






CPU驱动所有软件,通常是系统性能分析的首要目标。现代系统通常有许多CPU,由内核调度程序在所有运行的软件之间共享。当对CPU资源的需求超过可用资源时,进程线程(或任务)将排队等待执行。等待会在应用程序运行期间增加显着的延迟,降低性能。
可以详细检查CPU的使用情况,以寻找性能改进,包括消除不必要的工作。在高级别上,可以检查进程、线程或任务的CPU使用情况。在较低级别上,可以对应用程序和内核中的代码路径进行性能分析和研究。在最低级别上,可以研究CPU指令执行和周期行为。
本章包括五个部分:
- 背景介绍了与CPU相关的术语、CPU的基本模型和关键的CPU性能概念。
- 架构介绍了处理器和内核调度程序的架构。
- 方法论描述了性能分析方法,包括观察性的和实验性的。
- 分析描述了基于Linux和Solaris系统的CPU性能分析工具,包括分析、跟踪和可视化。
- 调优包括可调参数的示例。
前三节为CPU分析提供了基础,后两节展示了其在基于Linux和Solaris系统的实际应用。还涵盖了内存I/O对CPU性能的影响,包括受阻于内存的CPU周期以及CPU缓存的性能。第7章“内存”继续讨论内存I/O,包括MMU、NUMA/UMA、系统互连和内存总线。
6.1 Terminology
在本章中使用的与CPU相关的术语包括以下内容:
- 处理器:插入系统或处理器板上的插座的物理芯片,包含一个或多个作为核心或硬件线程实现的CPU。
- 核心:多核处理器上独立的CPU实例。使用核心是扩展处理器性能的一种方式,称为芯片级多处理(CMP)。
- 硬件线程:支持在单个核心上并行执行多个线程的CPU体系结构(包括英特尔的超线程技术),其中每个线程是独立的CPU实例。这种扩展方法的一种名称是多线程。
- CPU指令:来自其指令集的单个CPU操作。有关算术运算、内存I/O和控制逻辑的指令。
- 逻辑CPU:也称为虚拟处理器,是操作系统的CPU实例(可调度的CPU实体)。这可能由处理器作为硬件线程实现(在这种情况下也可以称为虚拟核心)、核心或单核处理器。
- 调度程序:分配线程在CPU上运行的内核子系统。
- 运行队列:等待被CPU服务的可运行线程的队列。对于Solaris系统,它通常被称为分派队列。
本章还介绍了其他术语。术语表中包括基本术语,如CPU、CPU周期和堆栈。同时,请参阅第2章和第3章的术语部分。
6.2 Models
以下简单模型说明了CPU和CPU性能的一些基本原则。第6.4节“架构”深入探讨,并包括特定实现的详细信息。}
6.2.1 CPU Architecture
图6.1显示了一个示例CPU架构,对于一个具有四个核心和总共八个硬件线程的单处理器。展示了物理架构以及操作系统看到的架构。
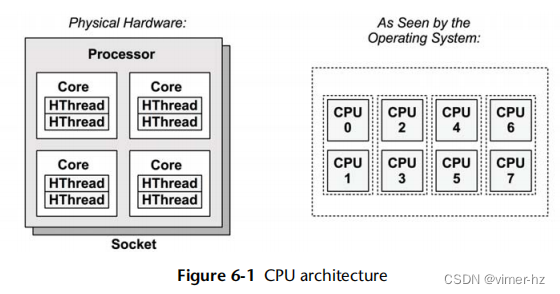
每个硬件线程可以被视为一个逻辑CPU,因此这个处理器看起来就像有八个CPU。操作系统可能对拓扑结构有一些额外的了解,比如哪些CPU在同一个核心上,以改善其调度决策。
6.2.2 CPU Memory Caches
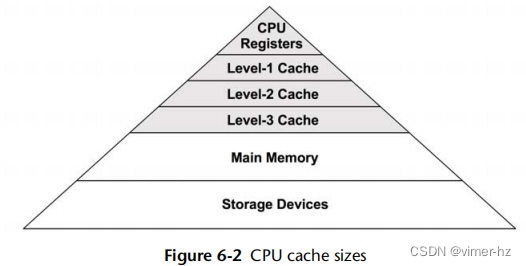
处理器提供各种硬件缓存来改善内存I/O性能。图6.2显示了缓存大小的关系,这些缓存离CPU越近,就会变得更小更快(一个权衡)。存在的缓存以及它们是否在处理器(集成的)上或者处理器外部,取决于处理器类型。较早的处理器提供了较少级别的集成缓存。
6.2.3 CPU Run Queues
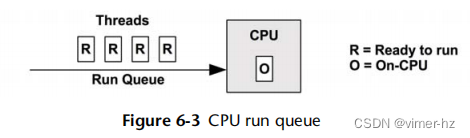
图6.3展示了一个CPU运行队列,由内核调度程序管理。
图中显示的线程状态,即准备运行和在CPU上运行,在第3章操作系统的图3.7中有介绍。
排队并准备运行的软件线程数量是一个重要的性能指标,表明CPU饱和度。在这个图中(此刻),有四个线程排队准备运行,并且额外有一个线程正在CPU上运行。在CPU运行队列等待的时间有时称为运行队列延迟或调度器队列延迟。本书中使用调度器延迟一词代替,因为它适用于所有调度器类型,包括那些不使用队列的调度器(请参见第6.4.2节“软件”中对CFS的讨论)。
对于多处理器系统,内核通常为每个CPU提供一个运行队列,并力求保持线程在同一个运行队列上。这意味着线程更有可能在同一个CPU上继续运行,其中CPU缓存已缓存其数据。(这些缓存被描述为具有缓存热度,偏好CPU的方法称为CPU亲和性。)在NUMA系统上,内存局部性也可能得到改善,从而提高性能(这在第7章“内存”中有描述)。
这也避免了线程同步(互斥锁)对队列操作的成本,如果运行队列是全局的并在所有CPU之间共享,会影响可伸缩性。
6.3 Concepts
以下是关于CPU性能的一些重要概念,从处理器内部结构的概述开始,包括CPU时钟频率和指令执行方式。这为后续的性能分析提供了背景知识,特别是对于理解每指令周期数(CPI)指标非常重要。
6.3.1 Clock Rate
时钟是驱动所有处理器逻辑的数字信号。每条CPU指令可能需要一个或多个时钟周期(称为CPU周期)来执行。CPU以特定的时钟频率运行;例如,一个5 GHz的CPU每秒执行50亿个时钟周期。
一些处理器能够改变它们的时钟频率,将其增加以提高性能或降低以节约功耗。时钟频率可以根据操作系统的要求进行变化,也可以由处理器自身动态调整。例如,内核空闲线程可以请求CPU降低频率以节省电力。
时钟频率通常被宣传为处理器的主要特性,但这可能有点误导。即使您系统中的CPU看起来完全被利用(成为瓶颈),更快的时钟频率可能并不会提高性能——这取决于这些快速CPU周期实际在做什么。如果它们大部分时间都是在等待内存访问时的停滞周期,那么加快执行并不会增加CPU指令速率或工作负载吞吐量。
6.3.2 Instruction
CPU执行从其指令集中选择的指令。一条指令包括以下步骤,每个步骤由CPU的一个称为功能单元的组件处理:
1. 指令获取
2. 指令解码
3. 执行
4. 内存访问
5. 寄存器写回
最后两个步骤取决于指令是否需要。许多指令仅操作寄存器,不需要内存访问步骤。
这些步骤中的每一个至少需要一个时钟周期来执行。内存访问通常是最慢的,因为读取或写入主存储器可能需要几十个时钟周期,在此期间指令执行会停滞(这些停滞期间被称为停滞周期)。这就是为什么CPU缓存很重要的原因,如第6.4节所述:它可以显著减少内存访问所需的时钟周期数。
6.3.3 Instruction Pipeline
指令流水线是一种CPU架构,能够并行执行多条指令,通过同时执行不同指令的不同组件。它类似于工厂的装配线,可以并行执行生产的各个阶段,从而增加吞吐量。
考虑之前列出的指令步骤。如果每个步骤都需要一个时钟周期,那么完成该指令需要五个周期。在指令的每个步骤中,只有一个功能单元处于活动状态,其他四个处于空闲状态。通过使用流水线技术,多个功能单元可以同时处于活动状态,在流水线中处理不同的指令。理想情况下,处理器可以在每个时钟周期内完成一条指令的执行。
6.3.4 Instruction Width
但我们还可以更快。可以包含多个相同类型的功能单元,因此即使更多的指令也可以在每个时钟周期内取得进展。这种CPU架构被称为超标量,并通常与流水线一起使用,以实现高指令吞吐量。
指令宽度描述了并行处理的目标指令数量。现代处理器通常是3-wide或4-wide,意味着它们可以在一个周期内完成多达三个或四个指令。这是如何工作取决于处理器,因为每个阶段可能具有不同数量的功能单元。
6.3.5 CPI, IPC
每条指令的周期数(CPI)是描述CPU在哪些时钟周期中消耗的重要高级指标,以及理解CPU利用率的性质。这个指标也可以表示为每个周期的指令数(IPC),它是CPI的倒数。
高CPI表示CPU经常处于停滞状态,通常是由于内存访问。低CPI表示CPU经常不会停滞,并且具有高的指令吞吐量。这些指标提示了性能调优工作可能最好的方向。
例如,内存密集型工作负载可以通过安装更快的内存(DRAM)、改进内存局部性(软件配置)或减少内存输入/输出来改善性能。安装时钟频率更高的CPU可能不会如预期的那样提高性能,因为CPU可能需要等待相同的时间才能完成内存I/O。换句话说,更快的CPU可能意味着更多的停滞周期,但完成的指令率相同。
高或低CPI的实际值取决于处理器和处理器特性,并且可以通过运行已知的工作负载进行实验确定。例如,您可能会发现,高CPI的工作负载的CPI为10或更高,而低CPI的工作负载的CPI小于1(这是由于前面描述的指令流水线和宽度)。
需要注意的是,CPI显示了指令处理的效率,但并不代表指令本身的效率。考虑一个添加了低效软件循环的软件更改,该循环主要在CPU寄存器上操作(没有停滞周期):这样的更改可能会导致较低的总体CPI,但CPU使用率和利用率更高。
6.3.6 Utilization
CPU利用率是指CPU实例在一个时间间隔内忙于执行工作的时间,以百分比表示。它可以被衡量为CPU不在运行内核空闲线程,而是在运行用户级应用线程或其他内核线程,或处理中断的时间。
高CPU利用率不一定是问题,而是系统正在执行工作的一个迹象。有些人也认为这是一个投资回报率指标:高度利用的系统被认为具有良好的回报率,而空闲的系统被认为是浪费的。与其他资源类型(如磁盘)不同,在高利用率下性能不会急剧下降,因为内核支持优先级、抢占和时间共享。这些机制使内核能够理解哪个任务具有更高的优先级,并确保它首先运行。
CPU利用率的测量涵盖了所有可用活动的时钟周期,包括内存停滞周期。这可能看起来有点反直觉,但CPU可能高度利用是因为它经常因等待内存I/O而停滞,而不仅仅是执行指令,就像前面部分所描述的那样。
CPU利用率通常分为内核时间和用户时间两个独立的指标。
6.3.7 User-Time/Kernel-Time
执行用户级应用程序代码所花费的CPU时间称为用户时间,而内核级代码则是内核时间。内核时间包括系统调用、内核线程和中断期间的时间。当在整个系统范围内进行测量时,用户时间与内核时间之比表明了所执行的工作负载类型。
计算密集型应用程序可能几乎全部时间都用于执行用户级代码,并且用户/内核比接近于 99/1。例如图像处理、基因组学和数据分析等应用。
I/O 密集型应用程序具有较高的系统调用率,这些调用执行内核代码以执行 I/O 操作。例如,执行网络 I/O 的 Web 服务器可能具有约为 70/30 的用户/内核比。
这些数字受到许多因素的影响,用来表达预期的比率类型。
6.3.8 Saturation
CPU完全利用率达到100%时会饱和,线程将因等待在 CPU 运行队列或其他用于管理线程的结构上而遇到调度延迟,降低整体性能。这种延迟是等待 CPU 运行队列或其他管理线程的结构的时间。
另一种形式的 CPU 饱和涉及 CPU 资源控制,例如在多租户云计算环境中可能会施加。尽管 CPU 可能未达到100%利用率,但已达到所施加的限制,并且可运行的线程必须等待它们的轮次。这对系统用户的可见性取决于使用的虚拟化类型;请参阅第11章云计算。
CPU运行于饱和状态不像其他资源类型那么成问题,因为具有更高优先级的工作可以抢占当前线程。
6.3.9 Preemption
在第三章“操作系统”中介绍的抢占机制允许具有更高优先级的线程剥夺当前正在运行的线程,并开始自己的执行。这消除了对于高优先级工作的运行队列延迟,提高了其性能。
6.3.10 Priority Inversion
优先级倒置发生在一个低优先级线程持有资源并阻塞一个高优先级线程运行时。这降低了高优先级工作的性能,因为它被阻塞等待。
Solaris内核实现了完整的优先级继承方案,以避免优先级倒置。以下是一个示例,说明这种机制如何工作(基于真实案例):
1. 线程A执行监控任务,优先级较低。它获取一个用于生产数据库的地址空间锁,以检查内存使用情况。
2. 线程B是一个常规任务,执行系统日志的压缩操作,开始运行。
3. 没有足够的CPU来同时运行两者。线程B抢占A并运行。
4. 线程C来自生产数据库,具有高优先级,并且一直处于等待I/O 的睡眠状态。现在该I/O 完成,将线程C放回可运行状态。
5. 线程C抢占B并运行,但随后由于被线程A持有的地址空间锁而阻塞。线程C离开CPU。
6. 调度程序选择下一个最高优先级的线程运行:B。
7. 当线程B运行时,一个高优先级线程C 实际上被阻塞在一个低优先级线程B 上。这就是优先级倒置。
8. 优先级继承使线程A获得了线程C的高优先级,抢占B,直到释放锁。现在线程C可以运行了。
自Linux 2.6.18 以来,提供了支持优先级继承的用户级互斥锁,用于实时工作负载。
6.3.11 Multiprocess, Multithreading
大多数处理器都提供某种形式的多个CPU。为了让应用程序能够利用这些CPU,它需要独立的执行线程,以便可以并行运行。例如,对于一个64-CPU系统,这意味着如果应用程序可以并行利用所有CPU,它可能可以以多达64倍的速度运行,或者处理64倍的负载。应用程序能够有效地随着CPU数量增加而扩展的程度是可伸缩性的衡量标准。

