::unique_lock<std::mutex> locker(m_mutex);
// 如果条件不满足(return false),即队列为空,继续等待wait
m_notEmpty.wait(locker, [this]{return !m_queue.empty();});
x = m_queue.front();
m_queue.pop_front();
}
// below 2 funcs just public funcs
bool Empty()
{
std::lock_guard<std::mutex> locker(m_mutex);
return m_queue.empty();
}
size_t Size()
{
std::lock_guard<std::mutex> locker(m_mutex);
return m_queue.size();
}
private:
std::list<T> m_queue;
std::mutex m_mutex;
// 队列不空的条件变量
std::condition_variable m_notEmpty;
};5.5 call_once/once_flag的使用
std::call_once用来保证函数在多线程环境中只被调用一次。
使用std::call_once时,需要一个once_flag作为call_once的入参。
#include <iostream>
#include <thread>
#include <mutex>
std::once_flag flag;
void do_once()
{
std::call_once(flag, [](){ std::cout << "Called once" << std::endl; });
}
int main()
{
std::thread t1(do_once);
std::thread t2(do_once);
std::thread t3(do_once);
t1.join();
t2.join();
t3.join();
return 0;
}5.6 异步操作类 std::future,std::promise,std::package_task
std:future作为异步结果的传输通道,用来获取线程函数的返回值;
std::promise用来包装一个值,将数据和future绑定起来;
std::package_task用来包装一个可调用对象,将函数和future绑定起来。
5.6.1 std::future
thread库提供了future用来访问异步操作的结果。因为一个异步操作的结果不能马上获取,只能在未来某个时刻从某个地方获取,这个异步操作的结果是一个未来的期待值,所以被称为future。
我们可以以同步等待的方式来获取结果,可以通过查询future的状态(future_status)来获取异步操作的结果。有3种future_status:
(1)Deferred,异步操作还没开始
(2)Ready,异步操作已经完成
(3)Timeout,异步操作超时
以下示例不断查询future的状态,直到任务完成为止:
std::future_status status;
do {
status = future.wait_for(std::chrono::seconds(1));
if (status == std::future_status::deferred) {
std::cout << "deferred\n";
} else if (status == std::future_status::timeout) {
std::cout << "timeout\n";
} else if(status == std::future_status::ready) {
std::cout << "ready\n";
}
} while (status != std::future_status::ready);future.get:等待异步操作结束并返回结果
future.wait:只等待异步操作完成
future.wait_for:超时等待返回结果
5.6.2 std::promise
std::promise内部将数据和std::future绑定起来,在线程函数中为外面传进的promise赋值,在线程函数执行完成后就可以通过promise的future获取值了。
std::promise的基本用法:
std::promise<int> pr;
// std::ref用于包装按引用传递的值
std::thread t([](std::promise<int>& p) { p.set_value_at_thread_exit(9); }, std::ref(pr));
std::future<int> f = pr.get_future();
// 9
auto r = f.get();5.6.3 std::package_task
std::package_task内部将函数和std::future绑定起来,以便异步调用。
std::package_task的基本用法:
std::packaged_task<int()> task([](){ return 7; });
std::future<int> f1 = task.get_future();
std::thread t1(std::ref(task));
// 7
auto r1 = f1.get();5.6.4 总结
std::future属于低层次的通道。在std::future之上的高一层是std::packaged_task和std::promise,std::packaged_task包装的是一个异步操作,std::promise包装的是一个值。需要获取线程中的某个值用std::promise,需要获取一个异步操作的返回值,用std::packaged_task。
5.7 线程异步操作函数 std::async
std::async比std::promise,std::packaged_task更高一层,它可以创建异步的task,异步任务返回的结果也保存在future中。当获取异步任务的结果时,调用future.get();不关注异步任务的结果,只等待任务完成的话,调用future.wait()。
async的声明:
async(std::launch::async | std::launch::deferred, f, args...)
(1)第一个参数:线程的创建策略
std::launch::async:调用async时就开始创建线程。
std::launch::deferred:延迟加载方式创建线程。
(2)第二个参数:线程函数
(3)第三个参数:线程函数的参数
async的基本用法:
std::future<int> f1 = std::async(std::launch::async, [](){
return 8;
});
cout << f1.get() << endl;
输出:
8std::future<int> f2 = std::async(std::launch::async, [](){
cout << 8 << endl;
});
f2.wait();
输出:
8std::future<int> future = std::async(std::launch::async, [](){
std::this_thread::sleep(std::chrono::seconds(3));
return 8;
});
cout << "waiting..." << endl;
std::future_status status;
do {
status = future.wait_for(std::chrono::seconds(1));
if (status == std::future_status::deferred) {
cout << "deferred" << endl;
} else if (status == std::future_status::timeout) {
cout << "timeout" << endl;
} else if (status == std::future_status::ready) {
cout << "ready" << endl;
}
} while (status != std::future_status::ready);
cout << "result is " << futute.get() << endl;
可能输出:
waiting...
timeout
timeout
ready
result is 8
8 使用C++11改进我们的模式
8.1 改进单例模式
定义:保证一个类仅有一个实例,并提供一个访问它的全局访问点。
类图:

C++11前,实现一个通用的泛型单例模式,支持0~3个参数的单例如下:
template <typename T>
class Singleton
{
public:
// 支持0个参数的构造函数
static T* Instance()
{
if (m_pInstance == null)
m_pInstance = new T();
return m_pInstance;
}
// 支持1个参数的构造函数
template<typename T0>
static T* Instance(T0 arg0)
{
if (m_pInstance == null)
m_pInstance = new T(arg0);
return m_pInstance;
}
// 支持2个参数的构造函数
template<typename T0,typename T1>
static T* Instance(T0 arg0, T1 arg1)
{
if (m_pInstance == null)
m_pInstance = new T(arg0, arg1);
return m_pInstance;
}
// 支持3个参数的构造函数
template<typename T0,typename T1,typename T2>
static T* Instance(T0 arg0, T1 arg1, T2 arg2)
{
if (m_pInstance == null)
m_pInstance = new T(arg0, arg1, arg2);
return m_pInstance;
}
// 获取单例
static T* GetInstance()
{
if (m_pInstance == null)
throw std::logic_error("the instance is not init");
return m_pInstance;
}
// 释放单例
static void DestroyInstance()
{
delete m_pInstance;
m_pInstance = nullptr;
}
private:
Singleton();
virtual ~Singleton();
Singleton(const Singleton&);
Singleton& operator = (const Singletion&);
static T* m_pInstance;
};
template <class T> T* Singleton<T>::m_pInstance = nullptr;
测试代码如下:
struct A
{
A() {}
};
struct B
{
B(int x) {}
};
struct C
{
C(int x, double y) {}
};
int main()
{
Singleton<A>::Instance();
Singleton<B>::Instance(1);
Singleton<C>::Instance(1, 2);
Singleton<A>::DestroyInstance();
Singleton<B>::DestroyInstance();
Singleton<C>::DestroyInstance();
}这个单例中的函数有很多重复定义,且当函数参数超过3个时,不得不再增加构造函数定义。
利用C++11的可变参数,可以消除这种重复,同时支持完美转发。既增加了灵活性又提高了性能。
C++11可变参数模板的单例:
template <typename T>
class Singleton
{
public:
template<typename... Args>
static T* instance(Args... args)
{
if (m_pInstance == nullptr)
{
// 完美转发
m_pInstance = new T(std::forward<Args>(args)...);
}
return m_pInstance;
}
// 获取单例
static T* GetInstance()
{
if (m_pInstance == nullptr)
{
throw std::logic_error("the instance is not init");
}
return m_pInstance;
}
// 销毁单例
static void DestroyInstance()
{
delete m_pInstance;
m_pInstance = nullptr;
}
private:
Singleton();
virtual ~Singleton();
Singleton(const Singleton&);
Singleton& operator = (const Singleton&);
static T* m_pInstance;
};
template <class T> T* Singleton<T>::m_pInstance = nullptr;
测试代码:
#include <iostream>
#include <string>
using namespace std;
struct A
{
A(const string&) { cout << "lvalue" << endl; };
A(string&& x) { cout << "rvalue" << endl; };
};
struct B
{
B(const string&) { cout << "lvalue" << endl; };
B(string&& x) { cout << "rvalue" << endl; };
};
struct C
{
C(int x, int y) {}
void Fun() { cout << "test" << endl; }
};
int main()
{
string str = "xxx";
Singleton<A>::Instance(str);
Singleton<B>::Instance(std::move(str));
Singleton<C>::Instance(1, 2);
Singleton<C>::GetInstance->Fun();
Singleton<A>::DestroyInstance();
Singleton<B>::DestroyInstance();
Singleton<C>::DestroyInstance();
return 0;
}
输出结果:
lvalue
rvalue
test
8.2 改进观察者模式
观察者(Observer)模式的定义:指多个对象间存在一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。这种模式有时又称作发布-订阅模式,它是对象行为型模式。
观察者模式是一种对象行为型模式,其主要优点如下。
1 降低了目标与观察者之间的耦合关系,两者之间是抽象耦合关系。符合依赖倒置原则。
2 目标与观察者之间建立了一套触发机制。
它的主要缺点如下。
1 目标与观察者之间的依赖关系并没有完全解除。
2 当观察者对象很多时,通知的发布会花费很多时间,影响程序的效率。
类图如下:

一个简单的观察者模式如下:
class Subject;
// 观察者接口类
class Observer
{
public:
virtual ~Observer();
// 即类图中Response函数
virtual void Update(Subject* theChangedSubject) = 0;
protected:
// 只有子类内部的其他函数可以调用protected函数
Observer();
};
// 目标接口类
class Subject {
public:
virtual ~Subject();
virtual void Attach(Observer*);
virtual void Detach(Observer*);
virtual void Notify();
protected:
Subject();
