








在这个数据驱动的时代,MySQL作为一款强大的关系型数据库管理系统,已经成为大数据开发者的必备技能之一。然而,面对浩如烟海的MySQL知识,很多人常常不知从何下手。今天,让我们一起探讨如何以"糙快猛"的方式高效学习MySQL。

什么是"糙快猛"学习法?
"糙快猛"学习法源于一个简单而深刻的道理:学习就应该糙快猛,不要一下子追求完美,在不完美的状态下前行才是最高效的姿势。这种方法强调:
- 快速入门,不拘小节
- 持续实践,边学边用
- 勇于尝试,不怕犯错

这种学习方法特别适合在当今快速变化的技术环境中学习新技能,比如MySQL。
我的MySQL学习故事
作为一名从0基础跨行到大数据领域的开发者,我深深体会到"糙快猛"学习法的威力。记得刚开始学习MySQL时,我并没有去追求掌握每一个细节,而是迅速搭建了一个简单的数据库环境,开始了我的实践之旅。
有一次,我需要为一个小项目创建一个用户表。虽然我对数据库设计还不够熟悉,但我决定先尝试一下:
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(50) NOT NULL,
email VARCHAR(100) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
这个表结构可能不是最优的,但它让我快速开始了我的项目。随着我对MySQL的理解加深,我逐渐优化了这个表结构,添加了索引,调整了字段类型。这个过程让我深刻体会到,"糙快猛"并不意味着永远停留在"糙"的阶段,而是一个不断迭代、持续优化的过程。
MySQL学习的"糙快猛"之道

1. 快速搭建环境
不要在环境搭建上花费太多时间。使用Docker可以快速启动一个MySQL实例:
docker run --name mysql-learn -e MYSQL_ROOT_PASSWORD=mypassword -d mysql:latest
2. 从基本的CRUD操作开始
掌握基本的增删改查(CRUD)操作是学习MySQL的第一步:
-- 插入数据
INSERT INTO users (username, email) VALUES ('john_doe', 'john@example.com');
-- 查询数据
SELECT * FROM users WHERE username = 'john_doe';
-- 更新数据
UPDATE users SET email = 'john.doe@example.com' WHERE username = 'john_doe';
-- 删除数据
DELETE FROM users WHERE username = 'john_doe';
3. 勇于尝试复杂查询
随着你对基本操作的熟悉,开始尝试更复杂的查询:
SELECT u.username, COUNT(o.id) as order_count
FROM users u
LEFT JOIN orders o ON u.id = o.user_id
GROUP BY u.id
HAVING order_count > 5
ORDER BY order_count DESC
LIMIT 10;
这个查询可能看起来很复杂,但通过逐步分析和实践,你会逐渐理解每一部分的作用。
深入MySQL核心概念