跨CPU扩展应用程序的两种技术是多进程和多线程,如图6.4所示。
在Linux上,多进程和多线程模型都可以使用,并且都由任务来实现。

多进程和多线程之间的差异如表6.1所示。
尽管对开发人员来说更复杂,但综合表中显示的所有优势,多线程通常被认为是更优越的。
不管使用哪种技术,重要的是创建足够的进程或线程来跨越所需数量的CPU,对于最大性能来说,可能是所有可用的CPU。一些应用程序在运行在较少的CPU上时可能表现更好,当线程同步的成本和降低内存局部性超过了跨多个CPU运行的好处时。并行架构也在第5章“应用”中进行了讨论。
6.3.12 Word Size
处理器的设计基于最大字长——32位或64位,这也是整数大小和寄存器大小。根据处理器的不同,字长通常也用于地址空间大小和数据路径宽度(有时称为位宽)。
较大的字长可能意味着更好的性能,尽管实际情况并非听起来那么简单。较大的字长可能会导致某些数据类型中未使用位的内存开销。当指针的大小(字长)增加时,数据占用的空间也会增加,这可能需要更多的内存I/O。对于x86 64位架构,通过增加寄存器和更高效的寄存器调用约定来补偿这些开销,因此64位应用程序可能比其32位版本更快。
处理器和操作系统可以支持多个字长,并且可以同时运行为不同字长编译的应用程序。如果软件已编译为较小的字长,它可能可以成功执行,但性能相对较差。
6.3.13 Compiler Optimization
通过编译器选项(包括设置字长)和优化,可以显著提高应用程序的CPU运行时间。编译器也经常更新,以利用最新的CPU指令集并实施其他优化。有时候,仅仅使用更新的编译器就能显著提高应用程序的性能。
更详细地介绍了这个主题,请参考第5章《应用程序》。
6.4 Architecture
这一部分介绍了CPU架构和实现,涵盖了硬件和软件两个方面。在第6.2节《模型》中介绍了简单的CPU模型,在之前的一节中介绍了通用概念。
这些主题作为性能分析的背景进行了总结。更多详情,请参阅厂商的处理器手册以及有关操作系统内部的文献。本章末尾列出了一些相关文献。
6.4.1 Hardware
CPU硬件包括处理器及其子系统,以及多处理器系统的CPU互连。
Processor
通用双核处理器的各组成部分如图6.5所示。
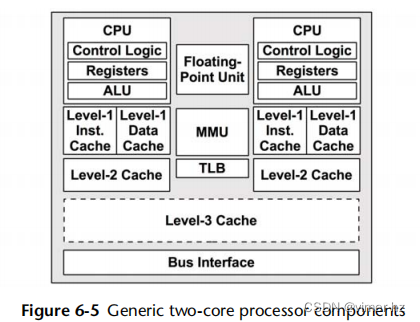
控制单元(图中显示为控制逻辑)是CPU的核心,负责指令获取、解码、管理执行和存储结果。
这个示例处理器展示了一个共享的浮点运算单元和(可选的)共享第3级缓存。您的处理器实际组件将根据其类型和型号而异。其他可能存在的与性能相关的组件包括以下内容:
- P缓存:预取缓存(每个CPU)
- W缓存:写入缓存(每个CPU)
- 时钟:用于CPU时钟的信号发生器(或者由外部提供)
- 时间戳计数器:用于高分辨率时间,由时钟递增
- 微码ROM:快速将指令转换为电路信号
- 温度传感器:用于热量监控
- 网络接口:如果芯片上有(用于高性能)
一些处理器类型使用温度传感器作为单个核心动态超频的输入(包括英特尔Turbo Boost技术),在核心保持在其温度范围内的情况下提高性能。
CPU Caches
处理器通常包含各种硬件缓存(称为芯片上、芯片内、嵌入式或集成)或与处理器一起使用的外部缓存。这些缓存通过使用更快的内存类型来缓存读取和缓冲写入,从而提高内存性能。通用处理器的缓存访问级别如图6.6所示。
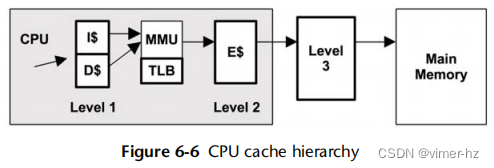
它们包括:
- 一级指令缓存(I$)
- 一级数据缓存(D$)
- 转换后备缓冲器(TLB)
- 二级缓存(E$)
- 三级缓存(可选)
E$中的E最初代表外部缓存,但随着二级缓存的整合,它被巧妙地称为嵌入式缓存。现今使用“级别”术语代替“E$”风格的标记,以避免混淆。
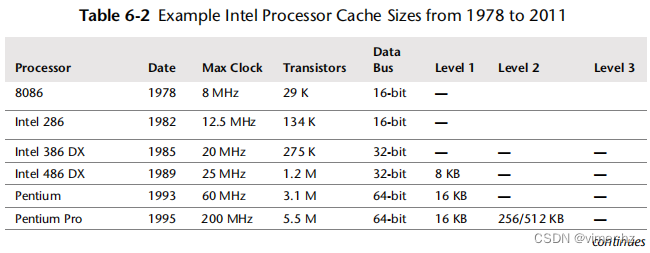
每个处理器可用的缓存取决于其类型和型号。随着时间的推移,这些缓存的数量和大小一直在增加。《Table 6.2》列出了自1978年以来的英特尔处理器,包括缓存方面的进展[Intel 12]。

对于多核和多线程处理器,其中一些缓存可能在核心和线程之间共享。
除了CPU缓存数量和大小的增加外,还存在将这些缓存提供在芯片上的趋势,这样可以将访问延迟降至最低,而不是提供外部的缓存给处理器使用。
Latency
为了提供最佳的大小和延迟配置,使用多级缓存。一级缓存的访问时间通常是几个CPU时钟周期,而较大的二级缓存大约需要十几个时钟周期。主存储器可能需要大约60纳秒(对于4 GHz处理器,大约240个周期),而由内存管理单元进行地址转换也会增加延迟。
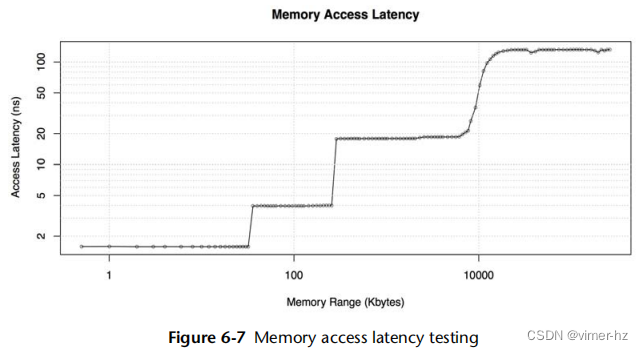
可以通过微基准测试[Ruggiero 08]来实验性地确定处理器的CPU缓存延迟特性。图6.7显示了对Intel Xeon E5620 2.4 GHz进行了LMbench[2]内存访问延迟测试的结果。
图中的两个轴都是对数刻度。图表中的阶跃点显示了何时超出了某个缓存级别,并且访问延迟成为下一个(更慢)缓存级别的结果。
Associativity
关联性是描述缓存中定位新条目的约束的一种特征。类型包括:
- 全关联式:缓存可以在任何位置定位新条目。例如,LRU算法可以淘汰整个缓存中最近未使用的条目。
- 直接映射式:每个条目在缓存中只有一个有效位置,例如,内存地址的哈希值,使用地址位的子集来形成缓存中的地址。
- 集合关联式:通过映射(例如,哈希)标识缓存的一个子集,在该子集内可以执行另一个算法(例如,LRU)。它以子集大小来描述;例如,四路组关联将地址映射到四个可能的位置,然后从这四个位置中选择最佳位置。
CPU缓存通常使用集合关联性作为全关联式(执行代价高昂)和直接映射式(命中率较低)之间的平衡。
Cache Line
CPU缓存的另一个特征是它们的缓存行大小。这是一组以字节为单位存储和传输的范围,可以提高内存吞吐量。x86处理器的典型缓存行大小为64字节。编译器在优化性能时会考虑到这一点。程序员有时也会考虑到这一点;请参阅第5章5.2.5节中的应用程序中的哈希表。
Cache Coherency
内存可能会同时被缓存在不同处理器上的多个CPU缓存中。当一个CPU修改内存时,所有缓存都需要知道它们缓存的副本现在已经过期,应该被丢弃,这样任何未来的读取操作都将检索到新修改的副本。这个过程称为缓存一致性,确保CPU始终访问内存的正确状态。这也是设计可扩展多处理器系统时面临的最大挑战之一,因为内存可能会迅速被修改。
MMU
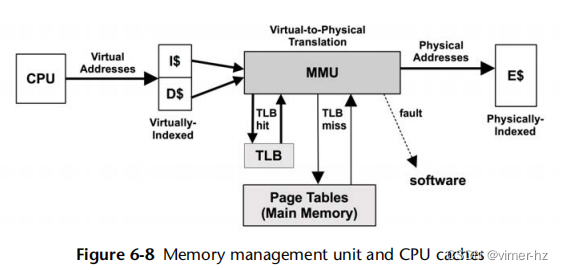
MMU负责虚拟地址到物理地址的转换。图6.8展示了一个通用的MMU以及CPU缓存类型。该MMU使用片上TLB缓存地址转换。缓存未命中时,由主内存(DRAM)中的翻译表(称为页表)满足,这些表由MMU(硬件)直接读取。
这些因素是处理器相关的。一些(较旧的)处理器通过软件处理TLB未命中,遍历页表然后将所请求的映射填充到TLB中。这样的软件可能会维护自己的更大的内存翻译缓存,称为翻译存储缓冲区(TSB)。新型处理器可以通过硬件服务TLB未命中,大大降低成本。
Interconnects
对于多处理器架构,处理器使用共享系统总线或专用互连进行连接。这与系统的内存架构有关,即统一内存访问(UMA)或非统一内存访问(NUMA),如第7章“内存”中所讨论的。
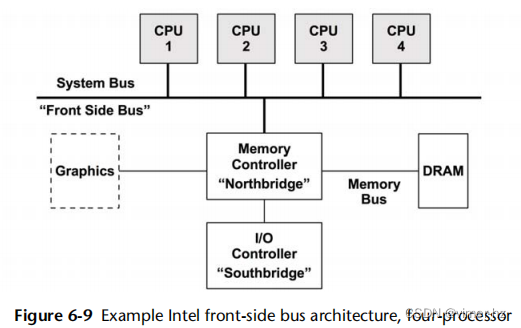
早期英特尔处理器使用的共享系统总线(称为前端总线)的四处理器示例可见于图6.9。
当增加处理器数量时,使用系统总线会出现可扩展性问题,因为会争夺共享总线资源。现代服务器通常是多处理器、NUMA架构,并使用CPU互连代替系统总线。
互连可以连接处理器以外的组件,例如I/O控制器。示例互连包括英特尔的Quick Path Interconnect(QPI)和AMD的HyperTransport(HT)。图6.10展示了一个四处理器系统的示例英特尔QPI架构。
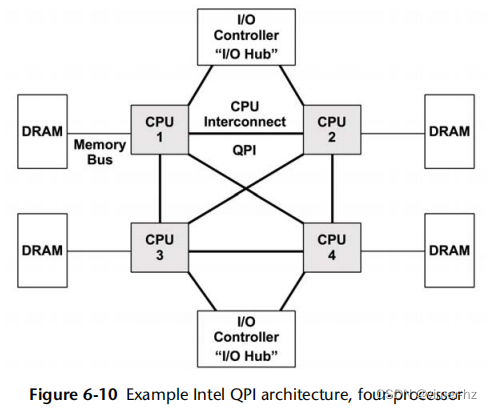
处理器之间的私有连接允许非竞争访问,同时也比共享系统总线具有更高的带宽。表6.3(Intel 09)中显示了英特尔前端总线(FSB)和QPI的一些示例速度。
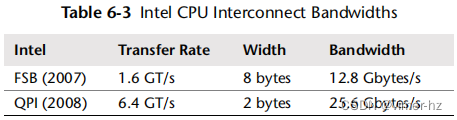
QPI是双泵技术,即在时钟的两个边沿上进行数据传输,从而使数据传输速率加倍。这解释了表中显示的带宽(6.4 GT/s x 2字节 x 双倍 = 25.6 G字节/秒)。
除了外部互连之外,处理器还具有用于核心通信的内部互连。
互连通常设计为高带宽,以确保其不会成为系统瓶颈。如果互连成为瓶颈,CPU指令在涉及互连的操作(如远程内存I/O)时将遇到停滞周期,导致性能下降。一个关键的指标是CPI的上升。可以使用CPU性能计数器来分析CPU指令、周期、CPI、停滞周期和内存I/O。
CPU Performance Counters
CPU性能计数器(CPCs)有许多名称,包括性能仪器计数器(PICs)、性能监视单元(PMU)、硬件事件和性能监视事件。它们是可以编程计算低级CPU活动的处理器寄存器。通常包括以下计数器:
- CPU周期:包括停滞周期和停滞周期类型
- CPU指令:已退役(执行)
- 一级、二级、三级缓存访问:命中、未命中
- 浮点单元:操作
- 内存I/O:读取、写入、停滞周期
- 资源I/O:读取、写入、停滞周期
每个CPU都有少量寄存器,通常在两到八个之间,可以编程记录此类事件。可用的寄存器取决于处理器类型和型号,并在处理器手册中有详细说明。
举个相对简单的例子,英特尔P6系列处理器通过四个特定于型号的寄存器(MSR)提供性能计数器。其中两个是计数器,只读。另外两个用于编程这些计数器,称为事件选择MSR,可读写。性能计数器是40位寄存器,事件选择MSR是32位。事件选择MSR的格式如图6.11所示。
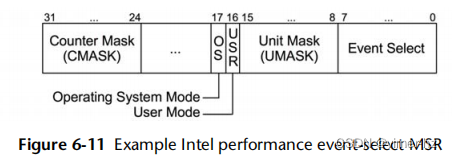
计数器由事件选择和UMASK标识。事件选择用于标识要计数的事件类型,UMASK用于标识子类型或子类型的组合。可以设置OS和USR位,以便根据处理器的保护环来仅在内核模式(OS)或用户模式(USR)下递增计数器。CMASK可以设置为在计数器递增之前必须达到的事件阈值。
英特尔处理器手册(卷3B [Intel 13])列出了可以根据事件选择和UMASK值计数的几十个事件。表6.4中的选定示例提供了不同目标(处理器功能单元)可能可观察到的想法。您需要参考当前的处理器手册来查看您实际拥有的内容。
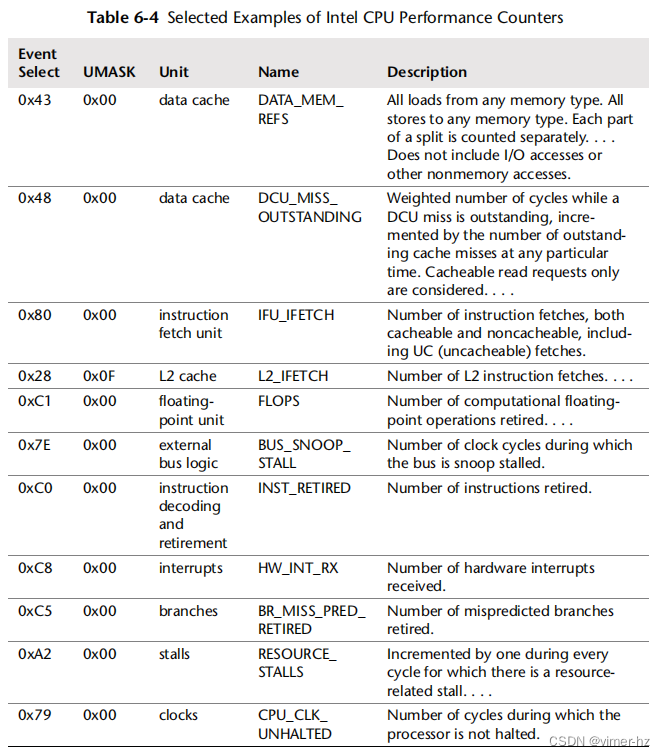
现代处理器有许多更多的计数器,特别是较新的处理器。英特尔Sandy Bridge系列处理器不仅提供更多的计数器类型,还提供更多计数器寄存器:每个硬件线程三个固定计数器和四个可编程计数器,以及每个核心额外的八个可编程计数器(“通用计数器”)。这些计数器在读取时为48位。
由于性能计数器在不同厂商之间存在差异,因此开发了一个标准,以提供跨平台的一致接口。这就是处理器应用程序编程接口(PAPI)。PAPI将计数器类型分配给通用名称,例如,PAPI_tot_cyc表示总周期计数,而不是CPU_CLK_UNHALTED。
6.4.2 Software
支持CPU的内核软件包括调度器、调度类和空闲线程。
Scheduler
内核CPU调度器的关键功能如图6.12所示。
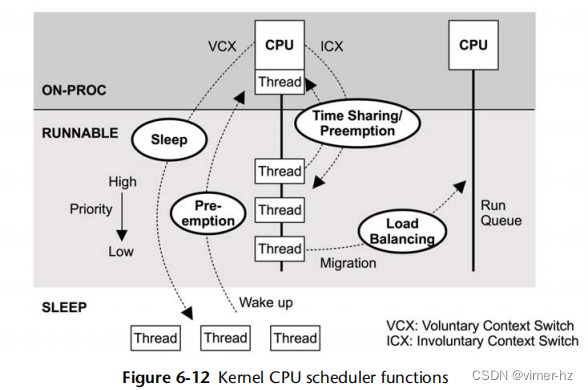
这些功能包括:
- 时间共享:在可运行线程之间进行多任务处理,首先执行优先级最高的线程。
- 抢占:对于已经以高优先级变为可运行状态的线程,调度器可以抢占当前正在运行的线程,以便立即开始执行更高优先级的线程。
- 负载平衡:将可运行线程移动到空闲或负载较低的CPU的运行队列中。
图中显示了每个CPU的运行队列。还有每个优先级级别的运行队列,因此调度器可以轻松地管理同一优先级的线程应该运行的情况。
下面是针对最近的基于Linux和Solaris的内核的调度工作的简要总结。包括了函数名称,以便您可以在源代码中找到它们进行进一步的参考(尽管它们可能已经发生了变化)。另外也可以参考文献中列出的内部文本。
Linux
在Linux上,时间共享是通过系统定时器中断驱动的,通过调用scheduler_tick()函数来调用调度类函数来管理优先级和称为时间片的CPU时间单位的到期。当线程变为可运行状态时,会触发抢占,调度器类会调用check_preempt_curr()函数。线程的切换由__schedule()函数管理,它通过pick_next_task()函数选择最高优先级的线程来运行。负载平衡由load_balance()函数执行。
Solaris
在基于Solaris的内核上,时间共享是由clock()函数驱动的,它调用调度器类函数,包括ts_tick()来检查时间片是否到期。如果线程超过其时间限制,其优先级会降低,允许另一个线程抢占。用户线程的抢占由preempt()函数处理,而内核线程的抢占由kpreempt()函数处理。swtch()函数管理离开CPU的线程,包括出于自愿的上下文切换等任何原因,并调用调度程序函数来找到最适合替代它的可运行线程:disp()、disp_getwork()或disp_getbest()。负载平衡包括空闲线程调用类似的函数,以从另一个CPU的调度程序队列(运行队列)中找到可运行线程。
Scheduling Classes
调度类管理可运行线程的行为,特别是它们的优先级,它们在CPU上的时间是否被切片,以及这些时间片的持续时间(也称为时间量子)。此外,通过调度策略还可以对其进行额外控制,这些策略可以在调度类中选择,并可以控制相同优先级线程之间的调度。图6.13展示了它们以及线程优先级范围。

