







最近在公司的项目中用到了很多的 zookeeper,记录一下免得忘记
Zookeeper 简介
Zookeeper 是由 Yahoo! 研究院研发的,前身是 Google 研发的 Chubby。Chubby 是为了解决分布式集群中的数据一致性问题出现的,它对外提供一个分布式文件系统的接口还有一个分布式锁。在 Google 的使用过程中 Chubby 作为 name service 更加受到欢迎,所以在开发 Zookeeper 的时候 Yahoo! 的工程师就直接去掉了分布式锁的接口,仅仅对外提供一个分布式文件系统接口。这个提供分布式一致服务的系统就叫做 Zookeeper。Zookeeper 虽然对外提供了一个文件接口也可以持久化保存数据,但是 Zookeeper 的设计不是为了做数据库,一个 node 一般不要存放超过 256k 的数据。Zookeeper 集群在正常的时候是一个主从结构,有一个leader和多个 follower。client 可以连接任意一个集群中的server.
Zookeeper 使用
zookeeper 的使用非常简单就参考一下官方的 programmer guild 好了 programmer guild
其中文件系统的增删改查、事件机制会用就没有问题
Zookeeper 的一致性可用性与分区容错性
任何一个分布式系统都逃脱不了 CAP 理论的制约,zookeeper 是一个强一致性系统,不是最终一致性(最终一致性是指实际上会有但理论上无法证明的一致性)。zookeeper 在数据写入的同步过程中,不会不可用,比如写入 /file/a 这个 node 的同时有一个访问,这个访问不会阻塞到 node 同步完成,会直接返回一个旧值。