






操作系统在历史上为观察系统软件和硬件组件提供了许多工具。对于新手来说,各种可用的工具似乎可以观察到一切,或者至少可以观察到所有重要的东西。实际上,存在许多空白,并且系统性能专家擅长于推理和解释:从间接的工具和统计数据中找出活动情况。
例如,网络数据包可以逐个检查(嗅探),但磁盘I/O却不能(至少不容易)。相反,磁盘利用率(忙碌百分比)可以轻松地通过操作系统工具观察到,但网络接口利用率却不能。
随着追踪框架的添加,特别是动态追踪,现在可以观察到一切,并且几乎可以直接观察到任何活动。这对系统性能产生了深远的影响,使得可以创建数百种新的可观测性工具(潜在数量无限)。
本章介绍了操作系统可观测性工具的类型,包括关键示例以及构建它们的框架。重点是框架,包括/proc、kstat、/sys、DTrace和SystemTap。在后面的章节中,还介绍了使用这些框架的许多其他工具,包括第6章中的Linux性能事件(LPE)和CPU。
4.1 Tool Types
性能可观测工具可以分为提供系统范围或进程级可观测性的两种类型,并且大多数基于计数器或跟踪。这些属性如图4.1所示,同时还提供了工具示例。

有些工具适用于多个象限;例如,top(1)也具有系统范围的摘要,而DTrace也具有进程级的功能。
还有一些基于性能分析的工具。这些工具通过采集一系列快照来观察活动,可以是系统范围的或者进程级的。
以下几节将总结使用计数器、跟踪和性能分析的工具,以及执行监控的工具。
4.1.1 Counters
内核维护各种统计数据,称为计数器,用于计算事件数量。它们通常实现为无符号整数,在事件发生时递增。例如,有关接收的网络数据包数量、发出的磁盘I/O和执行的系统调用都有相应的计数器。
由于计数器默认启用并由内核持续维护,因此被认为是“免费”可用的。使用计数器时唯一的额外开销是从用户空间读取其值(这个开销应该是可以忽略不计的)。下面的示例工具可读取这些系统范围或进程级的计数器值。
系统范围的工具
这些工具使用内核计数器,在系统软件或硬件资源的环境下,检查系统范围的活动。示例包括:
- vmstat:虚拟和物理内存统计,系统范围的
- mpstat:每个CPU的使用情况
- iostat:每个磁盘的I/O使用情况,从块设备接口报告
- netstat:网络接口统计信息,TCP/IP堆栈统计信息和一些连接级别的统计信息
- sar:各种统计数据;也可以将其存档以备历史报告
这些工具通常可以由系统上的所有用户(非root用户)查看。它们的统计数据通常也由监控软件绘制成图形。
许多工具都遵循一个使用约定,可以接受可选的时间间隔和输出次数,例如,vmstat(8)可以设置为每秒采样一次,输出三次结果:
$ vmstat 1 3
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
4 0 0 34455620 111396 13438564 0 0 0 5 1 2 0 0 100 0
4 0 0 34458684 111396 13438588 0 0 0 0 2223 15198 13 11 76 0
4 0 0 34456468 111396 13438588 0 0 0 0 1940 15142 15 11 74 0输出的第一行是自启动以来的总结,显示系统运行时间内的平均值。随后的行是每秒钟的摘要,显示当前的活动情况。至少,这是意图:这个Linux版本在第一行中混合了自启动以来的总结和当前值。
进程级工具
这些工具是以进程为导向,使用内核为每个进程维护的计数器。示例包括:
- ps:进程状态,显示各种进程统计数据,包括内存和CPU使用情况。
- top:显示顶部进程,按某种统计数据(如CPU使用率)排序。Solaris系统提供了prstat(1M)来实现此目的。
- pmap:列出进程内存段和使用统计信息。
这些工具通常从/proc文件系统读取统计数据。
4.1.2 Tracing
跟踪收集每个事件的数据以进行分析。跟踪框架通常不会默认启用,因为跟踪会产生CPU开销来捕获数据,可能需要大量存储空间来保存数据。这些开销可能会减缓跟踪目标,并且在解释测量时间时需要考虑到它们。
日志记录,包括系统日志,可以视为默认启用的低频跟踪。日志包括每个事件的数据,尽管通常仅限于错误和警告等不经常发生的事件。
以下是系统范围和进程范围跟踪工具的示例。
系统范围
这些跟踪工具使用内核跟踪功能,在系统软件或硬件资源的上下文中检查系统范围的活动。示例包括:
- tcpdump:网络数据包跟踪(使用libpcap)
- snoop:适用于Solaris系统的网络数据包跟踪
- blktrace:块I/O跟踪(Linux)
- iosnoop:基于DTrace的块I/O跟踪
- execsnoop:新进程跟踪(基于DTrace)
- dtruss:系统范围的缓冲系统调用跟踪(基于DTrace)
- DTrace:使用静态和动态跟踪跟踪内核内部和任何资源(不仅限于网络或块I/O)
- SystemTap:使用静态和动态跟踪跟踪内核内部和任何资源
- perf:Linux性能事件,跟踪静态和动态探针
由于DTrace和SystemTap是编程环境,因此可以在它们之上构建系统范围的跟踪工具,包括此列表中包含的一些工具。本书中提供了更多示例。
进程级别
这些跟踪工具是面向进程的,就像它们所基于的操作系统框架一样。示例包括:
- strace:用于Linux系统的系统调用跟踪
- truss:用于Solaris系统的系统调用跟踪
- gdb:源码级别的调试器,通常在Linux系统上使用
- mdb:用于Solaris系统的可扩展调试器
调试器可以检查每个事件的数据,但必须通过停止和启动目标的执行来实现。
诸如DTrace、SystemTap和perf之类的工具都支持一种仅能检查单个进程的执行模式,尽管更适合描述为系统范围的工具。
4.1.3 Profiling
性能分析是通过收集一组样本或快照来描述目标的行为。CPU使用率是一个常见的示例,其中采用程序计数器或堆栈跟踪的样本来描述消耗CPU周期的代码路径。这些样本通常以固定的速率收集,例如每秒100次或1000次(赫兹)。性能分析工具或分析器有时会稍微改变此速率,以避免与目标活动同步采样,这可能导致过多或过少计数。
性能分析还可以基于无时间限制的硬件事件,例如CPU硬件缓存失效或总线活动。它还可以显示哪些代码路径是负责的,这些信息可以帮助开发人员优化其代码以更好地利用系统资源。
以下是一些性能分析器的示例,它们都执行基于计时器和硬件缓存的分析:
- oprofile:Linux系统性能分析
- perf:Linux性能工具包,包括性能分析子命令
- DTrace:编程性能分析,基于计时器使用其profile提供程序,基于硬件事件使用其cpc提供程序
- SystemTap:编程性能分析,基于计时器使用其timer tapset,基于硬件事件使用其perf tapset
- cachegrind:来自valgrind工具包,可以分析硬件缓存使用情况,并可使用kcachegrind进行可视化
- Intel VTune Amplifier XE:用于Linux和Windows的性能分析,具有包括源代码浏览在内的图形界面
- Oracle Solaris Studio:用于Solaris和Linux的性能分析,包括具有源代码浏览功能的性能分析工具
编程语言通常具有自己的特定目的的分析器,可以检查语言上下文。
有关性能分析工具的更多信息,请参阅第6章《CPU》。
4.1.4 Monitoring (sar)
监控是在第二章“方法论”中介绍的。监视单个操作系统主机最常用的工具是源自AT&T Unix的系统活动报告器sar(1)。sar(1)是基于计数器的,具有代理程序,可以在预定时间(通过cron)执行以记录系统计数器的状态。sar(1)工具允许这些计数器在命令行中查看,例如:
# sar
Linux 3.2.6-3.fc16.x86_64 (web100) 04/15/2013 _x86_64_ (16 CPU)
05:00:00 CPU %user %nice %system %iowait %steal %idle
05:10:00 all 12.61 0.00 4.58 0.00 0.00 82.80
05:20:00 all 21.62 0.00 9.59 0.93 0.00 67.86
05:30:00 all 23.65 0.00 9.61 3.58 0.00 63.17
05:40:00 all 28.95 0.00 8.96 0.04 0.00 62.05
05:50:00 all 29.54 0.00 9.32 0.19 0.00 60.95
Average: all 23.27 0.00 8.41 0.95 0.00 67.37默认情况下,sar(1)会读取其统计存档(如果启用)以打印最近的历史统计数据。您可以为其指定可选的间隔和计数,以便按指定的速率检查当前活动。
关于sar(1)的具体用法在本书的后面章节中有描述,可参考第6、7、8、9和10章。附录C是sar(1)选项的摘要。
尽管sar(1)可以报告许多统计数据,但可能没有涵盖您实际所需的所有内容,并且它提供的统计数据有时会误导(特别是在基于Solaris的系统上[McDougall 06b])。已经开发出了一些替代方案,例如System Data Recorder和Collectl。
在Linux中,通过sysstat软件包提供了sar(1)。第三方监控产品通常是基于sar(1)或使用相同的可观察性统计数据构建的。
4.2 Observability Sources
接下来的几节描述了提供可观察工具所需的统计数据和数据的各种接口和框架。它们在表4.1中进行了总结。
接下来介绍了系统性能统计的主要来源:/proc、/sys和kstat。然后介绍了延迟账户和微状态账户,并对其他来源进行了总结。在这些内容之后,介绍了基于其中一些框架构建的DTrace和SystemTap工具。