在"糙快猛"的学习过程中,我们不能忽视一些核心概念。这些概念将帮助你更好地理解和使用MySQL。
1. 索引优化
索引是提高查询效率的关键。但要记住,过度使用索引可能会降低写入性能。以下是一个简单的索引示例:
CREATE INDEX idx_username ON users(username);
这个索引将加速基于username的查询,但可能会稍微降低插入和更新的速度。
2. 事务管理
理解事务的ACID属性(原子性、一致性、隔离性、持久性)对于保证数据完整性至关重要。这里是一个简单的事务示例:
START TRANSACTION;
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
UPDATE accounts SET balance = balance + 100 WHERE id = 2;
COMMIT;
3. 存储过程
存储过程可以大大提高复杂操作的效率。这是一个简单的存储过程示例:
DELIMITER //
CREATE PROCEDURE GetUserOrders(IN userId INT)
BEGIN
SELECT * FROM orders WHERE user_id = userId;
END //
DELIMITER ;
CALL GetUserOrders(1);
实战项目:构建简单的博客系统
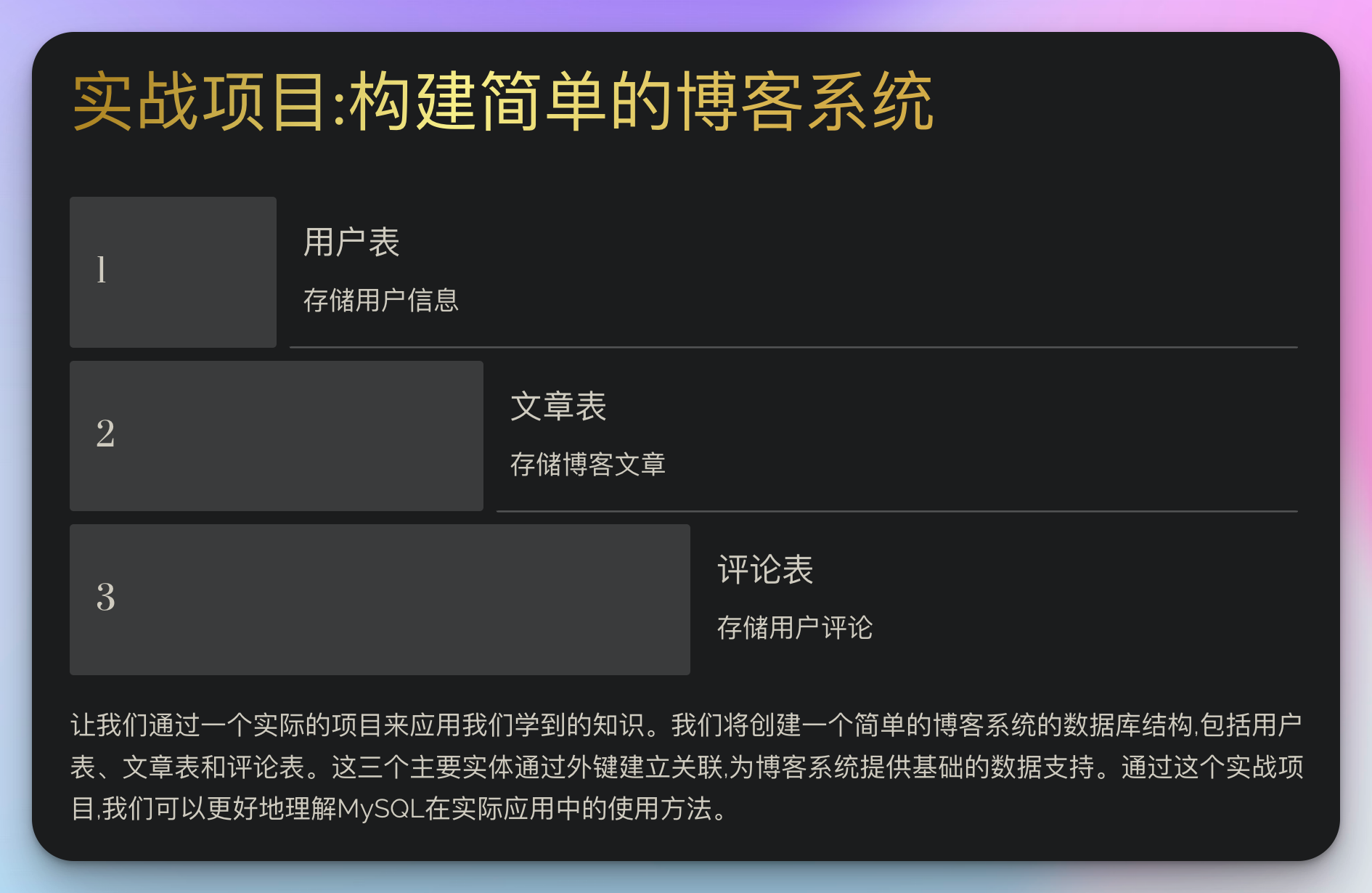
让我们通过一个实际的项目来应用我们学到的知识。我们将创建一个简单的博客系统的数据库结构。
-- 创建用户表
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(50) NOT NULL UNIQUE,
email VARCHAR(100) NOT NULL UNIQUE,
password VARCHAR(255) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 创建文章表
CREATE TABLE posts (
id INT AUTO_INCREMENT PRIMARY KEY,
user_id INT,
title VARCHAR(255) NOT NULL,
content TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (user_id) REFERENCES users(id)
);
-- 创建评论表
CREATE TABLE comments (
id INT AUTO_INCREMENT PRIMARY KEY,
post_id INT,
user_id INT,
content TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (post_id) REFERENCES posts(id),
FOREIGN KEY (user_id) REFERENCES users(id)
);
这个简单的结构包含了用户、文章和评论三个主要实体,它们之间通过外键建立关联。
性能优化技巧