private:
// 观察者列表
List<Observer*> _observers;
};
// 增加观察者
void Subject::Attach(Observer* o) {
_observers->append(o);
}
// 删除观察者
void Subject::Detach(Observer* o) {
_observers->remove(o);
}
// 目标类发出通知,通知所有观察者
void Subject::Notify() {
ListIterator<Observer*> i(_observers);
for(i.first();!i.isDone();i.next()) {
i.currentItem()->Update(this);
}
}
这种实现方式主要两个限定:
(1)需要继承,继承是强对象关系,不够灵活
(2)观察者被通知的接口参数不支持变化(Observer的Update接口)
C++11改进有两点:
(1)通过std::fucntion来代替继承
(2)通过可变参数模板使得被通知接口参数化
C++11提供了default和delete,使我们可以方便地实现一个NonCopyable类。如果希望类不被复制,则直接从这个NonCopyable类派生。
NonCopyable类的实现:
class NonCopyable
{
protected:
// 将函数声明为显示构造函数
NonCopyable() = default;
~NonCopyable() = default;
// 禁止复制构造
NonCopyable(const NonCopyable&) = delete;
// 禁止赋值
NonCopyable& operator = (const NonCopyable&) = delete;
};C++11改进后的观察者模式:
#include <iostream>
#include <string>
#include <functional>
#include <map>
using namespace std;
template<typename Func>
class Events : NonCopyable
{
public:
Events();
~Events();
// 注册观察者,支持右值引用
int Connect(Func&& f)
{
return Assign(f);
}
// 注册观察者
int Connect(const Func& f)
{
return Assign(f);
}
// 移除观察者
int DisConnect(int key)
{
m_connections.erase(key);
}
// 通知所有观察者
template<typename... Args>
void Notify(Args&&... args)
{
for (auto& it:m_connections)
{
it.second(std::forward<Args>(args)...);
}
}
private:
template<typename F>
int Assign(F&& f)
{
int k = m_observerId++;
m_connections.emplace(k, std::forward(F)(f));
return k;
}
// 观察者编号
int m_observerId = 0;
// 观察者列表
std::map<int, Func> m_connections;
};测试代码如下:
struct stA
{
int a, b;
void print(int a,int b)
{
cout << "a," << a << " b," << b << endl;
}
};
void print(int a, int b)
{
cout << "a:" << a << " b:" << b << endl;
}
int main(){
Events<std::function<void(int,int)>> myevent;
// 以函数方式注册观察者
auto key = myevent.Connect(print);
// lambda注册观察者
stA t;
auto lambdakey = myevent.Connect([&t](int a, int b){t.a = a; t.b = b;});
// std::function注册观察者
std::function<void(int,int)> f = std::bind(&stA::print, &t,
std::placeholders::_1, std::placeholders::_2);
auto funckey = myevent.Connect(f);
int a=1,b=2;
// 广播所有观察者
myevent.Notify(a,b);
// 移除观察者
myevent.Disconnect(key);
myevent.Disconnect(lambdakey);
myevent.Disconnect(funckey);
return 0;
}C++11改进后的观察者模式,内部维护了一个泛型函数map(m_connections),观察者只需将观察者函数注册进来,消除了继承导致的强耦合;也不要求观察者必须从某个类派生,当需要不同的观察者时,只需定义一个新的event即可。同时,通知接口使用了可变参数列表(Notify),支持任意参数。
参考网址:
http://c.biancheng.net/view/1390.html
8.3 改进访问者模式
访问者(Visitor)模式的定义:将作用于某种数据结构中的各元素的操作分离出来封装成独立的类,使其在不改变数据结构的前提下可以添加作用于这些元素的新的操作。它将对数据的操作与数据结构进行分离,是行为类模式中最复杂的一种模式。
访问者(Visitor)模式是一种对象行为型模式,其主要优点如下。
1 扩展性好。能够在不修改对象结构中的元素的情况下,为对象结构中的元素添加新的功能。
2 复用性好。可以通过访问者来定义整个对象结构通用的功能,从而提高系统的复用程度。
3 灵活性好。访问者模式将数据结构与作用于结构上的操作解耦,使得操作集合可相对自由地演化而不影响系统的数据结构。
4 符合单一职责原则。访问者模式把相关的行为封装在一起,构成一个访问者,使每一个访问者的功能都比较单一。
访问者(Visitor)模式的主要缺点如下。
1 增加新的元素类很困难。在访问者模式中,每增加一个新的元素类,都要在每一个具体访问者类中增加相应的具体操作,这违背了“开闭原则”。
2 破坏封装。访问者模式中具体元素对访问者公布细节,这破坏了对象的封装性。
3 违反了依赖倒置原则。访问者模式依赖了具体类,而没有依赖抽象类。
类图如下:

先看下访问者模式的实现:
#include <iostream>
#include <memory>
using namespace std;
struct ConcreteElement1;
struct ConcreteElement2;
// 访问者基类
struct Visitor
{
virtual ~Visitor();
// 被访问者1
virtual void Visit(ConcreteElement1* element) = 0;
// 被访问者2
virtual void Visit(ConcreteElement2* element) = 0;
};
// 被访问者基类
struct Element
{
virtual ~Element();
virtual void Accept(Visitor& visitor) = 0;
};
// 具体的访问者
struct ConcreteVisitor : public Visitor
{
void Visit(ConcreteElement1* element)
{
cout << "Visit ConcreteElement1" << endl;
}
void Visit(ConcreteElement2* element)
{
cout << "Visit ConcreteElement2" << endl;
}
};
// 具体的被访问者1
struct ConcreteElement1 : public Element
{
void Accept(Visitor& visitor)
{
visitor.Visit(this);
}
// 定义新的操作
void OperationA()
{
cout << "OperationA ConcreteElement1" << endl;
}
};
// 具体的被访问者2
struct ConcreteElement2 : public Element
{
void Accept(Visitor& visitor)
{
visitor.Visit(this);
}
// 定义新的操作
void OperationB()
{
cout << "OperationB ConcreteElement2" << endl;
}
};
void TestVisitor()
{
ConcreteVisitor v;
std::unique_ptr<Element> emt1(new ConcreteElement1);
std::unique_ptr<Element> emt2(new ConcreteElement2);
emt1->Accept(v);
emt2->Accept(v);
}
int main()
{
TestVisitor();
return 0;
}
输出结果:
Visit ConcreteElement1
OperationA ConcreteElement1
Visit ConcreteElement2
OperationB ConcreteElement2理解下访问者模式:
访问者模式适用于Element继承体系很少改变,但经常需要在此结构上定义新的操作(OperationA,OperationB)。也就是说,在访问者模式中被访问者应该是一个稳定的继承体系,如果这个继承体系经常变化,就会导致经常修改Visitor基类。
因为Visitor基类中定义了需要访问的对象类型,所以每增加一种访问类型就要增加一个对应的纯虚函数。例如,上例中如果需要增加一个被访问者ConcreteElement3,则需要在Visitor基类中增加一个纯虚函数:
// 被访问者3
virtual void Visit(ConcreteElement3* element) = 0;面向接口的编程原则:我们应该依赖于接口而不应该依赖于实现,因为接口是稳定的,不会变化。
如此看来,如果访问者模式中的被访问者继承体系不够稳定,需要修改Visitor基类接口,那会导致整个系统的不稳定。如何做到增加新的被访问者而不修改Visitor接口呢?我们可以通过C++11的可变参数模板来实现一个稳定的Visitor接口层。
C++11改进后的visitor模式:
#include <iostream>
// 声明一个带可变参数列表的Visitor类
template<typename... Types>
struct Visitor;
template<typename T, typename... Types>
struct Visitor<T, Types...> : Visitor<Types...>
{
// 通过using避免隐藏基类的Visit同名方法
using Visitor<Types...>::Visit;
virtual void Visit(const T&) = 0;
};
// 定义一个带可变参数列表的Visitor类
template<typename... Types>
struct Visitor<T>
{
virtual void Visit(const T&) = 0;
};
// 以下使用Visitor访问“被访问的继承体系”
struct stA;
struct stB;
// 被访问者基类
struct Base
{
// 定义通用的访问者类型,它可以访问stA和stB
typedef Visitor<stA, stB> MyVisitor;
virtual void Accept(MyVisitor&) = 0;
};
// 具体的被访问者1
struct stA : Base
{
double val;
void Accept(Base::MyVisitor& v)
{
v.Visit(*this);
}
}
// 具体的被访问者2
struct stB : Base
{
double val;
void Accept(Base::MyVisitor& v)
{
v.Visit(*this);
}
}
// 具体的访问者
struct ConcreteVisitor: Base::MyVisitor
{
void Visit(const stA& a)
{
cout << "from stA: " << a.val << endl;
}
void Visit(const stB& b)
{
cout << "from stB: " << b.val << endl;
}
};
测试代码如下:
void TestVisitor()
{
ConcreteVisitor visitor;
stA a;
a.val = 1;
stB b;
b.val = 2;
Base base = &a;
a->Accept(visitor);
base = &b;
b->Accept(visitor);
}
测试结果如下:
from stA: 1
from stA: 2
上例中:
typedef Visitor<stA, stB> MyVisitor;会自动生成stA和stB的Visit虚函数。
struct Visitor<stA, stB>
{
virtual void Visit(const stA&) = 0;
virtual void Visit(const stB&) = 0;
};如果需要新增被访问者类型,只需添加一个类型就可以了。
typedef Visitor<stA, stB, stC> MyVisitor;相比较原来的访问者模式,C++11改进后的访问者模式不会因为被访问者继承体系的变化而修改接口层,更加稳定。改进后的访问者模式把Visitor接口层的变化转移到被访问者基类对象(Base)中了。
参考网址:
http://c.biancheng.net/view/1397.html
9 使用C++11开发一个半同步半异步线程池
9.1 半同步半异步线程池介绍
传统的一个请求一个线程处理,在处理大量并发任务时,会导致大量的线程创建和销毁,消耗过多的系统资源。线程池可以解决这个问题。
本章介绍的是半同步半异步线程池,线程池结构图如图9-1:
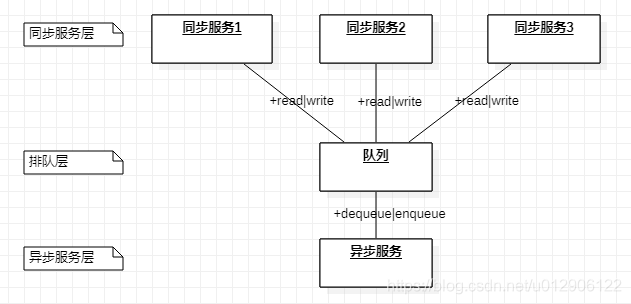
图9-1 半同步半异步线程池
第一层是同步服务层,它处理来自上层的任务请求。上层的请求可能是并发的,这些请求不是马上被处理,而是将这些请求放到一个同步队列里。
第二层是排队层,即同步队列。
第三层是异步服务层,多个线程从同步队列里取出任务并处理。
9.2 线程池实现的关键技术分析
线程池有两个活动过程,一个是向同步队列里添加任务的过程,另一个是从同步队列里取任务的过程,活动图如图9-2:
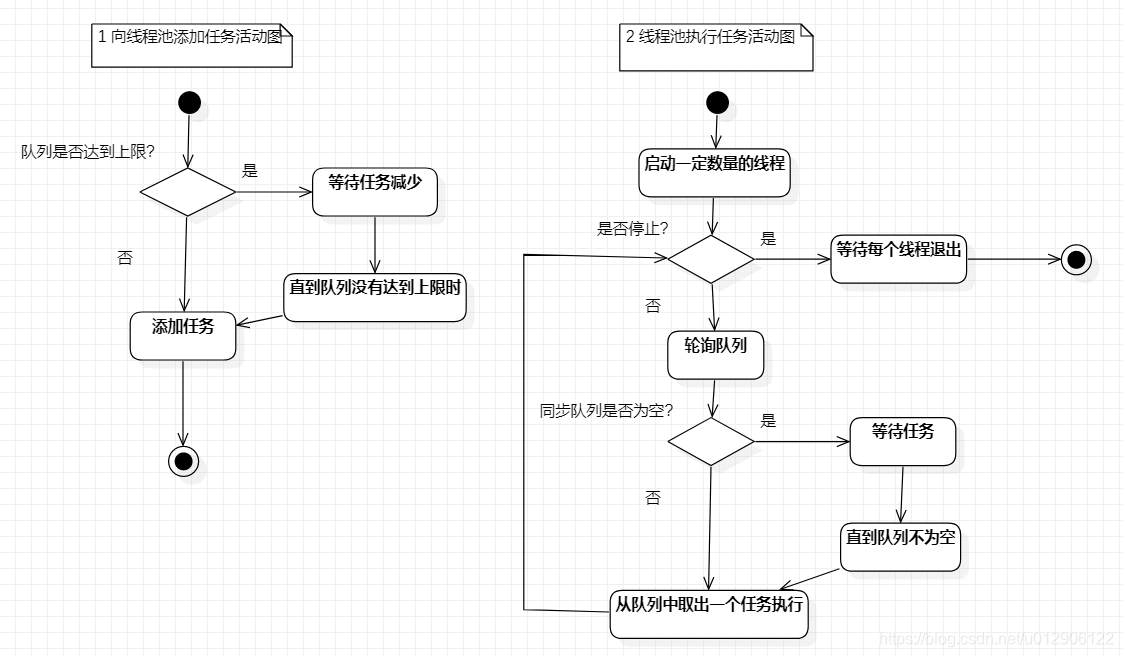 图9-2 半同步半异步线程池活动图
图9-2 半同步半异步线程池活动图
注意,同步队列会限制任务数的上限,避免任务过多导致内存暴涨。
9.3 同步队列
同步队列的实现代码:
#include <list>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <iostream>
using namespace std;
template<typename T>
class SyncQueue
{
public:
SyncQueue(int maxSize) : m_maxSize(maxSize), m_needStop(false)
{
}
void Put(const T& x)
{
Add(x);
}
void Put(T&& x)
{
Add(std::forward<T>(x));
}
void Take(std::list<T>& list)
{
std::unique_lock<std::mutex> locker(m_mutex);
// return条件都不满足,则wait
m_notEmpty.wait(locker, [this]{return m_needStop || NotEmpty();});
if(m_needStop) return;
// std::move后,m_queue为空!
