







你是否曾经面对过这样的场景:数据量激增,处理时间延长,系统性能下降?作为一名大数据开发人员,我深知高效的ETL(提取、转换、加载)流程对于数据仓库的重要性。今天,让我们一起探索如何设计一个能够应对海量数据、保证数据质量、并且高效运行的ETL流程。

目录
1. 为什么ETL流程如此重要?
在大数据时代,ETL流程就像是数据仓库的心脏,它负责将分散在各个源系统的原始数据抽取出来,经过清洗、转换和集成,最终加载到数据仓库中。一个高效的ETL流程不仅能够保证数据的及时性和准确性,还能大大提升整个数据仓库系统的性能和可扩展性。
想象一下,如果你的ETL流程效率低下,会发生什么?
- 数据更新延迟,导致决策失误
- 处理时间过长,影响其他系统操作
- 数据质量问题频发,引起用户不信任
- 系统资源消耗过大,成本激增

因此,设计一个高效的ETL流程,对于任何依赖数据驱动决策的组织来说都是至关重要的。
2. 高效ETL流程的核心原则
在深入探讨设计步骤之前,让我们先明确高效ETL流程应该遵循的核心原则:
- 数据质量优先: 确保数据的准确性、完整性和一致性是首要任务。
- 性能至上: 优化处理速度,减少资源消耗。
- 可扩展性: 设计应能够轻松应对数据量的增长。
- 灵活性: 能够快速适应源数据结构的变化。
- 可监控性: 提供充分的日志和监控机制,便于问题定位和优化。
- 增量处理: 尽可能采用增量方式,避免全量处理带来的性能开销。
- 并行化: 充分利用分布式计算资源,提高处理效率。

3. 设计高效ETL流程的步骤
现在,让我们逐步探讨如何设计一个高效的ETL流程:

3.1 需求分析和规划
在开始设计之前,我们需要深入了解业务需求和数据特征:
- 明确数据源的类型、格式和更新频率
- 定义数据转换规则和业务逻辑
- 确定数据仓库的模型结构
- 制定性能指标和SLA要求

3.2 数据源分析
详细分析每个数据源的特点:
- 数据量大小和增长趋势
- 数据质量状况
- 访问方式和限制条件
- 更新频率和模式(全量/增量)

