







前言
看到标题,可能你就失去了继续阅读的兴趣,反汇编?跟我的工作有关?汇编还记的?反正写程序用不到?的确,你可能几年都没碰过汇编,对于汇编指令记得更是寥寥无几,又或者你的工作永远也不会用到汇编了,所以很少去关注。但我想学习汇编并不是要求我们去从事跟其相关的领域,而是给了我们另一个从机器角度去看待程序的方式。这样,当下次处理我们程序中的指针就能更加清晰和随意,对于程序的栈帧结构和读写操作更加明了,以此为程序的优化提供可靠的依据。或者对于类似JAVA虚拟机的内部运行机制也能够了如指掌。甚至对于某些简单漏洞攻击或木马病毒也能通过反汇编的方式明白其中的奥秘。当然,你也可以据此根据程序的需求,对程序进行汇编级的重构来最大限度的提高执行效率,当然这可能会牺牲程序本身的可移植性。
在本篇中我不准备讲解关于汇编语言的基础指令,因为对于不同机器的处理器芯片其指令系统可能是不相同的,但其原理大都相同,比如寄存器、指令的寻址方式,存取方式等等。我将通过编写简单的C程序并结合其汇编代码来讲解本章的内容。在本篇中,我使用MS的VS开发工具来查看相关的代码,因此熟悉和了解X86指令系统是有必要的。下面就进入正题:
1. 程序编码
在第CSI-I一篇中,我们知道了程序经过编译阶段将文本文件.i编译成.s汇编文件。这个汇编文件就是对我们程序的低层翻译。而无论你是学习C或者JAVA,对这里的了解对你会有一定的帮助。
首先我们看一段代码和其对应的汇编指令:
Int accum = 0 ;
Int sum (intx,int y)
{
Int t = x+y;
Accum = t;
Return t;
}
这段程序计算两个数的和并返回给一个全局变量accum。下面是调试生成对应的汇编指令。我们从先从地址为0215139E的指令往后看,首先通过mov指令取到x的值,然后通过add指令相加存放到eax寄存器,该寄存器一般用来存放函数的返回值。之后再存放到t临时变量和全局变量的存储区中,结果通过eax返回。

接下来,我们继续查看在该段代码中存储区域的值。
0x0125139E
编码 机器码 指令
1:8b 45 08 mov eax ,dword ptr[x]
2:03 45 0c add eax,dworkptr[y]
3:89 45 f8 mov dwordptr[t],eax
4:8b 45 f8 mov eax,dword ptr[t]
5:a3 38 71 25 01 mov dword ptr[accum(1257138h)],eax
6:8b 45 f8 mov eax,dworkptr[t]
根据两条指令的存储地址,我们可以得到上一条指令的长度。从而取到指令的对应的机器指令。汇编代码对于机器来说是透明存在的,微处理器只能够识别汇编指令对应的机器码,而这种从机器码到汇编的转变是我们为了方便记忆和理解而做的人为的翻译。所以,基于这样的想法,才有了后来的高级语言。学过汇编语言我们知道,一条指令是由操作码和操作数构成的,操作码代表指令的所具有的功能,而操作数代表执行该操作所需要的数据,而一般的数据来源就是寄存器或者存储器。比如一条mov指令可以将一个寄存器A的数据存放到寄存器B中,或者将寄存器C中的数据存放到存储器M的位置,这中数据的不同存取方式就构成了指令系统的寻址方式。
