







Flash-Attention 1&2 论文理解
https://github.com/Dao-AILab/flash-attention
Self-Attention标准实现:


论文中
softmax
(
S
)
\text{softmax}(\mathbf S)
softmax(S)表示对矩阵
S
\mathbf S
S行进行操作,且需要减去行最大值。
论文思想类似矩阵乘法优化思路,即对矩阵进行分块,通过迭代法进行计算,迭代带来的问题是,迭代过程中softmax操作没法准确获取矩阵S每行的最大值(只能拿到当前最大值)。因此需要在每次迭代后对结果
O
\bf O
O进行修正(这是Flash-Attention 1 的想法, Flash-Attention2改为了在最后一步修正,因为当计算到每行最后一块时,行最大值就是准确的了)。具体步骤如下(假设只分成2步):
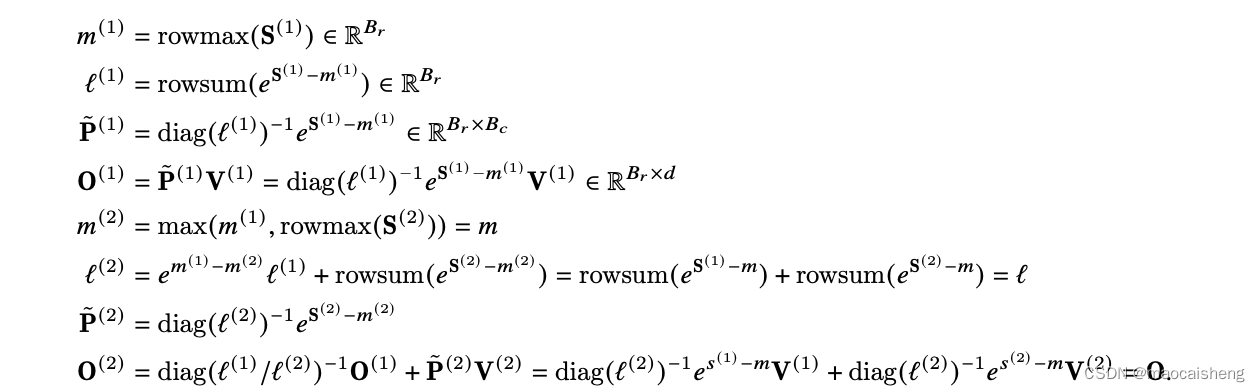
对比下不进行迭代计算(但依然分块):
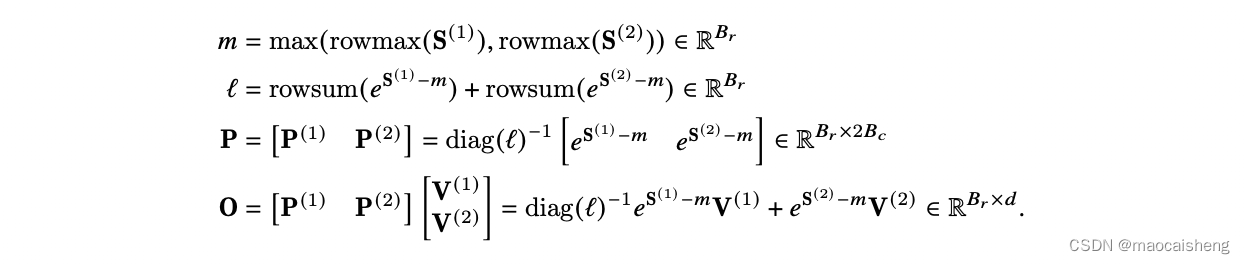
主要看行最大值
m
\bm m
m、指数和
l
\bm l
l的更新过程,比如计算
l
(
2
)
{\bm l}^{(2)}
l(2),在拿到新的最大值
m
(
2
)
{\bm m}^{(2)}
m(2)后,先对
l
(
1
)
{\bm l}^{(1)}
l(1)进行了修正(如果最大值没变
m
(
2
)
=
m
(
1
)
{\bm m}^{(2)}={\bm m}^{(1)}
