







本文介绍如何使用caffe对自己的图像数据进行分类。
1 图片数据库准备
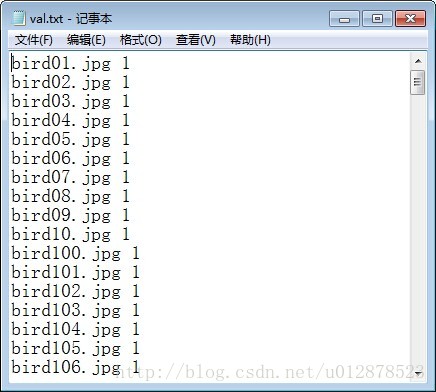
由于图片数据收集比较费时,为了简单说明,我用了两类,dog和bird,每种约300张。train200张,val100张。
新建一个文件夹mine,放自己的数据,在mine文件夹下新建train和val文件夹,train文件夹下新建bird和dog两个文件夹分别存放200张bird和200张dog,val文件夹里存放其他的图片用于验证。注意,图片的size要归一到相同尺寸。(256*256)
2 转换成leveldb格式
在mine文件夹下新建两个txt文件:train.txt和val.txt,列出对应图片名及其标签。
数据量较少的可以手动标签,数据量较大的话,可以写批处理命令,比较方便。

一定要注意,train列表中的图片带相对路径名bird/*.jpg dog/*.jpg。标签1代表bird,标签2代表dog。
生成列表后,编译convert_imageset.cpp.
在bin文件夹中将刚刚生成的MainCaller.exe重命名为convert_imageset.exe。做一个批处理命令将图片数据转换成leveldb格式。
在caffe-windows文件夹下新建convertimage2ldb.bat。
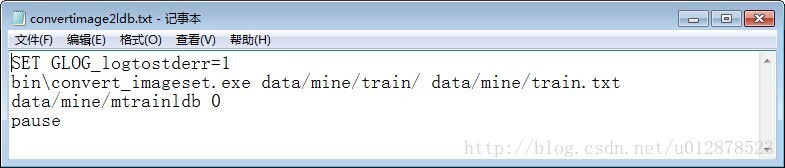
双击运行,在mine文件夹下就会出现mtrainldb文件夹。
同理可得到mvalldb。这两个就是caffe需要的数据。
注意,我的mine文件夹是放在data文件夹下的,在写convertimage2ldb.bat时注意你自己路径。
3 计算mean
这个比较简单,上篇文章也说了。编译comput_image_mean.cpp
在bin文件夹中将刚刚生成的MainCaller.exe重命名为comput_image_mean.exe。做一个computeMean.bat方便以后使用。
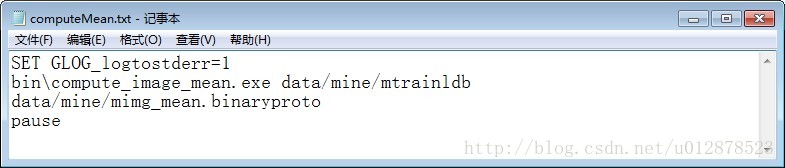
双击运行之后在mine里面出现mimg_mean.binaryproto,这就是caffe需要的图片均值文件。
4 训练自己的网络
数据集和均值文件都生成之后,训练和前面两篇文章类似。这次我直接使用的是imagenet的网络结构,几乎没怎么修改,所以我将imagenet里面的imagenet_train.prototxt、imagenet_val.prototxt、imagenet_solver.prototxt直接拷过来修改一下。
imagenet_val.prototxt、imagenet_train.prototxt里面的
source: "mtrainldb"
mean_file:"mimg_mean.binaryproto"
batch_size: 10
还有最后一层的output改为2,因为我只有两类。
imagenet_solver.prototxt里面的网络参数修改:
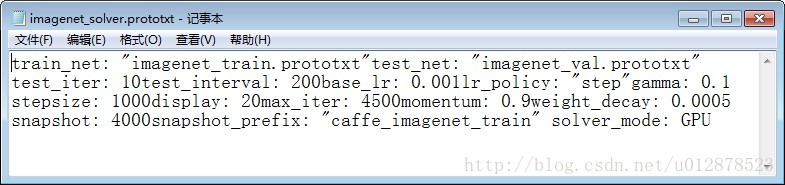
注意最后加上solver_mode:GPU。
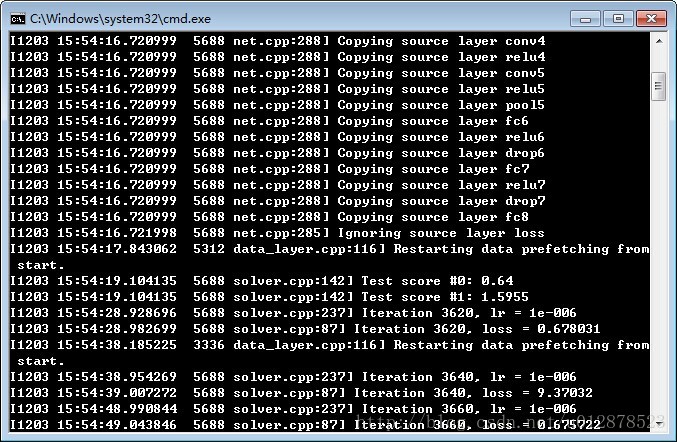
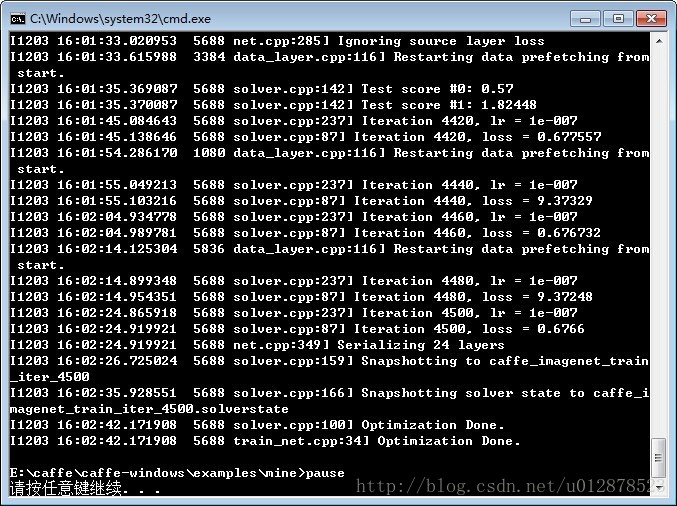
开始训练:

5 实验结果
由于数据量较小,训练比较快。正确率最高能达到0.87。但是最后并不收敛,4500次迭代正确率时高时低。本文只是介绍方法,还有很多参数值得推敲。
原文地址:http://blog.csdn.net/u012878523/article/details/41698209















 1113
1113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









