




作为一名大数据开发,从工具产品的角度,对比一下大数据工具最常使用的框架spark、hadoop和flink。工具无关好坏,但人的喜欢有偏好。
目录
评价标准
1 效率
- 明确目标:用户使用工具类产品是有明确的目标的。比如,美图产品需要帮助用户迅速进行美图。
- 简化操作:简化操作能够扩大用户数量,提升效率,提升用户满意度。操作困难重重的工具类产品注定会被替代。
- 容错性:使用工具有用错的可能,出错情况少、容错性高的工具让用户用起来更放心,更安心。
2 用户体验分析
- 用户群体(我是谁?)
- 解决场景下的痛点(我在哪里?)
- 解决痛点的形式(我在干什么?)
- 交互体验(UI感受)
- 行业优劣(竞品分析)
工具产品的共同道理,不管是什么形式的工具,其道理都是类似的:
从用户的维度来看
- 价值提供:工具是否能提供应该提供的价值,解决用户需求,完成用户的本质目标?
- 使用舒适度:用户在使用过程中是否感觉很舒服、容易?
- 目标促进:工具是否能吸引用户或促进用户完成目标?
- 易触达:工具是否易于触达?能否正常运行/使用?
从市场的维度来看
- 与时俱进:工具是否能与时俱进,比如设计风格、功能布局等?
- 功能对比:其他产品的功能是否更多更好?
- 用户量:工具的用户量是否最多?
从产品的维度来看
- 持续维护:工具是否会继续维护?
- 疑问解决:对工具有疑问时,是否有人及时解决?
- 定位不变:工具是否坚持自己的定位不变?
3 用户体验的基本原则
- 一看就用:好的用户体验,一看就能使用。
- 提高效率:提高用户效率,用完就走。
- 节省成本:节省成本,再次使用还会回来。
具体来说
成本和产出是否成正比
- 作为工具,若使用成本大于产出成本,那么宁可不使用工具。使用成本包括:上手成本、时间成本、工具成本,缺一不可,任何一环都需要考虑并进行衡量。
操作是否“人性化”
- 工具讲究易用性和效率,简单的使用界面和流程会使工具容易被接受(不包括军事或其他高级领域,只讨论2C)。
4. 功能性与用户体验评估
- 功能性:用户的需求是否满足,即客户要求的功能是否全部实现。
- 易用性:对新手用户来说,软件是否友好、方便,功能操作不需要用户花太多时间去学习或理解。
- 高效率性:软件的性能,在指定条件下实现功能所需的计算机资源的有效程度。效率反映了在完成功能要求时有没有浪费资源。资源包括内存、外存、通道能力及处理时间。