我自己做了个实验,开两个线程,跑两个客户端,一个线程异步写入,发送 setData 之后里面通知另外一个线程去 getData, 有概率得到旧的值。zookeeper 本身在设计的时候就是要做一个 wait-free 的系统。在出现分区的时候,如果 leader 在多数 follower 的一方,那么这半边正常,另外半边均不能读写,如果 leader 少数 follower 一方,那么leader会意识到没有多数follower的支持了,而多数的一方会选举出新的leader。
Zookeeper 的一致性算法
Zookeeper 的选举算法源自 Paxos,Paxos 随后的博文再介绍吧,这里介绍个 Paxos 的阉割版 Zab。严格上来说 Zab 并没有经过形式化的证明,但是在实际的实践过程中,Zab 的良好的完成了数据一致性的同步工作。
Zab有两种模式,一种是 broadcast 模式,用来在正常情况下在各个机器间同步数据,一种是 recovery 模式,这个模式用来 fail 的恢复。
broadcast
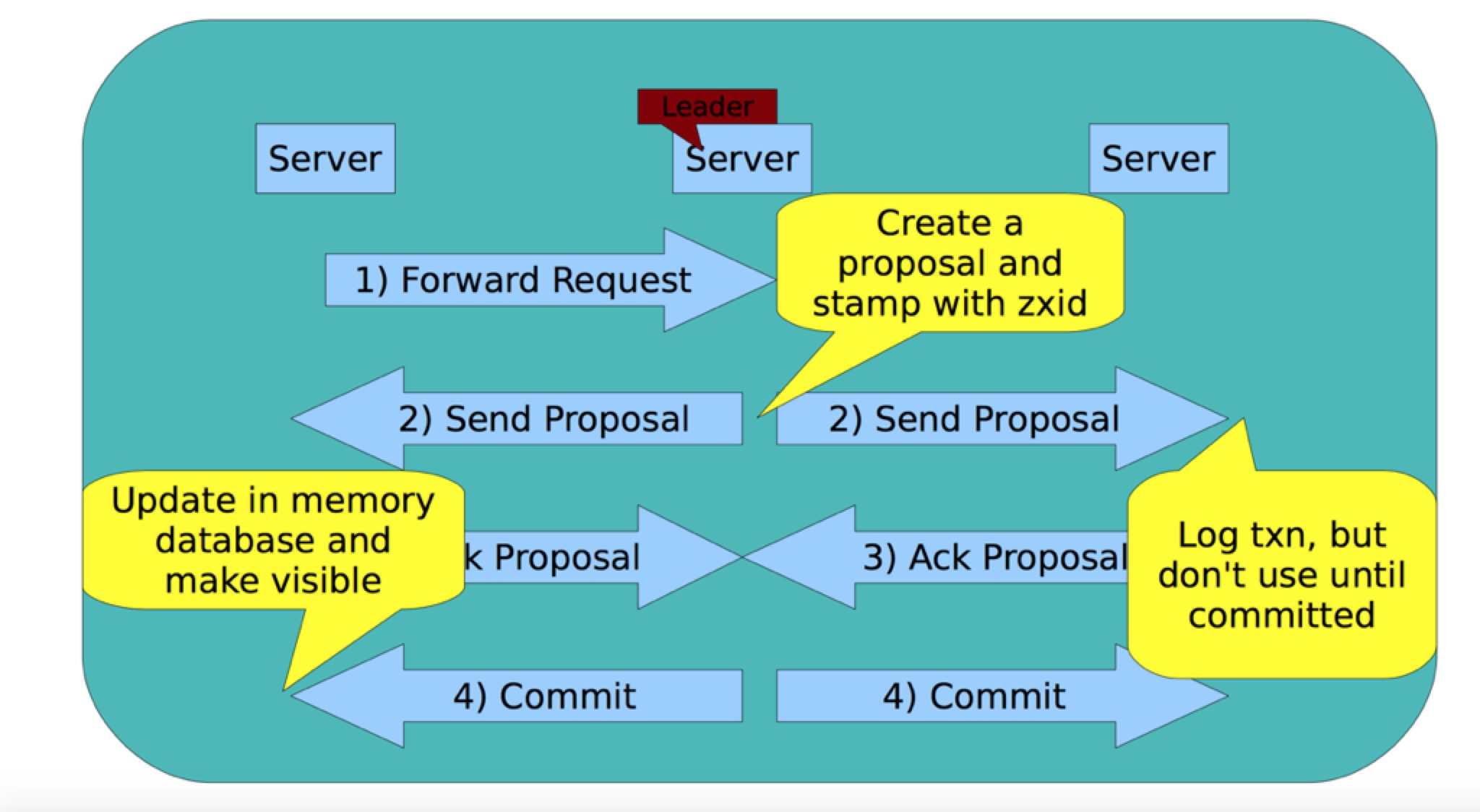
所有的写入过程都是通过leader来完成的,当一个 follower 接到 setData 的请求的时候会直接讲这个请求转发给 leader,leader 收到这个请求之后会生成一个 proposal ,这个 proposal 包含数据的内容和一个 zxid。这个 zxid 是一个由主节点维护的全局单调递增的 id,用来标识服务器的状态,zxid 越大服务器的状态越新。