list = std::move(m_queue);
m_notFull.notify_one();
}
void Take(T& t)
{
std::unique_lock<std::mutex> locker(m_mutex);
m_notEmpty.wait(locker, [this]{return m_needStop || NotEmpty();});
if(m_needStop) return;
t = m_queue.front();
m_queue.pop_front();
m_notFull.notify_one();
}
void Stop()
{
{
std::lock_guard<std::mutex> locker(m_mutex);
m_needStop = true;
}
m_notFull.notify_all();
m_notEmpty.notify_all();
}
bool Empty()
{
std::lock_guard<std::mutex> locker(m_mutex);
return m_queue.empty();
}
bool Full()
{
std::lock_guard<std::mutex> locker(m_mutex);
return m_queue.size() == m_maxSize;
}
size_t Size()
{
std::lock_guard<std::mutex> locker(m_mutex);
return m_queue.size();
}
private:
bool NotFull() const
{
bool full = m_queue.size() >= m_maxSize;
if(full) cout << "缓冲区满了,需要等待..." << endl;
return !full;
}
bool NotEmpty() const
{
bool empty = m_queue.empty();
if(empty) cout << "缓冲区空了,需要等待..." << endl;
return !empty;
}
template<typename F>
void Add(F&& x)
{
std::unique_lock<std::mutex> locker(m_mutex);
m_notFull.wait(locker, [this]{return m_needStop || NotFull();});
if(m_needStop) return;
m_queue.push_back(std::forward<F>x);
m_notEmpty.notify_one();
}
private:
std::list<T> m_queue; //缓冲区
std::mutex m_mutex;
std::condition_variable m_notEmpty; //缓冲区不为空的条件变量
std::condition_variable m_notFull; //缓冲区不满的条件变量
int m_maxSize;
bool m_needStop;
};Take函数
void Take(std::list<T>& list)每个数据加锁效率较低,这里改进,一次加锁就能将队列中所有数据取出,大大减少了加锁次数。
m_notEmpy.wait(locker, [this]{ return m_needStop || NotEmpty(); })判断式由两个条件组成,一个是停止的标志,一个是不为空的条件。当不满足任何一个条件时,条件变量会释放mutex并将线程置于wait状态,等待其他线程notify_one或notify_all将其唤醒。
9.4 线程池
线程池的实现:
#include <list>
#include <thread>
#include <functional>
#include <memory>
#include <atomic>
#include "SyncQueue.hpp"
const int MaxTaskCount = 100;
class ThreadPool
{
public:
using Task = std::function<void(void)>;
ThreadPool(int numThreads = std::thread::hardware_concurrency()) : m_queue(MaxTaskCount)
{
Start(numThreads);
}
~ThreadPool()
{
// 如果没有停止,则主动停止线程池
Stop();
}
void Stop()
{
// 保证多线程下只调用一次StopThreadGroup
std::call_once(m_flag, [this]{ StopThreadGroup(); });
}
void AddTask(Task&& task)
{
m_queue.Put(std::forward<Task>(task));
}
void AddTask(const Task& task)
{
m_queue.Put(task);
}
private:
void Start(int numThreads)
{
m_running = true;
// 创建线程组
for (int i = 0;i < numThreads; i++)
{
// thread runs ThreadPool::RunInThread() on object this
m_threadgroup.push_back(std::make_shared<std::thread>(&ThreadPool::RunInThread, this));
}
}
void RunInThread()
{
while (m_running)
{
std::list<Task> list;
m_queue.Take(list);
for(auto& task:list)
{
if(!m_running) return;
cout << "异步服务层线程id:" << thdId << endl;
task();
}
}
}
void StopThreadGroup()
{
m_queue.Stop();
m_running = false;
for (auto thread : m_threadgroup)
{
if(thread) thread->join();
}
m_threadgroup.clear();
}
// 处理任务的线程组
std::list<std::shared_ptr<std::thread>> m_threadgroup;
// 同步队列
SyncQueue<Task> m_queue;
atomic_bool m_running;
std::once_flag m_flag;
};
9.5 应用实例
void TestPool()
{
ThreadPool pool;
for (int i = 0; i < 10; i++)
{
auto thdId = this_thread::get_id();
pool.AddTask([thdId]{
cout << "同步服务层线程id:" << thdId << endl;
});
}
this_thread::sleep_for(std::chrono::seconds(2));
pool.Stop();
}线程池会根据当前cpu个数创建对应个数的异步线程。同步服务层线程不断地向同步队列添加任务,线程池里的线程会并行处理。
使用线程池时注意:
(1)要保证线程池中的任务不能挂死,否则会耗尽线程池中的线程。
(2)要避免长时间执行一个任务,会导致后面的任务大量堆积而得不到及时处理。对于耗时较长的任务建议采用单个线程处理。
10 使用C++11开发一个轻量级的AOP库(代理模式的应用)
代理模式的定义:由于某些原因需要给某对象提供一个代理以控制对该对象的访问。这时,访问对象不适合或者不能直接引用目标对象,代理对象作为访问对象和目标对象之间的中介。
代理模式的主要优点有:
1 代理模式在客户端与目标对象之间起到一个中介作用和保护目标对象的作用;
2 代理对象可以扩展目标对象的功能;
3 代理模式能将客户端与目标对象分离,在一定程度上降低了系统的耦合度,增加了程序的可扩展性
其主要缺点是:
1 代理模式会造成系统设计中类的数量增加
2 在客户端和目标对象之间增加一个代理对象,会造成请求处理速度变慢;
3 增加了系统的复杂度;
类图如下:

10.1 AOP介绍
AOP(Aspect-Oriented Programming,面向方面编程)。AOP把软件系统分为了两个部分:核心关注点和横切关注点。业务处理的主要流程是核心关注点,与之关系不大的是横切关注点。
10.2 AOP的简单实现
动态织入AOP一般采用动态代理的方式,在运行期对方法进行拦截,将切面动态织入到方法中。
代理模式实现方法的拦截:
#include <iostream>
#include <string>
#include <iostream>
using namespace std;
class IHello
{
public:
IHello()
{
}
virtual ~IHello()
{
}
virtual void Output(const string& str)
{
}
};
class Hello : class IHello
{
public:
void Output(const string& str) override
{
cout << str << endl;
}
};
class HelloProxy : public IHello
{
public:
HelloProxy(IHello* p) : m_ptr(p)
{
}
~HelloProxy()
{
delete m_ptr;
m_ptr = nullptr;
}
void Output(const string& str) final
{
cout << "Before real Output" << endl;
m_ptr->Output(str);
cout << "After real Output" << endl;
}
private:
IHello* m_ptr;
};
void TestProxy()
{
std::shared_ptr<IHello> hello = std::make_shared<HelloProxy>(new Hello());
hello->Output("It is a test");
}
输出结果如下:
Before real Output
It is a test
After real Output这里Hello::Output就是核心逻辑,HelloProxy就是一个切面,非核心逻辑在切面里实现。
代理模式实现的AOP有以下不足:
(1)不够灵活,不能自由组合多个切面。
(2)耦合性强,每个切面必须从基类继承,并实现基类的接口。
10.3 轻量级AOP框架的实现
要实现灵活组合切面,可以将切面作为模板的参数(如下代码AP)。为了降低耦合性,通过模板来做约束,每个切面对象必须有Before(Args...)或After(Args...)方法,用来处理核心逻辑执行前后的非核心逻辑。
AOP的实现如下:
/*
解释一下这段代码的功能,通过宏定义来定义一个member,来检测一个类T有没有名为member的函数。
比如HAS_MEMBER(func),经过宏展开之后,就可以用has_member_func<T,Args>的
方式来检测一个类是否有成员函数func。
*/
#define HAS_MEMBER(member)\
template<typename T, typename ... Args>struct has_member_##member\
{\
private:\
template<typename U> static auto Check(int)->decltype(std::declval<U>().member\
(std::declval<Args>()...), std::true_type());\
template<typename U> static std::false_type Check(...);\
public:\
enum {value = std::is_same<decltype(Check<T>(0)), std::true_type>::value };\
};\
HAS_MEMBER(Before)
HAS_MEMBER(After)template<typename Func, typename.. Args>
struct Aspect : NonCopyable
{
Aspect(Func&& f) : m_func(std::forward(f))
{
}
/*
模板偏特化:
通过typename std::enable_if<bool>::type传入一个bool值
就能推导出这个type是不是未定义的
*/
template<typename T>
typename std::enable_if<has_member_Before<T, Args...>::value && has_member_After<T, Args...>::value>::type Invoke(Args&&... args, T&& aspect)
{
aspect.Before(std::forward<Args>(args)...); //核心逻辑之前的切面逻辑
m_func(std::forward<Args>(args)...); //核心逻辑
aspect.After(std::forward<Args>(args)...); //核心逻辑之后的切面逻辑
}
template<typename T>
typename std::enable_if<has_member_Before<T, Args...>::value && !has_member_After<T, Args...>::value>::type Invoke(Args&&... args, T&& aspect)
{
aspect.Before(std::forward<Args>(args)...); //核心逻辑之前的切面逻辑
m_func(std::forward<Args>(args)...); //核心逻辑
}
template<typename T>
typename std::enable_if<!has_member_Before<T, Args...>::value && has_member_After<T, Args...>::value>::type Invoke(Args&&... args, T&& aspect)
{
m_func(std::forward<Args>(args)...); //核心逻辑
aspect.After(std::forward<Args>(args)...); //核心逻辑之后的切面逻辑
}
template<typename Head, typename... Tail>
void Invoke(Args&&... args, Head&& headAspect, Tail&&... tailAspect)
{
headAspect.Before(std::forward<Args>(args)...);
Invoke(std::forward<Args>(args)..., std::forward<Tail>(tailAspect)...);
headAspect.After(std::forward<Args>(args)...);
}
private:
Func m_func;
};
template<typename T> using identity_t = T;
// AOP的辅助函数,简化调用
template<typename... AP, typename... Args, typename Func>