用户级线程的优先级受用户定义的nice值影响,可以将其设置为降低不重要工作的优先级。在Linux中,nice值设置线程的静态优先级,这与调度器计算的动态优先级是分开的。
需要注意的是,在Linux和基于Solaris的内核之间,优先级范围是倒置的。原始的Unix优先级范围(第6版)使用较低的数字表示较高的优先级,这是现在系统Linux所采用的方式。
Linux
对于Linux内核,调度类如下:
RT:为实时工作负载提供固定和高优先级。内核支持用户级和内核级的抢占,允许实时任务以低延迟被调度。优先级范围是0-99(MAX_RT_PRIO-1)。
O(1):O(1)调度器在Linux 2.6中作为默认的用户进程时间共享调度器引入。其名称来源于O(1)的算法复杂度(参见第5章应用程序,了解大O符号的摘要)。先前的调度器包含迭代所有任务的例程,使其为O(n),这成为一个可扩展性问题。O(1)调度器动态提高I/O密集型工作负载的优先级,以减少交互和I/O工作负载的延迟。
CFS:完全公平调度被添加到Linux 2.6.23内核中,作为默认的用户进程时间共享调度器。该调度器在红黑树上管理任务,而不是传统的运行队列,其键值来自任务的CPU时间。这使得可以轻松找到并执行低CPU消耗者,优先于CPU密集型工作负载,从而提高交互和I/O密集型工作负载的性能。
用户级进程可以通过调用sched_setscheduler()来设置调度器策略,从而调整调度类的行为。RT类支持SCHED_RR和SCHED_FIFO策略,而CFS类支持SCHED_NORMAL和SCHED_BATCH。
调度器策略如下:
- RR:SCHED_RR是轮转调度。一旦线程使用完其时间量子,它将被移至该优先级级别的运行队列末尾,以便其他具有相同优先级的线程运行。
- FIFO:SCHED_FIFO是先进先出调度,继续运行运行队列开头的线程,直到它自愿离开,或直到更高优先级的线程到达。即使具有相同优先级的其他线程在运行队列上,该线程仍将继续运行。
- NORMAL:SCHED_NORMAL(以前称为SCHED_OTHER)是时间共享调度,是用户进程的默认值。调度器根据调度类动态调整优先级。对于O(1),时间片持续时间基于静态优先级进行设置:对于较高优先级的工作,持续时间较长。对于CFS,时间片是动态的。
- BATCH:SCHED_BATCH类似于SCHED_NORMAL,但预期线程将是CPU密集型,并且不应安排中断其他I/O密集型交互式工作。
随着时间的推移,可能会添加其他类和策略。已经研究了一些调度算法,这些算法具有超线程感知性[Bulpin 05]和温度感知性[Otto 06],通过考虑额外的处理器因素来优化性能。
当没有线程需要运行时,会执行一个特殊的空闲任务(也称为空闲线程)作为占位符,直到另一个线程可运行。
Solaris
对于基于Solaris的内核,调度类如下:
RT:实时调度为实时工作负载提供固定和高优先级。这些任务具有抢占所有其他工作(除中断服务程序外)的特性,以便应用程序响应时间可以确定性地保持,这是实时工作负载的典型要求。
SYS:系统是用于内核线程的高优先级调度类。这些线程具有固定的优先级,并且会执行所需的时间(或直到被RT或中断抢占)。
TS:时间共享是用户进程的默认调度类;它根据最近的CPU使用情况动态调整优先级和时间片。如果线程使用完其时间片,那么其优先级会降低,时间片会增加。这导致CPU密集型工作负载以较大的时间片低优先级运行(减少调度器成本),而I/O密集型工作负载——在其时间片用尽之前自愿进行上下文切换——以高优先级运行。结果是,I/O密集型工作负载的性能不会受长时间运行的CPU作业的影响。该类还会应用nice值(如果已设置)。
IA:交互式类似于TS,但默认优先级略高。如今很少使用(以前用于改善图形X会话的响应性)。
FX:固定(未显示在图6.13中)是一种用于设置固定优先级的进程调度类,与TS相同的全局优先级范围(0-59)。
FSS:公平份额调度(未显示在图6.13中)在项目或区域之间管理进程的CPU使用,基于份额值。这使得项目组可以根据份额公平地使用CPU,而不是根据其线程或进程数量。每个进程组可以消耗一个根据其份额值除以该时刻系统上总繁忙份额计算出的CPU的部分。这意味着如果该组是唯一繁忙的组,它可以使用所有CPU资源。FSS在云计算中广泛使用,以便租户(区域)可以公平分配份额,并在可用且未使用时使用更多CPU。FSS存在于与TS相同的全局优先级范围(0-59)并具有固定的时间片。
SYSDC:系统责任周期调度类用于大量消耗CPU的内核线程,例如ZFS事务组刷新线程。它允许指定目标责任周期(CPU时间与可运行时间的比率),并将取消安排线程以匹配责任周期。这可以防止长时间运行的内核线程(否则将属于SYS类)挤占需要使用该CPU的其他线程。
中断:为了调度中断线程,它们被赋予优先级159 + IPL(参见第3章操作系统的第3.2.3节“中断和中断线程”)。
基于Solaris的系统还支持使用sched_setscheduler()设置的调度策略(未显示在图6.13中):SCHED_FIFO、SCHED_RR和SCHED_OTHER(时间共享)。
空闲线程是一个特殊情况,以最低优先级运行。
Idle Thread
内核的“空闲”线程(或空闲任务)在没有其他可运行的线程时在CPU上运行,并具有可能的最低优先级。通常,它被设计为通知处理器可以停止CPU执行(停机指令)或降低速度以节省电源。CPU将在下一个硬件中断唤醒。
NUMA Grouping
在NUMA系统上,通过使内核具备NUMA意识,可以显著提高性能,从而能够做出更好的调度和内存放置决策。这样可以自动检测并创建本地化CPU和内存资源的组,并将它们组织成反映NUMA架构的拓扑结构。这种拓扑结构允许估计任何内存访问的成本。
在Linux系统中,这些被称为调度域[3],其拓扑结构始于根域。
在基于Solaris的系统中,这些被称为局部性组(lgrps),并从根组开始。
系统管理员可以手动进行一种形式的分组,要么将进程绑定到仅在一个或多个CPU上运行,要么创建一个专门的CPU集合供进程运行。请参阅第6.5.10节“CPU绑定”。
Processor Resource-Aware
除了NUMA之外,CPU资源拓扑可以被内核理解,以便它可以做出更好的调度决策,用于电源管理和负载平衡。在基于Solaris的系统中,这是通过处理器组来实现的。
6.5 Methodology
这一部分介绍了CPU分析和调优的各种方法和练习。表6.5总结了相关主题。
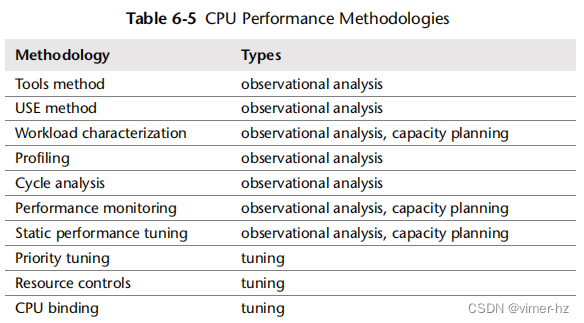
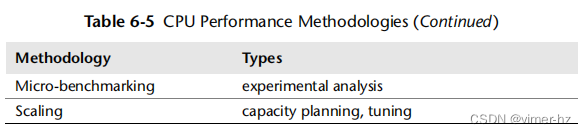
更多策略和这些内容的介绍,请参阅第2章“方法论”。您不需要使用它们的全部,可以将其视为一本食谱书,可以单独或组合使用其中的方法。
我的建议是按照以下顺序使用:性能监测、USE方法、性能分析、微基准测试和静态分析。
第6.6节“分析”展示了应用这些策略的操作系统工具。
6.5.1 Tools Method
工具方法是一个反复使用可用工具、检查其提供的关键指标的过程。虽然这是一种简单的方法论,但它可能忽视工具未提供良好或无法见到的问题,并且可能需要耗费大量时间来执行。
对于CPU,工具方法可以包括检查以下内容:
- uptime:检查负载平均值,以查看CPU负载随时间是增加还是减少。系统中的平均负载超过CPU数量通常表示饱和。
- vmstat:每秒运行一次,并检查空闲列,以查看可用空间。低于10%可能会出现问题。
- mpstat:检查单个繁忙(忙碌)的CPU,识别可能存在的线程可伸缩性问题。
- top/prstat:查看哪些进程和用户是最大的CPU消耗者。
- pidstat/prstat:将最大的CPU消耗者细分为用户时间和系统时间。
- perf/dtrace/stap/oprofile:为用户或内核时间分析CPU使用堆栈跟踪,以确定CPU被使用的原因。
- perf/cpustat:测量CPI。
如果发现问题,可以从可用工具的所有字段中检查以获取更多背景信息。有关每个工具的更多信息,请参阅第6.6节“分析”。
6.5.2 USE Method
USE 方法用于在性能调查的早期阶段,识别所有组件中的瓶颈和错误,在深入且耗时的策略之前进行。
对于每个 CPU,检查以下内容:
- 利用率(Utilization):CPU 忙碌的时间(不在空闲线程中)
- 饱和度(Saturation):可运行线程排队等待轮到它们在 CPU 上运行的程度
- 错误(Errors):CPU 错误,包括可纠正的错误
错误可能首先被检查,因为它们通常很快就可以检查,并且最容易解释。一些处理器和操作系统会感知到可纠正错误(纠错码,ECC)的增加,并在不可纠正错误导致 CPU 失效之前作为预防措施将 CPU 下线。检查这些错误可能仅仅是确认所有 CPU 仍然在线上。
利用率通常可以通过操作系统工具以百分比忙碌状态的形式轻松获得。应该针对每个 CPU 检查此指标,以检查是否存在可扩展性问题。也可以针对每个核心进行检查,以防止某个核心的资源被大量利用,从而阻止空闲的硬件线程执行。通过使用分析和周期分析,可以了解高 CPU 和核心利用率。
对于实现 CPU 限制或配额(资源控制)的环境,例如某些云计算环境中,CPU 利用率可能需要根据所施加的限制来衡量,除了物理限制之外。您的系统可能在物理 CPU 达到 100% 利用率之前就已经耗尽其 CPU 配额,比预期提前遇到饱和。
饱和度指标通常是系统范围内提供的,包括作为负载平均值的一部分。此指标量化了 CPU 过载的程度,或者如果存在 CPU 配额,则表示已经使用完。
6.5.3 Workload Characterization
在容量规划、基准测试和模拟工作负载中,对所施加的负载进行表征是很重要的。通过识别可以消除的不必要工作,也可以实现一些最大的性能提升。
用于表征 CPU 工作负载的基本属性包括:
- 负载平均数(利用率 + 饱和度)
- 用户时间与系统时间比率
- 系统调用速率
- 自愿上下文切换速率
- 中断速率
这些属性的目的是表征所施加的负载,而不是已交付的性能。负载平均数适合这一目的,因为它反映了所请求的 CPU 负载,而不考虑利用率/饱和度分布所显示的已交付性能。请参阅第 6.6.1 节“uptime”中的示例和进一步说明。
速率指标有点难以解释,因为它们既反映了所施加的负载,也在一定程度上反映了已交付的性能,这可能会限制它们的速率。
用户时间与系统时间比率显示了所施加的负载类型,正如在第 6.3.7 节“用户时间/内核时间”中介绍的那样。高用户时间率是由于应用程序花费时间执行它们自己的计算。高系统时间显示花费在内核中的时间,可以通过系统调用和中断率进一步理解。I/O 密集型工作负载具有较高的系统时间、系统调用以及自愿上下文切换速率,因为线程在等待 I/O 时会阻塞。
以下是一个工作负载描述示例,旨在展示这些属性如何一起表达:
在我们最繁忙的应用服务器上,负载平均值在一天中变化在 2 到 8 之间,具体取决于活跃客户端的数量。用户/系统比率为 60/40,因为这是一个 I/O 密集型工作负载,每秒执行约 100 K 个系统调用,并且有很高的自愿上下文切换率。
这些特征随着遇到不同负载而随时间变化。
Advanced Workload Characterization/Checklist
为了表征工作负载,可以包含额外的细节。以下列出的问题可作为考虑的指导,同时也可在深入研究 CPU 问题时起到检查表的作用:
- 整个系统的 CPU 利用率是多少?每个 CPU 呢?
- CPU 负载有多少并行性?是单线程的吗?有多少线程?
- 哪些应用程序或用户正在使用 CPU?使用量如何?
- 哪些内核线程正在使用 CPU?使用量如何?
- 中断的 CPU 使用率是多少?
- CPU 互连的利用率是多少?
- 为什么要使用 CPU(用户级和内核级调用路径)?
- 遇到了哪些类型的停滞周期?
请参阅第二章“方法论”以获得对该方法论以及要测量的特征(谁、为什么、什么、如何)的更高层次摘要。接下来的章节扩展了列表中的最后两个问题:如何使用分析来分析调用路径,以及如何使用周期分析来分析停滞周期。
6.5.4 Profiling
性能分析构建了一个研究对象的图像。CPU 使用情况可以通过在定时间隔采样 CPU 的状态来进行性能分析,具体步骤如下:
1. 选择要捕获的性能分析数据类型和频率。
2. 在定时间隔开始采样。
3. 等待感兴趣的活动发生。
4. 结束采样并收集样本数据。
5. 处理数据。
一些性能分析工具(包括 DTrace)允许在仍在进行采样时对捕获的数据进行实时处理和分析。
处理和浏览数据可能会受益于与用于收集数据的工具集不同的工具集。一个例子是火焰图(稍后介绍),它可以处理 DTrace 和其他性能分析工具的输出。另一个例子是 Oracle Solaris Studio 的性能分析器,它可以自动收集和浏览带有目标源代码的性能分析数据。
CPU 性能分析数据的类型基于以下因素:
- 用户级别、内核级别或两者兼而有之
- 函数和偏移量(基于程序计数器)、仅函数、部分堆栈跟踪或完整堆栈跟踪
选择同时捕获用户和内核级别的完整堆栈跟踪将捕获 CPU 使用情况的完整性能分析。然而,这通常会生成过多的数据。
仅捕获用户或内核部分堆栈(例如,深度为五级)甚至只捕获执行函数名称可能已经足以从更少的数据中识别 CPU 使用情况。
作为性能分析的简单示例,以下是一个 DTrace 单行命令,以 997 Hz 的频率对用户级别函数名称进行 10 秒的采样:


DTrace 已经执行了步骤 5,通过聚合函数名称并打印排序后的频率计数来处理数据。这表明,跟踪期间最常见的 on-CPU 用户级函数是 ut_fold_ulint_pair(),它被采样了 4,039 次。
使用 997 Hz 的频率可以避免与任何活动(例如以 100 或 1,000 Hz 运行的定时任务)同步采样。
通过采样完整的堆栈跟踪,可以识别 CPU 使用情况的代码路径,这通常指向 CPU 使用情况的更高级原因。在第 6.6 节“分析”中给出了更多采样的示例。此外,请参阅第五章“应用程序”,了解有关 CPU 性能分析的更多内容,包括从堆栈中获取其他编程语言上下文。
对于特定 CPU 资源(例如缓存和互连),性能分析可以使用基于 CPC 的事件触发器而不是定时间隔。这在下一节的周期分析中进行了描述。
6.5.5 Cycle Analysis
通过使用 CPU 性能计数器(CPCs),可以在周期级别了解 CPU 利用率。这可能会揭示周期是花费在一级、二级或三级缓存未命中、内存 I/O 或资源 I/O 上,或花费在浮点运算或其他活动上。这些信息可能通过调整编译器选项或更改代码来实现性能优化。
通过测量每指令周期数(CPI)开始进行周期分析。如果 CPI 较高,继续调查停滞周期的类型。如果 CPI 较低,寻找代码中减少执行指令的方法。对于“高”或“低” CPI 的值取决于您的处理器:低可能小于一,高可能大于十。您可以通过执行已知的以内存 I/O 或指令为主的工作负载,并测量每个工作负载的结果 CPI 来了解这些值。
除了测量计数器值外,CPC 还可以配置为在给定值溢出时中断内核。例如,每当发生 10,000 次二级缓存未命中时,可以中断内核以收集堆栈回溯。随着时间的推移,内核构建了导致二级缓存未命中的代码路径的概要,而无需测量每个未命中的繁重开销。这通常由集成开发环境(IDE)软件使用,以在引起内存 I/O 和停滞周期的位置上注释代码。使用 DTrace 和 cpc 提供程序也可以实现类似的可观察性。
周期分析是一项高级活动,可能需要几天的时间才能使用命令行工具进行,如第 6.6 节“分析”所示。您还应该花一些时间阅读您的 CPU 供应商的处理器手册。性能分析工具(如 Oracle Solaris Studio)可以节省时间,因为它们经过编程,可以找到您感兴趣的 CPC。
6.5.6 Performance Monitoring
性能监控可以在一段时间内识别出活动问题和行为模式。CPU 的关键指标包括:
利用率:表示占用率的百分比;
饱和度:可以通过运行队列长度(从负载平均值推导)或线程调度延迟来衡量;
应该按照每个 CPU 的基础进行利用率监控,以识别线程可扩展性问题。对于实现了 CPU 限制或配额(资源控制)的环境,如某些云计算环境,还需要记录与这些限制相比的 CPU 使用情况。
在监控 CPU 使用情况时面临的挑战是选择测量和存档的间隔。一些监控工具使用 5 分钟的间隔,但这可能会隐藏较短的 CPU 利用率突发。更倾向于使用每秒钟的测量,但您应该意识到即使在一秒钟内也可能存在突发。这些突发可以通过饱和度来识别。
6.5.7 Static Performance Tuning
静态性能调优侧重于已配置环境的问题。对于 CPU 性能,需要检查静态配置的以下方面:
可用于使用的 CPU 数量是多少?它们是核心吗?硬件线程吗?
CPU 架构是单处理器还是多处理器?
CPU 缓存的大小是多少?它们是共享的吗?
CPU 时钟速度是多少?它是动态的(例如,英特尔 Turbo Boost 和 SpeedStep)吗?这些动态功能在 BIOS 中启用了吗?
BIOS 中是否启用或禁用了其他与 CPU 相关的功能?
此处理器型号是否存在性能问题(缺陷)?它们是否列在处理器勘误表中?
此 BIOS 固件版本是否存在性能问题(缺陷)?
软件是否强制实施了 CPU 使用限制(资源控制)?是什么限制?
这些问题的答案可能揭示先前被忽视的配置选择。
最后一个问题尤其适用于云计算环境,其中 CPU 使用通常受限制。
6.5.8 Priority Tuning
Unix一直提供了一个用于调整进程优先级的nice()系统调用,它设置了一个nice值。正值nice值会导致较低的进程优先级(更nice),而负值nice值——只有超级用户(root)可以设置——会导致更高的优先级。出现了一个nice(1)命令,用于以nice值启动程序,并后来添加了renice(1M)命令(在BSD中),用于调整已运行进程的nice值。Unix第4版的man页面提供了这个示例:
对于希望执行长时间运行程序而不受管理人员干扰的用户,推荐使用值16。
今天,nice值仍然对调整进程优先级很有用。当CPU争用时,导致高优先级工作的调度器延迟时,这最为有效。您的任务是识别低优先级工作,其中可能包括监控代理和定期备份,这些工作可以通过设置nice值进行修改。还可以进行分析以检查调整是否有效,并确保对于高优先级工作,调度器延迟保持较低水平。
除了nice之外,操作系统可能会提供更高级的进程优先级控制,例如更改调度器类或调度策略,或更改类的调整。Linux和基于Solaris的内核都包括实时调度类,这可以允许进程抢占所有其他工作。尽管这可以消除调度器延迟(除了其他实时进程和中断之外),但请确保您了解后果。如果实时应用程序遇到多个线程进入无限循环的bug,可能会导致所有CPU对于所有其他工作不可用,包括手动修复问题所需的管理shell。这种特定情况通常只能通过重新启动系统来解决(糟糕!)。
6.5.9 Resource Controls
操作系统可以为分配CPU周期给进程或一组进程提供细粒度控制。这些控制可能包括对CPU利用率的固定限制和股份,以实现更灵活的方法——根据股份值允许使用空闲CPU周期。这些工作方式是与实现相关的,并在第6.8节“调优”中进行讨论。
6.5.10 CPU Binding
调整CPU性能的另一种方法涉及将进程和线程绑定到单独的CPU或CPU集合。这可以增加进程的CPU缓存热度,提高其内存I/O性能。对于NUMA系统,这也改善了内存局部性,同时也提高了性能。
通常有两种执行方式:
- 进程绑定:配置一个进程只在单个CPU上运行,或者仅在定义的一组CPU中选择一个CPU上运行。
- 独占CPU集:划分一组只能由分配给它们的进程使用的CPU。这可以进一步改善CPU缓存,因为当进程空闲时,其他进程无法使用CPU,使缓存保持温暖。
在基于Linux的系统上,可以使用cpusets实现独占CPU集方法。在基于Solaris的系统上,这称为处理器集。配置示例可在第6.8节“调优”中找到。
6.5.11 Micro-Benchmarking
有各种用于CPU微基准测试的工具,通常是测量执行简单操作所需的时间多次。这些操作可能基于以下内容:
- CPU指令:整数算术、浮点运算、内存加载和存储、分支和其他指令
- 内存访问:用于研究不同CPU缓存的延迟和主内存吞吐量
- 更高级别语言:类似于CPU指令测试,但使用高级解释或编译语言编写
- 操作系统操作:测试系统库和系统调用函数,如getpid()和进程创建等CPU限制操作
早期的CPU基准测试例子是国家物理实验室在1972年用Algol 60编写的Whetstone,旨在模拟科学工作负载。后来在1984年开发了Dhrystone基准测试,用于模拟当时的整数工作负载,并成为比较CPU性能的流行手段。这些基准测试,以及包括进程创建和管道吞吐量在内的各种Unix基准测试,被收录在一个名为UnixBench的集合中,最初来自莫纳什大学,并由BYTE杂志发布。近年来创建了更多CPU基准测试,用于测试压缩速度、素数计算、加密和编码等。
无论您使用哪种基准测试,在比较系统之间的结果时,重要的是要了解真正被测试的内容。像之前描述的这些基准测试经常会测试不同编译器版本之间的编译优化,而不是基准测试代码或CPU速度。许多基准测试也是单线程执行的,但这些结果在具有多个CPU的系统中失去意义。一个四CPU系统的基准测试可能略快于一个八CPU系统,但后者在提供足够的并行可运行线程时很可能会提供更大的吞吐量。
有关基准测试的更多信息,请参阅第12章“基准测试”。
6.5.12 Scaling
这里是一个基于资源容量规划的简单扩展方法:
1. 确定目标用户人口或应用请求速率。
2. 表达每个用户或每个请求的CPU使用率。对于现有系统,可以使用当前用户数量或请求速率监视CPU使用情况。对于未来系统,负载生成工具可以模拟用户,以便测量CPU使用率。
3. 当CPU资源利用率达到100%时,推断用户或请求。这为系统提供了理论极限。
系统可扩展性也可以建模以考虑争用和一致性延迟,以更真实地预测性能。有关此内容的更多信息,请参见第2章“方法论”中的第2.6节“建模”,以及同一章中有关扩展的第2.7节“容量规划”。
6.6 Analysis
本节介绍了针对基于Linux和Solaris操作系统的CPU性能分析工具。有关在使用这些工具时应遵循的策略,请参阅前一节。
本节中列出的工具见表6.6。
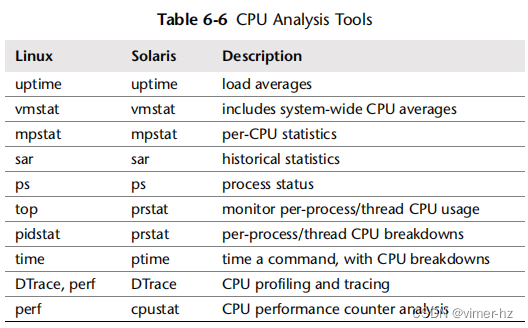
该列表首先介绍了用于CPU统计的工具,然后深入介绍了用于更深入分析的工具,包括代码路径分析和CPU周期分析。这是一组工具和功能,用于支持第6.5节“方法论”。有关每个工具的完整功能参考,请查阅每个工具的文档,包括其man页面。虽然您可能只对基于Linux或仅基于Solaris的系统感兴趣,但请考虑查看其他操作系统的工具以及它们提供的可观测性,以获得不同的视角。
6.6.1 uptime
uptime(1)是一些命令之一,用于打印系统的平均负载:

最后三个数字分别是1分钟、5分钟和15分钟的平均负载。通过比较这三个数字,您可以确定在过去的15分钟(左右)内负载是增加、减少还是保持稳定。
Load Averages
负载平均值表示对CPU资源的需求,计算方法是将正在运行的线程数(利用率)和排队等待运行的线程数(饱和度)相加。一种较新的计算负载平均值的方法是使用利用率加上线程调度延迟的总和,而不是采样队列长度,这有助于提高准确性。关于Solaris内核中这些计算的内部细节已在[McDougall 06b]中有记录。
要解释这个值,如果负载平均值高于CPU核心数量,那么没有足够的CPU来为线程提供服务,有些线程在等待。如果负载平均值低于CPU核心数量,那么(可能)意味着有剩余空间,线程可以在需要时在CPU上运行。
这三个负载平均数是指数衰减移动平均数,反映了超过1分钟、5分钟和15分钟时间的负载情况(实际上这些时间是指数移动求和中使用的常数[Myer 73])。图6.14展示了一个简单实验的结果,其中启动了一个单一的CPU密集型线程,并绘制了负载平均值。
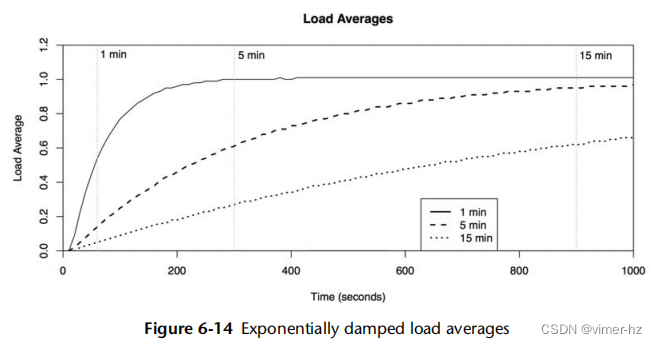
在1分钟、5分钟和15分钟的标记处,负载平均值已达到已知负载1.0的约61%。
负载平均值最早引入Unix系统中的早期BSD版本,基于调度器平均队列长度以及早期操作系统(如CTSS、Multics [Saltzer 70]、TENEX [Bobrow 72])中常用的负载平均值。这些负载平均值在[RFC 546]中有描述:
[1] TENEX负载平均值是对CPU需求的衡量。负载平均值是在给定时间段内可运行进程的平均值。例如,一个每小时负载平均值为10意味着(对于单CPU系统),在那一小时内的任何时刻都可以预期看到1个正在运行的进程和9个准备运行的进程(即未被I/O阻塞)等待CPU。
举个现代的例子,一个拥有64个CPU的系统的负载平均值为128。这意味着平均每个CPU始终有一个线程在运行,并且每个CPU都有一个线程在等待。同样的系统,如果负载平均值为10,表示有相当大的剩余空间,因为它可以在所有CPU都忙碌之前运行另外54个CPU密集型线程。
Linux Load Averages
目前,Linux将处于不可中断状态的执行磁盘I/O任务添加到负载平均值中。这意味着负载平均值不再仅仅表示CPU的剩余空间或饱和度,因为仅从数值本身无法确定它到底反映了多大程度的CPU负荷或磁盘负荷。同时,由于负载在不同的CPU和磁盘之间随时间变化,对三个负载平均数进行比较也变得困难。
另一种整合其他资源负载的方法是针对每种资源类型使用单独的负载平均值。(我曾为磁盘、内存和网络负载分别提供了各自的负载平均值示例,并发现这对非CPU资源提供了类似且有用的概览。)最好使用其他指标来了解Linux上的CPU负载,例如vmstat(1)和mpstat(1)提供的指标。
6.6.2 vmstat
虚拟内存统计命令vmstat(8)在最后几列中显示了系统范围的CPU平均值,并在第一列中显示可运行线程的计数。以下是Linux版本的示例输出:


输出的第一行是自引导以来的摘要,除了Linux上的r列——它开始显示当前值。各列含义如下:
- r:运行队列长度—可运行线程的总数(见下文)
- us:用户时间
- sy:系统时间(内核)
- id:空闲时间
- wa:等待I/O,用于衡量当线程在磁盘I/O上阻塞时CPU的空闲时间
- st:被窃取的时间(未在输出中显示),用于虚拟化环境中展示CPU时间用于为其他租户提供服务
除r列外,所有这些值都是跨所有CPU的系统范围平均值,r列则表示总数。
在Linux上,r列表示等待任务和正在运行任务的总数。man手册目前描述的内容是其他内容——“等待运行时间的进程数量”—这表明它仅计算等待的进程而不是正在运行的进程。作为对其预期含义的启示,在1979年由Bill Joy和Ozalp Babaoglu为3BSD编写的原始vmstat(1)以RQ列开始,用于表示可运行和正在运行的进程数量,就像目前的Linux vmstat(8)一样。man手册需要更新。
在Solaris上,r列仅计算位于分发队列(运行队列)中等待的线程数量。该值可能看起来不稳定,因为它仅每秒进行一次采样(从clock()中取样),而其他CPU列基于高分辨率CPU微状态。这些其他列目前不包括等待I/O或被窃取的时间。有关更多关于等待I/O的信息,请参阅第9章《磁盘》。
6.6.3 mpstat
多处理器统计工具mpstat可以按CPU报告统计信息。以下是Linux版本的一些示例输出:

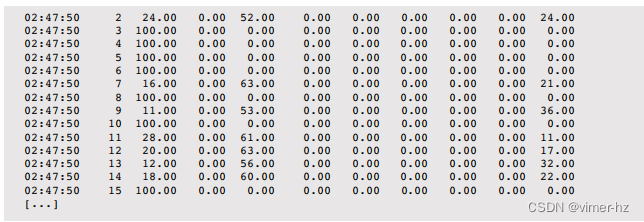
使用-P ALL选项可打印每个CPU的报告。默认情况下,mpstat(1)仅打印系统范围的摘要行(all)。各列含义如下:
- CPU:逻辑CPU ID,或用于总结的all
- %usr:用户时间
- %nice:具有nice'd优先级进程的用户时间
- %sys:系统时间(内核)
- %iowait:I/O等待时间
- %irq:硬件中断CPU使用率
- %soft:软件中断CPU使用率
- %steal:用于为其他租户提供服务的时间
- %guest:在虚拟机中花费的CPU时间
- %idle:空闲时间
关键列为%usr、%sys和%idle。这些列标识每个CPU的CPU使用情况,并显示用户时间/内核时间比率。这还可以识别“繁忙”CPU——那些运行在100%利用率(%usr+%sys)而其他CPU没有的情况,可能是由单线程应用程序工作负载或设备中断映射引起的。
对于基于Solaris的系统,mpstat(1M)从自引导以来的摘要开始,然后是间隔摘要。例如:

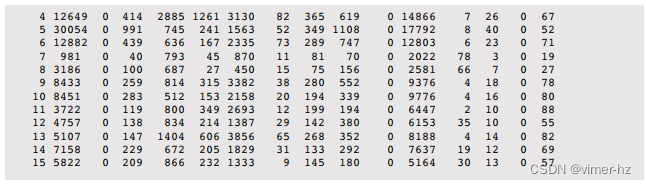
各列包括:
- CPU:逻辑CPU ID
- xcal:CPU之间的跨调用次数
- intr:中断次数
- ithr:作为线程服务的中断数量(较低的IPL)
- csw:上下文切换次数(总计)
- icsw:非自愿上下文切换次数
- migr:线程迁移次数
- smtx:互斥锁旋转次数
- srw:读者/写者锁旋转次数
- syscl:系统调用次数
- usr:用户时间
- sys:系统时间(内核)
- wt:等待I/O(已弃用,始终为零)
- idl:空闲时间
要检查的关键列包括:
- xcal,用于查看是否存在超额速率,这会消耗CPU资源。例如,查看在多个CPU上至少为1,000次/秒。通过详细分析可以解释其原因(参见第6.6.10节《DTrace》中的示例)。
- smtx,用于查看是否存在超额速率,这会消耗CPU资源,并且可能也是锁竞争的证据。可以使用其他工具来探索锁活动(参见第5章《应用程序》)。
- usr、sys和idl,用于描述每个CPU的CPU使用情况以及用户时间/内核时间比率。
6.6.4 sar
系统活动报告工具sar(1)可用于观察当前活动,并可配置为存档和报告历史统计信息。它在第4章《可观测性工具》中介绍,并在其他相关章节中提到。Linux版本提供以下选项:
- -P ALL:与mpstat -P ALL相同
- -u:与mpstat(1)的默认输出相同:仅系统范围的平均值
- -q:包括运行队列大小作为runq-sz(等待加运行,与vmstat的r相同)和负载平均值
Solaris版本提供:
- -u:%usr、%sys、%wio(零)和%idl的系统范围平均值
- -q:包括运行队列大小作为runq-sz(仅等待),以及运行队列中有线程等待的时间百分比作为%runocc,尽管该值在0到1之间不准确
Solaris版本不提供每CPU的统计信息。
6.6.5 ps
进程状态命令ps(1)列出所有进程的详细信息,包括CPU使用统计数据。例如:
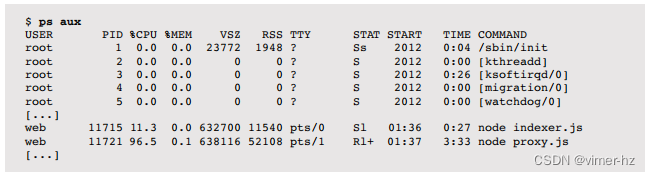
这种操作风格起源于BSD,可以通过在aux选项之前缺少破折号来识别。这些选项列出所有用户(a),具有扩展的面向用户的详细信息(u),并包括没有终端的进程(x)。终端显示在电传打字机(TTY)列中。
另一种风格来自SVR4,使用在选项之前带有破折号的方式:
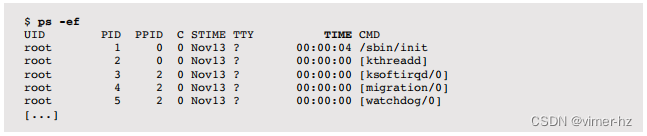
这将列出每个进程(-e),并显示完整详情(-f)。在大多数基于Linux和Solaris的系统上,ps(1)支持BSD和SVR4参数。
CPU使用的关键列是TIME和%CPU。
TIME列显示进程(用户+系统)自创建以来消耗的总CPU时间,以小时:分钟:秒为单位。
在Linux上,%CPU列显示前一秒钟跨所有CPU的CPU使用情况总和。单线程的CPU密集型进程将报告100%。双线程的CPU密集型进程将报告200%。
在Solaris上,%CPU已标准化为CPU数量。例如,在一个八核系统中,一个单线程的CPU密集型线程将显示为12.5%。该指标还显示最近的CPU使用情况,使用与负载平均值类似的衰减平均值。
ps(1)还提供各种其他选项,包括-o用于自定义输出和显示的列。
6.6.6 top
top(1)命令是由William LeFebvre在1984年为BSD系统创建的。他受到了VMS命令MONITOR PROCESS/TOPCPU的启发,该命令显示了消耗CPU最多的作业,包括CPU百分比和ASCII条形图直方图(但不包括数据列)。
top(1)命令监视顶部运行的进程,并以固定时间间隔更新屏幕。例如,在Linux上:

系统范围的摘要显示在顶部,进程/任务列表显示在底部,默认按照CPU消耗最高的进程进行排序。系统范围的摘要包括负载平均值和CPU状态:%us, %sy, %ni, %id, %wa, %hi, %si, %st。这些状态等同于之前描述的mpstat(1)打印的状态,并且是对所有CPU进行平均计算的。
CPU使用情况通过TIME和%CPU列显示,这两列是在前面关于ps(1)的部分中介绍的。
这个例子显示了一个TIME+列,与上面显示的列相同,但分辨率为百分之一秒。例如,“1:36.53”表示总共1分钟36.53秒的CPU时间。某些版本的top(1)提供了可选的“累计时间”模式,其中包括已退出的子进程的CPU时间。
在Linux上,默认情况下,%CPU列的值不会根据CPU核数进行归一化;top(1)将其称为“Irix模式”,以IRIX上的行为命名。可以切换到“Solaris模式”,该模式将CPU使用情况除以CPU核数。在这种情况下,在16 CPU服务器上运行的热点双线程进程将报告百分比CPU为12.5。
虽然top(1)通常是性能分析师的工具,但你应该意识到top(1)本身的CPU使用率可能会变得显著,并将top(1)作为CPU消耗最高的进程!这是由于可用的系统调用(open()、read()、close())及其在迭代/proc条目时的成本导致的。一些基于Solaris系统的top(1)版本通过保持文件描述符打开并调用pread()来减少开销,prstat(1M)工具也采用了这种方式。
由于top(1)对/proc进行快照,它可能会错过在快照被拍摄前就退出的短暂进程。这在软件构建过程中经常发生,因为CPU可能会被许多短暂的构建工具大量加载。一种用于Linux的top(1)变种,称为atop(1),使用进程记账来捕获短暂进程的存在,并将其包含在显示中。
6.6.7 prstat
prstat(1)命令被引入为“面向基于Solaris系统的top命令”。例如:
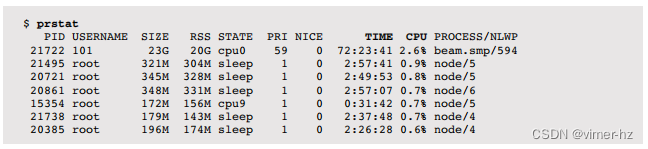
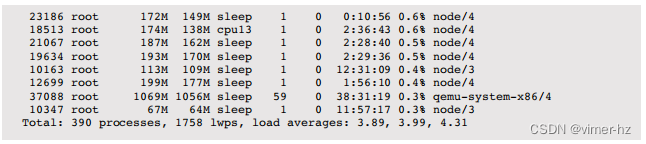
底部显示了一行系统摘要。CPU列显示最近的CPU使用情况,与Solaris上的top(1)显示的指标相同。TIME列显示已消耗的时间。
prstat(1M)通过使用保持文件描述符打开的方式,使用pread()读取/proc状态,而不是使用open()、read()、close()循环,从而消耗较少的CPU资源。
可以使用-m选项通过prstat(1M)打印线程微状态账户统计信息。以下示例使用-L按线程(每个LWP)报告此信息,并使用-c进行持续输出(而不是屏幕刷新):
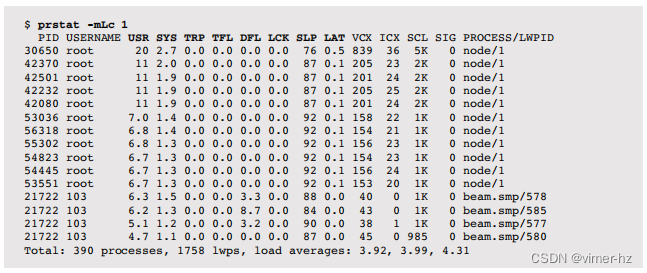
这八列显示了在每个微状态中所花费的时间,并总和为100%。它们分别是:
- USR: 用户时间
- SYS: 系统时间(内核)
- TRP: 系统陷阱
- TFL: 文本错误(可执行段的页面错误)
- DFL: 数据错误
- LCK: 等待用户级锁的时间
- SLP: 休眠时间,包括I/O阻塞
- LAT: 调度延迟(调度器队列延迟)
线程时间的这种分解非常有用。以下是进一步研究的建议路径(还可以参见第5章应用程序中的5.4.1节“线程状态分析”):
- USR: 用户级CPU使用率的分析
- SYS: 检查使用的系统调用并分析内核级CPU使用率
- SLP: 取决于休眠事件;跟踪系统调用或代码路径以获取更多详细信息
- LAT: 检查系统范围的CPU利用率和任何施加的CPU限制/配额
其中许多内容也可以使用DTrace来执行。
6.6.8 pidstat
Linux的pidstat(1)工具打印进程或线程的CPU使用情况,包括用户和系统时间的分解。默认情况下,仅打印活动进程的滚动输出。例如:
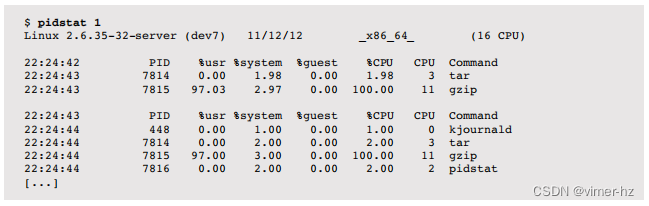
这个例子捕获了一个系统备份过程,涉及使用tar(1)命令从文件系统读取文件,并使用gzip(1)命令对其进行压缩。如预期的那样,gzip(1)的用户时间很高,因为它在压缩代码中变为CPU密集型。tar(1)命令在内核中花费了更多时间,从文件系统中读取数据。
可以使用-p ALL选项来打印所有进程,包括那些空闲的进程。-t用于打印每个线程的统计信息。其他pidstat(1)选项包含在本书的其他章节中。
6.6.9 time, ptime
time(1)命令可用于运行程序并报告CPU使用情况。它通常位于操作系统的/usr/bin目录下,也可以作为shell内建命令提供。
以下示例在一个大文件上两次运行time来计算cksum(1)命令的校验和:
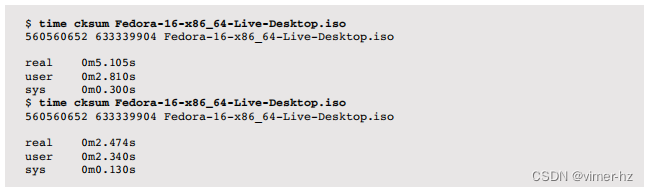
首次运行花费了5.1秒,其中有2.8秒是在用户模式下进行校验和计算,0.3秒是在系统模式下进行读取文件所需的系统调用。缺失的2.0秒(5.1 - 2.8 - 0.3)可能是在磁盘I/O读取上被阻塞的时间,因为这个文件只被部分缓存。第二次运行完成得更快,只用了2.5秒,几乎没有任何阻塞在I/O上的时间。这是可以预期的,因为第二次运行时,文件可能完全被缓存在主存中。
在Linux上,/usr/bin/time版本支持详细信息:
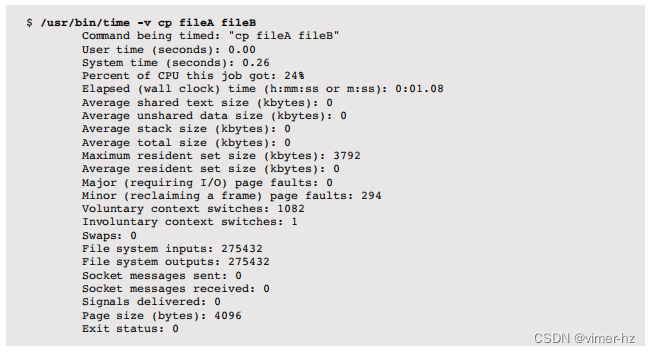
一般情况下,shell内建版本不提供-v选项。
基于Solaris的系统包括时间命令的另一个版本ptime(1),它基于线程微状态计算提供高精度的时间。如今,基于Solaris的系统上的time(1)最终使用相同的统计数据来源。ptime(1)仍然很有用,因为它提供了一个-m选项来打印完整的线程微状态时间集,包括调度器延迟(lat):