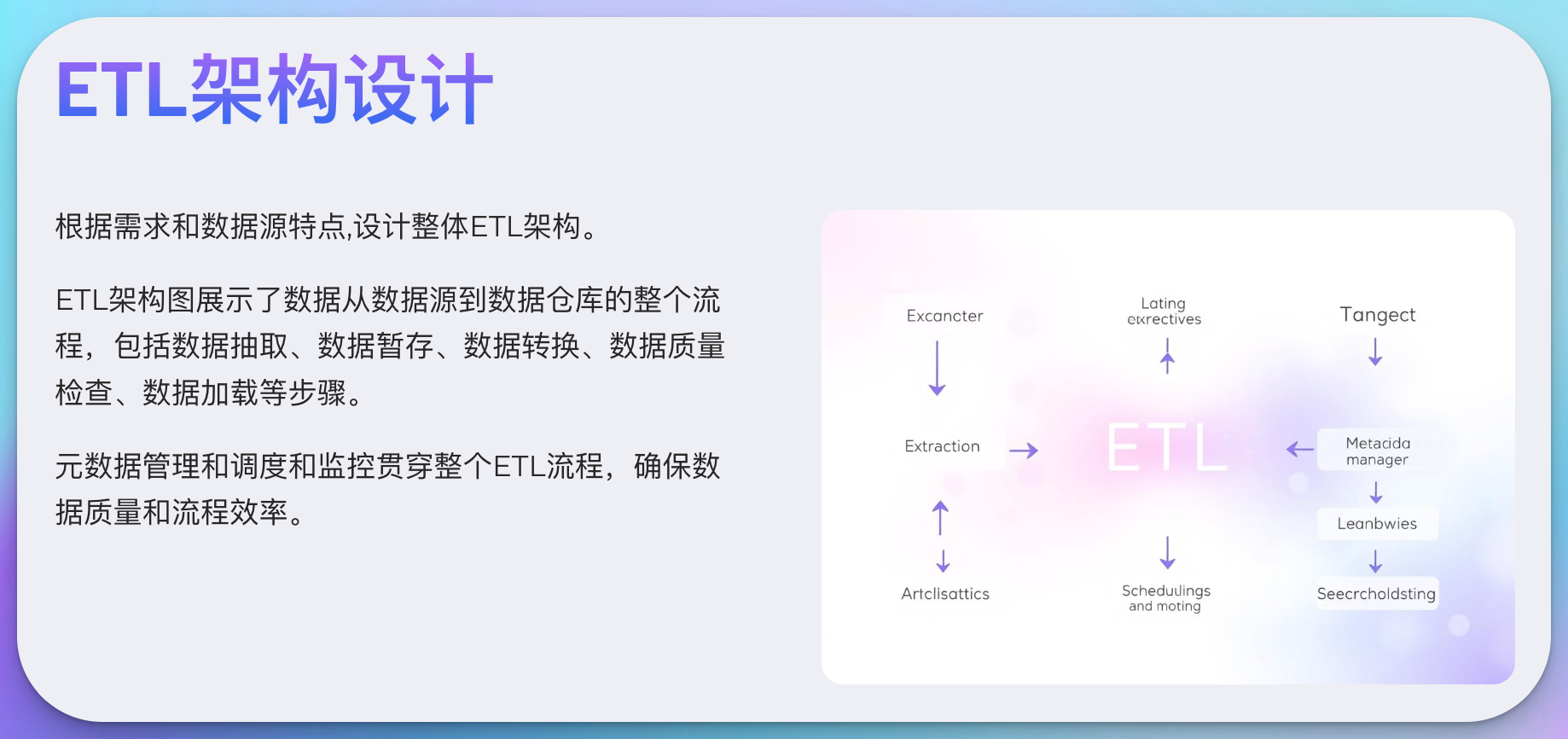
3.3 ETL架构设计
根据需求和数据源特点,设计整体ETL架构:
3.4 抽取策略设计
选择合适的抽取策略:
- 全量抽取: 适用于小规模、变化频繁的数据
- 增量抽取: 适用于大规模、变化相对稳定的数据
- 变更数据捕获(CDC): 实时捕获源系统的数据变更
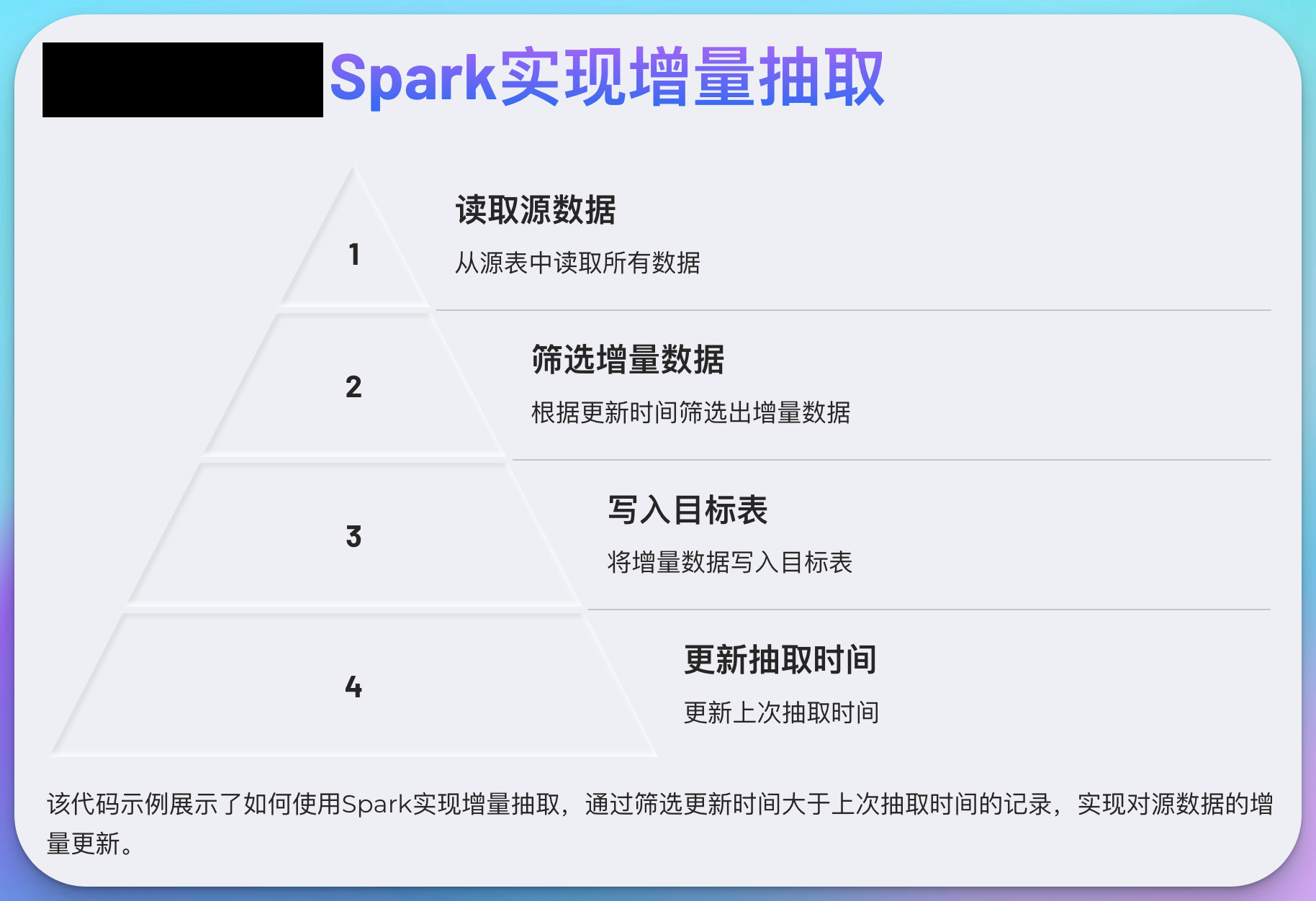
示例:使用Spark实现增量抽取
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
def incremental_extract(spark, source_table, target_table, last_extract_time):
# 读取源数据
source_df = spark.read.table(source_table)
# 筛选增量数据
incremental_df = source_df.filter(col("update_time") > last_extract_time)
# 写入目标表
incremental_df.write.mode("append").saveAsTable(target_table)
# 更新抽取时间
new_extract_time = incremental_df.agg({"update_time": "max"}).collect()[0][0]
return new_extract_time
# 使用示例
spark = SparkSession.builder.appName("IncrementalExtract").getOrCreate()
last_extract_time = "2024-03-01 00:00:00"
new_extract_time = incremental_extract(spark, "source_orders", "stage_orders", last_extract_time)
print(f"新的抽取时间: {new_extract_time}")