void Invoke(Func&& f, Args&&... args)
{
Aspect<Func, Args...> asp(std::forward<Func>(f));
// 调用到Aspect的最后一个Invoke
asp.Invoke(std::forward<Args>(args)..., identity_t<AP>()...);
}
以上代码切面中的约束:
(1)通过模板参数化切面,要求切面必须有Before或After函数
(2)Before或After函数的入参必须和核心逻辑的函数入参保持一致
应用举例,带日志和计时切面的AOP:
struct TimeElapseAspect
{
void Before(int i)
{
m_lastTime = m_t.elapsed();
}
void After(int i)
{
cout << "time elapsed: " << m_t.elapsed() - m_lastTime << endl;
}
private:
double m_lastTime;
Timer m_t;
};
struct LoggingAspect
{
void Before(int i)
{
cout << "entering" << endl;
}
void After(int i)
{
cout << "leaving" << endl;
}
};
void foo(int a)
{
cout << "real function: " << a << endl;
}
int main()
{
Invoke<LoggingAspect, TimeElapseAspect>(&foo, 1);
return 0;
}
输出结果:
entering
start timer
real function: 1
time elapsed: 0.001
leaving参考网址:
http://c.biancheng.net/view/1359.html
SFINAE技术初涉_qq_37925512的博客-CSDN博客
11 使用C++11开发一个轻量级的IoC容器(工厂模式的应用及优化)
11.1 IoC容器是什么
工厂模式的定义:定义一个创建产品对象的工厂接口,将产品对象的实际创建工作推迟到具体子工厂类当中。
类图如下:

第11章介绍了C++11改进工厂模式的各种优化手段,一层一层地解耦泛化封装。
先看一个由直接依赖产生耦合性的例子:
#include <iostream>
using namespace std;
struct Base
{
virtual ~Base(){};
virtual void Func(){};
};
struct DerivedB : Base
{
void Func() override
{
cout << "call func in DerivedB" << endl;
}
};
struct DerivedC : Base
{
void Func() override
{
cout << "call func in DerivedC" << endl;
}
};
struct DerivedD : Base
{
void Func() override
{
cout << "call func in DerivedD" << endl;
}
};
// 类似代理模式
class A
{
public:
A(Base* interface) : m_inferfaceB(interface)
{
}
~A()
{
if (m_interfaceB != nullptr)
{
delete m_interfaceB;
m_interfaceB = nullptr;
}
}
void Func()
{
m_interfaceB->Func();
}
private:
// 依赖,是一种使用的关系
// 虽然依赖相对于继承关系属于对象关系中最弱的一种,但也会产生耦合性
Base* m_interfaceB;
};
int main()
{
A* a = new A(new DerivedB());
a->Func();
delete a;
return 0;
}
输出结果:
call func in DerivedB
A对象直接依赖于Base接口对象,会产生耦合性。看如下例子:
int main()
{
A* a = nullptr;
if (conditionB)
a = new A(new DerivedB());
else if (conditionC)
a = new A(new DerivedC());
else
a = new A(new DerivedD());
delete a;
return 0;
}耦合性产生的原因在于A对象的创建直接依赖于new外部对象,这属于硬编码,使二者紧耦合。一种解决方法是通过工厂模式来创建对象。
struct Factory
{
static Base* Create(const string& condition)
{
if (condition == "B")
return new DerivedB();
else if (condition == "C")
return new DerivedC();
else if (condition == "D")
return new DerivedD();
else
return nullptr;
}
};
int main()
{
string condition = "B";
A *a = new A(Factory::Create(condition));
a->Func();
delete a;
return 0;
}工厂模式避免了直接依赖,降低了耦合性,但是A对象仍然要依赖于一个工厂,通过工厂间接依赖于Base对象,没有彻底解耦。
控制反转(Inversion of Control, IoC),就是应用本身不负责依赖对象的创建和维护,而交给一个外部容器来负责。这样控制权就由应用转移到了IoC容器,实现了控制反转。IoC用来降低对象之间直接依赖产生的耦合性。具体做法是在IoC容器中配置这种依赖关系,有IoC容器来管理对象的依赖关系。
void IocSample()
{
// 通过IoC容器来配置A和Base对象的关系
IocContainer ioc;
// A与Base是依赖关系
ioc.RegisterType<A, DerivedB>("B");
ioc.RegisterType<A, DerivedC>("C");
ioc.RegisterType<A, DerivedD>("D");
// 由IoC容器区初始化A对象
A* a = ioc.Resolve<A>("B");
a->Func();
delete a;
}通过依赖注入(Dependency Injection, DI)来将对象创建的依赖关系注入到目标类型的构造函数中。如将上例中A依赖于DerivedB的依赖关系注入到A的构造函数中。这样,A对象的创建不再依赖于工厂和Base对象,彻底解耦。
实现IoC容器需要解决3个问题:
(1)创建所有类型的对象(11.2)
(2)类型擦除(11.3, 11.4)
(3)创建依赖对象(11.4)
参考网址:
http://c.biancheng.net/view/1348.html
11.2 IoC创建对象
一个可配置的对象工厂实现思路如下:
1 先注册可能需要创建对象的构造函数,将其放到一个内部关联容器map中,设置键为类型的名字,值为类型的构造函数。
2 然后在创建的时候根据类型名称查找对应的构造函数并最终创建出目标对象。
可配置的对象工厂如下:
#include <string>
#include <map>
#include <memory>
#include <functional>
using namespace std;
template<class T>
class IocContainer
{
public:
IocContainer() {}
~IocContainer() {}
// 注册需要创建对象的构造函数
template<class Drived>
void RegisterType(string strKey)
{
std::function<T*()> function = []{return new Drived();};
RegisterType(strKey, function);
}
// 根据唯一标识查找对应的构造函数,并创建指针对象
T* Resolve(string strKey)
{
if (m_creatorMap.find(strKey) == m_creatorMap.end())
{
return nullptr;
}
std::function<T*()> function = m_creatorMap(strKey);
return function();
}
// 创建智能指针对象
std::shared_ptr<T> ResolveShared(string strKey)
{
T* ptr = Resolve(strKey);
return std::shared_ptr<T>(ptr);
}
private:
void RegisterType(string strKey, std::function<T*()> creator)
{
if (m_creatorMap.find(strKey) != m_creatorMap.end()) {
throw std::invalid_argument("this key has already exist!");
}
m_creatorMap.emplace(strKey, creator);
}
private:
map<string, std::function<T*()>> m_creatorMap;
};测试代码如下:
struct ICar
{
virtual ~ICar() {}
virtual void test() const = 0;
};
struct Bus : ICar
{
Bus() {};
void test() const { cout << "Bus::test()" << endl; };
};
struct Car : ICar
{
Car() {};
void test() const { cout << "Car::test()" << endl; };
};
int main()
{
IocContainer<ICar> carioc;
// Bus,ICar继承关系
carioc.RegisterType<Bus>("bus");
carioc.RegisterType<Car>("car");
std::shared_ptr<ICar> bus = carioc.ResolveShared("bus");
bus->test();
std::shared_ptr<ICar> car = carioc.ResolveShared("car");
car->test();
return 0;
}
输出结果:
Bus::test()
Car::test()上述代码可以创建所有的无参数的ICar派生对象。但还有如下两点不足:
(1)只能创建无参对象,不能创建有参数的对象。
(2)只能创建一种接口类型ICar的对象,通过ioccar实例不能创建所有类型的对象。
如果希望能够创建所有类型的对象,则需要通过类型擦除来实现。
11.3 类型擦除的常用方法
类型擦除就是将原有类型消除或隐藏。类型擦除可以使得程序获得更好的扩展性,消除耦合。
下面是常见的类型擦除方式:
1 多态
2 模板
3 类型容器Variant
4 通用类型Any
5 闭包
1 多态
通过将派生类型隐式转换为基类型,再通过基类去调用虚函数。这样就把派生类型转成基类型隐藏起来。多态方式的类型擦除只是部分擦除,因为基类型还在;且需要继承关系,强耦合。
2 模板
本质上是把不同类型的共同行为进行了抽象,不需要再通过继承这种强耦合方式去获取共同的行为。存在的问题是,不能把T本身作为容器元素,必须在容器初始化时指定T为某个具体类型。
3 类型容器Variant
Variant可以把各种不同的类型包起来,获得一种统一的类型,它是个类型容器。例如,可以通过Variant这样擦除类型:
typedef Variant<double, int, uint32_t, char*> Value;
vector<Value> vt;
vt.push_back(1);
vt.push_back("test");
vt.push_back(1.22);通过Get<T>()就可以获取对应类型的值。这种方式通过把类型包起来,达到类型擦除的目的。缺点是通用的类型必须提前定义好。
4 通用类型Any
通用类型Any类似Java中的Object,介绍用Any类型擦除的方法:
vector<Any> v;
v.push_back(1);
v.push_back("test");
v.push_back(2.35);
auto r1 = v[0].AnyCast<int>();
auto r2 = v[1].AnyCast<const char*>();
auto r3 = v[2].AnyCast<double>();Any允许任何类型的对象都赋值给Any对象。缺点是取值的时候仍需要具体的类型,可通过闭包改进。
5 闭包
闭包就是能够读取其他函数内部变量的函数。如lambda表达式。闭包将类型信息保存在闭包中,从而隐藏了类型信息,实现类型擦除的目的。因为闭包本身类型是确定的,可以放到普通容器中,在需要时可从闭包中取出具体的类型。看下如何通过闭包擦除类型:
template<typename T>
void Func(T t)
{
cout << t << endl;
}
void TestErase()
{
int x = 1;
char y = 's';
vector<std::function<void()>> v;
// 类型擦除,闭包中隐藏了具体的类型(x,y)
v.pushback([x]{ Func(x); });
v.pushback([y]{ Func(y); });
// 遍历闭包,取出实际的参数
for (auto item:v)
{
item();
}
}IoC容器主要用到通用类型Any和闭包来擦除类型。
11.4 通过Any和闭包来擦除类型和创建依赖的对象
11.2节的对象工厂只能创建指定接口类型的对象,原因是它依赖了一个类型固定的对象构造器std::function<T*()>,这个function作为对象构造器只能创建T类型的对象,不能创建所有类型的对象。我们可以通过Any类来使map存放所有类型的对象。Any类的基本用法如下:
Any a = 1;
Any b = 1.25;
Any c = "string";
std::vector<Any> v = {a, b, c};
// 用的时候转换回来
if (a.Is<int>())
{
int i = a.AnyCast<int>();
}
if (b.Is<double>)
{
double j = b.AnyCast<double>();
}通过Any擦除类型可以解决之前对象工厂不能创建所有类型对象的问题:
#include <string>
#include <unordered_map>
#include <memory>
#include <functional>
using namespace std;
#include "Any.hpp"
class IocContainer
{
public:
IocContainer() {}
~IocContainer() {}
// 注册需要创建对象的构造函数
template<class T, typename Depend>
void RegisterType(const string& strKey)
{
// 注意,这里创建的是依赖的对象!不再是创建对象!
