







使用python获取网页需要使用到urllib模块,我们先导入:
from urllib.request import Request,urlopen下面用Request生成一个请求头,这里抓取的是百度的首页:
req = Request('https://www.baidu.com/')
req.add_header('User-Agent', 'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25')
也可以这样写:
req = Request('https://www.baidu.com/', headers={'User-Agent':'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25'})哪一个更好,这就看大家的个人喜好了。
请求头的信息,我们可以通过浏览器的开发人员工具获得:
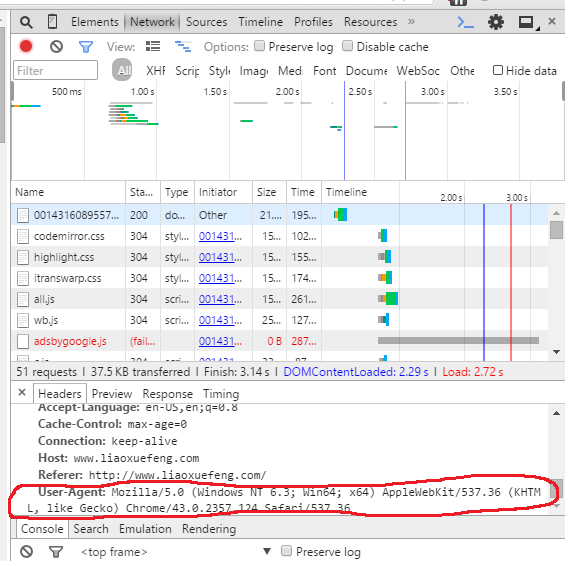
添加请求头的意义在于防止服务器的过滤,一些服务器会屏蔽没有请求头的请求。
下面我们就可以使用urlopen就可以打开网页了,不过urlopen的返回值是一个类:<class 'http.client.HTTPResponse'>我们需要read函数来获得网页的源代码。
file = urlopen(req).read()file中储存的就是网页的html编码,我们可以用print将网页打印下来,或是保存在一个文件里。
with open('out.html', 'wb') as f:
f.write(file)打开我们的网页文件,就是百度的首页:
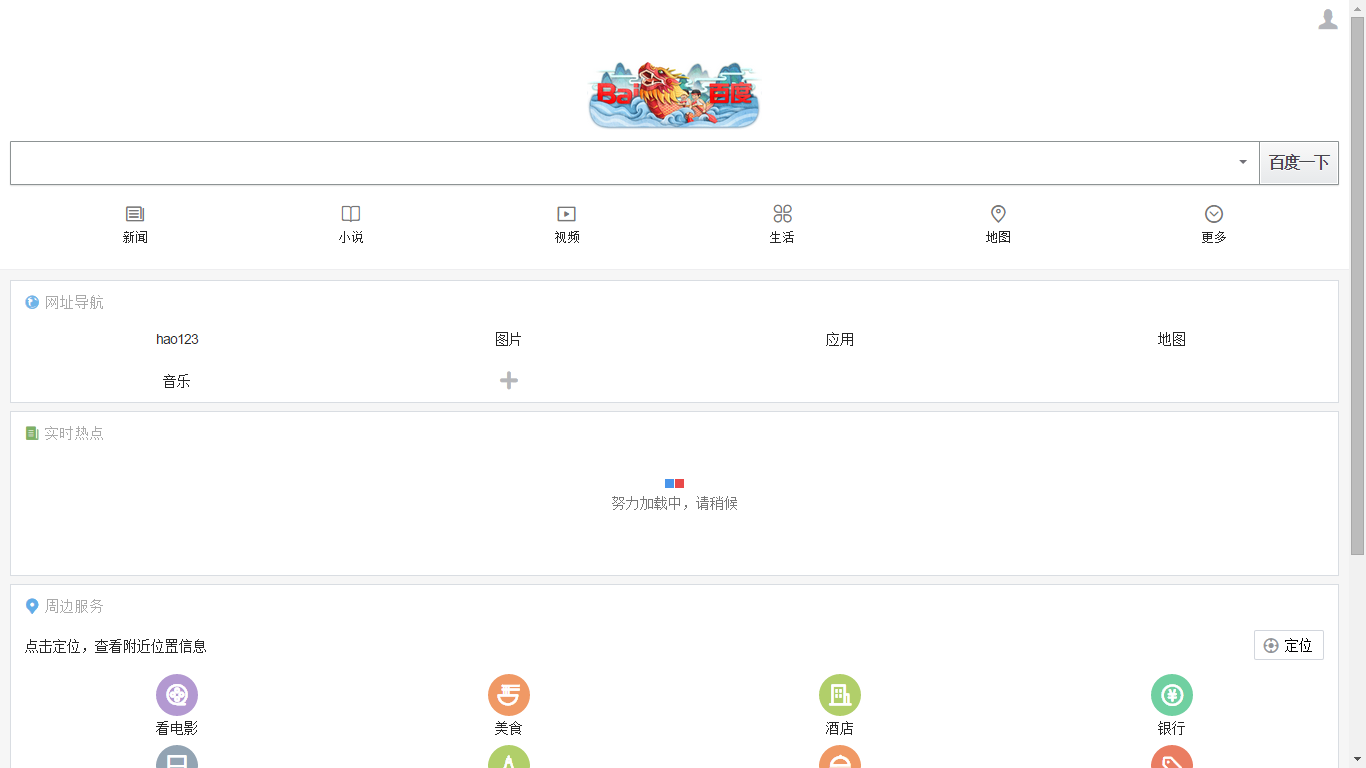
值得一提的是,我们抓取的网页,其实只是百度首页的html文件。但在在浏览器中打开时,浏览器会自动从网络上下载关联的图片、js、css文件等将我们的网页补全了。
总的来说用python抓取网页本身是很简单的,复杂重复的工作,python都通过了模块来完成,python本身就是一门立足于简介的语言。
下面是我的python脚本:
from urllib.request import Request, urlopen
req = Request('https://www.baidu.com/')
req.add_header('User-Agent',
'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25')
file = urlopen(req).read()
with open('out.html', 'wb') as f:
f.write(file)
python版本:python3.4
2.7与此类似
<如有遗漏,欢迎留言补充,转载请注明出处>















 4154
4154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