在这种情况下,运行时长为8.3秒,其中有6.4秒处于休眠状态(磁盘I/O)。
6.6.10 DTrace
DTrace可以用于对用户级和内核级代码的CPU使用情况进行分析,以及跟踪函数执行、CPU跨调用、中断和内核调度器。这些功能支持工作负载特征化、性能分析、深入分析和延迟分析。
以下部分介绍了在基于Solaris和Linux的系统上使用DTrace进行CPU分析。除非另有说明,DTrace命令适用于两种操作系统。第4章“可观测性工具”中包含了DTrace入门介绍。
Kernel Profiling
先前的工具,包括mpstat(1)和top(1),显示了系统时间——在内核中花费的CPU时间。DTrace可以用于确定内核正在做什么。
下面的一行命令在基于Solaris的系统上演示,在997 Hz的频率下对内核堆栈进行采样(以避免锁步,详见第6.5.4节“性能分析”)。谓词确保在进行采样时CPU处于内核模式,通过检查内核程序计数器(arg0)是否非零:

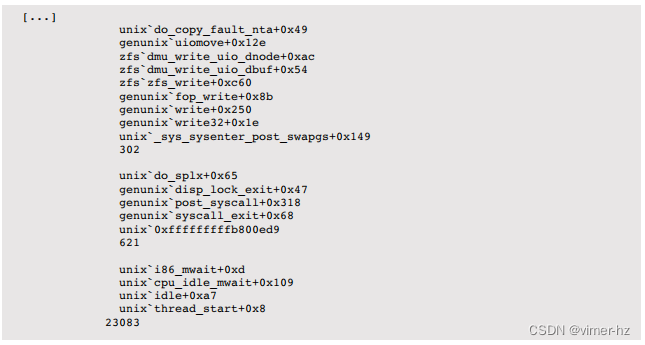
最频繁的堆栈最后打印出来,在这种情况下是空闲线程的堆栈,被采样了23,083次。对于其他堆栈,显示了顶部函数和祖先。
此输出中有许多页面被截断。以下一行命令展示了其他采样内核CPU使用情况的方法,其中一些将输出进一步压缩。
One-Liners
以997 Hz的频率采样内核堆栈:
![]()
以997 Hz的频率采样内核堆栈,仅显示前十个:
![]()
以997 Hz的频率采样内核堆栈,仅显示五个帧:
![]()
以997 Hz的频率采样内核上的CPU函数:
![]()
以997 Hz的频率采样内核上的CPU模块:
![]()
User Profiling
类似于内核,可以对用户模式下花费的CPU时间进行性能分析。以下一行命令通过检查arg1(用户PC)匹配用户级代码,并且还匹配名称为"mysqld"(MySQL数据库)的进程:
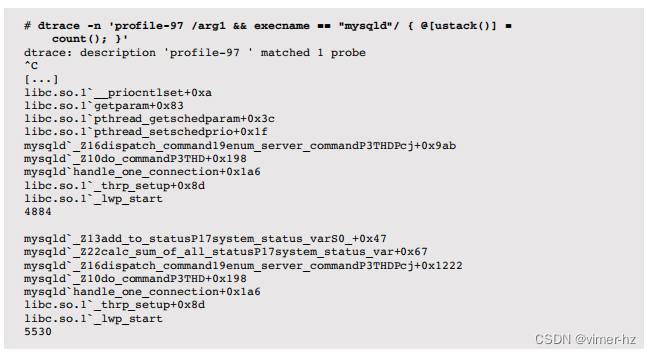
最后一个堆栈显示MySQL正在执行do_command()和calc_sum_of_all_status(),这两个函数经常执行在CPU上。堆栈帧看起来有点混乱,因为它们是C++签名(可以使用c++filt(1)工具来还原)。
以下一行命令展示了其他采样用户CPU使用情况的方法,前提是用户级操作是可用的(此功能目前尚未移植到Linux)。
One-Liners
以97 Hz的频率采样PID为123的用户堆栈:
![]()
以97 Hz的频率采样所有名称为"sshd"的进程的用户堆栈:
![]()
以97 Hz的频率采样系统上所有进程(在输出中包含进程名称)的用户堆栈:
![]()
以97 Hz的频率采样PID为123的用户堆栈,仅显示前十个:

以97 Hz的频率采样PID为123的用户堆栈,仅显示五个帧:
![]()
以97 Hz的频率采样PID为123的用户CPU函数:
![]()
以97 Hz的频率采样PID为123的用户CPU模块:
![]()
以97 Hz的频率采样PID为123的用户堆栈,包括在系统时间冻结期间用户堆栈的情况(通常在系统调用时):
![]()
以97 Hz的频率采样进程在哪个CPU上运行的信息,对PID为123的进程进行采样:
![]()
Function Tracing
虽然性能分析可以显示函数消耗的总CPU时间,但它并不显示这些函数调用的运行时分布。这可以通过使用跟踪和内置的vtimestamp来确定,vtimestamp是一个高分辨率时间戳,仅在当前线程在CPU上时递增。可以通过跟踪函数的进入和返回,并计算vtimestamp之间的差值来测量函数的CPU时间。例如,使用动态跟踪(fbt提供者)来测量内核ZFS zio_checksum_generate()函数中的CPU时间:
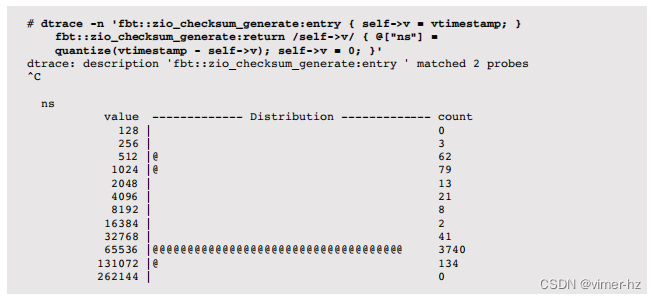
这个函数大部分时间消耗在65至131微秒的CPU时间范围内。这包括所有子函数的CPU时间。
如果该函数被频繁调用,这种特定的跟踪方式可能会增加开销。最好与性能分析结合使用,以便进行交叉检查。
如果可用,类似的动态跟踪也可以通过PID提供程序执行用户级代码。
通过fbt或pid提供程序进行动态跟踪被视为不稳定的接口,因为函数可能在不同版本之间发生变化。静态跟踪提供程序可用于跟踪CPU行为,旨在提供稳定的接口。这些包括用于跟踪CPU跨调用、中断和调度器活动的探针。
CPU Cross Calls
过多的CPU跨调用会由于它们的CPU消耗而降低性能。在引入DTrace之前,跨调用的来源很难确定。现在只需要一行命令,就可以追踪跨调用并显示导致它们的代码路径。
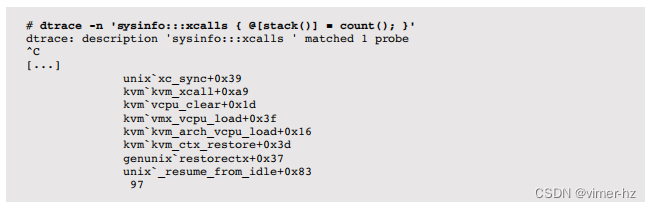
这是在一个基于Solaris的系统上使用sysinfo提供程序进行演示的。
Interrupts
DTrace允许跟踪和检查中断。基于Solaris的系统配备了intrstat(1M),这是一个基于DTrace的工具,用于总结中断CPU使用情况。
例如:
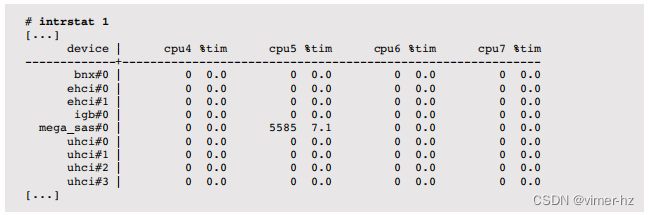
输出通常在多CPU系统上非常长,其中包括每个驱动程序在每个CPU上的中断计数和CPU时间百分比。前面的摘录显示mega_sas驱动程序占用了CPU 5的7.1%。
如果intrstat(1M)不可用(目前在Linux上就是这种情况),可以通过使用动态函数跟踪来检查中断活动。
Scheduler Tracing
调度器提供程序(sched)提供用于跟踪内核CPU调度器操作的探针。探针列在表6.7中。

由于许多这些事件发生在线程上下文中,curthread内置指的是相关的线程,并且可以使用线程局部变量。例如,可以使用线程局部变量(self->ts)来跟踪CPU运行时间:
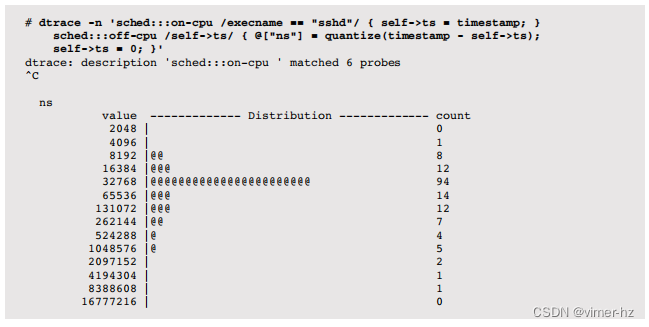
这对名为"sshd"的进程进行了CPU运行时间的跟踪。大部分时间它只在CPU上短暂运行,介于32到65微秒之间。
6.6.11 SystemTap
SystemTap也可以在Linux系统上用于跟踪调度器事件。请参阅第4章“可观测性工具”中的第4.4节“SystemTap”,以及附录E,以获取将前面的DTrace脚本转换的帮助。
6.6.12 perf
最初称为Linux性能计数器(PCL),perf(1)命令已经发展演变成了一套用于性能分析和跟踪的工具集,现在被称为Linux性能事件(LPE)。每个工具都作为一个子命令进行选择。例如,perf stat执行stat命令,提供基于CPC的统计信息。这些命令在USAGE消息中列出,下表列出了其中的一部分(来自版本3.2.6-3)。
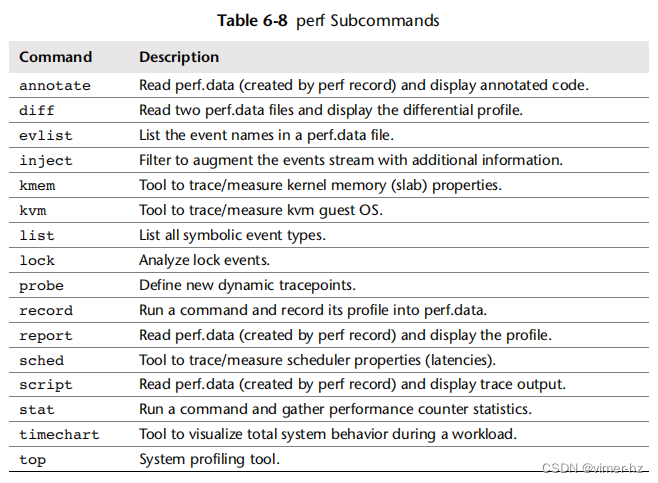
关键命令在接下来的章节中进行演示。
System Profiling
perf(1)可以用于对CPU调用路径进行性能分析,总结CPU时间在内核空间和用户空间中的消耗情况。这是通过record命令执行的,该命令以固定间隔捕获样本并保存到一个perf.data文件中。然后使用report命令查看该文件。
在下面的示例中,所有CPU(-a)以997Hz (-F 997)的速率对调用堆栈(-g)进行采样,持续10秒(sleep 10)。使用--stdio选项打印所有输出,而不是以交互模式运行。
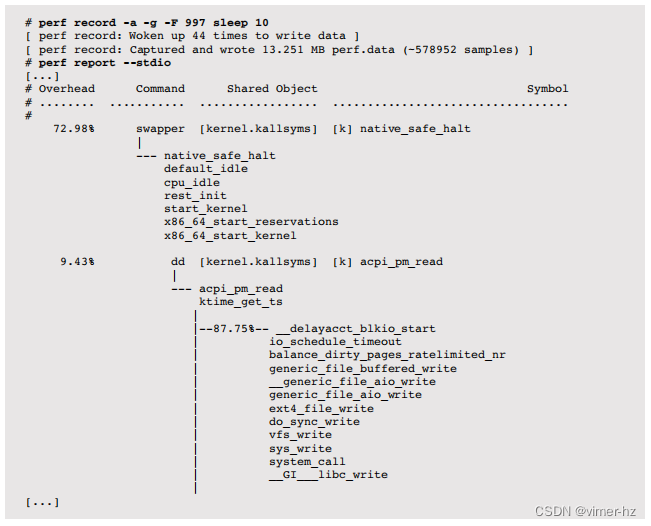
完整输出非常长,按降序样本计数顺序排列。这些样本计数以百分比形式给出,显示了CPU时间的消耗情况。这个示例表明,72.98% 的时间花费在空闲线程上,9.43% 的时间花费在 dd 进程上。在这9.43%中,87.5% 是由所示的堆栈组成,用于 ext4_file_write()。
这些内核和进程符号仅在其调试信息文件可用时才可用;否则将显示十六进制地址。
perf(1)通过为CPU循环计数器编程溢出中断来运行。由于现代处理器的周期频率变化,使用一个保持恒定的“缩放”计数器。
Process Profiling
除了跨所有CPU进行性能分析外,还可以针对单个进程进行操作。以下命令执行该命令并创建perf.data文件:

与之前一样,在查看报告时,perf(1)需要可用的调试信息来转换符号。
Scheduler Latency
sched命令记录并报告调度器的统计信息。例如:
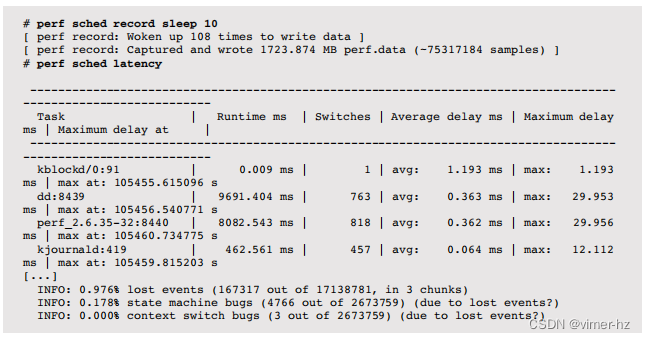
这显示了跟踪过程中的平均调度延迟和最大调度延迟。调度器事件频繁发生,因此这种类型的跟踪会带来CPU和存储开销。在这个示例中,进行10秒跟踪所生成的perf.data文件大小为1.7 GB。输出中的INFO行显示有一些事件被丢弃。这指出了DTrace模型在内核中进行过滤和聚合的优势:它可以在跟踪过程中总结数据,并仅将摘要传递到用户空间,从而最大限度地减少开销。
stat
stat命令基于CPC提供了CPU周期行为的高级摘要。在以下示例中,它启动了一个gzip(1)命令:
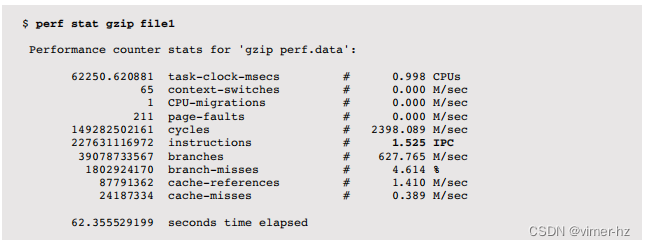
这些统计数据包括循环计数、指令计数以及IPC(CPI的倒数)。正如前面所述,这是一个非常有用的高级指标,可以确定发生的循环类型以及其中有多少是停顿循环。以下列出了其他可以检查的计数器:
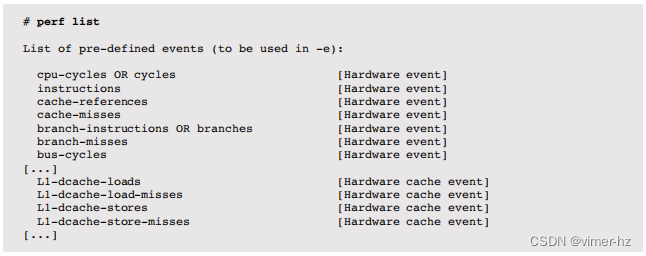
查找“硬件事件”和“硬件缓存事件”。可用的事件取决于处理器架构,并在处理器手册(例如,Intel软件开发人员手册)中有详细说明。这些事件可以使用-e参数进行指定。例如(以下示例来自Intel Xeon处理器):
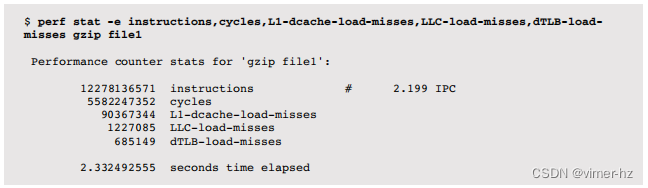
除了指令和周期之外,这个示例还测量了以下内容:
L1-dcache-load-misses:一级数据缓存加载未命中。这可以衡量应用程序由于一些加载操作从一级缓存返回后引起的内存加载。可以与其他一级事件计数器进行比较,以确定缓存命中率。
LLC-load-misses:最后一级缓存加载未命中。在最后一级缓存之后,访问主内存,因此这是主内存加载的度量。LLC-load-misses与L1-dcache-load-misses之间的差异(其他计数器需要用于完整性)可以给出CPU缓存在一级缓存以外的效果的一个概念。
dTLB-load-misses:数据转换查找缓冲器未命中。这显示了MMU缓存页面映射对工作负载的有效性,并可以度量内存工作负载(工作集)的大小。
还可以检查许多其他计数器。perf(1)支持使用描述性名称(例如本示例中使用的名称)和十六进制值。对于在处理器手册中找到的奇特计数器,可能需要使用后者,因为没有提供描述性名称。
注意:翻译时请遵循中国法律法规,不得提及敏感政治话题。
Software Tracing
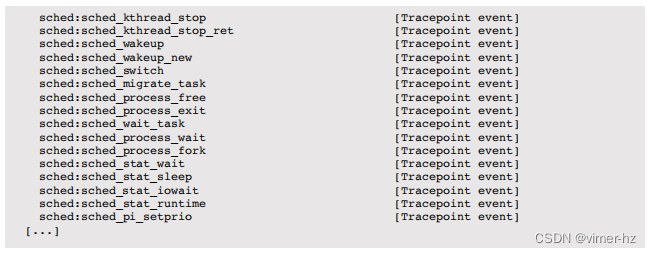
perf record -e可以与各种软件插装点一起使用,用于跟踪内核调度程序的活动。这些包括软件事件和跟踪点事件(静态探针),可以通过perf list列出。例如:

以下示例使用上下文切换软件事件来跟踪应用程序何时离开CPU,并在10秒内收集调用堆栈:
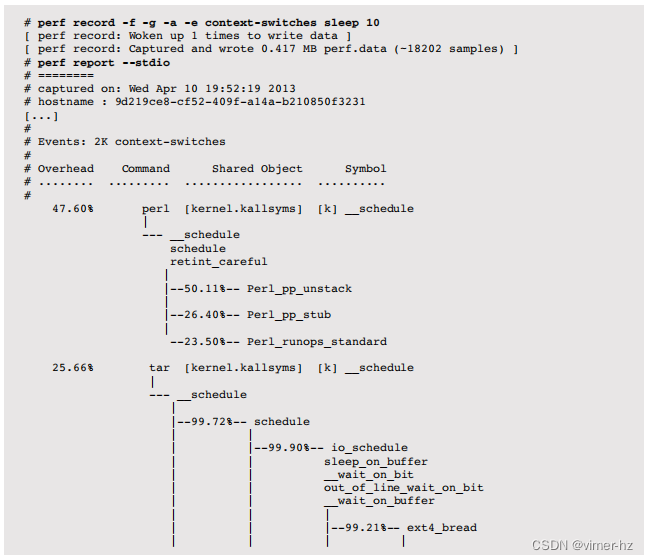
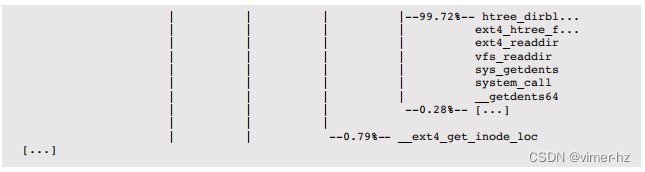
这个截断的输出展示了两个应用程序,perl和tar,以及它们在上下文切换时的调用堆栈。从堆栈中可以看出,tar程序正在进行文件系统(ext4)读取时处于睡眠状态。perl程序由于执行大量的计算任务而被非自愿地上下文切换,尽管单凭这个输出无法清楚地看出这一点。使用sched跟踪点事件可以找到更多信息。内核调度器函数也可以直接使用动态跟踪点(动态跟踪)进行跟踪,与静态探针一起,可以提供类似于之前从DTrace中看到的数据,尽管可能需要更多的后处理才能产生您所需的结果。
第9章“磁盘”中包括使用perf(1)进行静态跟踪的另一个示例:块I/O跟踪点。第10章“网络”中包含了使用perf(1)对tcp_sendmsg()内核函数进行动态跟踪的示例。
Documentation
有关更多关于perf(1)的信息,请参阅其man页面,在Linux内核源代码中tools/perf/Documentation下的文档,“Perf Tutorial”以及“The Unofficial Linux Perf Events Web-Page”。
6.6.13 cpustat
在基于Solaris的系统上,用于检查CPC的工具有cpustat(1M)用于系统范围分析,cputrack(1M)用于进程分析。这些工具使用性能仪器计数器(PICs)一词来指代CPC。
例如,要测量CPI,必须同时计算周期数和指令数。
使用PAPI名称:
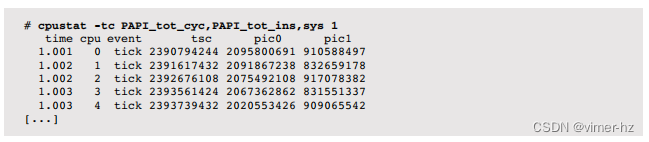
cpustat(1M)每个CPU生成一行输出。可以对此输出进行后处理(例如,使用awk),以便进行CPI计算。
使用sys标记,以便同时计算用户模式和内核模式的周期数。
这设置了第6.4.1节“硬件”中描述的CPU性能计数器标志。
使用特定于平台的事件名称测量相同的计数器:
![]()
运行cpustat -h以获取处理器支持的计数器的完整列表。输出通常以对供应商处理器手册的引用结束;例如:
请参阅“Intel 64和IA-32体系结构软件开发人员手册第3B卷:系统编程指南,第2部分”附录A,订货号:253669-026US,2008年2月。
这些手册详细描述了处理器的低级行为。
在同一时间内系统上只能运行一个cpustat(1M)实例,因为内核不支持多路复用。
6.6.14 Other Tools
其他Linux CPU性能工具包括:
- oprofile:John Levon开发的最初的CPU分析工具。
- htop:包括CPU使用情况的ASCII条形图,并且比原始的top(1)工具具有更强大的交互界面。
- atop:包含更多系统范围的统计信息,并使用进程记账来捕获短生命周期进程的存在。
- /proc/cpuinfo:可以读取此文件以查看处理器的详细信息,包括时钟速度和特性标志。
- getdelays.c:这是一个延迟记账可观察性的示例,并包括每个进程的CPU调度器延迟。在第4章“可观察性工具”中进行了演示。
- valgrind:一个内存调试和分析工具包,其中包含callgrind工具用于跟踪函数调用并收集调用图,可以使用kcachegrind进行可视化;还有cachegrind用于分析给定程序对硬件缓存的使用情况。
对于Solaris系统:
- lockstat/plockstat:用于锁分析,包括自适应互斥锁的自旋锁和CPU消耗(参见第5章“应用程序”)。
- psrinfo:处理器状态和信息(-vp选项)。
- fmadm faulty:用于检查是否由于可纠正的ECC错误增加而对CPU进行预测性故障。还可以参考fmstat(1M)。
- isainfo -x:列出处理器特性标志。
- pginfo、pgstat:处理器组统计信息,显示CPU拓扑和CPU资源共享情况。
- lgrpinfo:用于本地性组统计信息。这对于检查lgrps是否正在使用(需要处理器和操作系统支持)可能很有用。
还有一些复杂的CPU性能分析产品,包括Oracle Solaris Studio,适用于Solaris和Linux系统。
6.6.15 Visualizations
CPU使用率在历史上通常被可视化为利用率或负载平均值的折线图,包括最初的X11负载工具(xload(1))。这些折线图是显示变化的有效方式,因为可以通过视觉比较幅度。它们还可以显示随时间变化的模式,正如第2章“方法论”的第2.9节“监控”中所示。
然而,每个CPU利用率的折线图无法随着今天所见到的CPU数量扩展,特别是对于涉及数万个CPU的云计算环境——10000条线的图表可能会变得混乱不堪。
其他以折线图形式绘制的统计数据,包括平均值、标准差、最大值和百分位数,提供了一些价值并且可以扩展。然而,CPU利用率通常是双峰的——由空闲或接近空闲的CPU组成,然后一些CPU的利用率达到100%——这些统计数据无法有效传达这种情况。通常需要研究完整的分布情况。利用率热图使这成为可能。
接下来的部分介绍CPU利用率热图、CPU亚秒偏移热图和火焰图。我创建这些可视化类型来解决企业和云性能分析中的问题。
Utilization Heat Map
利用率随时间的变化可以呈现为热图,每个像素的饱和度(深浅)显示了在该利用率和时间范围内的CPU数量。热图是在第2章“方法论”中介绍的。
图6.15展示了整个数据中心(可用区)的CPU利用率,该数据中心运行着一个公共云环境。它包括超过300台物理服务器和5312个CPU。
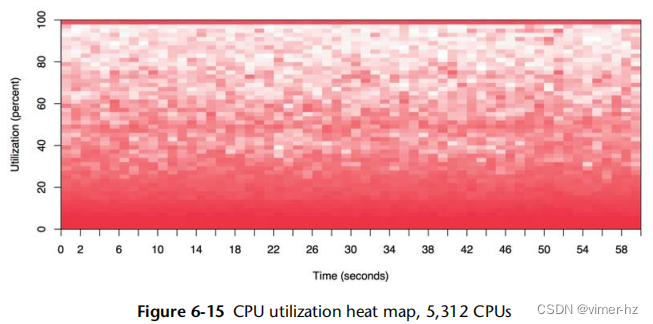
在这个热图的底部较暗的阴影显示大多数CPU的利用率在0%到30%之间。然而,顶部的实线显示随着时间的推移,也有一些CPU的利用率达到100%。实线颜色较深表明不止一个CPU达到了100%利用率。
这种特定的可视化是由实时监控软件(Joyent Cloud Analytics)提供的,该软件允许通过点击选择点以显示更多细节。在这种情况下,可以点击100%的CPU线以显示这些CPU所属的服务器,以及驱动CPU达到此利用率的租户和应用程序。
Subsecond-Offset Heat Map
这种热图类型允许检查每秒内的活动情况。CPU活动通常以微秒或毫秒为单位进行测量;将这些数据报告为整秒的平均值可能会丢失有用的信息。这种热图将亚秒偏移放在y轴上,每个偏移处的非空闲CPU数量由饱和度表示。这样可以将每秒可视化为一列,并从底部到顶部进行"绘制"。
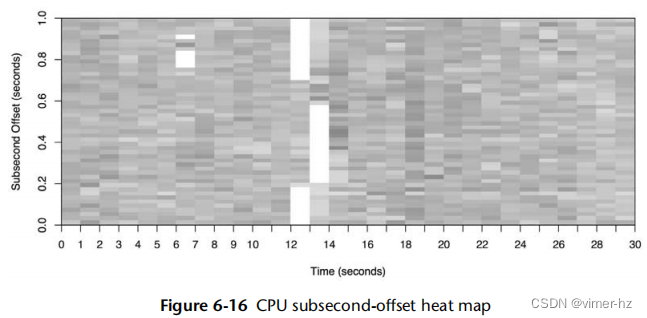
图6.16展示了一个云数据库(Riak)的CPU亚秒偏移热图。这个热图的有趣之处不在于CPU忙于为数据库提供服务的时间,而是那些未忙碌的时间,这些时间通过白色的列来表示。这些间隔的持续时间也很有趣:在这段时间内,数据库线程没有一个处于CPU上,持续了数百毫秒。这导致发现了一个锁定问题,导致整个数据库每次被阻塞数百毫秒。
如果我们使用折线图来检查这些数据,每秒CPU利用率的下降可能会被视为可变负载并且不会进一步调查。
Flame Graphs
分析堆栈跟踪是解释CPU使用率的有效方法,可以显示哪些内核或用户级别的代码路径是负责的。然而,它可能会产生数千页的输出。火焰图可视化了配置文件中的堆栈帧,以便更快、更清晰地理解CPU使用情况。
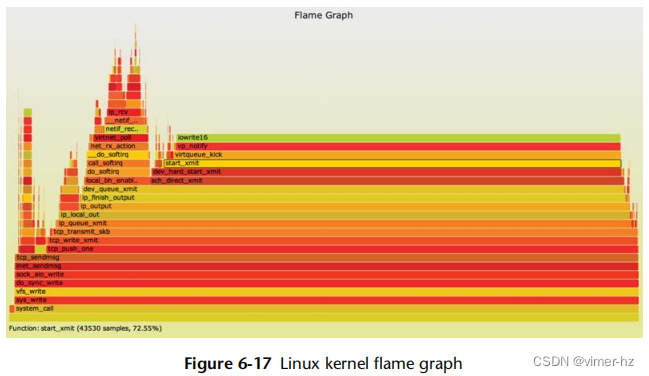
火焰图可以基于DTrace、perf或SystemTap的数据构建。图6.17的示例展示了使用perf对Linux内核进行配置文件分析的情况。
火焰图具有以下特点:
- 每个方框代表堆栈中的一个函数(一个"堆栈帧")。
- y轴显示堆栈深度(堆栈上的帧数)。顶部的方框显示正在运行的函数,其下方是祖先函数。一个函数的下方是其父函数,就像之前显示的堆栈跟踪一样。
- x轴跨越采样数据集。它不显示从左到右的时间流逝,与大多数图表不同。左到右的排序没有意义(按字母顺序排序)。
- 方框的宽度显示它在CPU上或作为CPU上祖先的一部分所花费的总时间(基于采样计数)。宽的方框函数可能比窄的方框函数慢,或者它们可能只是被更频繁地调用。调用计数不显示(也无法通过采样获知)。
- 如果有多个线程并行运行和采样,采样计数可能超过经过的时间。
- 颜色没有实际意义,并且是随机选择的温暖色调。它被称为"火焰图",因为它显示了在CPU上的热点。
火焰图也是交互式的。它是一个包含嵌入式JavaScript程序的SVG文件,在浏览器中打开后,可以将鼠标悬停在元素上以在底部显示详细信息。在图6.17的示例中,highlighted的是start_xmit()函数,显示它在采样堆栈中出现了72.55%的次数。
6.7 Experimentation
这一部分介绍了用于主动测试CPU性能的工具。有关背景信息,请参阅第6.5.11节“微基准测试”。
在使用这些工具时,建议保持mpstat(1)持续运行,以确认CPU使用率和并行性。
6.7.1 Ad Hoc
虽然这很琐碎且不会测量任何东西,但它可以作为一个有用的已知工作负载,用于确认可观察性工具所显示的内容是否与其声称的一致。这将创建一个CPU密集型的单线程工作负载(“在一个CPU上高负荷”):