m(2)=m(1),则系数等于1),然后加上当前块的指数和,从而得到累计到当前块的指数和。
仔细思考可以发现迭代过程中
P
~
\bf \tilde P
P~的缩放系数(对应softmax函数中除以指数和的部分)是多余的,因为在计算
O
(
2
)
\bf O^{(2)}
O(2)过程中,将
O
(
1
)
\bf O^{(1)}
O(1)代入后,之前除以的系数后面又被乘了回来(这里怀疑公式中
d
i
a
g
(
l
(
1
)
/
l
(
2
)
)
−
1
diag(\bm l^{(1)} /\bm l^{(2)})^{-1}
diag(l(1)/l(2))−1是不是写反了?应该为
d
i
a
g
(
l
(
2
)
/
l
(
1
)
)
−
1
diag(\bm l^{(2)} /\bm l^{(1)})^{-1}
diag(l(2)/l(1))−1 ?)。因此在Flash-Attention 2中改为:
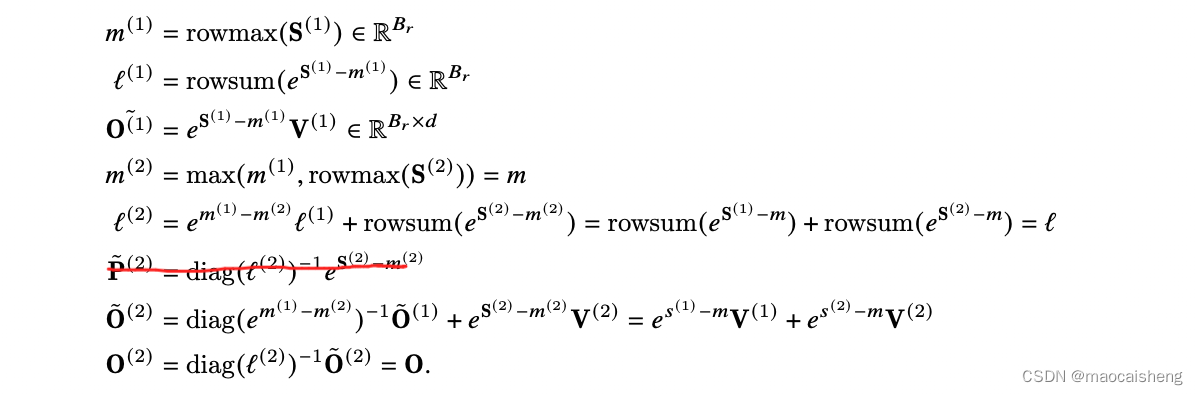
这里
P
~
(
2
)
\bf \tilde P^{(2)}
P~(2)计算应该是多余的。
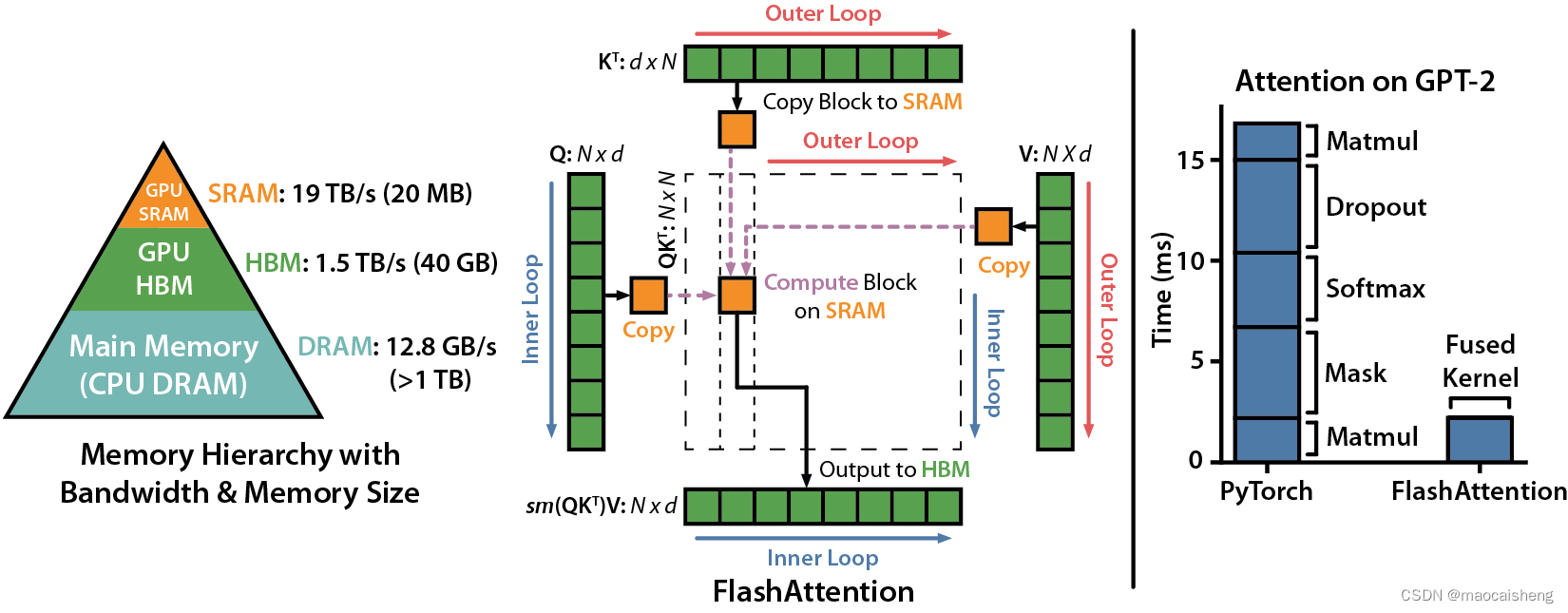
采用迭代方式目的是充分利用GPU中的共享内存,即第一张图中左侧部分,SRAM速度快,但存储小,通过迭代方式可以一次只计算大矩阵的中一小块,将所有操作限制到SRAM中,从而实现加速。
最后贴一下Flash-Attention 2的算法步骤,注意最后一步的修正:

可以对照这两张图进行理解:

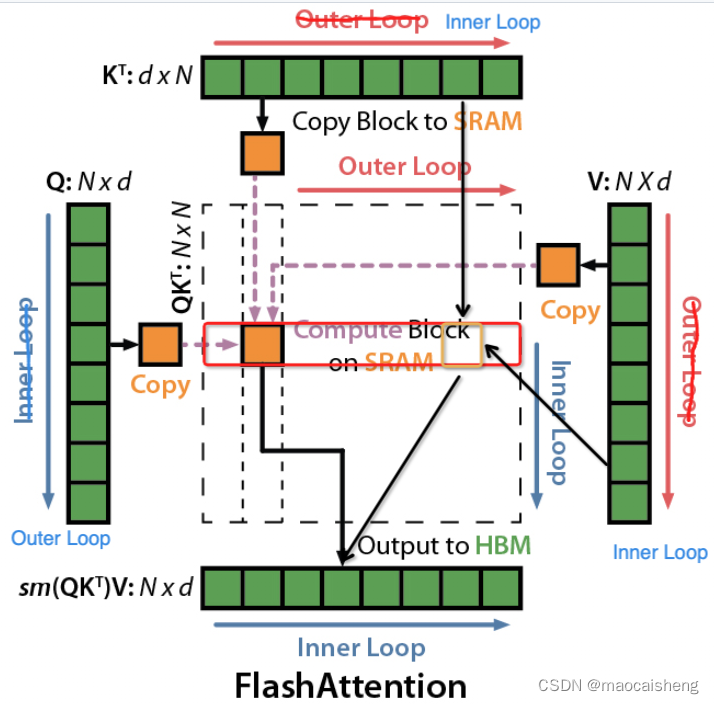
另外,Flash-Attention 2 相比 Flash-Attention 1还改了下循环变量,2中将Q作为外层循环,1中将Q放到内层循环,显然2更加合理,因为给定
Q
i
\bf Q_{i}
Qi后,在内层循环中,可以将O完整的计算出来,而1需要将O的中间结果写回显存,在后续的外层循环中再读出来。对比1的实现如下:

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









