







系列
目录
os.path.isfile() 和 os.path.isdir()
time.localtime([timestamp]) 获取当地时间
time.strftime(format[, t]) 格式化
random.sample(population, k) 抽样
module 模块指什么
Python模块就是包含Python代码的文件,模块名就是文件名(去掉.py后缀)。模块可以包含函数、类、变量等。模块可以提高代码的可维护性和重复使用,避免函数名和变量名冲突。
typing 数据类型
Python的typing库提供了类型提示的功能,可以在代码中指定参数和返回值的类型。
int 整数
def add_numbers(a: int, b: int) -> int:
return a + bfloat 浮点数
def divide_numbers(a: float, b: float) -> float:
return a / bstr 字符串
def greet(name: str) -> str:
return "Hello, " + name + "!"bool 布尔值
def is_positive(number: int) -> bool:
return number > 0TypeVar 类型变量
from typing import TypeVar
T = TypeVar('T')
def get_first_element(arr: list[T]) -> T:
return arr[0]functools 高阶函数工具
functools 是 Python 的一个内置模块,它提供了对高阶函数(接受其他函数作为参数的函数)的支持,以及一些有用的工具函数。
functools.partial() 函数偏置
partial() 是一个非常有用的函数,它用于将一个函数的某些参数固定下来,返回一个新的函数。这样,你就可以创建一个新的函数,该函数在调用时将始终使用指定的参数值。
下面的例子将message参数固定下来,生成了一个函数
from functools import partial
def greet(name, message):
print(f"{message}, {name}!")
greet_with_hello = partial(greet, message="Hello")
greet_with_hello("Alice") # 输出: Hello, Alice!再举个例子,
import functools
int2 = functools.partial(int, base=2)
int2('1000000') # 64
functools.lru_cache() 函数缓存
lru_cache() 是一个装饰器,它可以用来为 Python 函数添加缓存功能。它使用 LRU(最近最少使用)策略来缓存函数调用的结果。当同一个函数被多次调用时,它可以提高性能,因为它可以避免重复计算。
from functools import lru_cache
@lru_cache(maxsize=128)
def fibonacci(n):
if n <= 1:
return n
return fibonacci(n-1) + fibonacci(n-2)
print(fibonacci(10)) # 输出: 55 (因为结果被缓存了)sorted 排序
与sort方法不同,sorted()函数会生成一个新的列表,而不是在原始的列表上进行操作。
列表排序
list.sort() # 列表排序
list.reverse() # 列表逆序元组排序
sorted(tuple) # 元组排序
reversed(tuple) # 元组逆序字符串排序(按长度)
words = ["apple", "banana", "cherry"]
sorted_words = sorted(words, key=len)
print(sorted_words) # ['apple', 'cherry', 'banana']字符串排序(按字典序)
strings = ["apple", "banana", "cherry", "date"]
sorted_strings = sorted(strings)
print(sorted_strings) # ['apple', 'banana', 'cherry', 'date']类排序
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def __lt__(self, other):
# 实现 less than方法,来实现排序
return self.age < other.age
people = [Person("Alice", 25), Person("Bob", 30), Person("Charlie", 20)]
sorted_people = sorted(people)
print([p.name for p in sorted_people]) # ['Charlie', 'Alice', 'Bob']Lambda表达式排序
# 对元组列表按照第一个元素升序排序
my_list = [(2, 'b'), (3, 'c'), (1, 'a')]
sorted_list = sorted(my_list, key=lambda x: x[0])
print(sorted_list) # 输出 [(1, 'a'), (2, 'b'), (3, 'c')]copy 复制
copy.copy() 浅拷贝
浅拷贝是指创建一个新对象,但是这个新对象中的元素是原对象的引用。新对象中的元素和原对象中的元素指向同一个内存地址。
import copy
list1 = [1, 2, [3, 4]]
list2 = copy.copy(list1)
print(list1) # [1, 2, [3, 4]]
print(list2) # [1, 2, [3, 4]]
list1[2][0] = 5
print(list1) # [1, 2, [5, 4]]
print(list2) # [1, 2, [5, 4]] # 修改一个元素,另一个元素也会发生变化copy.deepcopy() 深拷贝
在 Python 中,可以使用 copy 模块中的 deepcopy() 函数来实现二维数组的任意拷贝。deepcopy() 函数可以递归地复制对象中的所有元素,包括嵌套的对象。
import copy
# 原始二维数组
arr = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
# 使用 deepcopy() 函数进行拷贝
arr_copy = copy.deepcopy(arr)
# 修改拷贝后的数组
arr_copy[0][0] = 0
# 打印原始数组和拷贝后的数组
print("原始数组:", arr)
print("拷贝后的数组:", arr_copy)heapq 堆