4.2.1 /proc
这是一个用于内核统计的文件系统接口。/proc目录包含许多子目录,每个子目录以其所代表的进程的进程ID命名。这些目录包含一些文件,其中包含从内核数据结构映射而来的有关每个进程的信息和统计数据。在Linux上,/proc还包含用于系统范围统计的其他文件。
/proc由内核动态创建,不依赖于存储设备(它在内存中运行)。它主要是只读的,为可观察性工具提供统计数据。一些文件是可写的,用于控制进程和内核行为。
文件系统接口非常方便:它通过目录树直观地向用户空间公开内核统计数据,并通过POSIX文件系统调用(open()、read()、close())具有众所周知的编程接口。文件系统还通过使用文件访问权限提供用户级安全性。
以下示例展示了如何使用top(1)和strace(1)读取每个进程的统计数据:
stat("/proc/14704", {st_mode=S_IFDIR|0555, st_size=0, ...}) = 0
open("/proc/14704/stat", O_RDONLY) = 4
read(4, "14704 (sshd) S 1 14704 14704 0 -"..., 1023) = 232
close(4)这打开了一个名为“stat”的文件,该文件位于以进程ID命名的目录中,然后读取了文件内容。top(1)会为系统上的所有活动进程重复执行此操作。在某些系统上(特别是进程众多的系统),执行这些操作的开销可能会变得明显,特别是对于在每个屏幕更新时针对每个进程重复执行此序列的top(1)版本。这可能会导致top(1)报告top(1)本身是最高的CPU消耗者!
在Linux上,/proc的文件系统类型为“proc”,在基于Solaris的系统上,则为“procfs”。
Linux
/proc提供了各种用于每个进程统计数据的文件。以下是可能可用的一些示例:
ls -F /proc/28712
attr/ cpuset io mountinfo oom_score sessionid syscall
auxv cwd@ latency mounts pagemap smaps task/
cgroup environ limits mountstats personality stack wchan
clear_refs exe@ loginuid net/ root@ stat
cmdline fd/ maps numa_maps sched statm
coredump_filter fdinfo/ mem oom_adj schedstat status可用文件的确切列表取决于内核版本和配置选项。
与每个进程的性能可观察性相关的文件包括:
- limits:生效的资源限制
- maps:映射的内存区域
- sched:各种CPU调度器统计信息
- schedstat:CPU运行时间、延迟和时间片
- smaps:带有使用统计的映射内存区域
- stat:进程状态和统计信息,包括总CPU和内存使用情况
- statm:以页为单位的内存使用摘要
- status:可读性强的stat和statm信息
- task:每个任务统计的目录
Linux还扩展了/proc,包含系统范围的统计信息,这些信息在以下附加文件和目录中:
cd /proc; ls -Fd [a-z]*
acpi/ dma kallsyms mdstat schedstat timer_list
buddyinfo driver/ kcore meminfo scsi/ timer_stats
bus/ execdomains keys misc self@ tty/
cgroups fb key-users modules slabinfo uptime
cmdline filesystems kmsg mounts@ softirqs version
consoles fs/ kpagecount mtrr stat vmallocinfo
cpuinfo interrupts kpageflags net@ swaps vmstat
crypto iomem latency_stats pagetypeinfo sys/ zoneinfo
devices ioports loadavg partitions sysrq-trigger
diskstats irq/ locks sched_debug sysvipc/与性能可观察性相关的系统范围文件包括:
- cpuinfo:物理处理器信息,包括每个虚拟CPU、型号名称、时钟速度和缓存大小。
- diskstats:所有磁盘设备的磁盘I/O统计信息
- interrupts:每个CPU的中断计数器
- loadavg:负载平均值
- meminfo:系统内存使用情况分解
- net/dev:网络接口统计信息
- net/tcp:活动TCP套接字信息
- schedstat:系统范围的CPU调度器统计信息
- self:指向当前进程ID目录的符号链接,以方便使用
- slabinfo:内核slab分配器高速缓存统计信息
- stat:内核和系统资源统计摘要:CPU、磁盘、分页、交换、进程
- zoneinfo:内存区域信息
这些文件由系统范围的工具读取。例如,这里是vmstat(8)通过strace(1)跟踪读取/proc的示例:
open("/proc/meminfo", O_RDONLY) = 3
lseek(3, 0, SEEK_SET) = 0
read(3, "MemTotal: 889484 kB\nMemF"..., 2047) = 1170
open("/proc/stat", O_RDONLY) = 4
read(4, "cpu 14901 0 18094 102149804 131"..., 65535) = 804
open("/proc/vmstat", O_RDONLY) = 5
lseek(5, 0, SEEK_SET) = 0
read(5, "nr_free_pages 160568\nnr_inactive"..., 2047) = 1998/proc文件通常是以文本格式进行格式化的,这使得它们可以轻松地从命令行中读取并通过shell脚本工具进行处理。例如:
cat /proc/meminfo
MemTotal: 889484 kB
MemFree: 636908 kB
Buffers: 125684 kB
Cached: 63944 kB
SwapCached: 0 kB
Active: 119168 kB
[...]
$ grep Mem /proc/meminfo
MemTotal: 889484 kB
MemFree: 636908 kB虽然这很方便,但内核编码统计信息为文本以及任何处理该文本的用户空间工具都会增加开销。/proc的内容在proc(5)手册页和Linux内核文档中有详细说明:Documentation/filesystems/proc.txt。部分内容有扩展文档,比如Documentation/iostats.txt中的diskstats和Documentation/scheduler/sched-stats.txt中的调度器统计信息。除了文档,您还可以研究内核源代码,了解/proc中所有项目的确切来源。阅读消费这些信息的工具的源代码也可能会有所帮助。
一些/proc条目取决于CONFIG选项:使用CONFIG_SCHEDSTATS启用schedstats,使用CONFIG_SCHED_DEBUG启用sched。
Solaris
在基于Solaris的系统中,/proc仅包含进程状态统计信息。系统范围的可观察性通过其他框架提供,主要是kstat。
以下是/proc进程目录中的文件列表:
ls -F /proc/22449
as cred fd/ lstatus map path/ rmap status xmap
auxv ctl ldt lusage object/ priv root@ usage
contracts/ cwd@ lpsinfo lwp/ pagedata psinfo sigact watch与性能可观察性相关的文件包括:
- map:虚拟地址空间映射
- psinfo:各种进程信息,包括CPU和内存使用情况
- status:进程状态信息
- usage:扩展的进程活动统计信息,包括进程微状态、故障、阻塞、上下文切换和系统调用计数器
- lstatus:类似于status,但包含每个线程的统计信息
- lpsinfo:类似于psinfo,但包含每个线程的统计信息
- lusage:类似于usage,但包含每个线程的统计信息
- lwpsinfo:代表LWP(当前最活跃的轻量级进程)的轻量级进程(线程)统计信息;还有lwpstatus和lwpsinfo文件
- xmap:扩展的内存映射统计信息(未记录)
以下是truss(1)输出显示prstat(1M)读取进程状态的示例:
open("/proc/4363/psinfo", O_RDONLY) = 5
pread(5, "01\0\0\001\0\0\0\v11\0\0".., 416, 0) = 416这些文件的格式是二进制的,如上方的pread()数据所示。psinfo包含了以下信息:
typedef struct psinfo {
int pr_flag; /* process flags (DEPRECATED: see below) */
int pr_nlwp; /* number of active lwps in the process */
int pr_nzomb; /* number of zombie lwps in the process */
pid_t pr_pid; /* process id */
pid_t pr_ppid; /* process id of parent */
pid_t pr_pgid; /* process id of process group leader */
pid_t pr_sid; /* session id */
uid_t pr_uid; /* real user id */
uid_t pr_euid; /* effective user id */
gid_t pr_gid; /* real group id */
gid_t pr_egid; /* effective group id */
uintptr_t pr_addr; /* address of process */
size_t pr_size; /* size of process image in Kbytes */
size_t pr_rssize; /* resident set size in Kbytes */
dev_t pr_ttydev; /* controlling tty device (or PRNODEV) */
ushort_t pr_pctcpu; /* % of recent cpu time used by all lwps */
ushort_t pr_pctmem; /* % of system memory used by process */
timestruc_t pr_start; /* process start time, from the epoch */
timestruc_t pr_time; /* cpu time for this process */
timestruc_t pr_ctime; /* cpu time for reaped children */
char pr_fname[PRFNSZ]; /* name of exec'ed file */
char pr_psargs[PRARGSZ]; /* initial characters of arg list */
int pr_wstat; /* if zombie, the wait() status */
int pr_argc; /* initial argument count */
uintptr_t pr_argv; /* address of initial argument vector */
uintptr_t pr_envp; /* address of initial environment vector */
char pr_dmodel; /* data model of the process */
lwpsinfo_t pr_lwp; /* information for representative lwp */
taskid_t pr_taskid; /* task id */
projid_t pr_projid; /* project id */
poolid_t pr_poolid; /* pool id */
zoneid_t pr_zoneid; /* zone id */
ctid_t pr_contract; /* process contract id */
} psinfo_t;可以直接将这些数据读取到用户空间中的psinfo_t变量中,然后可以通过解引用来访问成员。这使得Solaris的/proc更适合用C语言编写的程序进行处理,这些程序可以包含系统提供的头文件中的结构定义。
/proc的相关信息可以在proc(4)手册页和sys/procfs.h头文件中找到。与Linux一样,如果内核是开源的,研究这些统计信息的来源以及工具如何消费它们可能会有所帮助。
lxproc
在基于Solaris的系统中,有时需要类似Linux的/proc文件系统。原因之一是为了移植Linux的可观察性工具(例如htop(1)),否则由于/proc的差异,移植可能会变得困难:从基于文本的界面到二进制界面。