在学习过程中,你可能会遇到性能问题。以下是一些基本的优化技巧:
- 使用EXPLAIN分析查询计划
- 合理使用索引
- 避免使用SELECT *,只选择需要的列
- 使用批量插入而不是多次单条插入
- 定期进行ANALYZE TABLE和OPTIMIZE TABLE
踩坑经历与解决方案
在我的学习过程中,遇到过不少坑。比如有一次,我在一个大表上执行了一个没有WHERE条件的UPDATE语句,结果导致整个数据库卡住。从那以后,我学会了始终使用WHERE子句,并在执行前先用SELECT测试。

这样的经历让我意识到,"糙快猛"并不意味着鲁莽,而是在保持前进的同时,时刻保持警惕和学习的心态。
MySQL在大数据生态中的角色
作为一名大数据开发者,了解MySQL在整个大数据生态系统中的位置至关重要。虽然我们经常将注意力集中在Hadoop、Spark等大数据处理工具上,但MySQL在数据收集、预处理和结果存储方面仍然扮演着重要角色。

1. 数据采集层
在很多大数据架构中,MySQL常被用作数据采集层。例如,一个电商平台可能使用MySQL存储用户交易数据:
CREATE TABLE transactions (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
user_id INT,
product_id INT,
amount DECIMAL(10, 2),
transaction_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
INDEX idx_user (user_id),
INDEX idx_product (product_id)
);
这些数据随后可能被导入到Hadoop或其他大数据平台进行进一步分析。
2. 结果存储
大数据分析的结果often需要以可查询的形式存储,以供业务人员访问。MySQL非常适合这种场景:
CREATE TABLE daily_sales_summary (
date DATE PRIMARY KEY,
total_sales DECIMAL(15, 2),
unique_customers INT,
top_selling_product_id INT
);
实战技巧:MySQL与Python的结合

在大数据开发中,我们常常需要将MySQL与其他工具结合使用。以下是一个使用Python操作MySQL的简单示例:
import mysql.connector
def get_top_customers(limit=10):
conn = mysql.connector.connect(
host="localhost",
user="your_username",
password="your_password",
database="your_database"
)
cursor = conn.cursor()
query = """
SELECT u.username, SUM(t.amount) as total_spent
FROM users u
JOIN transactions t ON u.id = t.user_id
GROUP BY u.id
ORDER BY total_spent DESC
LIMIT %s
"""
cursor.execute(query, (limit,))
results = cursor.fetchall()
cursor.close()
conn.close()
return results
top_customers = get_top_customers()
for customer in top_customers:
print(f"Customer: {customer[0]}, Total Spent: ${customer[1]}")
这个例子展示了如何使用Python连接MySQL,执行查询,并处理结果。这种结合对于数据分析和报告生成非常有用。
学习曲线与心态调整

在我从零开始学习MySQL的过程中,我深刻体会到学习曲线并非一帆风顺。有时你可能会感到沮丧,尤其是在面对复杂查询优化或性能调优时。但请记住,这是完全正常的。
我的建议是:
-
分解学习目标:将"精通MySQL"这个大目标分解成一系列小目标,如"掌握基本CRUD操作"、"理解索引原理"等。
-
创建学习项目:为自己创建一个个人项目,如一个简单的博客系统或者图书管理系统。这样可以将学到的知识立即应用到实践中。
-
拥抱错误:每一个错误都是学习的机会。当你遇到错误时,不要气馁,而是要仔细分析错误信息,理解其背后的原因。
-
保持好奇心:尝试深入理解MySQL的工作原理。例如,当你创建一个索引时,思考一下MySQL是如何使用这个索引来加速查询的。
-
定期回顾:每学习一段时间后,花些时间回顾和总结你学到的知识。这有助于巩固记忆,也能让你发现自己的进步。
进阶话题:分库分表