这是一个Bourne shell程序,在后台执行一个无限循环。一旦不再需要它,就需要将其终止。
6.7.2 SysBench
SysBench系统基准套件具有一个简单的CPU基准测试工具,用于计算素数。例如:
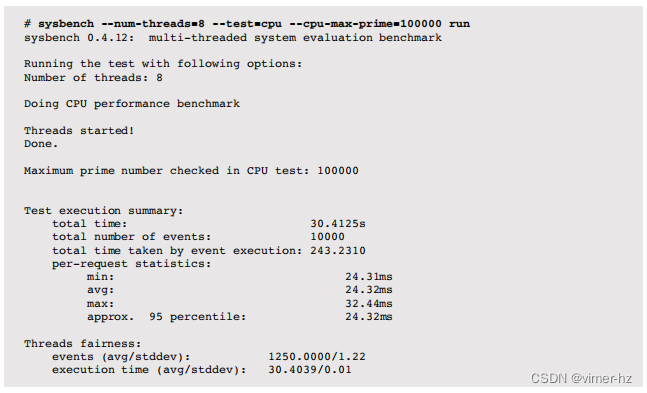
这个命令使用了八个线程,最大素数为100,000。运行时间为30.4秒,可以与其他系统或配置的结果进行比较(假设许多条件相同,如使用相同的编译器选项构建软件;请参阅第12章“基准测试”)。
6.8 Tuning
对于CPU来说,通常能够带来最大性能提升的是消除不必要的工作,这是一种有效的优化方式。第6.5节“方法论”和第6.6节“分析”介绍了许多分析和识别执行的工作的方法,帮助您找出任何不必要的工作。还介绍了其他调优方法:优先级调优和CPU绑定。本节包括这些以及其他调优示例。
调优的具体内容——可用的选项以及如何设置它们——取决于处理器类型、操作系统版本和预期工作负载。以下按类型组织提供了一些可能可用的选项以及它们的调优示例。前面的方法论部分提供了关于何时以及为什么要调优这些可调整参数的指导。
6.8.1 Compiler Options
编译器以及它们为代码优化提供的选项可以对CPU性能产生显著影响。常见的选项包括选择64位而不是32位进行编译,并选择一定程度的优化。编译器优化在第5章“应用程序”中有所讨论。
6.8.2 Scheduling Priority and Class
nice(1)命令可用于调整进程优先级。正nice值降低优先级,负nice值增加优先级,只有超级用户可以设置。取值范围为-20到+19。例如:
![]()
使用nice值为19的命令 - 这是nice可以设置的最低优先级。要更改已经运行进程的优先级,请使用renice(1)命令。
在Linux上,chrt(1)命令可以直接显示和设置调度优先级以及调度策略。调度优先级也可以使用setpriority()系统调用直接设置,并且优先级和调度策略可以使用sched_setscheduler()系统调用设置。
在Solaris上,您可以使用priocntl(1)命令直接设置调度类和优先级。例如:
![]()
这将将目标进程ID设置为以实时调度类运行,优先级为10。在设置此项时要小心:如果实时线程消耗了所有的CPU资源,可能会导致系统死机。
6.8.3 Scheduler Options
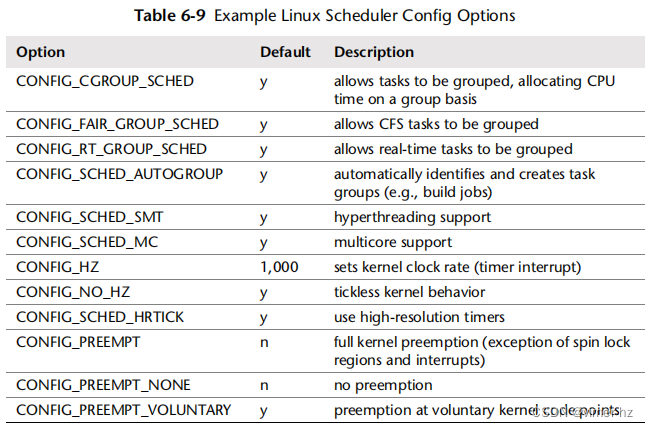
您的内核可能会提供可调参数来控制调度程序行为,尽管这些参数可能永远不需要调整。在Linux系统上,可以设置配置选项,包括从3.2.6内核中的表6.9中的示例,使用的是Fedora 16的默认值。
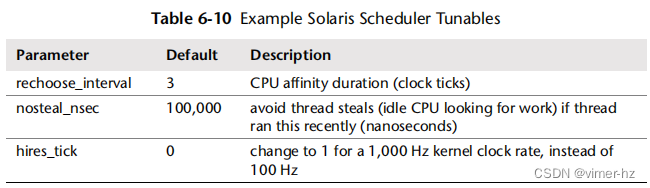
一些Linux内核提供额外的可调参数(例如,在/proc/sys/sched中)。在基于Solaris的系统上,表6.10中显示的内核可调参数修改调度程序行为。作为参考,找到您操作系统版本的相应文档(例如,对于Solaris,是Solaris可调参数参考手册)。这样的文档应该列出关键的可调参数、它们的类型、何时设置它们、它们的默认值以及有效范围。在使用这些参数时要小心,因为它们的范围可能没有经过充分测试。(根据公司或供应商政策,可能也禁止调整它们。)
Scheduler Class Tuning
基于Solaris的系统还提供了一种通过dispadmin(1)命令修改调度类别使用的时间量和优先级的方式。例如,可以打印出用于时间共享调度类别(TS)的可调参数表(称为调度程序表):
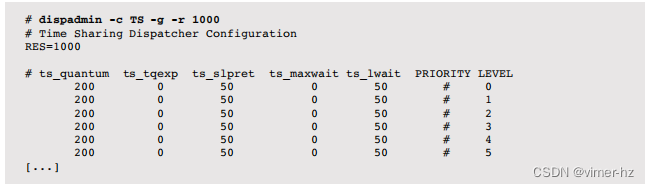
这个输出包括:
- ts_quantum:时间量子(以毫秒为单位,使用 -r 1000 来设置分辨率)
- ts_tqexp:线程使用完当前时间量子后提供的新优先级(降低优先级)
- ts_slpret:线程休眠后(I/O)唤醒后的新优先级(优先级提升)
- ts_maxwait:在晋升到 ts_lwait 中的优先级之前等待 CPU 的最长时间(以秒为单位)
- 优先级级别:优先级值
这些内容可以写入文件,进行修改,然后通过 dispadmin(1M)重新加载。您应该有充分理由这样做,比如首先使用 DTrace 测量优先级争用和调度程序延迟。
6.8.4 Process Binding
一个进程可以绑定到一个或多个CPU,这可能会通过提高缓存热度和内存局部性来提高其性能。在Linux上,可以使用taskset(1)命令来执行此操作,它可以使用CPU掩码或范围来设置CPU亲和性。例如:

这将 PID 10790 设置为仅在 CPU 7 到 10 上运行。
在基于Solaris的系统上,可以使用 pbind(1) 来执行此操作。例如:

这将 PID 11901 设置为在 CPU 10 上运行。无法指定多个CPU。要实现类似的功能,请使用独占的CPU集合。
6.8.5 Exclusive CPU Sets
Linux提供了cpusets,允许将CPU分组并将进程分配给它们。这类似于进程绑定,可以改善性能,但通过使cpuset独占,性能可以进一步提高 — 防止其他进程使用它。权衡是系统中可用CPU的减少。
以下是一个注释示例,创建一个独占集合:
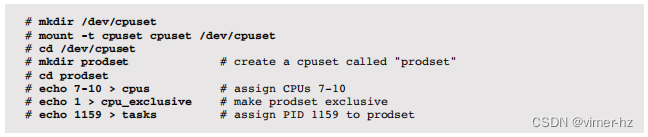
有关详细信息,请参阅cpuset(7)手册页。
在Solaris上,您可以使用psrset(1M)命令创建独占的CPU集合。
6.8.6 Resource Controls
除了将进程与整个CPU关联起来,现代操作系统还提供了资源控制,用于对CPU使用量进行精细化分配。
基于Solaris的系统具有用于进程或进程组的资源控制(从Solaris 9开始引入),称为项目。使用公平份额调度程序和份额,可以灵活地控制CPU使用情况,这些控制方式决定了空闲CPU如何被需要的人消耗。还可以设定限制,以控制总CPU利用率,用于那些一致性比份额的动态行为更可取的情况。
对于Linux,有容器组(cgroups),也可以通过进程或进程组来控制资源使用。可以使用份额来控制CPU使用情况,CFS调度程序允许设定固定限制(CPU带宽),即按照每个间隔分配微秒的CPU周期。CPU带宽是相对较新的功能,自2012年(3.2版)开始添加。
《云计算》第11章描述了管理OS虚拟化租户的CPU使用情况的用例,包括如何同时使用份额和限制。
6.8.7 Processor Options (BIOS Tuning)
处理器通常提供设置来启用、禁用和调整处理器级功能。在x86系统上,这些设置通常在启动时通过BIOS设置菜单访问。
这些设置通常默认提供最大性能,不需要进行调整。我今天调整这些设置最常见的原因是为了禁用Intel Turbo Boost,以便CPU基准测试以一致的时钟速率执行(请注意,对于生产使用,Turbo Boost 应该启用以获得稍微更快的性能)。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