heapq是一个Python内置模块,提供了对堆队列(heap queue)的基本支持。它可以对可迭代对象进行原地堆排序并返回一个排序后的列表。
heapq.heappush() 创建小顶堆
import heapq
a = [] #创建一个空堆
heapq.heappush(a,18)
heapq.heappush(a,1)
heapq.heappush(a,20)
heapq.heappush(a,10)
heapq.heappush(a,5)
heapq.heappush(a,200)
print(a) # [1, 5, 10, 18, 20, 200]
heapq.nsmallest() 获取前n个最小值
import heapq
a = [1, 5, 0, 100]
n_small_list = heapq.nsmallest(3, a) # [1, 5, 10]heapq.heapfy() 列表转小顶堆
import heapq
a = [1, 5, 200, 18, 10, 200]
heapq.heapify(a)
print(a) # [1, 5, 200, 18, 10, 200]
os 操作系统
os模块是Python标准库中的一个用于访问操作系统功能的模块,提供了一种可移植的方法使用操作系统的功能。
path 路径
os.path.join() 拼接
用于将多个路径组件合并为一个路径。
import os
path = os.path.join("a", "b", "c")
print(path) # 输出 a\b\cos.path.abspath() 绝对路径
返回文件的绝对路径。
import os
path = os.path.abspath("a/b/c")
print(path) # D:\Code\CodePython\test-0811\a\b\cos.path.dirname() 获取目录
返回路径的目录名。
import os
path = os.path.abspath("a/b/c")
print(os.path.dirname(path)) # 输出目录信息 D:\Code\CodePython\test-0811\a\bos.path.basename() 获取文件名
返回路径的基本文件名。
import os
path = os.path.abspath("a/b/c")
print(os.path.basename(path)) # 输出目录信息 cos.path.exists() 检测目录是否存在
检查文件或目录是否存在。
import os
exists = os.path.exists("a/b/c")
print(exists) # 输出: True 或 False,取决于文件或目录是否存在os.path.isfile() 和 os.path.isdir()
检查给定的路径是否是一个文件或目录。
import os
exists = os.path.exists("a/b/c")
print(os.path.isfile("a/b/c")) # 输出: True 或 False,取决于是文件还是目录
print(os.path.isdir("a/b/c")) # 输出: True 或 False,取决于是文件还是目录os.getcwd() 获取当前工作目录
得到当前工作目录,即当前python脚本工作的目录路径。
import os
print(os.getcwd()) # 输出目录
print(os.getcwdb()) # 输出目录的字节类型
print(type(os.getcwdb())) # 输出目录的字节类型 <class 'bytes'>
os.getenv()和os.putenv() 环境变量
分别用来读取和设置环境变量。
import os
print(os.getenv("path")) # C:\WINDOWS;C:\WINDOWS\system32;C:\WINDOWS\System32\Wbem;...os.listdir() 返回目录信息
返回指定目录下第一层的所有文件和目录名。
import os
print(os.listdir()) # ['.idea', 'main.py', 'main1.py', 'main2.py', 'main3.py', 'main32.py', 'resources']
os.stat(file) 获取文件属性
获得文件属性。
import os
print(os.stat(r"D:\Code\CodePython\test-0811\main32.py"))
# os.stat_result(st_mode=33206, st_ino=30680772461484765 ...具体含义
`st_mode`:文件类型和访问权限的标志位,可以通过 `stat.S_ISDIR()` 和 `stat.S_ISREG()` 等函数判断文件类型。
`st_ino`:文件的 inode 号,唯一标识一个文件。
`st_dev`:文件所在的设备号。
`st_nlink`:文件的硬链接数。
`st_uid`:文件所有者的用户 ID。
`st_gid`:文件所有者的组 ID。
`st_size`:文件大小,单位是字节。
`st_atime`:文件的最近访问时间,是一个时间戳。
`st_mtime`:文件的最近修改时间,是一个时间戳。
`st_ctime`:文件的创建时间,是一个时间戳。
os.chmod(file) 修改文件权限
import os, sys, stat
# 假定 /tmp/foo.txt 文件存在,设置文件可以通过用户组执行
os.chmod("/tmp/foo.txt", stat.S_IXGRP)os.mkdir(name) 创建目录
创建一个名为 path 的目录,应用以数字表示的权限模式 mode。
如果目录已存在,则抛出 FileExistsError 异常。
某些系统会忽略 mode。如果没有忽略它,那么将首先从它中减去当前的 umask 值。如果除最后 9 位(即 mode 八进制的最后 3 位)之外,还设置了其他位,则其他位的含义取决于各个平台。在某些平台上,它们会被忽略,应显式调用 chmod() 进行设置。
本函数支持 基于目录描述符的相对路径。
import os
for x in range(10):
path = r"D:\Code\CodePython\test-0811\dir" + str(x)
if not os.path.exists(path):
os.mkdir(path)os.makedirs() 递归创建目录
import os
for x in range(10):
path = r"D:\Code\CodePython\test-0811\dir\dirr" + str(x)
if not os.path.exists(path):
os.makedirs(path)os.remove(file) 删除文件
删除一个文件.