当你在"糙快猛"的学习过程中逐渐掌握了MySQL的基础知识,你可能会遇到一些性能瓶颈,特别是在处理大规模数据时。这时,分库分表的概念就变得非常重要了。
分库分表是指将一个大的数据库或表分割成多个小的数据库或表,以提高查询效率和系统的可扩展性。以下是一个简单的水平分表的例子:
-- 创建用户表1(存储用户ID为奇数的记录)
CREATE TABLE users_1 (
id INT PRIMARY KEY,
username VARCHAR(50),
email VARCHAR(100),
-- 其他字段...
CONSTRAINT check_user_id_odd CHECK (id % 2 = 1)
);
-- 创建用户表2(存储用户ID为偶数的记录)
CREATE TABLE users_2 (
id INT PRIMARY KEY,
username VARCHAR(50),
email VARCHAR(100),
-- 其他字段...
CONSTRAINT check_user_id_even CHECK (id % 2 = 0)
);
在实际应用中,你可能需要使用中间件(如MyCat或ShardingSphere)来管理这种分库分表的策略,使其对应用程序透明。
高级概念:查询优化与执行计划分析

在"糙快猛"的学习过程中,你可能会遇到一些性能问题。这时,理解查询优化和执行计划分析就显得尤为重要。
使用EXPLAIN分析查询
EXPLAIN是MySQL提供的一个强大工具,用于分析查询的执行计划。让我们看一个例子:
EXPLAIN SELECT u.username, COUNT(o.id) as order_count
FROM users u
LEFT JOIN orders o ON u.id = o.user_id
WHERE u.created_at > '2023-01-01'
GROUP BY u.id
HAVING order_count > 5
ORDER BY order_count DESC
LIMIT 10;
运行这个EXPLAIN命令会给出查询的执行计划。你需要关注的主要字段包括:
type:显示连接使用了哪种类型。从最好到最差依次是:system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALLpossible_keys:显示可能应用在这张表中的索引key:实际使用的索引rows:MySQL认为必须检查的行数
理解并优化这些参数可以大大提高查询效率。
优化技巧
- 正确使用索引:在WHERE和JOIN子句中频繁使用的列上创建索引。
- 避免使用SELECT *:只选择需要的列,减少数据传输量。
- 使用覆盖索引:尽可能在索引中包含所有需要的列,避免回表。
- 分页优化:对于大数据量的分页,使用"延迟关联"技术。
SELECT *
FROM users u
INNER JOIN (
SELECT id FROM users
WHERE status = 'active'
ORDER BY created_at DESC
LIMIT 10000, 20
) AS sub
ON u.id = sub.id;
实际案例分析:电商平台数据库优化