3.5 转换逻辑设计
设计数据转换逻辑,包括:
- 数据清洗:处理空值、异常值、重复数据等
- 数据标准化:统一编码、格式转换等
- 业务规则应用:计算派生字段、聚合统计等
- 维度处理:缓慢变化维度(SCD)处理

示例:使用Spark SQL进行数据转换
from pyspark.sql import SparkSession
from pyspark.sql.functions import when, col, to_date
def transform_order_data(spark):
# 读取暂存区数据
stage_df = spark.read.table("stage_orders")
# 数据清洗和转换
cleaned_df = stage_df.withColumn(
"order_status",
when(col("order_status") == "", "Unknown")
.otherwise(col("order_status"))
).withColumn(
"order_date",
to_date(col("order_date"), "yyyy-MM-dd")
)
# 应用业务规则
transformed_df = cleaned_df.withColumn(
"is_high_value",
when(col("order_amount") > 1000, True).otherwise(False)
)
# 写入转换后的数据
transformed_df.write.mode("overwrite").saveAsTable("transformed_orders")
# 使用示例
spark = SparkSession.builder.appName("OrderTransform").getOrCreate()
transform_order_data(spark)
3.6 加载策略设计
根据数据仓库模型和性能需求,设计加载策略:
- 直接加载:适用于小规模数据
- 分批加载:将大规模数据分成多批次加载
- 并行加载:多个维度或事实表并行加载