import os
os.remove(r"D:\xxx.py")os.rmdir(name) 删除目录
目录下面必须是空的,才行。推荐使用shutil.rmtree()
import os
for x in range(10):
path = r"D:\Code\CodePython\test-0811\dir"
os.rmdir(path)os.removedirs() 删除多个目录
也不推荐,推荐使用shutil.rmtree()。
os.system() 运行shell命令
涉及安全问题,一般不用。
shutil
shutil 是 Python 的一个标准库模块,它的全称是"shell utility",意为"shell工具"。它提供了文件和文件集合的高层操作。这个模块中的函数提供了一些文件操作的功能,这些功能通常比使用 os 模块中的函数更方便。
copy()和copy2() 复制
这两个函数用于复制文件。copy() 只会复制源文件的内容,而不会复制元数据(如修改日期和时间)。copy2() 会尝试复制源文件的元数据。
import shutil
# 源文件路径
src_file = "/path/to/source/file.txt"
# 目标文件路径
dst_file = "/path/to/destination/file.txt"
# 复制文件
shutil.copy(src_file, dst_file)
# 复制文件并尽可能保留元数据
shutil.copy2(src_file, dst_file)move()
这个函数用于将文件或目录从一个位置移动到另一个位置。
import shutil
# 源文件路径
src_file = "/path/to/source/file.txt"
# 目标文件路径(可以同时指定新名称)
dst_file = "/path/to/destination/new_file.txt"
# 移动文件
shutil.move(src_file, dst_file)rmtree()
这个函数用于删除目录及其所有内容。
import shutil
import os
# 要删除的目录路径
dir_path = "/path/to/directory"
# 检查目录是否存在,如果存在则删除整个目录及其内容
if os.path.exists(dir_path):
shutil.rmtree(dir_path)disk_usage()
这个函数返回指定路径的磁盘使用情况。
print(shutil.disk_usage(path))
# usage(total=776039559168, used=173954117632, free=602085441536)chown()
这个函数用于改变文件或目录的所有者和组。
import os
# 打开一个文件并设置权限
with open('example.txt', 'w') as f:
os.chmod(f.fileno(), 0o777)
# 这里的0o777只是一个示例,实际使用时需要根据你的需求设置合适的权限time
time模块提供了一系列函数,用于获取当前时间、时间格式化、时间戳等操作。
time.time() 获取时间戳
返回当前时间的时间戳,以秒为单位,浮点数表示。
print(time.time()) # 1703581829.3947577time.sleep() 休眠
使程序暂停指定的秒数。
time.sleep(1) # 休眠1stime.localtime([timestamp]) 获取当地时间
将给定的时间戳转换为本地时间,返回一个包含年、月、日、时、分、秒等信息的time.struct_time对象。
import time
# 获取指定时间的当地时间
print(time.localtime(time.time()))
# time.struct_time(tm_year=2023, tm_mon=12, tm_mday=26, tm_hour=17, tm_min=14, tm_sec=4, tm_wday=1, tm_yday=360, tm_isdst=0)
# 查看返回结果的类型
print(type(time.localtime(time.time())))
# <class 'time.struct_time'>
# 获取当前时间的当地时间
print(time.localtime())
# time.struct_time(tm_year=2023, tm_mon=12, tm_mday=26, tm_hour=17, tm_min=14, tm_sec=4, tm_wday=1, tm_yday=360, tm_isdst=0)time.strftime(format[, t]) 格式化
将时间对象格式化为字符串。