假设你正在为一个快速增长的电商平台优化数据库。以下是你可能遇到的一些挑战和解决方案:
挑战1:热点数据访问
问题:某些热门商品的页面访问量突然激增,导致数据库压力骤增。
解决方案:实施多级缓存策略。
- 使用Redis缓存热门商品信息。
- 在应用层实现本地缓存。
- 使用CDN缓存静态资源。
挑战2:订单表数据量剧增
问题:随着业务增长,订单表数据量已经超过了10亿行,查询变得极其缓慢。
解决方案:实施分库分表策略。
- 按照订单创建时间进行分表,每个月一张表。
- 使用分布式数据库中间件(如MyCat)管理多个数据库实例。
- 在应用层实现路由逻辑,将查询定向到正确的表。
-- 2023年6月的订单表
CREATE TABLE orders_202306 (
id BIGINT PRIMARY KEY,
user_id INT,
order_time TIMESTAMP,
total_amount DECIMAL(10, 2),
-- 其他字段...
INDEX idx_user_time (user_id, order_time)
) PARTITION BY RANGE (DAYOFMONTH(order_time)) (
PARTITION p01 VALUES LESS THAN (8),
PARTITION p02 VALUES LESS THAN (16),
PARTITION p03 VALUES LESS THAN (24),
PARTITION p04 VALUES LESS THAN MAXVALUE
);
挑战3:复杂的实时分析需求
问题:需要实时分析用户行为和销售趋势,但直接在交易数据库上进行复杂查询会影响系统性能。
解决方案:搭建实时数据仓库。
- 使用Canal监听MySQL binlog,将变更实时同步到Kafka。
- 使用Flink进行实时ETL,将数据转换后写入ClickHouse。
- 在ClickHouse上进行复杂的分析查询。
-- ClickHouse中的实时销售分析表
CREATE TABLE sales_analysis
(
event_time DateTime,
product_id UInt32,
category_id UInt16,
price Decimal(10,2),
quantity UInt16,
total_amount Decimal(10,2)
)
ENGINE = MergeTree()
PARTITION BY toYYYYMMDD(event_time)
ORDER BY (category_id, product_id, event_time);
未来趋势:MySQL在云原生时代的发展

随着云计算和容器技术的普及,MySQL也在不断适应这个新时代。以下是一些值得关注的趋势:
-
Kubernetes上的MySQL运维:使用operators如Presslabs MySQL Operator简化MySQL集群的部署和管理。
-
Serverless MySQL:如Amazon Aurora Serverless,按需自动扩展,适合负载变化大的应用。
-
分布式MySQL:如Vitess,提供水平扩展能力,支持超大规模数据处理。
-
实时数据复制与流处理集成:如Debezium,将MySQL变更以流的形式输出,便于与大数据生态系统集成。
-
AI驱动的查询优化:未来的MySQL优化器可能会利用机器学习技术,根据历史查询模式自动优化执行计划。
互动学习:自测小游戏
为了帮助你检验学习成果,我们设计了一个简单的自测游戏。尝试回答以下问题:
-
在MySQL中,以下哪种索引类型通常具有最好的性能?
A) B-Tree索引
B) Hash索引
C) 全文索引
D) 空间索引 -
当执行一个包含ORDER BY和LIMIT子句的查询时,如果没有合适的索引,MySQL可能会进行哪种操作?
A) 文件排序
B) 索引排序
C) 随机排序
D) 不排序 -
在大型数据库中,为什么"SELECT *"通常被认为是不好的实践?
A) 它总是导致全表扫描
B) 它可能返回不必要的数据,增加网络传输和应用层处理的开销
C) 它会使MySQL优化器困惑
D) 它会锁定整张表 -
在对一个大表进行分页查询时,为什么"LIMIT 1000000, 10"可能会有性能问题?
A) LIMIT子句总是很慢
B) MySQL需要扫描并丢弃前1000000行
C) 它会导致全表锁定
D) 它会使索引失效
答案将在文章的评论区最后公布,但在查看答案之前,建议你先独立思考这些问题。这种自测不仅能帮助你巩固知识,还能培养解决实际问题的能力。
结语:拥抱变化,持续进化
在这个技术日新月异的时代,MySQL和整个数据库领域都在不断evolve。作为一个"糙快猛"的学习者,我们需要保持开放和好奇的心态,随时准备接纳新知识。
记住,真正的大师永远怀着学习的热情。就像我从零开始到成为大数据开发者的旅程一样,你的每一步学习和实践都在塑造着未来的你。不要害怕犯错,因为每一个错误都是成长的机会。
在这个AI辅助学习的新时代,我们有了更多的工具和资源。但技术的本质和解决问题的能力仍然需要通过实践来掌握。所以,继续你的MySQL学习之旅吧!保持热情,保持好奇,你终将成为MySQL和大数据领域的专家!
让我们以"糙快猛"的姿态,在数据的海洋中探索,创新,并留下属于我们自己的印记。未来的世界需要你的智慧和创造力,现在正是启程的最好时机!
















 1010
1010

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