// 通过闭包擦除了Depend参数类型
std::function<T*()> function = []{ return new T(new Depend()); };
RegisterType(strKey, function);
}
// 根据唯一标识查找对应的构造函数,并创建指针对象
template<class T>
T* Resolve(const string& strKey)
{
if (m_creatorMap.find(strKey) == m_creatorMap.end())
{
return nullptr;
}
Any resolver = m_creatorMap[strKey];
// 将查找到的Any转换为function
std::function<T*()> function = resolver.AnyCast<std::function<T*()>>();
return function();
}
// 创建智能指针对象
template<class T>
std::shared_ptr<T> ResolveShared(const string& strKey)
{
T* ptr = Resolve<T>(strKey);
return std::shared_ptr<T>(ptr);
}
private:
void RegisterType(const string& strKey, Any constructor)
{
if (m_creatorMap.find(strKey) != m_creatorMap.end()) {
throw std::invalid_argument("this key has already exist!");
}
// 通过Any擦除不同类型的构造器
m_creatorMap.emplace(strKey, constructor);
}
private:
unordered_map<string, Any> m_creatorMap;
};测试代码如下:
struct Base
{
virtual ~Base();
virtual void Func();
};
struct DerivedB : public Base
{
void Func() override
{
cout << "call func in DerivedB" << endl;
}
};
struct DerivedC : public Base
{
void Func() override
{
cout << "call func in DerivedC" << endl;
}
};
struct DerivedD : public Base
{
void Func() override
{
cout << "call func in DerivedD" << endl;
}
};
struct A
{
A(Base* ptr) : m_ptr(ptr)
{
}
~A()
{
if (m_ptr != nullptr)
{
delete m_ptr;
m_ptr = nullptr;
}
}
void Func()
{
m_ptr->Func();
}
private:
Base* m_ptr;
};
void TestIOC()
{
IocContainer ioc;
// 配置依赖关系
ioc.RegisterType<A, DerivedB>("B");
ioc.RegisterType<A, DerivedC>("C");
ioc.RegisterType<A, DerivedD>("D");
auto pb = ioc.ResolvedShared<A>("B");
pb->Func();
auto pc = ioc.ResolvedShared<A>("C");
pc->Func();
return 0;
}
输出结果:
call func in DerivedB
call func in DerivedC改进后,当前对象工厂可以创建所有无参接口类型的对象。对于创建带参数的对象,可以用可变参数模板来优化。
11.6 完整的IoC容器
通过可变参数模板改进IoC容器,让它支持带参数对象的创建:
#include <string>
#include <unordered_map>
#include <memory>
#include <functional>
using namespace std;
#include "Any.hpp"
#include "NonCopyable.hpp"
class IocContainer : NonCopyable
{
public:
IocContainer() {}
~IocContainer() {}
// 注册需要创建对象的构造函数
template<class T, typename Depend, typename... Args>
void RegisterType(const string& strKey)
{
// 注意,这里创建的是依赖的对象!不再是创建对象!
// 通过闭包擦除了Depend参数类型
std::function<T*(Args...)> function = [](Args... args){ return new T(new Depend(args...)); };
RegisterType(strKey, function);
}
// 根据唯一标识查找对应的构造函数,并创建指针对象
template<class T,typename... Args>
T* Resolve(const string& strKey, Args... args)
{
if (m_creatorMap.find(strKey) == m_creatorMap.end())
{
return nullptr;
}
Any resolver = m_creatorMap[strKey];
// 将查找到的Any转换为function
std::function<T*(Args...)> function = resolver.AnyCast<std::function<T*(Args...)>>();
return function(args...);
}
// 创建智能指针对象
template<class T, typename... Args>
std::shared_ptr<T> ResolveShared(const string& strKey, Args... args)
{
T* ptr = Resolve<T>(strKey, args...);
return std::shared_ptr<T>(ptr);
}
private:
void RegisterType(const string& strKey, Any constructor)
{
if (m_creatorMap.find(strKey) != m_creatorMap.end()) {
throw std::invalid_argument("this key has already exist!");
}
// 通过Any擦除不同类型的构造器
m_creatorMap.emplace(strKey, constructor);
}
private:
unordered_map<string, Any> m_creatorMap;
};测试代码如下:
struct Base
{
virtual ~Base();
virtual void Func();
};
struct DerivedB : public Base
{
DerivedB(int a, double b):m_a(a), m_b(b)
{
}
void Func() override
{
cout << m_a + m_b << endl;
}
private:
int m_a;
double m_b;
};
struct DerivedC : public Base
{
};
struct A
{
A(Base* ptr) : m_ptr(ptr)
{
}
~A()
{
if (m_ptr != nullptr)
{
delete m_ptr;
m_ptr = nullptr;
}
}
void Func()
{
m_ptr->Func();
}
private:
Base* m_ptr;
};
void TestIOC()
{
IocContainer ioc;
// 配置依赖关系
ioc.RegisterType<A, DerivedC>("C");
auto pc = ioc.ResolvedShared<A>("C");
// 注册时注意DerivedB的参数int,double
ioc.RegisterType<A, DerivedB, int, double>("B");
auto pb = ioc.ResolvedShared<A>("B", 1, 2.0);
pb->Func();
return 0;
}
输出结果:
3上面代码可以创建所有的有参构造函数对象了。注意,当前RegisterType里A与继承类(DerivedB)的关系是依赖关系。
我们希望RegisterType更加灵活,支持多种配置。
(1)可配置依赖关系
(2)可配置继承关系
(3)可创建普通的对象
完整的IoC的最终实现代码如下:
#include <string>
#include <unordered_map>
#include <memory>
#include <functional>
using namespace std;
#include "Any.hpp"
#include "NonCopyable.hpp"
class IocContainer : NonCopyable
{
public:
IocContainer() {}
~IocContainer() {}
// 1 配置依赖关系
template<class T, typename Depend, typename... Args>
typename std::enable_if<!std::is_base_of<T, Depend>::value>::type RegisterType (const string& strKey)
{
std::function<T* (Args...)> function = [](Args... args) { return new T(new Depend(args...)) };
RegisterType(strKey, function);
}
// 2 配置继承关系
template<class T, typename Depend, typename... Args>
typename std::enable_if<!std::is_base_of<T, Depend>::value>::type RegisterType (const string& strKey)
{
std::function<T* (Args...)> function = [](Args... args) { return new Depend(args...) };
RegisterType(strKey, function);
}
// 3 创建普通对象
template<class T, typename... Args>
void RegisterSimple(const string& strKey)
{
std::function<T* (Args...)> function = [](Args... args) { return new T(args...) };
RegisterType(strKey, function);
}
// 根据唯一标识查找对应的构造函数,并创建指针对象
template<class T,typename... Args>
T* Resolve(const string& strKey, Args... args)
{
if (m_creatorMap.find(strKey) == m_creatorMap.end())
{
return nullptr;
}
Any resolver = m_creatorMap[strKey];
// 将查找到的Any转换为function
std::function<T* (Args...)> function = resolver.AnyCast<std::function<T*(Args...)>>();
return function(args...);
}
// 创建智能指针对象
template<class T, typename... Args>
std::shared_ptr<T> ResolveShared(const string& strKey, Args... args)
{
T* ptr = Resolve<T>(strKey, args...);
return std::shared_ptr<T>(ptr);
}
private:
void RegisterType(const string& strKey, Any constructor)
{
if (m_creatorMap.find(strKey) != m_creatorMap.end()) {
throw std::invalid_argument("this key has already exist!");
}
// 通过Any擦除不同类型的构造器
m_creatorMap.emplace(strKey, constructor);
}
private:
unordered_map<string, Any> m_creatorMap;
};上述代码通过依赖注入的方式实现了控制反转。所谓依赖注入,即组件之间的依赖关系由容器在运行期决定,即由容器动态地将某种依赖关系注入到组件中。
测试代码如下:
struct Base
{
virtual ~Base();
virtual void Func();
};
struct DerivedB : public Base
{
DerivedB(int a, double b):m_a(a), m_b(b)
{
}
void Func() override
{
cout << m_a + m_b << endl;
}
private:
int m_a;
double m_b;
};
struct DerivedC : public Base
{
};
struct A
{
A(Base* ptr) : m_ptr(ptr)
{
}
~A()
{
if (m_ptr != nullptr)
{
delete m_ptr;
m_ptr = nullptr;
}
}
void Func()
{
m_ptr->Func();
}
private:
Base* m_ptr;
};
struct SimpleE
{
SimpleE(int a):m_a(a)
{
}
private:
int m_a;
};
void TestIOC()
{
IocContainer ioc;
//1 配置依赖关系