import time
t = (2009, 2, 17, 17, 3, 38, 1, 48, 0)
t = time.mktime(t)
print(time.strftime("%b %d %Y %H:%M:%S", time.gmtime(t))) # Feb 17 2009 09:03:38datetime
三种基本类型 data、time、datetime
datetime模块提供了日期和时间数据类型,包括date、time和datetime。
- datetime.date:表示日期,包括年、月、日。
- datetime.time:表示时间,包括时、分、秒、纳秒。
- datetime.datetime:表示日期和时间,包括年、月、日、时、分、秒、纳秒。
date
date表示日期(年、月、日)。
date() 初始化日期
from datetime import date
# 创建一个日期对象
d = date(2023, 3, 15)
print(d) # 输出:2023-03-15
# 获取日期对象的信息
print(d.year) # 输出:2023
print(d.month) # 输出:3
print(d.day) # 输出:15time
time表示时间(时、分、秒、微秒)。
time() 初始化时间
from datetime import time
# 创建一个时间对象
t = time(13, 45, 30)
print(t) # 输出:13:45:30
# 获取时间对象的信息
print(t.hour) # 输出:13
print(t.minute) # 输出:45
print(t.second) # 输出:30datetime
datetime表示日期和时间。
datetime.strftime() 时间转字符串
将日期时间格式化为字符串。
from datetime import datetime
now = datetime.now()
month = now.strftime("%m")
print("month:", month) # month: 12
day = now.strftime("%d")
print("day:", day) # day: 26
time = now.strftime("%H:%M:%S")
print("time:", time) # time: 17:20:51
date_time = now.strftime("%Y-%m-%d, %H:%M:%S")
print("date and time:", date_time) # date and time: 2023-12-26, 17:20:51datetime.strptime() 字符串转日期
将字符串解析为日期时间。
from datetime import datetime
date_string = "21 June, 2018"
print("date_string =", date_string)
print("type of date_string =", type(date_string))
date_object = datetime.strptime(date_string, "%d %B, %Y")
print("date_object =", date_object)
print("type of date_object =", type(date_object))
- %d Day of the month as a zero-padded decimal. 01, 02, ..., 31
- %-d Day of the month as a decimal number. 1, 2, ..., 30
- %b Abbreviated month name. Jan, Feb, ..., Dec
- %B Full month name. January, February, ...
- %m Month as a zero-padded decimal number. 01, 02, ..., 12
- %-m Month as a decimal number. 1, 2, ..., 12
- %y Year without century as a zero-padded decimal number. 00, 01, ..., 99
- %-y Year without century as a decimal number. 0, 1, ..., 99
- %Y Year with century as a decimal number. 2013, 2019 etc.
