







 本文详细介绍了如何在Yarn模式下获取Spark作业信息,包括正在运行和历史作业的查看,以及两种获取作业信息的方法:解析作业记录文件和使用REST API。解析文件涉及对HDFS中特定目录的文件处理,而REST API适用于Spark 1.3及以上版本,提供了方便的作业信息获取接口。文章还提到了在多主机环境下获取作业信息的挑战及解决策略。
本文详细介绍了如何在Yarn模式下获取Spark作业信息,包括正在运行和历史作业的查看,以及两种获取作业信息的方法:解析作业记录文件和使用REST API。解析文件涉及对HDFS中特定目录的文件处理,而REST API适用于Spark 1.3及以上版本,提供了方便的作业信息获取接口。文章还提到了在多主机环境下获取作业信息的挑战及解决策略。
目录
提前说明
- 本文仅讨论运行在Yarn模式下Spark作业信息的获取,至于获取其它模式下的作业信息,请见参考博文1。
- 官方文档见Spark1.6.1–Monitoring and Instrumentation。
作业信息的查看
正在运行作业
一般作业运行后,可打开http://<driver-node>:4040查看作业的运行情形,如下所示,
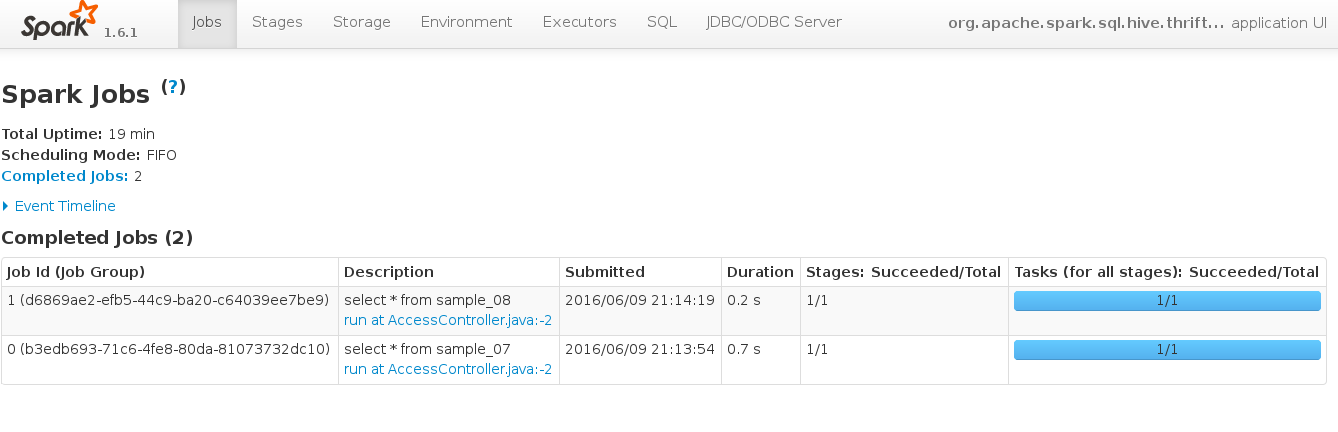
历史作业查看
打开spark-defaults.conf文件,增加如下配置,意为将记录Spark作业的历史信息,并将其写到HDFS的/user/spark/applicationHistory目录下。
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop0:8020/user/spark/applicationHistory打开spark-env.sh,增加如下配置,意为打开历史界面时,从HDFS的/user/spark/applicationHistory目录下读取历史作业信息。这一步也可以通过在History Server的启动命令中添加参数来解决,即sbin/start-history-server.sh hdfs://hadoop0:8020/user/spark/applicationHistory。
export SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://hadoop0:8020/user/spark/applicationHistory"启动History Server成功后,即可在http://<history-server>:18080界面查看所有历史作业。当然上述的history-server写你刚刚启动History Server的那台主机。
值得注意的是,CDH安装后默认完成了上述所有步骤并自带了History Server,唯一的不同点是端口是18088而不是18080,此点需特别注意。
作业信息的获取
这一节讲作业信息的获取,即获取作业的各个指标,以用来进行二次开发。
方式1—解析作业记录文件
既然作业的信息都存在HDFS的/user/spark/applicationHistory目录下,那么可以解析该目录下所有文件,以获取作业信息。
- 正在运行作业
正在运行作业的命名类似于application_1465461051654_0001.inprogress - 历史作业
运行作业的命名类似于application_1465461051654_0002
方式2—REST API
Spark1.3以上的版本提供了REST API,以方便开发者快速获取作业信息,参见Spark1.6.1–Monitoring and Instrumentation。
正在运行作业
Request:获取正在运行作业的全部job
curl -i http://localhost:4040/api/v1/applications/local-1465476936241/jobsResponse
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1262
1262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