其中一个解决方案是使用lxproc文件系统:它为基于Solaris的系统提供了与Linux部分兼容的/proc,并可以与标准的procfs /proc并行挂载。例如,可以将lxproc挂载在/lxproc上,需要类似Linux的/proc的应用程序可以修改为从/lxproc加载进程信息,而不是/proc——这应该只是一个小的改动。
smartos# more /lxproc/meminfo
total: used: free: shared: buffers: cached:
Mem: 1073741824 88395776 985346048 0 0 0
Swap: 2147483648 267640832 1879842816
MemTotal: 1048576 kB
MemFree: 962252 kB
[...]就像Linux的/proc一样,每个进程也有相应的目录,其中包含进程信息。
lxproc可能是不完整的,并且可能需要进行添加:它仅作为简单的Linux /proc用户的尽力而为的接口提供。
4.2.2 /sys
Linux提供了一个sysfs文件系统,挂载在/sys上,它是从2.6内核开始引入的,为内核统计信息提供了一个基于目录的结构。这与/proc不同,后者随着时间的推移不断发展,并在顶级目录中添加了各种系统统计信息。sysfs最初是为了提供设备驱动程序的统计信息而设计的,但已扩展到包括任何类型的统计信息。
例如,以下列出了CPU 0的/sys文件(已截断):
find /sys/devices/system/cpu/cpu0 -type f
/sys/devices/system/cpu/cpu0/crash_notes
/sys/devices/system/cpu/cpu0/cache/index0/type
/sys/devices/system/cpu/cpu0/cache/index0/level
/sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size
/sys/devices/system/cpu/cpu0/cache/index0/physical_line_partition
/sys/devices/system/cpu/cpu0/cache/index0/ways_of_associativity
/sys/devices/system/cpu/cpu0/cache/index0/number_of_sets
/sys/devices/system/cpu/cpu0/cache/index0/size
/sys/devices/system/cpu/cpu0/cache/index0/shared_cpu_map
/sys/devices/system/cpu/cpu0/cache/index0/shared_cpu_list
[...]
/sys/devices/system/cpu/cpu0/topology/physical_package_id
/sys/devices/system/cpu/cpu0/topology/core_id
/sys/devices/system/cpu/cpu0/topology/thread_siblings
/sys/devices/system/cpu/cpu0/topology/thread_siblings_list
/sys/devices/system/cpu/cpu0/topology/core_siblings
/sys/devices/system/cpu/cpu0/topology/core_siblings_list其中许多提供有关CPU硬件缓存的信息。以下输出显示了它们的内容(使用grep(1),以便输出中包含文件名):
$ grep . /sys/devices/system/cpu/cpu0/cache/index*/level
/sys/devices/system/cpu/cpu0/cache/index0/level:1
/sys/devices/system/cpu/cpu0/cache/index1/level:1
/sys/devices/system/cpu/cpu0/cache/index2/level:2
/sys/devices/system/cpu/cpu0/cache/index3/level:3
$ grep . /sys/devices/system/cpu/cpu0/cache/index*/size
/sys/devices/system/cpu/cpu0/cache/index0/size:32K
/sys/devices/system/cpu/cpu0/cache/index1/size:32K
/sys/devices/system/cpu/cpu0/cache/index2/size:256K
/sys/devices/system/cpu/cpu0/cache/index3/size:8192K这显示CPU 0可以访问两个32 K字节的一级缓存,一个256 K字节的二级缓存和一个8 M字节的三级缓存。
/sys文件系统通常有成千上万个只读文件中的统计信息,还有许多可写文件用于更改内核状态。例如,通过向名为“online”的文件写入“1”或“0”,可以将CPU设置为在线或离线状态。与读取统计信息一样,设置状态可以通过在命令行中使用文本字符串(echo 1 > filename)而不是二进制接口进行。
4.2.3 kstat
基于Solaris的系统拥有一个用于系统范围的可观测性工具的内核统计(kstat)框架。kstat包括大多数资源的统计信息,包括CPU、磁盘、网络接口、内存以及内核中的许多软件组件。一个典型的系统可以从kstat获得成千上万个统计信息。
与/proc或/sys不同,kstat没有伪文件系统,并且通过ioctl()从/dev/kstat读取。通常通过libkstat库提供的便利函数或Sun::Solaris::Kstat进行操作,后者是用于相同目的的Perl库(尽管在某些发行版中正在逐步淘汰libkstat)。kstat(1M)工具提供了命令行上的统计信息,并可与shell脚本一起使用。
kstats结构化为四元组:
module:instance:name:statistic这些是:
模块(module):通常指创建该统计信息的内核模块,比如SCSI磁盘驱动程序的sd模块,或ZFS文件系统的zfs模块。
实例(instance):某些模块存在多个实例,例如每个SCSI磁盘的sd模块。实例是一个枚举值。
名称(name):这是统计信息的分组名称。
统计信息(statistic):这是单个统计信息的名称。例如,以下使用kstat(1M)读取nproc统计信息,并指定完整的四元组:
$ kstat -p unix:0:system_misc:nproc
unix:0:system_misc:nproc 94该统计信息显示当前正在运行的进程数量。使用kstat(1M)的-p选项打印可解析输出(以冒号分隔)。空字段被视为通配符。尾随冒号也可以省略。这些规则结合在一起,允许以下命令匹配并打印系统_misc组中的所有统计信息:
$ kstat -p unix:0:system_misc
unix:0:system_misc:avenrun_15min 201
unix:0:system_misc:avenrun_1min 383
unix:0:system_misc:avenrun_5min 260
unix:0:system_misc:boot_time 1335893569
unix:0:system_misc:class misc
unix:0:system_misc:clk_intr 1560476763
unix:0:system_misc:crtime 0
unix:0:system_misc:deficit 0
unix:0:system_misc:lbolt 1560476763
unix:0:system_misc:ncpus 2
unix:0:system_misc:nproc 94
unix:0:system_misc:snaptime 15604804.5606589
unix:0:system_misc:vac 0avenrun*统计信息用于计算系统负载平均值,由包括uptime(1)和top(1)在内的工具报告。
kstat中的许多统计信息是累计的。它们不提供当前值,而是显示自启动以来的总计。
这个freemem统计信息以每秒空闲页的数量递增。这样可以计算出时间间隔内的平均值。许多系统范围的可观测性工具打印的自启动以来的摘要也可以通过将当前值除以自启动以来的秒数来计算。
另一个版本的freemem提供了即时值(unix:0:system_pages:freemem)。这弥补了累积版本的不足之处:至少需要一秒钟才能知道当前值,因此这将是可以计算增量的最小时间。
没有任何统计名称,kstat(1M)会列出所有统计信息。例如,以下命令将所有统计信息的列表传输到grep(1)中搜索包含freemem的统计信息,然后使用wc(1)计算总统计数量:
$ kstat -p | grep freemem
unix:0:system_pages:freemem 5962178
unix:0:vminfo:freemem 184893612065859
$ kstat -p | wc -l
33195kstat统计信息没有正式文档记录,因为它们被认为是不稳定的接口——每当内核更改时就会发生变化。为了理解每个统计信息的作用,可以研究增加它们的位置在内核源代码中的实现(如果可用)。例如,累计freemem统计信息源自以下内核代码:
usr/src/uts/common/sys/sysinfo.h:
typedef struct vminfo { /* (update freq) update action */
uint64_t freemem; /* (1 sec) += freemem in pages */
uint64_t swap_resv; /* (1 sec) += reserved swap in pages */
uint64_t swap_alloc; /* (1 sec) += allocated swap in pages */
uint64_t swap_avail; /* (1 sec) += unreserved swap in pages */
uint64_t swap_free; /* (1 sec) += unallocated swap in pages */
uint64_t updates; /* (1 sec) ++ */
} vminfo_t;
usr/src/uts/common/os/space.c:
vminfo_t vminfo; /* VM stats protected by sysinfolock mutex */
usr/src/uts/common/os/clock.c:
static void clock(void)
{
[...]
if (one_sec) {
[...]
vminfo.freemem += freemem;freemem统计信息是由内核中的clock()例程每秒递增一次,其值由名为freemem的全局变量确定。可以检查修改freemem的位置以查看所有涉及的代码。
还可以研究现有系统工具的源代码(如果可用),以了解kstat使用的示例。
4.2.4 Delay Accounting
具有CONFIG_TASK_DELAY_ACCT选项的Linux系统跟踪每个任务在以下状态下的时间:
调度延迟:等待轮到使用CPU
阻塞I/O:等待块I/O完成
交换:等待分页(内存压力)
内存回收:等待内存回收例程
从技术上讲,调度延迟统计信息来自schedstats(早期在/proc中提到),但与其他延迟记账状态一起公开。 (它在struct sched_info中,而不是struct task_delay_info中。)
这些统计信息可以通过使用taskstats读取用户级工具来读取,taskstats是一种基于netlink的接口,用于获取每个任务和进程的统计信息。 内核源代码Documentation / accounting目录中有文档delay-accounting.txt和示例消费者getdelays.c:
$ ./getdelays -dp 17451
print delayacct stats ON
PID 17451
CPU count real total virtual total delay total delay average
386 3452475144 31387115236 1253300657 3.247ms
IO count delay total delay average
302 1535758266 5ms
SWAP count delay total delay average
0 0 0ms
RECLAIM count delay total delay average
0 0 0ms除非另有说明,否则时间单位为纳秒。此示例来自一个CPU负载较重的系统,并且正在检查的进程正在遭受调度延迟。
4.2.5 Microstate Accounting
基于Solaris的系统具有每个线程和每个CPU微状态记账,记录预定义状态的一组高分辨率时间。与先前基于tick的指标相比,这些指标大大提高了准确性,并提供了额外的状态以进行性能分析[MCDougall 06b]。它们通过kstat对用户级工具公开,以获取每个CPU指标和/proc以获取每个线程指标。
CPU微状态显示为mpstat(1M)的usr、sys和idl列(请参见第6章CPU)。您可以在内核代码中找到它们,例如CMS_USER、CMS_SYSTEM和CMS_IDLE。