- %H Hour (24-hour clock) as a zero-padded decimal number. 00, 01, ..., 23
- %-H Hour (24-hour clock) as a decimal number. 0, 1, ..., 23
math和cmath
math提供了用于数学运算的函数。cmath提供了用于复数(Complex)计算的函数。
math.pi 圆周率
π 的近似值。
import math
print(math.pi) # 3.141592653589793math.e
e 的近似值。
import math
print(math.e) # 2.718281828459045math.sqrt(x) 开方
返回 x 的平方根。
import math
print(math.sqrt(10)) # 3.1622776601683795math.exp(x) e指数
返回 e 的 x 次方。e=2.71828。
import math
print(math.exp(2)) # 7.38905609893065math.pow(x, y) 求幂
返回x的y幂。
import math
print(math.pow(2, 5)) # 32.0math.ceil(x) 向上取整
返回大于或等于 x 的最小整数。
math.floor(x) 向下取整
返回小于或等于 x 的最大整数。
math.trunc(x) 截断取整
返回 x 的整数部分。
import math
x = 105.89
print(math.ceil(x)) # 106
print(math.floor(x)) # 105
print(math.trunc(x)) # 105random 随机数
随机模块,用于生成随机数。
random.random() 随机0-1
返回一个 0 到 1 之间的浮点数,包括 0 但不包括 1。
import random
print(random.random()) # 0.35353881754112093
print(random.random()) # 0.6368590695408868
print(random.random()) # 0.3432285144630204random.randint(a, b) 整数
返回一个 a 到 b 之间的整数,包括 a 和 b。
import random
print(random.randint(1, 100)) # 54
print(random.randint(1, 10)) # 7
print(random.randint(10, 20)) # 18
random.sample(population, k) 抽样
从 population 中随机选择 k 个不重复的元素。返回的是一个列表。注意,population 可以是一个序列或集合。
import random
print(random.sample([1, 5, 3, 3, 4], 4)) # [3, 5, 3, 4]
pickle
Python的pickle(Python object serialization)模块是一个用于序列化和反序列化Python对象的模块。它可以将Python对象转换为一种可以存储或传输的格式,以便稍后可以将其重新加载到Python中。pickle模块提供了一种方便的方式来保存和加载Python对象,包括列表、字典、集合等。
shelve
shelve(货架)是一个持久的、类似于字典的对象。与“dbm”数据库的区别在于,存储库中的值(而不是键)本质上可以是任意的Python对象——pickle模块可以处理的任何东西。这包括大多数类实例、递归数据类型和包含大量共享子对象的对象。键是普通的字符串。
argparse 参数解析
Python的argparse模块是一个用于解析命令行参数和选项的强大工具。它提供了一种灵活的方式来解析位置参数、选项、标志和可选参数,并且可以根据需要生成帮助信息和使用示例。
argparse.ArgumentParser() 初始化
import argparse
parser = argparse.ArgumentParser()add_argument() 添加参数
import argparse
parser = argparse.ArgumentParser(description="Main32")
parser.add_argument('--verbose', action='store_true', default=False, help="Show Log details or not")
parser.add_argument('--name', type=str, default="zhangsan", help="Name")
parser.add_argument('--height', type=float, default=1.72, help="Height")type: 数据类型int、str、float;
default: 默认值;
help: 提示语;
parse_args() 解析参数
import argparse
parser = argparse.ArgumentParser(description="Main32")