然后 leader 在磁盘上记录下这个 proposal, 然后讲这个 proposal 发送给各个 follower。follower 收到 proposal 之后也是先把数据记录在磁盘上,先不更新,然后返回一个 ack 给 leader,当 leader 收到半数以上的 follower 返回 ack 之后会再次发送一个 commit 指令,当 follower 收到这个 commit 指令之后会把数据更新到 内存中,这个时候 client 再次 getData 的时候就会得到一个新的数值。
recovery
Zab 的 recovery 模式可以一方面选举出 leader , 另一方面同步集群中的所有机器的状态到最新。
leader 选举
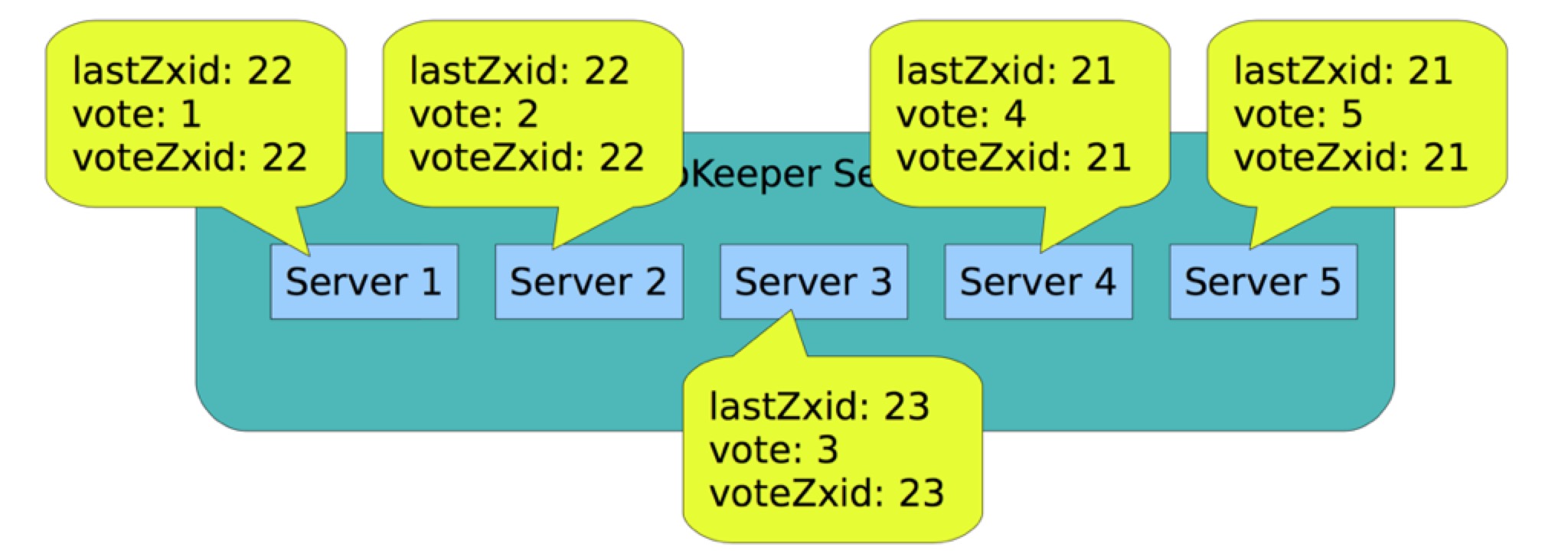
选举的时候所有人都会首先生成一张选票,这张选片上写着投给哪个server,那台 server 的 zxid 是什么。一开始的时候,所有机器都会把票投给自己,然后轮询集群中所有其他机器的选票,如果有其他机器的 zxid 大于自己,那么就把选票投给它,如果 zxid 相同就投给哪个 serverid 最大的,这个过程一直持续到有个server得到了超过半数的机器的支持。
状态同步
新选举的leader拥有最新的 zxid,所以它会把其他 follower 没有提交的提议再发给他们然后同步状态。发送一个 新的 epoch 开始 成为 leader。zxid 是由 epoch + counter 组成的,总共 64bit,高 32 bit 是 epoch,低 32 位是单纯的计数 counter。当旧leader挂掉重启的时候可能会发送还没发送完的请求,这时候可以通过 epoch来判断是否过时。