线程微状态可见于prstat -m的USR、SYS等列,并在第6章CPU的6.6.7节prstat中进行了总结。
4.2.6 Other Observability Sources
其他各种可观察性来源包括:
CPU性能计数器:这些是可编程的硬件寄存器,提供低级性能信息,包括CPU周期计数、指令计数、停顿周期等等。在Linux上,它们通过perf_events接口和perf_event_open()系统调用进行访问,并被包括perf(1)在内的工具使用。在基于Solaris的系统上,它们通过libcpc进行访问,并由包括cpustat(1M)在内的工具使用。有关这些计数器和工具的更多信息,请参见第6章CPU。
进程级跟踪:这会跟踪用户级软件事件,例如系统调用和函数调用。通常执行起来很昂贵,会减慢目标速度。在Linux上,有ptrace()系统调用来控制进程跟踪,它被strace(1)用于跟踪系统调用。Linux还具有uprobes用于用户级动态跟踪。基于Solaris的系统使用procfs和truss(1)工具跟踪系统调用,并使用DTrace进行动态跟踪。
内核跟踪:在Linux上,tracepoints提供静态内核探针(最初为内核制造者),而kprobes提供动态探针。这两者都被追踪工具如ftrace、perf(1)、DTrace和SystemTap所使用。在基于Solaris的系统上,dtrace内核模块提供静态和动态探针。DTrace和SystemTap都是内核跟踪的消费者,在接下来的章节中将介绍静态和动态探针的术语解释。
网络抓包:这些接口提供了一种从网络设备捕获数据包进行详细研究的方式,以分析数据包和协议性能。在Linux上,通过libpcap库和/proc/net/dev实现抓包功能,并由tcpdump(8)工具使用。在基于Solaris的系统上,通过libdlpi库和/dev/net实现抓包功能,并由snoop(1M)工具使用。也为基于Solaris的系统开发了libpcap和tcpdump(8)的移植版本。捕获和检查所有数据包会带来CPU和存储开销。有关网络抓包的更多信息,请参见第10章"网络"。
进程账户:这一概念可以追溯到大型机时代,用于根据进程的执行和运行时间为部门和用户计费。Linux和基于Solaris的系统都以某种形式存在进程账户,并且在进程级别的性能分析中有时会很有帮助。例如,atop(1)工具使用进程账户来捕获并显示短生命周期进程的信息,否则在快照/proc时可能会被忽略。
系统调用:某些系统或库调用可提供一些性能指标。其中包括getrusage()函数调用,用于进程获取自身的资源使用统计信息,包括用户时间、系统时间、故障、消息和上下文切换。基于Solaris的系统还具有swapctl()系统函数,用于交换设备管理和统计(Linux中为/proc/swap)。如果您对每个接口的工作原理感兴趣,通常可以找到相关文档,这些文档是面向在这些接口上构建工具的开发人员编写的。
And More
根据您的内核版本和启用的选项,可能还会提供更多的可观察性源。一些在本书的后面章节中提到过。以下是一些例子:
Linux: I/O账户、blktrace、timer_stats、lockstat、debugfs
Solaris: 扩展账户、流量账户、Solaris审计
查找这些源的一种技术是阅读您感兴趣的内核代码,并查看是否在其中放置了统计信息或跟踪点。
在某些情况下,您可能无法获取您所需的内核统计信息。除了接下来介绍的动态跟踪之外,您可能会发现调试器可以获取内核变量以解决问题。其中包括gdb(1)和mdb(1)(仅适用于Solaris)。一种类似但更为困难的方法是通过打开/dev/mem或/dev/kmem直接读取内核内存的工具。
不同接口的多个可观察性源可能会增加学习负担,并且当它们的功能重叠时可能效率低下。由于DTrace自2003年起成为Solaris内核的一部分,已经有努力将一些旧的跟踪框架移植到DTrace,并从中满足所有新的跟踪需求。这种整合工作非常成功,并简化了基于Solaris的系统的跟踪。我们可以希望这种趋势继续下去,未来的内核将提供更少但更强大的可观察性框架。
4.3 Dtrace
DTrace是一个包含编程语言和工具的可观察性框架。本节概述了DTrace的基础知识,包括动态和静态跟踪、探针、提供者、D语言、动作、变量、一行脚本和脚本编写。它旨在作为DTrace入门指南,为您提供足够的背景,以便在本书后面理解其在基于Solaris和Linux的系统上扩展性能可观察性的使用。
DTrace可以通过称为探针的插装点观察所有用户级和内核级代码。当探针被触发时,可以在其D语言中执行任意操作。操作可以包括计数事件、记录时间戳、执行计算、打印值和汇总数据。这些操作可以在实时跟踪仍然启用的情况下执行。
以下是使用DTrace进行动态跟踪的示例,此示例对内核ZFS(文件系统)spa_sync()函数进行了插装,显示了完成时间和持续时间(单位为纳秒)(illumos kernel):
# dtrace -n 'fbt:zfs:spa_sync:entry { self->start = timestamp; }
fbt:zfs:spa_sync:return /self->start/ { printf("%Y: %d ns",
walltimestamp, timestamp - self->start); self->start = 0; }'
dtrace: description 'fbt:zfs:spa_sync:entry ' matched 2 probes
CPU ID FUNCTION:NAME
7 65353 spa_sync:return 2012 Oct 30 00:20:27: 63849335 ns
12 65353 spa_sync:return 2012 Oct 30 00:20:32: 39754457 ns
18 65353 spa_sync:return 2012 Oct 30 00:20:37: 261013562 ns
8 65353 spa_sync:return 2012 Oct 30 00:20:42: 29800786 ns
17 65353 spa_sync:return 2012 Oct 30 00:20:47: 250368664 ns
20 65353 spa_sync:return 2012 Oct 30 00:20:52: 37450783 ns
11 65353 spa_sync:return 2012 Oct 30 00:20:57: 56010162 ns
[...]spa_sync()函数将写入的数据刷新到ZFS存储设备,导致磁盘I/O的突发。它在性能分析中特别受关注,因为I/O有时可能会排队等待已发出的磁盘I/O。使用DTrace,可以立即查看和研究spa_sync()触发的频率和持续时间的信息。可以以类似的方式研究其他数千个内核函数,无论是打印每个事件的详细信息还是对其进行汇总。
DTrace与其他跟踪框架(例如系统调用跟踪)的一个关键区别在于,DTrace被设计为在生产环境中安全可靠,并且性能开销最小化。它通过使用每个CPU的内核缓冲区来实现这一点,从而改善内存本地性,减少缓存一致性开销,并且可以消除同步锁的需要。这些缓冲区还用于以温和的速率(默认情况下每秒一次)向用户空间传递数据,从而最小化上下文切换。DTrace还提供了一组在内核中汇总和过滤数据的操作,也可以减少数据开销。
DTrace支持静态和动态跟踪,每种跟踪方式都提供互补的功能。静态探针具有文档化和稳定的接口,而动态探针可以根据需要提供几乎无限的可观察性。
4.3.1 Static and Dynamic Tracing
理解静态和动态跟踪的一种方法是查看涉及的源代码和CPU指令。考虑以下来自内核块设备接口(illumos)的代码,路径为usr/src/uts/common/os/bio.c:
/*
* Mark I/O complete on a buffer, release it if I/O is asynchronous,
* and wake up anyone waiting for it.
*/
void
biodone(struct buf *bp)
{
if (bp->b_flags & B_STARTED) {
DTRACE_IO1(done, struct buf *, bp);
bp->b_flags &= ~B_STARTED;
}
[...]DTRACE_IO1宏是静态探针的一个示例,它在编译之前添加到代码中。源代码中没有动态探针的可见示例,因为这些探针是在软件运行时编译之后添加的。此函数的已编译指令如下(截断):
> biodone::dis
biodone: pushq %rbp
biodone+1: movq %rsp,%rbp
biodone+4: subq $0x20,%rsp
biodone+8: movq %rbx,-0x18(%rbp)
biodone+0xc: movq %rdi,-0x8(%rbp)
biodone+0x10: movq %rdi,%rbx
biodone+0x13: movl (%rdi),%eax
biodone+0x15: testl $0x2000000,%eax
[...]当使用动态跟踪来探测进入biodone()函数时,第一条指令会被改变:
> biodone::dis
biodone: int $0x3
biodone+1: movq %rsp,%rbp
biodone+4: subq $0x20,%rsp
biodone+8: movq %rbx,-0x18(%rbp)
biodone+0xc: movq %rdi,-0x8(%rbp)
biodone+0x10: movq %rdi,%rbx
biodone+0x13: movl (%rdi),%eax
biodone+0x15: testl $0x2000000,%eax
[...]int指令调用软中断,该软中断被编程以执行动态跟踪操作。当禁用动态跟踪时,该指令将恢复到原始状态。这是对内核地址空间进行现场修补的技术,使用的技术可能因处理器类型而异。
只有在启用动态跟踪时才会添加指令。当未启用时,没有额外的指令用于仪器化,因此也没有探测效果。这被描述为不使用时的零开销。当使用时,由于额外的指令,开销与探测事件的触发速率成比例:即被跟踪事件的速率以及它们执行的操作。
DTrace可以动态跟踪函数的进入和返回,以及用户空间中的任何指令。由于它根据CPU指令动态构建探针,而不同软件版本之间的CPU指令可能有所不同,因此被视为不稳定的接口。基于动态跟踪的任何DTrace一行命令或脚本可能需要更新,以适应其跟踪的较新软件版本。
4.3.2 Probes
DTrace探针以四元组命名:
provider:module:function:name提供者是相关探针的集合,类似于软件库。模块和函数是动态生成的,并指定了探针的代码位置。名称是探针本身的名称。
在指定这些时,可以使用通配符(“*”)。将字段留空(“::”)等同于通配符(“:*:”)。还可以从探针规范中删除留空的字段(例如,“:::BEGIN” == “BEGIN”)。
例如:
io:::start这是来自io提供者的start探针。模块和函数字段留空,因此它们将匹配start探针的所有位置。
4.3.3 Providers
可用的DTrace提供者取决于您的DTrace和操作系统版本。它们可能包括:
- syscall:系统调用陷阱表
- vminfo:虚拟内存统计信息
- sysinfo:系统统计信息
- profile:在任意速率下进行采样
- sched:内核调度事件
- proc:进程级事件:创建、执行、退出
- io:块设备接口跟踪(磁盘I/O)
- pid:用户级动态追踪
- tcp:TCP协议事件:连接、发送和接收
- ip:IP协议事件:发送和接收
- fbt:内核级动态跟踪
还有许多用于高级语言的其他提供者:Java、JavaScript、Node.js、Perl、Python、Ruby、Tcl等。
许多提供者使用静态跟踪实现,因此它们具有稳定的接口。在可能的情况下,最好使用这些(而不是动态跟踪),以便您的脚本适用于目标软件的不同版本。这种权衡是可见性相对较低,因为只有必要的内容提升到稳定的接口,以最小化维护和文档负担。
4.3.4 Arguments
探针可以通过一组称为参数的变量提供数据。参数的使用取决于提供者。
例如,syscall提供者为每个系统调用提供了入口和返回探针。它们设置以下参数变量:
入口:arg0,...,argN:系统调用的参数
返回:arg0或arg1:返回值;同时设置errno
fbt和pid提供者以类似的方式设置参数,允许检查传递给内核或用户级函数的数据以及返回的数据。
要了解每个提供者的参数是什么,可以参考其文档(也可以尝试使用带有-lv选项的dtrace(1),它会打印一个摘要)。
4.3.5 D Language
D语言类似于awk,可以用于单行命令或脚本(与awk相同)。DTrace语句的形式为
probe_description /predicate/ { action }动作是一系列可选的分号分隔的语句,当探针触发时执行。谓词是一个可选的过滤表达式。例如,语句
proc:::exec-success /execname == "httpd"/ { trace(pid); }跟踪proc提供者中的exec-success探针,并在进程名称等于"httpd"时执行打印动作trace(pid)。exec-success探针通常用于跟踪新进程的创建,并记录成功的exec()系统调用。使用内置变量execname获取当前进程名称,使用pid获取当前进程ID。
4.3.6 Built-in Variables
内置变量可用于计算和谓词,并可以使用trace()和printf()等动作进行打印。常用的内置变量列在表4.2中。