示例:使用Spark实现分批并行加载
from pyspark.sql import SparkSession
from pyspark.sql.functions import spark_partition_id
import concurrent.futures
def load_partition(df, target_table, partition_id):
partition_df = df.filter(spark_partition_id() == partition_id)
partition_df.write.mode("append").saveAsTable(target_table)
return f"Partition {partition_id} loaded successfully"
def parallel_batch_load(spark, source_table, target_table, num_partitions):
# 读取源数据
source_df = spark.read.table(source_table)
# 重分区
repartitioned_df = source_df.repartition(num_partitions)
# 并行加载
with concurrent.futures.ThreadPoolExecutor(max_workers=num_partitions) as executor:
futures = [executor.submit(load_partition, repartitioned_df, target_table, i)
for i in range(num_partitions)]
for future in concurrent.futures.as_completed(futures):
print(future.result())
# 使用示例
spark = SparkSession.builder.appName("ParallelBatchLoad").getOrCreate()
parallel_batch_load(spark, "transformed_orders", "dw_fact_orders", 4)

3.7 性能优化
应用各种优化技术提升ETL性能:
- 合理使用缓存
- 优化Spark参数配置
- 采用列式存储格式(如Parquet)
- 实现数据倾斜处理
- 利用索引和分区
示例:Spark参数优化
spark = SparkSession.builder \
.appName("OptimizedETL") \
.config("spark.sql.shuffle.partitions", 200) \
.config("spark.default.parallelism", 100) \
.config("spark.sql.broadcastTimeout", 1800) \
.config("spark.sql.adaptive.enabled", "true") \
.config("spark.sql.adaptive.coalescePartitions.enabled", "true") \
.getOrCreate()

3.8 错误处理和恢复机制
设计健壮的错误处理和恢复机制:
- 实现检查点和断点续传
- 设计重试逻辑
- 记录详细的错误日志
示例:实现简单的断点续传机制
import pickle
def save_checkpoint(checkpoint_data, checkpoint_file):
with open(checkpoint_file, 'wb') as f:
pickle.dump(checkpoint_data, f)
def load_checkpoint(checkpoint_file):
try:
with open(checkpoint_file, 'rb') as f:
return pickle.load(f)
except FileNotFoundError:
return None
def etl_with_checkpoint(spark, source_table, target_table, checkpoint_file):
checkpoint = load_checkpoint(checkpoint_file)
if checkpoint:
start_id = checkpoint['last_processed_id']
else:
start_id = 0
try:
df = spark.read.table(source_table).filter(f"id > {start_id}")
# 执行ETL逻辑
transformed_df = transform_data(df)
transformed_df.write.mode("append").saveAsTable(target_table)
# 更新检查点
last_processed_id = df.agg({"id": "max"}).collect()[0][0]
save_checkpoint({'last_processed_id': last_processed_id}, checkpoint_file)
except Exception as e:
print(f"ETL失败: {str(e)}")
# 这里可以添加重试逻辑
# 使用示例
spark = SparkSession.builder.appName("CheckpointETL").getOrCreate()
etl_with_checkpoint(spark, "source_data", "target_data", "etl_checkpoint.pkl")

3.9 监控和日志设计
实现全面的监控和日志系统:
- 记录每个ETL步骤的执行时间和状态
- 监控系统资源使用情况
- 设置关键指标的告警阈值
示例:使用Python的logging模块实现ETL日志
import logging
import time
def setup_logger():
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
filename='etl.log'
)
return logging.getLogger('ETL_Logger')
def log_etl_step(logger, step_name, func):
def wrapper(*args, **kwargs):
start_time = time.time()
logger.info(f"开始执行 {step_name}")
try:
result = func(*args, **kwargs)
end_time = time.time()
logger.info(f"{step_name} 执行成功,耗时 {end_time - start_time:.2f} 秒")
return result
except Exception as e:
logger.error(f"{step_name} 执行失败: {str(e)}")
raise
return wrapper
# 使用示例
logger = setup_logger()
@log_etl_step(logger, "数据抽取")
def extract_data():
# 数据抽取逻辑
pass
@log_etl_step(logger, "数据转换")
def transform_data():
# 数据转换逻辑
pass
@log_etl_step(logger, "数据加载")
def load_data():
# 数据加载逻辑
pass
def run_etl():
extract_data()
transform_data()
load_data()
run_etl()