Zookeeper 持久化机制
zookeeper 有两种持久化的机制,一种是 snapshot,另外一种是前文提到过的 log。
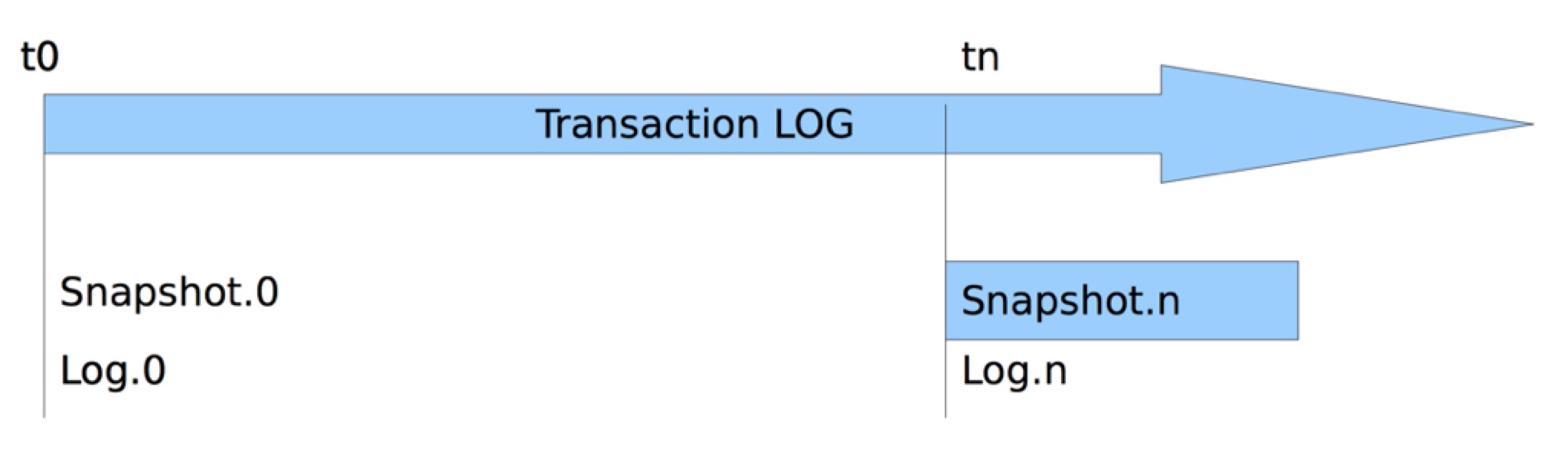
snapshot 其实就是从根节点来一次 dfs,dfs 的时候zookeeper不会停止服务还会更新节点,所以叫做粗心的 snapshot,假如在 tn 的时候关闭重启 zookeeper,那么一方面要载入 snapshot,另一方面要把tn之后的log再执行一遍。
Zookeeper 的吞吐量
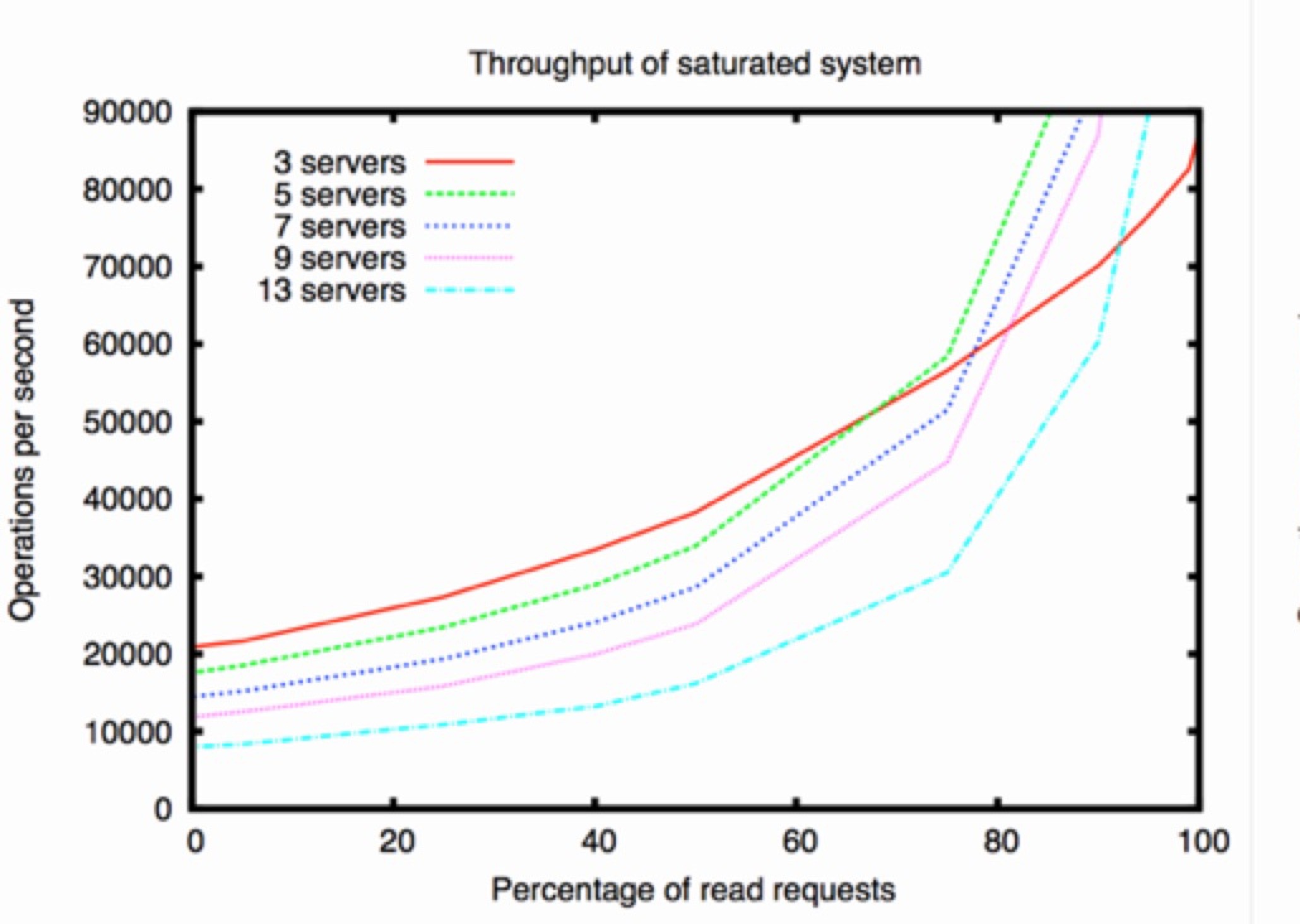
client 可以连接任意一台服务器进行读写操作,server在处理读操作的时候直接从内存中返回,在处理写操作的时候转发给 leader 然后进行一次 broadcast 同步。所以集群中机器越多,读的效率越高写的效率越低,一般一个集群 5~7 台即可。从 paper 中拿了一张图出来。
参考文献
A simple totally ordered broadcast protocol
The Chubby lock service for loosely-coupled distributed systems
ZooKeeper: Wait-free Coordination for Internet-scale Systems















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