4.3.7 Actions
常用的动作包括表4.3中列出的动作。
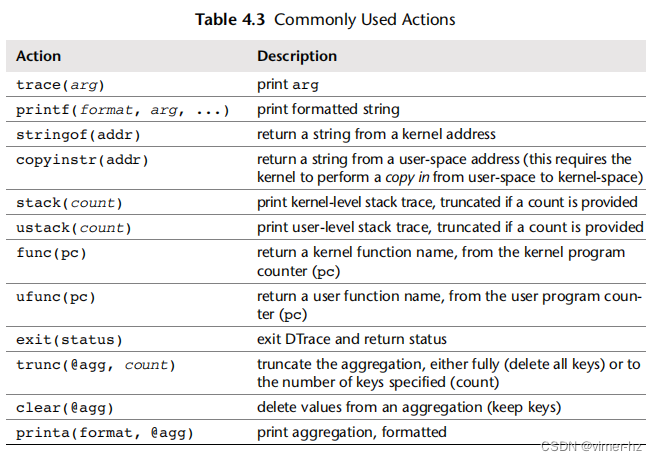
列出的最后三个动作是用于一种特殊变量类型,称为聚合。
4.3.8 Variable Types
表4.4总结了变量的类型,按照使用偏好的顺序列出(首选聚合变量,然后是开销从低到高的变量)。