parser.add_argument('--verbose', action='store_true', default=False, help="Show Log details or not")
parser.add_argument('--name', type=str, default="zhangsan", help="Name")
parser.add_argument('--height', type=float, default=1.72, help="Height")
args = parser.parse_args()
print(args.verbose)
print(args.name)
print(args.height)输出结果如下
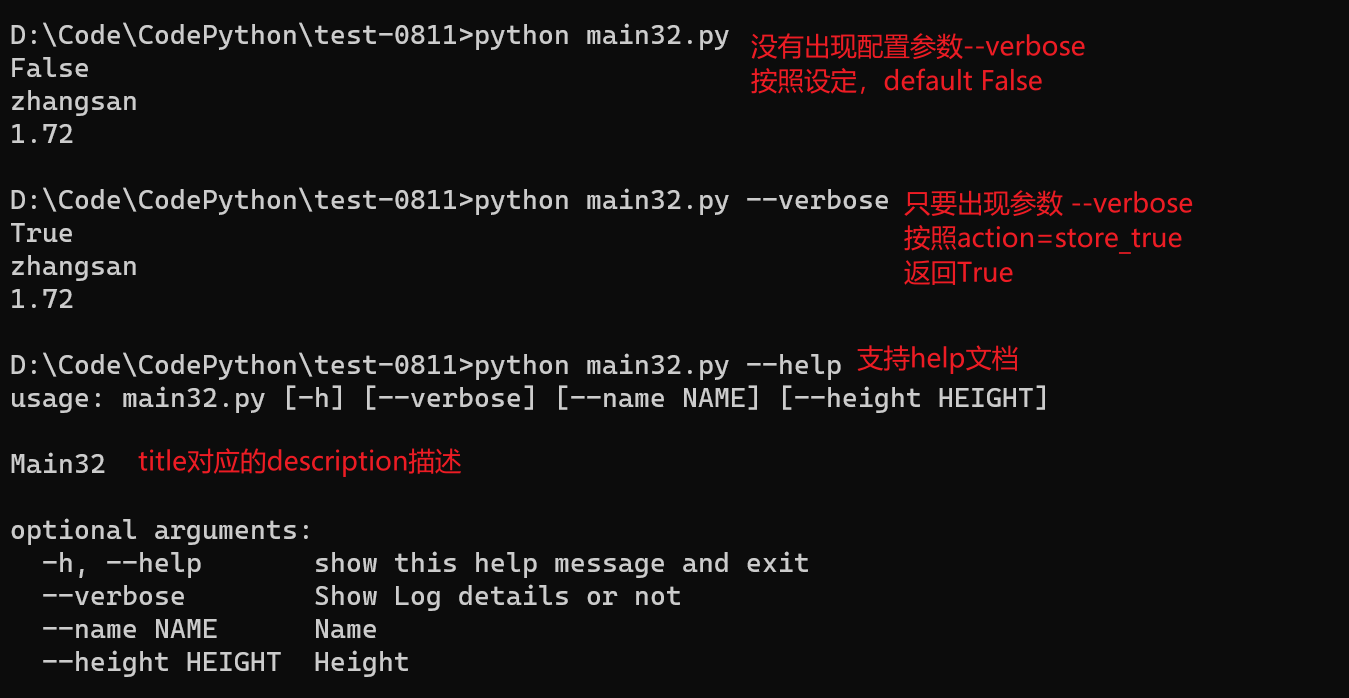
threading 多线程
threading.Thread() 创建线程
import threading
def worker():
print("Worker thread is running")
# 创建线程对象
thread = threading.Thread(target=worker)
# 启动线程
thread.start()
# 等待线程结束
thread.join()
- group 应为 None;保留给将来实现 ThreadGroup 类的扩展使用。
- target 是用于 run() 方法调用的可调用对象。默认是 None,表示不需要调用任何方法。
- name 是线程名称。 在默认情况下,会以 "Thread-N" 的形式构造唯一名称,其中 N 为一个较小的十进制数值,或是 "Thread-N (target)" 的形式,其中 "target" 为 target.__name__,如果指定了 target 参数的话。
- args 是用于发起调用目标函数的参数列表或元组。 默认为 ()。
- kwargs 是用于调用目标函数的关键字参数字典。默认是 {}。
- daemon 如果不是 None,daemon 参数将显式地设置该线程是否为守护模式。 如果是 None (默认值),线程将继承当前线程的守护模式属性。
如果子类型重载了构造函数,它一定要确保在做任何事前,先发起调用基类构造器(Thread.__init__())。
在 3.10 版更改: 使用 target 名称,如果 name 参数被省略的话。
在 3.3 版更改: 加入 daemon 参数。
name 指定线程名字
thread = threading.Thread(target=worker, name="my_thread")target 目标函数名
参数误传的区别
thread = threading.Thread(target=my_func, name="Thread-Func") # 正确用法
thread = threading.Thread(target=my_func(), name="Thread-Func") # 错误用法
错误用法多写一个括号,
1. `thread = threading.Thread(target=my_func, name="Thread-Func")`:
在这种情况下,`target` 参数指定的是一个函数对象 `my_func`,该函数将作为线程的目标函数。当线程启动后,将调用 `my_func` 函数来执行线程的逻辑。
2. `thread = threading.Thread(target=my_func(), name="Thread-Func")`:
在这种情况下,`target` 参数指定的是一个函数调用 `my_func()`,而不是函数对象本身。因此,当这个语句执行时,`my_func` 函数将会立即被调用,并且函数的返回值将作为线程的目标函数。换句话说,`my_func()` 函数将在创建线程之前立即执行,并且线程的目标函数将是 `my_func()` 的返回值。
所以,两个语句的区别在于 `target` 参数指定的是函数对象还是函数调用。通常情况下,我们应该使用第一种方式,即 `target=my_func`,将函数对象作为目标函数。这样可以确保线程启动后才会执行函数逻辑,而不是在创建线程之前立即执行函数。
threading.active_count() 获取当前活动线程数
import threading
import time
def my_func():
for x in range(5):
time.sleep(0.5)
if __name__ == '__main__':
thread = threading.Thread(target=my_func, name="Thread-Func")
thread.start()
for x in range(5):
print("active_count=", threading.active_count())
time.sleep(0.5)
输出
active_count= 2
active_count= 2
active_count= 2
active_count= 2
active_count= 2














 332
332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