ioc.RegisterType<A, DerivedB, int, double>("B");
auto pb = ioc.ResolvedShared<A>("B", 1, 2.0);
pb->Func();
//2 配置继承关系
ioc.RegisterType<Base, DerivedC>("C");
auto pc = ioc.ResolvedShared<Base>("C");
//3 创建普通的对象
ioc.RegisterType<SimpleE>("E");
auto pe = ioc.ResolvedShared<SimpleE>("E");
return 0;
}注意:
(1)IoC容器不能实现完美转发,因为注册时丢失了参数为左值还是右值的信息
(2)建议使用ResolvedShared接口,智能指针,自动管理生命周期
12 使用C++11开发一个对象的消息总线(观察者模式和中介者模式的应用及优化)
12.2 消息总线关键技术
对象之间的关系:依赖,关联,聚合,组合和继承,耦合关系依次加强。
12.2 消息总线关键技术
12.2.1 通用的消息定义
消息类型定义:主题+泛型函数的签名
主题可以是字符串或整型等其他类型;这里将泛型函数定为std::function<R(Args...)>,R表示函数返回值,Args表示函数可变入参。泛型函数能表示所有的可调用对象,表示通用的消息格式。
如下将可调用对象转换为std::function,用到特性萃取function_traits:
#include<functional>
#include<tuple>
template<typename T>
struct function_traits;
// 普通函数
template<typename Ret,typename... Args>
struct function_traits<Ret(Args...)>
{
public:
enum { arity = sizeof...(Args) };
typedef Ret function_type(Args...);
typedef Ret return_type;
using stl_function_type = std::function<function_type>;
typedef Ret(*pointer)(Args...);
template<size_t I>
struct args {
static_assert(I < arity, "index is out of range");
using type = typename std::tuple_element < I, std::tuple<Args...>>::type;
};
};
// 函数指针
template<typename Ret, typename... Args>
struct function_traits<Ret(*)(Args...)> : function_traits<Ret(Args...)>{};
// std::function
template<typename Ret, typename... Args>
struct function_traits<std::function<Ret(Args...)>> : function_traits<Ret(Args...)>{};
// member function
#define FUNCTION_TRAITS(...)\
template<typename ReturnType, typename ClassType, typename ... Args>\
struct function_traits<ReturnType(ClassType::*)(Args...) __VA_ARGS__> : function_traits<ReturnType(Args...)>{}; \
FUNCTION_TRAITS()
FUNCTION_TRAITS(const)
FUNCTION_TRAITS(volatile)
FUNCTION_TRAITS(const volatile)
// 函数对象
template<typename Callable>
struct function_traits :function_traits<decltype(&(Callable::operator())>{};
template<typename Function>
typename function_traits<Function>::stl_function_type to_function(const Function & lambda)
{
return static_cast<function_traits<Function>::stl_function_type>(lambda);
}
template<typename Function>
typename function_traits<Function>::stl_function_type to_function(Function && lambda)
{
return static_cast<function_traits<Function>::stl_function_type(std::forward<Function>(lambda));
}
template<typename Function>
typename function_traits<Function>::pointer to_function_pointer(const Function & lambda)
{
return static_cast<typename function_traits<Function>::pointer>(lambda);
}测试代码如下:
auto f = to_function([](int i){return i;});
std::function<int(int)> f1 = [](int i){return i;};
if (std::is_same<deltype(f), deltype(1)>::value) {
cout << "same" << endl;
}输出same,可以看到,to_function会将lambda表达式(可调用对象)转换为std::function。
12.2.2 消息的注册
消息的注册是告诉总线该对象对某种消息感兴趣,希望收到某种主题和类型的消息。
消息类型:topic + std::function<R(Args...)>。
对于不同的Args和R,消息类型是不同的。为了保存不同的消息对象,需要用Any做类型擦除。
最后,消息总线内部使用std::unordered_multimap<string, Any> m_map来保存消息,键为topic + typeid的字符串,值为消息对象。
消息注册如下:
// 注册可调用对象
template<typename T>
void Attach(const string& strTopic, const F& f)
{
auto func = to_function(f);
Add(strTopic, std::move(func));
}
template<typename T>
void Add(const string& strTopic, F&& f)
{
// typeid 运算符用来获取一个表达式的类型信息
string strKey = strTopic + typeid(F).name();
// Any类型擦除
m_map.emplace(std::move(strKey), f);
}先将可调用对象转换为了std::function,后将std::function通过类型擦除转换为Any,最后将消息保存在map里。
12.2.3 消息分发
看下消息总线如何发送消息的:
template<typename R, typename... Args>
void sendReq(Args&&... args, const string& strTopic = "")
{
using function_type = std::function<R(Args...)>; // 1
string strMsgType = strTopic + typeid(function_type).name(); // 2
auto range = m_map.equal_range(strMsgType); // 3
for (Iterator it = range.first(); it != range.second; it++) // 4
{
auto f = it->second.AnyCast<function_type>(); // 5
f(std::forward<Args>(args)...); // 6
}
}函数的第1行根据形参生成具体的消息std::function<R(Args...)>;第2行获取主题+表达式类型的字符串,用来查找注册了该消息的对象;第3行查找哪些对象注册了该消息;第5行将被擦除类型恢复;第6行通知接收者处理消息。
12.2.4 消息总线的设计思想
消息总线融合了观察者模式和中介者模式。观察者模式是用来维护主题目标,在适当的时候向观察者广播消息;中介者模式用来降低主题目标与各个观察者之间的耦合性,把观察者中主题目标与观察者的1对多关系转移为中介者与观察者的1对多关系,使得主题目标与观察者不再依赖,耦合性降低。另外,消息是所有类型的可调用对象,没有对象之间的直接调用,没有继承,也会降低耦合性。
先看下观察者模式和中介者模式:
(1)观察者模式
观察者(Observer)模式的定义:指多个对象间存在一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。这种模式有时又称作发布-订阅模式,它是对象行为型模式。
观察者模式是一种对象行为型模式,其主要优点如下。
1 降低了目标与观察者之间的耦合关系,两者之间是抽象耦合关系。符合依赖倒置原则。
2 目标与观察者之间建立了一套触发机制。
它的主要缺点如下。
1 目标与观察者之间的依赖关系并没有完全解除。
2 当观察者对象很多时,通知的发布会花费很多时间,影响程序的效率。
类图如下:
(2)中介者模式
中介者(Mediator)模式的定义:定义一个中介对象来封装一系列对象之间的交互,使原有对象之间的耦合松散,且可以独立地改变它们之间的交互。中介者模式又叫调停模式,它是迪米特法则的典型应用。
中介者模式是一种对象行为型模式,其主要优点如下。
1 类之间各司其职,符合迪米特法则。
2 降低了对象之间的耦合性,使得对象易于独立地被复用。
3 将对象间的一对多关联转变为一对一的关联,提高系统的灵活性,使得系统易于维护和扩展。
其主要缺点是:中介者模式将原本多个对象直接的相互依赖变成了中介者和多个同事类的依赖关系。当同事类越多时,中介者就会越臃肿,变得复杂且难以维护。
中介者模式包含以下主要角色。
1 抽象中介者(Mediator)角色:它是中介者的接口,提供了同事对象注册与转发同事对象信息的抽象方法。
2 具体中介者(Concrete Mediator)角色:实现中介者接口,定义一个 List 来管理同事对象,协调各个同事角色之间的交互关系,因此它依赖于同事角色。
3 抽象同事类(Colleague)角色:定义同事类的接口,保存中介者对象,提供同事对象交互的抽象方法,实现所有相互影响的同事类的公共功能。
4 具体同事类(Concrete Colleague)角色:是抽象同事类的实现者,当需要与其他同事对象交互时,由中介者对象负责后续的交互。
类图如下:
消息总线的时序图如下:

图12-1 消息总线时序图
从图12-1可以看到,Subject和Observer对象之间没有任何联系,它们是通过消息总线发生联系的。
(1)观察者向消息总线注册消息,消息类型定义:主题+泛型函数的签名。
topic + std::function<R(Args...)>
(2)消息总线保存观察者注册的消息。
(3)主题对象向消息总线发送消息,消息类型定义:主题+泛型函数的签名。
topic + std::function<R(Args...)>
(4)消息总线根据主题对象发送的消息查找对该消息感兴趣的观察者。
(5)消息总线向观察者广播消息。
(6)观察者处理消息。
消息总线的类图如下:
图12-2 消息总线类图
类图中的几个对象:
(1)NonCopyable:防止类被复制。
(2)MessageBus:消息总线,维护系统之所有的消息,具备注册消息,分发消息和移除消息的功能。
(3)Observer:观察者对象,接收并处理来自消息总线的消息。
(4)Obsever_Function:消息,本质是可调用对象,实际是观察者对象的某个函数。
(5)Subject:主题目标对象,向消息总线发送消息。
分析类图,如何应用了观察者和中介者模式:
(1)主题目标(Subject)与观察者(Observer),观察者注册感兴趣的消息类型,当主题目标发送一个消息时,会通过消息总线告知所有感兴趣的观察者,观察者收到消息后处理消息。==>观察者模式
(2)主题目标(Subject)里不再依赖多个观察者(Observer),而是消息总线里依赖多个观察者,从而使得主题目标与观察者没有关系,降低了耦合度。==>中介者模式
最后来看下消息总线与QT中信号与槽的区别:
(1)消息总线是观察者模式与中介者模式的融合;信号槽本质上是观察者模式。
(2)消息总线可以接收所有类型的函数注册(因为类型擦除);信号槽,一种信号只能接收特定函数注册。
12.3 完整的消息总线
完整的MessageBus实现:
#include <string>
#include <functional>
#include <map>
#include "Any.h"
#include "function_traits.h"
#include "NonCopyable.h"
using namespace std;
class MessageBus : NonCopyable
{
public:
// 注册消息
template<typename F>
void Attach(F&& f, const string& strTopic = "") {
auto func = to_function(std::forward<F>(f));
Add(strTopic, std::move(func));
}
// 发送消息
template<typename R>
void sendReq(const string& strTopic = "") {
using function_type = std::function<R()>;
std::string strMsgType = strTopic + typeid(function_type).name();
auto range = m_map.equal_range(strMsgType);
for (Iterator it = range.first; it!= range.second; it++) {