4. 实践案例:电商数据仓库的ETL流程优化
让我们通过一个电商数据仓库的ETL流程优化案例,来具体说明如何应用上述设计原则和步骤。
4.1 背景
某电商某电商平台面临数据处理的挑战:随着业务规模的快速增长,日订单量从10万增长到100万,原有的ETL流程已经无法满足需求,导致数据更新延迟、系统负载过高等问题。让我们看看如何优化他们的ETL流程。
4.2 现状分析
- 数据源:订单系统、用户系统、商品系统、物流系统
- 当前ETL流程:每日凌晨全量抽取,串行处理
- 主要问题:
- 处理时间长,影响次日业务运营
- 资源消耗大,成本高
- 缺乏实时性,无法支持实时分析需求
4.3 优化方案
4.3.1 数据抽取优化
- 实现增量抽取:
- 对订单表使用时间戳进行增量抽取
- 对用户和商品表使用CDC(变更数据捕获)技术
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
def incremental_extract_orders(spark, last_extract_time):
return spark.read.table("source_orders") \
.filter(col("create_time") > last_extract_time)
def cdc_extract_users(spark, cdc_table):
return spark.read.format("delta") \
.option("readChangeFeed", "true") \
.table(cdc_table)
# 使用示例
spark = SparkSession.builder.appName("IncrementalExtract").getOrCreate()
new_orders = incremental_extract_orders(spark, "2024-03-28 00:00:00")
changed_users = cdc_extract_users(spark, "cdc_users")
- 并行抽取:使用多线程同时从不同数据源抽取数据
import concurrent.futures
def parallel_extract(spark, extract_functions):
with concurrent.futures.ThreadPoolExecutor(max_workers=len(extract_functions)) as executor:
futures = [executor.submit(func, spark) for func in extract_functions]
return [future.result() for future in concurrent.futures.as_completed(futures)]
# 使用示例
extract_functions = [
incremental_extract_orders,
lambda spark: cdc_extract_users(spark, "cdc_users"),
lambda spark: cdc_extract_products(spark, "cdc_products")
]
extracted_data = parallel_extract(spark, extract_functions)
4.3.2 数据转换优化
- 使用Spark SQL进行高效转换:
from pyspark.sql.functions import when, col, explode
def transform_order_data(orders_df, users_df, products_df):
# 连接订单、用户和商品数据
enriched_orders = orders_df.join(users_df, "user_id") \
.join(products_df, "product_id")
# 应用业务规则
return enriched_orders.withColumn(
"order_status",
when(col("payment_status") == "paid", "completed")
.when(col("payment_status") == "pending", "processing")
.otherwise("cancelled")
).withColumn(
"is_new_customer",
when(col("user_order_count") == 1, True).otherwise(False)
).withColumn(
"order_items",
explode(col("items"))
)
# 使用示例
transformed_orders = transform_order_data(new_orders, changed_users, products_df)
- 使用UDF(用户定义函数)处理复杂逻辑:
from pyspark.sql.functions import udf
from pyspark.sql.types import StringType
@udf(returnType=StringType())
def calculate_delivery_status(order_date, current_date, delivery_date):
if delivery_date is not None:
return "delivered"
elif (current_date - order_date).days > 7:
return "delayed"
else:
return "in_transit"
# 在转换中使用UDF
transformed_orders = transformed_orders.withColumn(
"delivery_status",
calculate_delivery_status(col("order_date"), current_date(), col("delivery_date"))
)
4.3.3 数据加载优化
- 使用Spark的分区写入优化数据加载:
def optimized_load(df, target_table):
df.write \
.partitionBy("order_date") \
.format("parquet") \
.mode("overwrite") \
.option("overwriteSchema", "true") \
.saveAsTable(target_table)
# 使用示例
optimized_load(transformed_orders, "dw_fact_orders")
- 实现小批量实时加载:
from pyspark.sql import SparkSession
from pyspark.sql.functions import window
def micro_batch_load(spark):
orders_stream = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("subscribe", "orders") \
.load()
# 处理流数据
processed_orders = orders_stream.select(
from_json(col("value").cast("string"), order_schema).alias("order")
).select("order.*")
# 小批量写入
query = processed_orders \
.writeStream \
.outputMode("append") \
.format("parquet") \
.option("checkpointLocation", "/tmp/checkpoint") \
.option("path", "/data/orders") \
.trigger(processingTime='1 minute') \
.start()
query.awaitTermination()
# 使用示例
spark = SparkSession.builder.appName("MicroBatchETL").getOrCreate()
micro_batch_load(spark)
4.3.4 性能调优
- Spark参数优化:
spark = SparkSession.builder \
.appName("OptimizedETL") \
.config("spark.sql.adaptive.enabled", "true") \
.config("spark.sql.adaptive.coalescePartitions.enabled", "true") \
.config("spark.sql.shuffle.partitions", "200") \
.config("spark.default.parallelism", "100") \
.config("spark.memory.fraction", "0.8") \
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer") \
.getOrCreate()
- 数据倾斜处理:
from pyspark.sql.functions import broadcast
def handle_skew(orders_df, products_df):
# 对小表进行广播
return orders_df.join(broadcast(products_df), "product_id")
# 使用动态分区裁剪
spark.conf.set("spark.sql.optimizer.dynamicPartitionPruning.enabled", "true")
4.3.5 监控和告警