- 可靠性:在规定时间和条件下,软件维持其性能水平的程度。可靠性对某些软件是重要的质量要求,反映了软件在故障发生时能继续运行的程度。
- 可维护性:软件在研发时需求变更时进行相应修改的容易程度,以及上市后的运行维护的方便性。易于维护的软件系统也是易理解、易测试和易修改的,以便纠正或增加新功能,或允许在不同软件环境上操作。
- 可移植性:从一个环境转移到另一个环境的容易程度。
总而言之
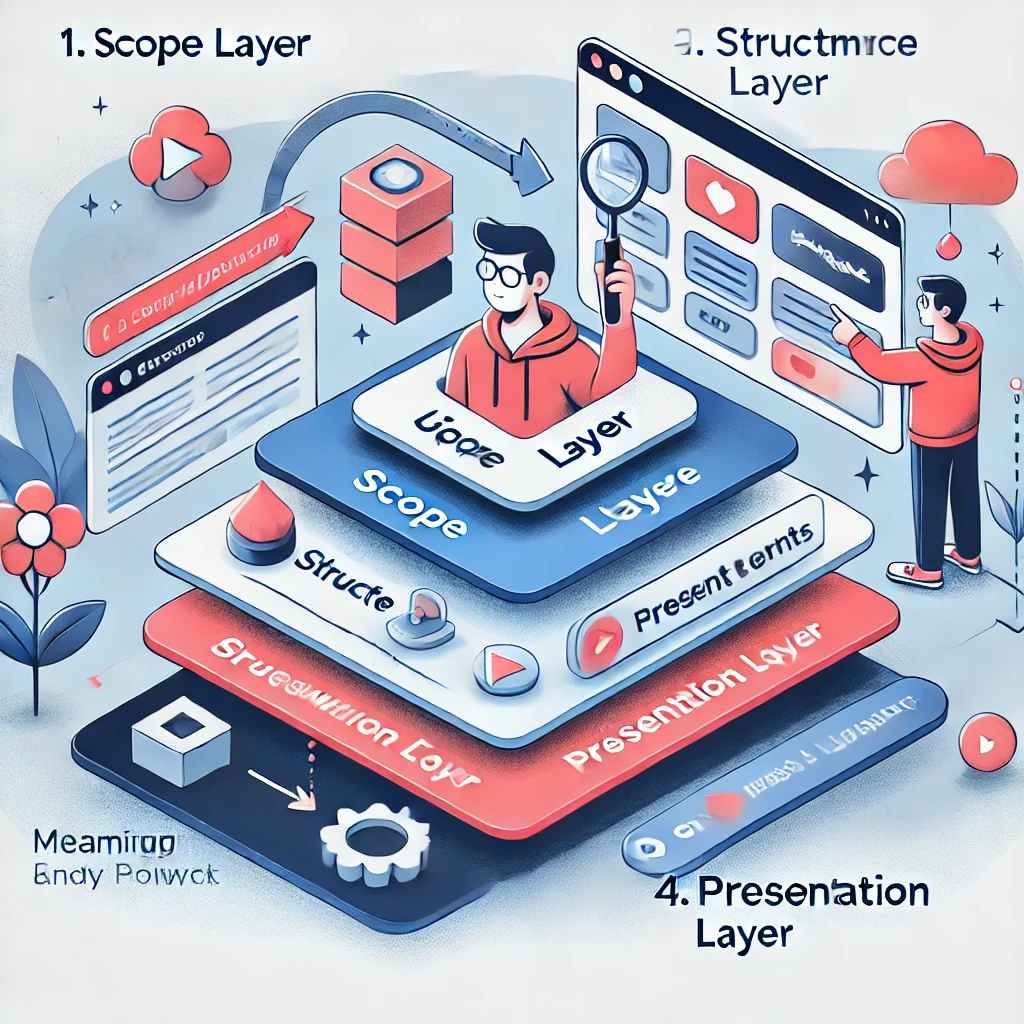
“好不好用”圈定了讨论范围要围绕功能。从用户体验要素上来说,用户在进入产品之前有一个核心任务:
- 范围层:在产品内是否能使用户完成自己的任务?
- 结构层:用户完成任务的流程是否流畅?
- 框架层:用户是否能清晰地找到完成任务的入口?
- 表现层:任务完成各阶段的提示、反馈是否明确、有意义?
大数据框架评估
用户视角
效率
- Apache Hadoop:适用于处理大规模数据集,但设置和管理复杂,可能降低新用户的效率。
- Apache Spark:提供内存中处理,大大提升性能和速度,非常适合迭代算法和实时数据处理。
- Apache Flink:在实时流处理方面表现出色,提供高效的低延迟处理。
示例代码
Spark:计算Pi的近似值
from pyspark import SparkContext
import random
sc = SparkContext("local", "Pi Approximation")
def inside(p):
x, y = random.random(), random.random()
return x*x + y*y < 1
num_samples = 1000000
count = sc.parallelize(range(0, num_samples)).filter(inside).count()
pi = 4 * count / num_samples
print("Pi is roughly %f" % pi)
Flink:实时流处理示例
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 4287
4287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