auto f = it->second.AnyCast<function_type>();
f();
}
}
// 发送消息,函数重载
template<typename R,typename... Args>
void sendReq(Args&&... args,const string& strTopic = "") {
using function_type = std::function<R(Args...)>;
string strMsgType = strTopic + typeid(function_type).name();
auto range = m_map.equal_range(strMsgType);
for (Iterator it = range.first; it != range.second; it++) {
auto f = it->second.AnyCast<function_type>();
f(std::forward<Args>(args)...);
}
}
// 移除消息
template<typename R, typename... Args>
void Remove(const std::string& strTopic = "") {
using function_type = std::function<R(Args...)>;
string strMsgType = strTopic + typeid(function_type).name();
auto range = m_map.equal_range(strMsgType);
m_map.erase(range.first, range.second);
}
private:
template<typename F>
void Add(const string& strTopic, F&& f) {
string strMsgType = strTopic + typeid(F).name();
m_map.emplace(std::move(strMsgType), std::forward<F>(f));
}
std::multimap<string, Any> m_map;
typedef std::multimap<string, Any>::iterator Iterator;
};测试代码如下:
void TestMsgBus()
{
MessageBus bus;
// 注册消息
bus.Attach([](int a){ cout << "no reference " << a << endl; });
bus.Attach([](int& a){ cout << "lvalue reference " << a << endl; });
bus.Attach([](int&& a){ cout << "rvalue reference " << a << endl; });
bus.Attach([](const int& a){ cout << "const lvalue reference " << a << endl; });
bus.Attach([](int a){ cout << "no reference " << a << " return value " << endl;
return a; }, "a"); 自定义主题"a"
int i = 2;
// 发送消息
bus.SendReq<void, int>(2);
bus.SendReq<int, int>(2, "a");
bus.SendReq<void, int&>(i);
bus.SendReq<void, const int&>(2);
bus.SendReq<void, int&&>(2);
// 移除消息
bus.Remove<void, int>();
bus.Remove<int, int>("a");
bus.Remove<void, int&>();
bus.Remove<void, const int&>();
bus.Remove<void ,int&&>();
// 测试继续发送消息
bus.SendReq<void, int>(2);
bus.SendReq<int, int>(2, "a");
bus.SendReq<void, int&>(i);
bus.SendReq<void, const int&>(2);
bus.SendReq<void, int&&>(2);
}输出结果如下:
no reference 2
no reference 2 return value
lvalue reference 2
rvalue reference 2
const lvalue reference 2 上述代码,移除所有消息后,发送的消息没有接收者,所以不会有打印。
12.4 应用实例
假设有3个对象Car,Bus,Truck,都向消息总线注册了消息,消息类型为std::function<void(int)>,其中Car,Bus在注册时指定了主题。这三个对象在注册完消息后,希望能收到感兴趣的消息并处理,并不关心是谁给他们发送消息;另外,有个Subject会发送消息,Subject并不关心实惠收到消息。
3个对象和Subject对象没有耦合关系,它们之间唯一的联系就是消息总线。MessageBus的一个应用示例如下:
#include "MessageBus.hpp"
MessageBus g_bus;
const string Topic = "Drive";
struct Subject
{
void SendReq(const string& topic)
{
g_bus.SendReq<void, int>(500,topic);
}
};
Struct Car
{
Car()
{
g_bus.Attach([this](int speed){ Drive(speed); }, Topic);
}
void Drive(int speed)
{
cout << "Car drive " << speed << endl;
}
};
Struct Bus
{
Bus()
{
g_bus.Attach([this](int speed){ Drive(speed); }, Topic);
}
void Drive(int speed)
{
cout << "Bus drive " << speed << endl;
}
};
Struct Truck
{
Truck()
{
g_bus.Attach([this](int speed){ Drive(speed); });
}
void Drive(int speed)
{
cout << "Truck drive " << speed << endl;
}
};
void TestBus()
{
Subject subject;
Car car;
Bus bus;
Truck truck;
subject.SendReq(Topic);
cout << "-------" << endl;
subject.SendReq("");
g_bus.Remove<void, int>();
subject.SendReq("");
}
输出结果如下:
Car drive
Bus drive
-------
Truck drive
subject发送"Drive"主题的消息时,Car和Bus接收消息并处理;subject发送""消息时,Truck接收消息并处理。消息总线删除std::funciton<void(int)>消息后,接收者不再接收消息。
需求变复杂:在3个对象接收并处理完消息后,需要再告诉发送者消息已经处理完成。
MessageBus的应用示例如下:
#include "MessageBus.hpp"
MessageBus g_bus;
const string Topic = "Drive";
const string CallBackTopic = "DriveOk";
struct Subject
{
Subject
{
// 主题也注册消息
g_bus.Attach([this]{ DriveOk(); }, CallBackTopic);
}
void SendReq(const string& topic)
{
g_bus.SendReq<void, int>(500,topic);
}
void DriveOK()
{
cout << "drive ok" << endl;
}
};
Struct Car
{
Car()
{
g_bus.Attach([this](int speed){ Drive(speed); }, Topic);
}
void Drive(int speed)
{
cout << "Car drive " << speed << endl;
// 接收者处理消息后,回复消息给发送者
g_bus.SendReq<void>(CallBackTopic);
}
};
Struct Bus
{
Bus()
{
g_bus.Attach([this](int speed){ Drive(speed); }, Topic);
}
void Drive(int speed)
{
cout << "Bus drive " << speed << endl;
// 接收者处理消息后,回复消息给发送者
g_bus.SendReq<void>(CallBackTopic);
}
};
Struct Truck
{
Truck()
{
g_bus.Attach([this](int speed){ Drive(speed); });
}
void Drive(int speed)
{
cout << "Truck drive " << speed << endl;
// 接收者处理消息后,回复消息给发送者
g_bus.SendReq<void>(CallBackTopic);
}
};
void TestBus()
{
Subject subject;
Car car;
Bus bus;
Truck truck;
subject.SendReq(Topic);
cout << "-------" << endl;
subject.SendReq("");
g_bus.Remove<void, int>();
subject.SendReq("");
}
输出结果如下:
Car drive
drive ok
Bus drive
drive ok
-------
Truck drive
drive ok
可以看到用户只需维护主题与消息,对象(Car,Bus,Truck)之间都是松耦合。
注意:
消息总线的使用场景适用于对象很多且关系复杂的时候,对于对象较少且关系简单的不要使用消息总结使得简单问题复杂化。
16 使用C++11开发一个简单的通信程序(Proactor模式)
16.1 Reactor反应器模式和Proactor主动器模式介绍
libevent是基于Reactor(反应器)模式实现的,asio是基于Proactor(主动器)模式实现的。
1 Reactor反应器
反应器模式的类图:
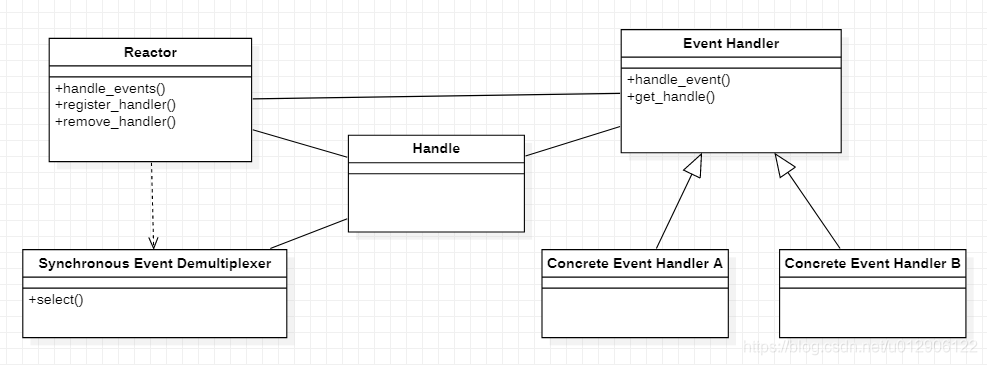 图16-1 反应器模式的类图
图16-1 反应器模式的类图
反应器模式的流程如下:
(1)应用程序在反应器上注册具体事件处理器,处理器提供内部句柄给反应器。
(2)应用程序开始启动反应器事件循环。反应器将通过select等待发生在句柄集上的事件。
(3)当一个或多个句柄编程就绪状态时,反应器将通知注册的具体事件处理器。
(4)具体事件处理器处理事件,完成用户请求。
反应器模式不能同时支持大量的客户请求或者耗时过长的请求,因为select的支持的fd数量有限且本质上是同步IO,会阻塞。
这里总结下Unix IO模型中的3种“异步IO”(select,poll,epoll):
select和poll:本质上是同步IO,内核态缓冲区拷贝到用户态缓冲区时是阻塞的;
epoll:很接近异步IO,还不完善;(Windows的IOCP完成端口实现了真正的异步IO)
2 Proactor主动器
主动器模式的类图:
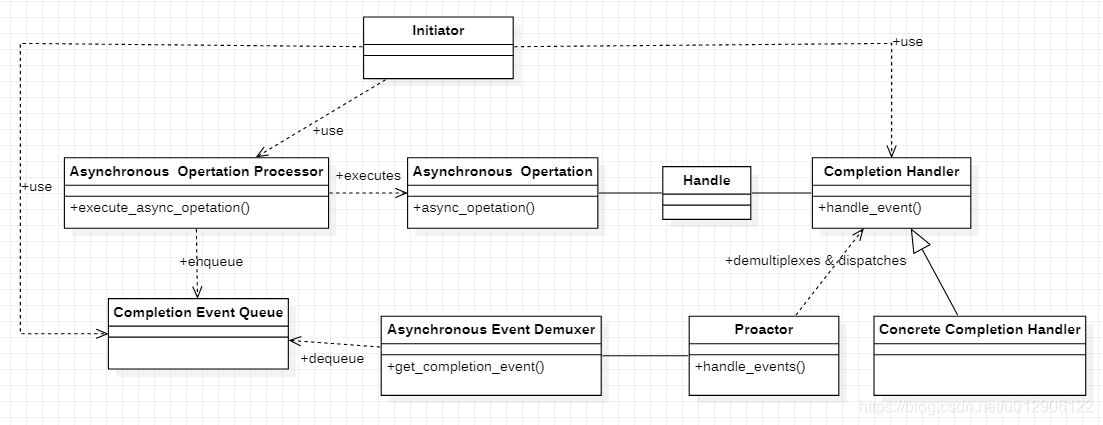 图16-2 主动器模式的类图
图16-2 主动器模式的类图
主动器模式的流程如下:
(1)应用程序定义一个异步执行的操作,如socket的异步读/写。
(2)异步事件处理器(AOP)将异步请求交给操作系统后就直接返回了,让操作系统去完成具体的操作,操作系统完成操作之后,会将完成事件放入一个完成事件队列。
(3)异步事件分离器会检测完成事件,若有事件则从完成事件队列里取出事件,并通知应用程序注册的完成事件处理函数去处理。
(4)完成事件处理函数去处理事件。
Reactor模式和Proactor模式的主要区别就是Reactor实际上是同步IO,需要反应器通过select等待就绪事件;Proactor是异步IO,用户发出请求后直接返回,由操作系统完成具体操作然后回调通知用户事件已经完成。
16.3 asio的基本用法
asio的异步操作过程如下:(asio的全称为Asynchronous input and output(异步输入输出)的缩写)

图16-7 asio的异步操作过程
(1)应用程序发起了一个异步请求(异步读或写),需要提供socket或异步操作完成函数。
(2)asio的io_object对象会将这个异步请求交给操作系统,由操作系统完成该请求。
(3)调用io-service::run等待异步事件的完成。
(4)操作系统完成异步操作后,将异步操作的结果返回给io_service。
(5)io_service将完成事件的结果回调到对应的完成函数并处理。
用户要发起一个异步操作需要做如下3件事:
(1)发起异步操作,如async_read,async_write,async_connect,这些异步接口需要一个回调函数。
(2)调用io_service::run处理异步事件,必须保证io_service::run不退出,因为io_service通过一个循环去处理这些异步操作事件。一个简单办法是使用io_service::work,保证io_service一直运行。
(3)处理异步操作完成事件,回调函数处理。
16.3.1 异步connect
async_connect的基本用法:
asio::io_service io_service;
// 创建socket
aiso::ip::tcp::socket socket(io_service);
// 发起异步连接
boost::asio::async_connect(socket, server_address, connect_handler);
// 启动事件循环
io_service.run();connect_handler的简单实现如下:
void connect_handler(const boost::system::error_code& error)
{
if (error) {
cout << error.message() << endl;
// 异常处理
return;
}
// do sth.