实现一个简单的监控系统:
import time
from prometheus_client import start_http_server, Gauge, Counter
# 定义指标
processing_time = Gauge('etl_processing_time', 'Time taken for ETL job')
records_processed = Counter('etl_records_processed', 'Number of records processed')
error_count = Counter('etl_error_count', 'Number of errors encountered')
def run_etl_with_monitoring():
start_time = time.time()
try:
# ETL逻辑
extract_data()
transform_data()
load_data()
records_processed.inc(processed_count)
except Exception as e:
error_count.inc()
raise
finally:
processing_time.set(time.time() - start_time)
# 启动Prometheus客户端
start_http_server(8000)
# 运行ETL
run_etl_with_monitoring()
4.4 优化效果
通过以上优化,该电商平台的ETL流程取得了显著改善:
- 处理时间:从原来的6小时缩短到1.5小时
- 资源利用率:提高了40%
- 数据时效性:实现了准实时数据更新,最大延迟不超过15分钟
- 成本节省:云计算资源成本降低了35%
5. 常见陷阱和解决方案
在设计和实现高效ETL流程时,我们可能会遇到一些常见的陷阱。以下是一些典型问题及其解决方案:

5.1 数据质量问题
陷阱: 源数据质量差,导致转换错误或加载失败。
解决方案:
- 实现数据质量检查机制:
from pyspark.sql.functions import col, when
def check_data_quality(df):
return df.select(
when(col("order_id").isNull(), 1).otherwise(0).alias("null_order_id"),
when(col("order_amount") < 0, 1).otherwise(0).alias("negative_amount"),
when(col("order_date") > current_date(), 1).otherwise(0).alias("future_date")
).agg(*[sum(col(c)).alias(c) for c in df.columns])
# 使用示例
quality_issues = check_data_quality(orders_df)
if quality_issues.filter("null_order_id > 0 OR negative_amount > 0 OR future_date > 0").count() > 0:
raise ValueError("Data quality check failed")
- 实现数据修复和补偿机制
- 与源系统团队合作,解决根本问题
5.2 性能瓶颈
陷阱: 随着数据量增长,ETL性能急剧下降。
解决方案:
- 使用分布式处理框架(如Spark)
- 实现增量处理
- 优化数据模型和查询
- 使用列式存储格式(如Parquet)
def optimize_storage(df, table_name):
df.write \
.format("parquet") \
.mode("overwrite") \
.partitionBy("year", "month") \
.bucketBy(100, "user_id") \
.sortBy("order_date") \
.saveAsTable(table_name)
# 使用示例
optimize_storage(transformed_orders, "optimized_orders")
5.3 依赖管理
陷阱: 复杂的表依赖关系导致ETL作业难以管理和调度。
解决方案:
- 使用工作流管理工具(如Apache Airflow)
- 实现依赖图自动生成和验证
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime, timedelta
default_args = {
'owner': 'data_team',
'depends_on_past': False,
'start_date': datetime(2024, 3, 1),
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
dag = DAG(
'etl_workflow',
default_args=default_args,
description='ETL workflow for e-commerce data',
schedule_interval=timedelta(days=1),
)
extract_task = PythonOperator(
task_id='extract_data',
python_callable=extract_data,
dag=dag,
)
transform_task = PythonOperator(
task_id='transform_data',
python_callable=transform_data,
dag=dag,
)
load_task = PythonOperator(
task_id='load_data',
python_callable=load_data,
dag=dag,
)
extract_task >> transform_task >> load_task
5.4 错误处理和恢复
陷阱: ETL作业失败后难以恢复,导致数据丢失或不一致。
解决方案:
- 实现检查点和断点续传机制
- 使用事务来保证数据一致性
- 实现智能重试机制
from pyspark.sql import SparkSession
import time
def etl_with_retry(func, max_retries=3, delay=60):
for attempt in range(max_retries):
try:
return func()
except Exception as e:
if attempt == max_retries - 1:
raise
print(f"Attempt {attempt + 1} failed. Retrying in {delay} seconds...")
time.sleep(delay)
delay *= 2 # 指数退避
def run_etl():
spark = SparkSession.builder.appName("ETLWithRetry").getOrCreate()
@etl_with_retry
def extract():
# 提取逻辑
pass
@etl_with_retry
def transform(data):
# 转换逻辑
pass
@etl_with_retry
def load(data):
# 加载逻辑
pass
data = extract()
transformed_data = transform(data)
load(transformed_data)
# 运行ETL
run_etl()
6. 未来展望:ETL的发展趋势
随着技术的不断进步,ETL领域也在持续演变。以下是一些值得关注的趋势:
-
实时ETL:
- 流处理技术(如Apache Flink, Spark Streaming)的应用将更加广泛
- 实现亚秒级的数据延迟
-
智能ETL:
- 利用机器学习自动优化ETL流程
- 智能数据质量控制和异常检测
-
Serverless ETL:
- 无需管理基础设施,按需使用计算资源
- 降低运维成本,提高灵活性
-
数据编排(Data Orchestration):
- 更智- 更智能的数据流程编排,自动化管道构建
- 跨平台、跨云的数据集成变得更加便捷
-
DataOps:
- 将DevOps理念应用到数据工程中
- 持续集成、持续交付(CI/CD)在ETL开发中的广泛应用
-
数据网格(Data Mesh):
- 去中心化的数据架构
- 领域驱动的数据所有权和管理
-
ETL即代码(ETL as Code):
- 使用版本控制和代码审查来管理ETL逻辑
- 提高ETL开发的可维护性和协作效率
让我们通过一些代码示例来展示这些趋势如何影响ETL的实践:
6.1 实时ETL示例
使用Apache Flink实现实时ETL:
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
public class RealTimeETL {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 配置Kafka消费者
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("group.id", "real-time-etl");
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>("input-topic", new SimpleStringSchema(), properties);
// 读取输入流
DataStream<String> inputStream = env.addSource(consumer);
// 实时ETL转换
DataStream<String> transformedStream = inputStream
.map(new TransformationFunction())
.filter(new QualityCheckFunction());
// 配置Kafka生产者
FlinkKafkaProducer<String> producer = new FlinkKafkaProducer<>("output-topic", new SimpleStringSchema(), properties);
// 写入输出流
transformedStream.addSink(producer);
env.execute("Real-time ETL Job");
}
}
6.2 智能ETL示例
使用机器学习优化ETL参数:
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestRegressor
import pandas as pd
def optimize_etl_parameters(historical_data):
# 准备特征和目标变量
X = historical_data[['data_volume', 'cpu_cores', 'memory']]
y = historical_data['processing_time']
# 定义模型和参数网格
model = RandomForestRegressor()
param_grid = {
'n_estimators': [100, 200, 300],
'max_depth': [10, 20, 30],
'min_samples_split': [2, 5, 10]
}
# 使用网格搜索找到最佳参数
grid_search = GridSearchCV(model, param_grid, cv=5)
grid_search.fit(X, y)
# 返回最佳参数
return grid_search.best_params_
# 使用示例
historical_data = pd.read_csv('etl_performance_logs.csv')
best_params = optimize_etl_parameters(historical_data)
print("最佳ETL参数:", best_params)
6.3 Serverless ETL示例
使用AWS Lambda实现Serverless ETL:
import json
import boto3
def lambda_handler(event, context):
# 初始化S3客户端
s3 = boto3.client('s3')
# 从事件中获取输入文件信息
bucket = event['Records'][0]['s3']['bucket']['name']
key = event['Records'][0]['s3']['object']['key']
# 读取输入文件
response = s3.get_object(Bucket=bucket, Key=key)
content = response['Body'].read().decode('utf-8')
# 执行转换
transformed_content = transform_data(content)
# 写入转换后的数据
output_key = 'transformed/' + key
s3.put_object(Bucket=bucket, Key=output_key, Body=transformed_content)
return {
'statusCode': 200,
'body': json.dumps('ETL process completed successfully!')
}
def transform_data(content):
# 实现你的转换逻辑
return content.upper() # 示例:将所有文本转换为大写
6.4 DataOps示例
使用GitLab CI/CD实现ETL的持续集成和部署:
# .gitlab-ci.yml
stages:
- test
- build
- deploy
test_etl:
stage: test
script:
- pip install -r requirements.txt
- pytest tests/
build_etl:
stage: build
script:
- docker build -t my-etl-app .
only:
- master
deploy_etl:
stage: deploy
script:
- kubectl apply -f k8s-deployment.yaml
only:
- master
6.5 数据网格示例
实现领域驱动的数据产品:
class OrderDataProduct:
def __init__(self):
self.source_systems = ['order_system', 'payment_system']
self.schema = {
'order_id': 'string',
'customer_id': 'string',
'order_date': 'date',
'total_amount': 'decimal',
'status': 'string'
}
def extract(self):
# 从源系统提取数据
pass
def transform(self, data):
# 应用领域特定的转换
pass
def load(self, data):
# 加载到数据产品存储
pass
def validate(self, data):
# 应用领域特定的数据质量规则
pass
def expose(self):
# 提供API或其他访问方式
pass
# 使用示例
order_product = OrderDataProduct()
raw_data = order_product.extract()
transformed_data = order_product.transform(raw_data)
order_product.validate(transformed_data)
order_product.load(transformed_data)
order_product.expose()
这些示例展示了ETL未来发展趋势的一些实践应用。随着这些趋势的发展,ETL流程将变得更加智能、高效和易于管理。
7. 总结与展望
在本文中,我们深入探讨了如何设计一个高效的ETL流程。我们从ETL的基本概念出发,详细讲解了设计步骤,分享了最佳实践和优化技巧,并通过一个实际案例展示了如何应用这些原则。此外,我们还讨论了ETL领域的未来发展趋势。

关键要点总结:
- ETL流程的效率直接影响数据仓库的性能和数据质量。
- 设计高效ETL需要考虑数据源特性、转换逻辑复杂度、目标系统要求等多个因素。
- 增量处理、并行化、数据分区等技术可以显著提升ETL性能。
- 错误处理、监控告警、数据质量检查等机制对于保证ETL的可靠性至关重要。
- 新兴技术如实时处理、机器学习、Serverless等正在改变ETL的实现方式。
随着数据量的持续增长和实时分析需求的增加,ETL流程的设计和优化将面临更多挑战。然而,这也带来了新的机遇。通过采用先进的技术和最佳实践,我们可以构建更加高效、可靠和智能的ETL系统,为数据驱动的决策提供坚实的基础。
未来,我们可以期待看到:
- 更智能的自动化ETL工具
- 跨云、跨平台的无缝数据集成
- 基于机器学习的自适应ETL优化
- 更加敏捷和协作的ETL开发模式
作为数据工程师,我们应该持续学习和实践,不断提升自己的ETL设计和优化能力,为组织创造更大的数据价值。
你有什么关于ETL设计的经验或见解吗?欢迎在评论区分享你的想法!


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