线程本地变量具有每个线程范围。这允许将数据(如时间戳)与线程轻松关联起来。
语句本地变量用于中间计算,仅在相同探针描述的动作语句中有效。
多个CPU同时写入同一个标量变量可能导致变量状态损坏,因此会显示“no”。尽管这种情况不太可能发生,但确实发生过,并且已经注意到对字符串标量的影响(导致字符串损坏)。
聚合是一种特殊的变量类型,可以按CPU进行累积,并在以后进行组合以传递给用户空间。它们具有最低的开销,并用于以不同方式汇总数据。
填充聚合的动作列在表4.5中。


作为聚合和直方图动作quantize()的示例,以下显示了read()系统调用返回的大小:

这个一行代码在跟踪时收集统计信息,并在dtrace结束时打印摘要,本例中是当键入Ctrl-C时。输出的第一行"dtrace: description . . ."是dtrace默认打印的,表示跟踪已经开始。
value列是量化范围的最小大小,count列是该范围内的出现次数。中间显示了分布的ASCII表示。在这种情况下,最常返回的大小为零字节,共发生447次。许多返回的读取大小在8,192到131,071字节之间,其中170次在16,384到32,767范围内。这种双峰分布在只报告平均值的工具中不会被注意到。
4.3.9 One-Liners
DTrace允许您编写简洁而强大的一行命令,就像我之前演示的那样。以下是更多的例子。
跟踪open()系统调用,打印进程名称和文件路径名:
dtrace -n 'syscall::open:entry { printf("%s %s", execname, copyinstr(arg0)); }'请注意,Oracle Solaris 11显着修改了系统调用陷阱表(由DTrace探测以创建syscall提供程序),因此在该系统上跟踪open()变得更加复杂。
dtrace -n 'syscall::openat:entry { printf("%s %s", execname, copyinstr(arg1)); }'按进程名称汇总CPU跨调用:
dtrace -n 'sysinfo:::xcalls { @[execname] = count(); }'以99 Hz的频率对内核级堆栈进行采样:
dtrace -n 'profile:::profile-99 { @[stack()] = count(); }'本书中还使用了许多更多的DTrace一行命令,并在附录D中列出。
4.3.10 Scripting
DTrace语句可以保存到文件中以供执行,这样就可以编写更长的DTrace程序。
例如,bitesize.d脚本按进程名称显示请求的磁盘I/O大小:
#!/usr/sbin/dtrace -s
#pragma D option quiet
dtrace:::BEGIN
{
printf("Tracing... Hit Ctrl-C to end.\n");
}
io:::start
{
this->size = args[0]->b_bcount;
@Size[pid, curpsinfo->pr_psargs] = quantize(this->size);
}
dtrace:::END
{
printf("\n%8s %s\n", "PID", "CMD");
printa("%8d %S\n%@d\n", @Size);
}由于这个文件以解释器行(#!)开头,可以将其设置为可执行,并从命令行运行。
#pragma行设置了静默模式,可以抑制默认的DTrace输出(在前面的spa_sync()示例中看到,包括CPU、ID和FUNCTION:NAME列)。
脚本中的io:::start探针实现了实际的启用操作。
dtrace:::BEGIN探针在开始时触发以打印信息消息,dtrace:::END在结束时触发以格式化并打印摘要。
以下是一些示例输出:

在跟踪过程中,大部分磁盘I/O是由tar命令请求的,其大小如上所示。
bitesize.d是一个名为DTraceToolkit的DTrace脚本集合中的一部分,可以在线找到。
4.3.11 Overheads
正如前面提到的,DTrace通过使用每个CPU的内核缓冲区和内核聚合摘要来最小化插装开销。默认情况下,它还以每秒一次的温和异步速率将数据从内核空间传递到用户空间。它具有各种其他功能,可降低开销并提高安全性,包括一种例程,当检测到系统可能出现无响应时,它将中止跟踪。
进行跟踪的开销成本与跟踪频率和它们执行的操作有关。跟踪块设备I/O通常是如此罕见(每秒1,000次I/O或更少),以至于开销可以忽略不计。另一方面,跟踪网络I/O时,数据包速率可能达到每秒数百万个,可能会导致显着的开销。
此外,执行动作也是有代价的。例如,我经常以997 Hz的速率跨所有CPU对内核堆栈进行采样(使用stack()),而没有明显的开销。对用户级堆栈进行采样更为复杂(使用ustack()),因此我通常将速率降低到97 Hz。
保存数据到变量中也会带来开销,特别是关联数组。虽然使用DTrace通常不会引起明显的开销,但你需要意识到这是可能的,并且需要谨慎使用。
4.3.12 Documentation and Resources
DTrace的参考资料,其中记录了所有操作、内建函数和标准提供者,是动态跟踪指南,最初由Sun Microsystems编写并在线免费提供[2]。关于动态跟踪的背景、它解决的问题以及DTrace的发展,请参阅[Cantrill 04]和[Cantrill 06]。
附录D列出了方便的DTrace一行命令。除了它们的实用性外,它们可能是逐行学习DTrace的有用参考资料。
要查看脚本和策略的参考资料,请参阅《DTrace:Oracle Solaris、Mac OS X和FreeBSD中的动态跟踪》[Gregg 11]。该书中的脚本可在网上获取[3]。
DTraceToolkit包含超过200个脚本,目前托管在我的主页上[4]。其中许多脚本使用shell或Perl封装,以提供命令行选项和类似其他Unix工具的行为,例如execsnoop。

还基于DTrace构建了一些图形用户界面(GUI),包括Oracle ZFS Appliance Analytics和Joyent Cloud Analytics。
4.4 SystemTap
SystemTap还为用户级和内核级代码提供了静态和动态跳迹追踪,最初由来自Red Hat、IBM和英特尔的团队在Linux上设计[Eigler 05]。当时Linux还没有DTrace的移植版本。与DTrace类似,称为探针的插装点可以被编程以执行任意操作,包括事件计数、记录时间戳、执行计算、打印数值、汇总数据等等。这些操作是在实时跟踪的同时进行的。SystemTap可以从命令行中作为一行命令或脚本来使用。
SystemTap利用其他内核框架进行跟踪:静态探针使用tracepoints,动态探针使用kprobes,用户级探针使用uprobes。这些资源也被其他工具(如perf、LTTng)所使用。
经过数年的开发,SystemTap在匹配DTrace的功能集方面取得了良好的进展,有时甚至超越了它。然而,稳定性一直是一个问题,一些版本会导致内核恐慌或死机。此外,与DTrace相比,SystemTap还存在其他问题,尽管相对较小:启动时间较慢,错误消息令人困惑,未记录的隐式功能以及语言不够简洁。
与此同时,已经开始了两个将DTrace移植到Linux的独立项目。其中一个是由Oracle为Oracle Enterprise Linux进行的;另一个是由英国的程序员Paul Fox主要独自完成的努力。这些移植已被用于本书中提供的DTrace Linux示例。由于这些是新的项目并且仍在开发中,它们也可能引发内核恐慌。
如果您希望或需要改用SystemTap,可以将本书中的大多数DTrace脚本转换为SystemTap脚本。附录E是一个简短的转换指南。
下一节概述了SystemTap的基础知识,包括探针(probes)、tapsets、操作(actions)和内建功能(built-ins),然后提供了两个SystemTap示例进行比较。
4.4.1 Probes
探针定义以句点分隔,括号中可选嵌入参数。一些示例包括:
begin:程序开始
end:程序结束
syscall.read:read()系统调用开始
syscall.read.return:read()系统调用结束
kernel.function("sys_read"):内核sys_read()函数开始
kernel.function("sys_read").return:sys_read()函数结束
socket.send:socket发送
timer.ms(100):在一个CPU上每100毫秒触发一次的探针
timer.profile:以内核时钟速率在所有CPU上触发的探针,用于采样/分析
process("a.out").statement("*@main.c:100"):跟踪目标进程,可执行文件为"a.out",位于main.c第100行
许多探针提供相关数据作为内建变量。例如,syscall.read探针提供请求大小作为$count。
4.4.2 Tapsets
相关探针组被称为tapsets。许多探针的名称开头包含tapset名称。一些tapset的示例包括:
syscall:系统调用
ioblock:块设备接口和I/O调度器
scheduler:内核CPU调度器事件
memory:进程和虚拟内存使用情况
scsi:SCSI目标事件
networking:网络设备事件,包括接收和发送
tcp:TCP协议事件,包括发送和接收事件
socket:套接字事件
tapsets还用于提供额外的可执行操作。
4.4.3 Actions and Built-ins
SystemTap还提供许多操作和内建函数,包括execname()用于进程名称,pid()用于当前进程ID,以及print_backtrace()用于打印内核堆栈回溯。更多内容列在附录E中。
4.4.4 Examples
以下一行命令追踪read()系统调用,将返回的读取大小保存为2的幂次直方图。这既作为SystemTap的示例,也作为与DTrace进行比较的范例,前面已展示了等效的一行命令。