}16.3.2 异步read
async_read和async_write需要一个boost::asio::buffer来作为数据读和写的缓冲区。
async_read的基本用法如下:
asio::io_service io_service;
asio::ip:tcp::socket socket(io_service);
std::string str = "test";
boost::asio::async_read(socket, boost::asio::buffer(str.c_str(), str.length()+1), read_handler);
io_service.run();
void read_handler(const boost::system::error_code& error)
{
if (error) {
cout << error.message() << endl;
// 异常处理
return;
}
// do sth.
}16.3.3 异步write
注意:不能连续调用异步发送接口async_write。
async_write内部不断调用async_write_some,直到所有的数据发送完成为止。如果第一次调用async_write发送一个较大的包,马上又再调用async_write发送一个很小的包。很可能第二个包先发完,第一个包还没发完,导致乱序问题。解决办法是用发送缓冲区控制发送。
异步发送的示例如下:
// 发送队列
std::list<Message> m_sendQueue;
void AsyncWrite()
{
auto msg = m_sendQueue.front();
async_write(m_sock, buffer(msg.pData, msg.len), boost::bind(&HandleWrite, boost::asio::placeholders:error));
}
void HandleWrite(boost:system::error_code& ec)
{
if (!ec) {
m_sendQueue.pop_front();
if (!m_sendQueue.empty()) {
AsyncWrite();
}
} else {
HandleError(ec);
if (!m_sendQueue.empty()) {
m_sendQueue.clear();
}
}
}注意:发送数据(AsyncWrite)和io_service.run()必须在同一个线程里执行。
16.4 C++11结合asio实现一个简单的服务端程序
需求:服务端监听某个端口,允许多个客户端连接上来,打印客户端发来的数据。
(1)能接收多个客户端。
考虑用一个map来管理socket,每次有新连接时,服务器自动分配一个连接号给这个连接,以方便管理。socket不允许复制,不能直接将socket放到map里,需要外面封装一层。
(2)打印客户端的数据,需要异步读数据。
为简化操作,将socket封装到一个读/写事件处理器中。这时采用同步写,异步读。
读/写事件处理器的实现如下:
#include <array>
#include <functional>
#include <iostream>
using namespace std;
#include <boost/asio.hpp>
using namespace boost::asio;
using namespace boost::asio::ip;
using namespace boost;
const int MAX_IP_PACK_SIZE = 65536;
const int HEAD_LEN = 4;
class RWHandler
{
public:
RWHandler(io_service& ios) : m_sock(ios)
{
}
~RWHandler()
{
}
void HandleRead()
{
// 异步读
async_read(m_sock, buffer(m_buff), transfer_at_least(HEAD_LEN),
[this](const boost::system::error_code& ec, size_t size) {
if (ec != nullptr) {
HandleError(ec);
return;
}
// 打印客户端发来的数据
cout << m_buff.data() + HEAD_LEN << endl;
// 循环发起异步读事件
HandleRead();
});
}
void HandleWrite(char* data, int len) {
boost::system::error_code ec;
// 同步写
write(m_sock, buffer(data, len), ec);
if (ec != nullptr) {
HandleError(ec);
}
}
tcp::socket& GetSocket()
{
return m_sock;
}
void CloseSocket()
{
boost::system::error_code ec;
m_sock.shutdown(tcp::socket::shutdown_send, ec);
m_sock.close(ec);
}
void SetConnId(int connId)
{
m_connId = connId;
}
int GetConnId() const
{
return m_connId;
}
void SetCallBackError(std::function<void(int)> f)
{
m_callbackError = f;
}
private:
void HandlerError(const boost::system::error_code& ec)
{
CloseSocket();
cout << ec.message << endl;
if (m_callbackError) {
m_callbackError(m_connId);
}
}
private:
tcp::socket m_sock;
//固定长度的读缓冲区
std::array<char, MAX_IP_PACK_SIZE> m_buff;
int m_connId;
std::function<void(int)> m_callbackError;
};
异步操作对象m_socket的生命周期没有处理,socket可能在异步回调返回之前已经释放,这时需要通过shared_from_this来保证对象的生命周期。
有了RWHandler后,服务端接受新连接后的读/写操作就交给RWHandler,服务端Server的实现如下:
#include <boost/asio/buffer.hpp>
#include <unordered_map>
#include <numeric>
#include "Message.hpp"
#include "RWHandler.hpp"
const int MaxConnectionNum = 65536;
const int MaxRecvSize = 65536;
class Server
{
public:
Server(io_service& ios, short port) : m_ios(ios), m_acceptor(ios, tcp::endpoint(tcp::v4(), port), m_cnnIdPool(MaxConnectionNum))
{
m_cnnIdPool.resize(MaxConnectionNum);
// 用顺序递增的值赋值指定范围内的元素
std::iota(m_cnnIdPool.begin(), m_cnnIdPool.end(), 1);
}
~Server()
{
}
void Accept()
{
cout << "Start Listening..." << endl;
std::shared_ptr<RWHandler> handler = CreateHandler();
m_acceptor.async_accept(handler->GetSocket(), [this, handler](const boost::system::error_code& error)
if (error)
{
cout << "error: " << error.message() << endl;
HandleAcpError(handle, error);
return ;
}
m_handlers.insert(std::make_pair(handler->GetConnId(), handler));
cout << "current connect count:" << m_handlers.size() << endl;
// 异步读
handler->HandleRead();
// 等待下一个连接
Accept();
});
}
private:
void HandlerAcpError(std::shared_ptr<RWHandler> eventHandler, const boost::system::error_code& error)
{
cout << "Error: " << error.message() << endl;
// 关闭socket,移除读写事件处理器
eventHandler->CloseSocket();
StopAccept();
}
void StopAccept()
{
boost::system::error_code ec;
m_acceptor.cancel(ec);
m_acceptor.close(ec);
m_ios.stop();
}
std::shared_ptr<RWHandler> CreateHandler()
{
int connId = m_cnnIdPool.front();
m_cnnIdPool.pop_front();
std::shared_ptr<RWHandler> handler = std::make_shared<RWHandler>(m_ios);
handler->SetConnId(connId);
handler->SetCallBackError([this](int connId){
RecyclConnid(connId);
});
}
void RecyclConnid(int connId)
{
auto it = m_handlers.find(connId);
if (it != m_handlers.end()) {
m_handlers.erase();
}
cout << "current connect count:" << m_handlers.size() << endl;
m_cnnIdPool.push_back(connId);
}
private:
io_service& m_ios;
tcp::acceptor m_acceptor;
std::unordered_map<int, std::shared_ptr<RWHandler>> m_handlers;
list<int> m_cnnIdPool;
};Server会管理所有连接的客户端。
测试程序如下:
void TestServer()
{
io_service ios;
Server server(ios, 9900);
server.Accept();
ios.run();
}循环发起异步读事件会保证io_service::run一直运行。
16.5 C++11结合asio实现一个简单的客户端程序
客户端的需求:具备读/写能力,能自动重连。
自动重连用一个线程去检测,读/写能力复用RWHandler。
客户端的实现如下:
class Connector
{
public:
Connector(io_service& ios, const string& strIP, short port) : m_ios(ios), m_socket(ios), m_serverAddr(tcp::endpoint(address::from_string(strIP), port)), m_isConnected(false), m_chkThread(nullptr)
{
CreateEventHandler(ios);
}
~Connector()
{
}
bool Start()
{
m_eventHandler->GetSocket().async_connect(m_serverAddr, [this](const boost::system::error_code& error){
if (error) {
HandleConnectError(error);
return ;
}
cout << "connect ok" << endl;
m_isConnected = true;
// 连接成功后发起一个异步读操作
m_eventHandler->HandleRead();
});
boost::this_thread::sleep(boost::posix_time::seconds(1));
return m_isConnected;
}
bool IsConnected() const
{
return m_isConnected;
}
void Send(char* data, int len)
{
if(!m_isConnected) {
return ;
}
// 同步写
m_eventHandler->HandleWrite(data, len);
}
private:
void CreateEventHandler(io_service& ios)
{
m_eventHandler = std::make_shared<RWHandler>(ios);
m_eventHandler->SetCallBackError([this](int connid){
HandleRWError(connid);
});
}
void HandleRWError(int connid)
{
m_isConnected = false;
CheckConnnect();
}
void HandleConnectError(const boost::system::error_code &error)
{
m_isConnected = false;
cout << error.message() << endl;
m_eventHandler->CloseSocket();
CheckConnect();
}
void CheckConnect()
{
if (m_chkThread != nullptr) {
return;
}
m_chkThread = std::make_shared<std::thread>([this]{
while(true) {
if(!IsConnected()) {
Start();
}
boost::this_thread::sleep(boost::posix_time::seconds(1));
}
});
}
private:
io_service& m_ios;
tcp::socket m_socket;
// 服务端地址
tcp::endpoint m_serverAddr;
std::shared_ptr<RWHandler> m_eventHandler;
bool m_isConnected;
// 专门检测重连的线程
std::shared_ptr<std::thread> m_chkThread;
};连接成功后发起了一个异步读操作,它用来判断连接是否断开,因为当连接断开时,HandleRWError会触发重连操作。
客户端的测试代码如下:
int main()
{
io_service ios;
boost::asio::io_service::work work(ios);
boost::thread thd([&ios]{
ios.run();
});
Connector conn(ios, "127.0.0.1", 9900);
conn.Start();
istring str;
if (!conn.IsConnected()) {
cin >> str;
return -1;
}
const int len = 512;
char line[len] = "";
while(cin >> str) {
char header[HEAD_LEN] = {};
// str末尾'/0'
int totalLen = str.length() + 1 + HEAD_LEN;
std::sprintf(header, "%d", totalLen);
memcpy(line, header, HEAD_LEN);
memcpy(line + HEAD_LEN, str.c_str(), str.length() + 1);
conn.Send(line, totalLen);
}
return 0;
}注意:这里通过boost::asio::io_service::work和单独线程来保证ios::run()不退出。

















 1588
1588

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