-v选项会打印有关编译阶段的详细信息,当追踪被启用时会通知用户("starting run")。如果没有该选项,SystemTap默认不会打印任何内容,让您疑惑追踪何时开始。在某些情况下,编译阶段可能需要超过20秒,早期的Ctrl-C不仅会完全中止追踪,还可能根据中断的编译阶段打印令人困惑的错误信息。
这条一行命令首先声明了一个名为stats的全局变量 —— SystemTap要求进行预声明。探针定义以关键字probe开头,匹配read()系统调用的返回。动作是使用统计运算符<<<将返回值(作为$return提供)记录在stats变量中。这以一种通用方式记录数值,允许稍后以不同方式对其进行总结。
结束探针需要打印此统计变量作为直方图。如果没有它,SystemTap在退出时只会打印基本的数字摘要。
关于直方图的最后一点说明:read()的$return值有时是负数 —— 设置为错误号(errno)的负版本。这遵循内核约定而非POSIX标准,可能会让期望看到后者的用户感到困惑。也并不清楚这是否是有意为之,因为$return的目的未经记录。
以下是等效的一行命令,首先是SystemTap,然后是DTrace:

像这样的比较可以更深入地理解每种技术。这里有一个不同的示例,这次使用SystemTap来突显DTrace的局限性:


这条一行命令通过进程名称保存read返回大小的统计信息。它使用三个不同的函数打印,提供了调用次数、平均大小(字节)和总字节数的列。为此,DTrace需要填充三个单独的聚合,每种类型一个。
这还利用了if语句和foreach循环。DTrace不提供if语句,而是通过谓词提供分支功能,有时对程序员来说可能不太自然。此外,DTrace目前没有循环能力,除了展开的循环,出于安全考虑,它永远不会执行向后跳转。
SystemTap通过为循环提供上限解决了这个问题,以便在SystemTap脚本中的无限循环不会在内核上下文中挂起。
最后一个区别是:在SystemTap中可以直接访问统计值,如s[k],而DTrace聚合只能整体打印或通过聚合函数进行处理。
4.4.5 Overheads
使用SystemTap的开销与之前描述的DTrace类似,使用时需要注意相同的问题。此外,当程序首次执行时,SystemTap的编译阶段可能会消耗CPU资源(持续几秒钟)。SystemTap会缓存程序,以便不会在每次使用时发生这种开销。还应该有可能在不同系统上编译SystemTap程序,然后将缓存结果传输到目标系统。
另一个额外的开销是需要内核调试信息进行内核分析,这通常不包含在Linux发行版中(其大小可能达数百兆字节)。
4.4.6 Documentation and Resources
SystemTap有大量的man页面,包括单个探针的页面。例如,对于ioblock.request探针:

SystemTap语言的文档可以在SystemTap语言参考[5]的在线页面中找到。在SystemTap文档网站[6]上还有教程、入门指南和tapset参考。
您还可以将本书中的所有DTrace示例视为可能的SystemTap功能示例。请参阅附录E以获取它们的转换示例。
4.5 perf
Linux性能事件(LPE),简称perf,一直在发展以支持广泛的性能可观测活动。尽管它目前没有DTrace或SystemTap的实时编程能力,但它可以执行静态和动态跟踪(基于跟踪点、kprobes和uprobes),以及性能分析。它还可以检查堆栈跟踪、本地变量和数据类型。由于它是主线内核的一部分,如果已经存在,则可能是使用最简单的,并且可能提供足够的可观测性以回答您的许多问题。
perf(1)的一些跟踪开销应该与DTrace相似。在典型的用法中,DTrace程序被编写为汇总内核中的数据(聚合),而perf(1)目前不会这样做。使用perf(1),数据会传递到用户级别进行后处理(它有一个脚本框架来帮助),当跟踪频繁事件时,这可能会导致显着的额外开销。请参阅第6章CPU的第6.6节“分析”,介绍perf(1)并演示其许多功能。
4.6 Observing Observability
可观测性工具及其所构建的统计数据是在软件中实现的,而所有软件都有可能存在错误。描述软件的文档也是如此。对于您不熟悉的任何统计数据,应该持健康的怀疑态度,质疑它们真正意味着什么,以及它们是否真的正确。
度量指标可能存在以下问题:
- 工具并非总是正确。
- man手册并非总是正确。
- 可用的度量可能是不完整的。
- 可用的度量可能设计不佳。
当多个可观测性工具具有重叠覆盖范围时,您可以使用它们相互交叉检查。理想情况下,它们将使用不同的框架来检查其中的错误。动态跟踪对此尤为有用,因为可以使用它创建自定义工具。
另一种验证技术是应用已知的工作负载,然后检查可观测性工具是否与您预期的结果一致。这可能涉及使用微基准测试工具报告其自己的统计数据进行比较。
有时候出错的不是工具或统计数据,而是描述它们的文档,包括man手册。软件可能已经发展,但文档尚未更新。
现实情况是,您可能没有时间再次核对每个使用的性能测量数据,只有在遇到异常结果或使用特别重要的结果时才会这样做。即使您没有再次核对,意识到您没有这样做,并且假设工具是正确的也是有价值的。
除了度量指标可能不正确外,它们也可能是不完整的。面对大量工具和度量指标时,可能会诱人地认为它们提供了完整和有效的覆盖范围。然而事实往往并非如此:度量指标可能是程序员添加用于调试其代码,然后稍后构建为可观测性工具,而没有进行针对实际客户需求的深入研究。有些程序员可能根本没有向新子系统添加任何内容。
缺乏度量指标可能比存在低质量度量指标更难以识别。第二章“方法论”可以通过研究您在性能分析中需要回答的问题来帮助您找到这些缺失的度量指标。
















 526
526











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