从上面的指令可以作出推测,1,4,6的属于同一种寻址方式,对应的MOV操作码为8B,而3对应的另一种寻址方式的MOV操作码为89。这段指令中的dword ptr[]其实是寄存器间接寻址。可以看到在第1,2条指令中的最后一个字节08,0C是函数sum的两个参数x,y的在栈中基于寄存器ebp的偏移地址,这个是由栈帧结构决定的,而第二个字节45分别就应该代表了寄存器eax和ebp寄存器,表示该指令所操作的寄存器。
第5条指令占去了5个字节,其中a3代表了指令的操作码,后面的四个字节代表的应该是全局变量accum相对ebp的偏移地址1257138h。而指令中给出的是38 71 25 01 这是由于机器是小端存储方式,即高位地址存储数据高位,低位地址存储数据低位。所以a3所代表的指令,我们也可以看做是Mov指令的一种形式。
2.栈帧结构
IA32程序用程序栈支持过程调用。机器用栈来传递过程参数、存储返回信息、保存寄存器用于以后恢复,以及本地存储。为单个过程函数分配的栈称为栈帧。栈帧的最顶端以两个指针界定,寄存器ebp为帧指针,而寄存器esp为栈指针。当程序执行时,栈指针可以移动因此大多数的数据访问都是基于栈指针的。
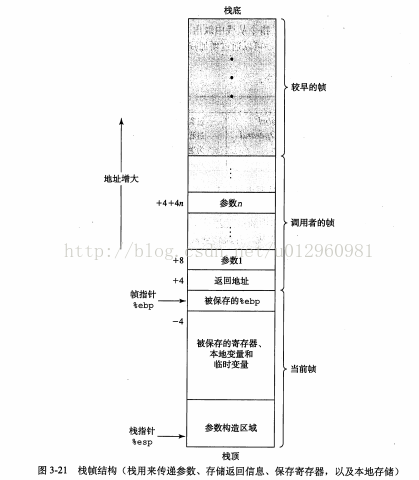
从图中可以看到,栈是向低地址方向增长的。栈寄存器%esp总是指向栈顶。
假设过程P(调用者)调用过程Q(被调用者),则Q的参数放在P的栈帧中。另外,当P调用Q时,P中的返回地址被压入栈中,形成P的栈帧的末尾。返回地址就是当程序从Q返回是应该继续执行的地方。Q的栈帧从保存的帧指针ebp的值开始,后面保存的是其他寄存器的值。
在了解程序在执行过程中栈的变化情况,我们首先了解几个汇编指令:
1.CALL指令,将返回地址入栈,并跳转到被调用过程的起始处。返回地址是在程序中紧跟在call指令后面的那条指令的地址。
2.RET指令,从栈中弹出返回地址,并跳转到对应的位置。
3.LEAVE指令,这条指令使栈做好返回的准备,相当于:
Mov ebp,esp
Pop ebp
下面看下程序sum再调用过程中的栈帧结构:
首先是调用者的栈帧结构,在这里就是Main函数对应的栈帧结构。我们看到
在地址002B1404处,使用call指令来调用sum函数,并在之前的将参数a,b都push到栈中。在调用结束后地址002B1409处,add指令用来将sum的参数从自己的栈帧中弹出。
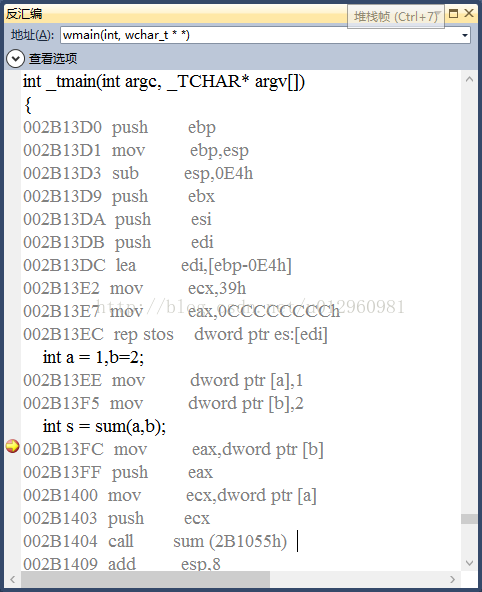
接着我们继续跟进地址2B1055即CALL指令所调用的地址处。
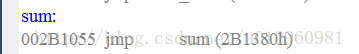
在此处又用jmp指令做了一次跳转(应该是编译器所为),跳转到地址2B1380处。在该地址处我们看到的是sum的栈帧结构。

看完这两个过程的栈帧结构,我们发现其有很大的相似之处,至少在开头的前几条指令是这样的。先是保存了帧寄存器的值,然后将其值设为栈指针的值,随后开辟了栈帧所需要的空间,然后再保存了ebx,esi,edi寄存器的值,最后执行了几条莫名的指令才开始了函数所要做的计算过程。其实这么做不无道理,都是为了遵循寄存器的使用惯例:
根据惯例,寄存器eax,edx和ecx被划分为调用者保存寄存器。即这些寄存器中的内容是由调用者保存的,因此被调用者可以随意覆盖。而另一些寄存器,edi,esi,ebx是被调用者保存寄存器,这就要求被调用者在使用之前先将其保存在自己的栈帧中,待使用完成后再从栈中恢复。此外根据惯例被调用者也必须对ebp,esp进行保存。
那么在那开头的三条push指令之后的那几条指令是用来干什么的?在后面讲解缓冲区溢出时我们就会明白,这几条指令是用来防止缓冲溢出的,属于编译器所做的特殊处理。
在了解了函数的栈帧结构后,我们再接着看下对于一个递归函数来说,它的栈帧结构到底是怎么样的,我们知道递归函数能够对其本身进行重复调用,但调用过程到底是如何进行的呢?下面我们再看一个例子:
int rfact(int n)
{
int result ;
if(n<=1)
result= 1;
else
result= n*rfact(n-1);
return result;
}
对于这个计算阶乘的递归函数,我们得到的汇编程序如下:
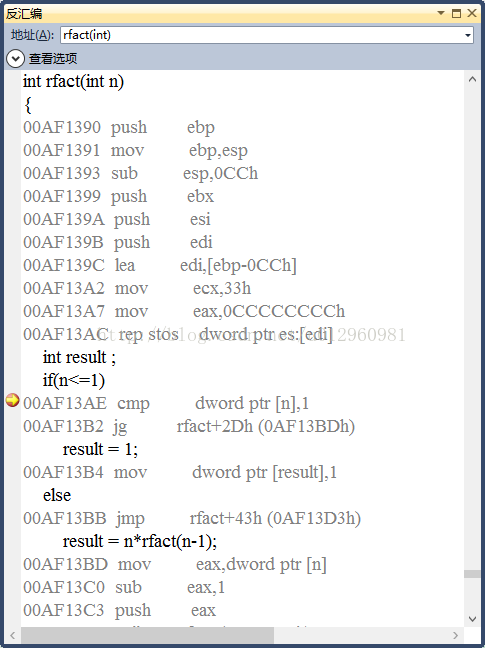
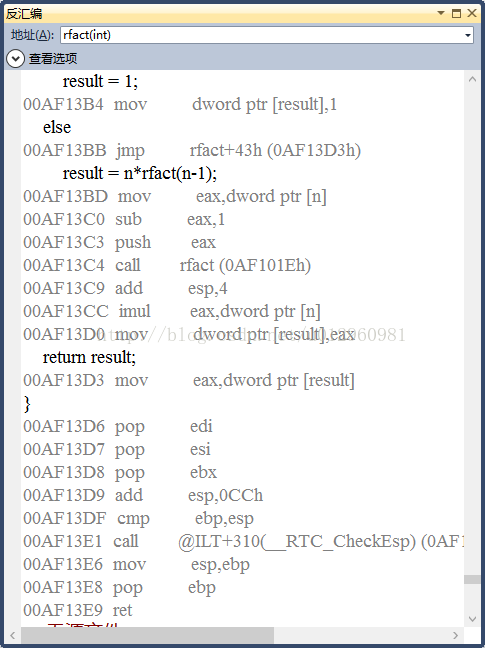
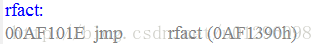
我们可以看到对于递归过程,其栈帧结构没有多大的变化,只是在执行过程中能够调用其过程本身,每个调用在栈中都有其私有的空间,因此多个未完成调用的局部变量不会互相影响。这是由于栈本省的特性所提供的,当过程调用时分配局部存储,当返回时释放存储。
根据上面的汇编代码我们可以试着画出该递归函数的栈帧结构图:
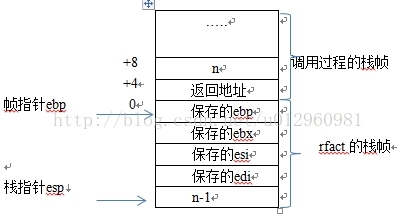
可以看到,函数在每次调用自身的过程中,需要占用一定的栈空间,所以如果递归函数不能够正常的返回而无限调用自身,会不断的消耗进程的栈空间,最终导致栈溢出。所以在写递归调用时要异常的小心,要保证其出口的正确性。
同时另一方面,从汇编代码中可以大致看出,递归调用在执行过程中,需要进行频繁的栈操作,每次调用自身都需要使栈做好准备,包括了被调用者寄存器的内容保存,返回地址以及释放栈时的相应动作导致了递归调用的效率并不是很高。
4. 异质的数据结构
C语言提供了两种结合不同类型的对象来创建数据类型的机制:结构(struct)和联合(union).
结构是将不同类型的对象聚合到一个对象中,结构中各个组成部分用名字来引用。类似于数组的实现,结构的所有组成部分存储在一段连续的区域内。
联合提供了一种方式,能够规避C语言的类型系统,允许以多种类型来引用一个对象。其组成部分的不同字段引用的是相同的存储块。
对于联合,我们很清楚的知道其存储大小就是最大字段的大小。而对于结构来说,由于涉及到数据对齐(alignment)有时候容易搞错其真正所占用的存储大小。所以下面我们重点看下结构(struct)的存储形式。
关于数据对齐,我们需要了解其存在的意义,许多计算机系统对于基本数据类型的合法地址做出了一些限制,要求某种类型对象的地址必须是某个K值(通常是2、4或者8)的倍数。这种对齐限制简化了形成处理器和存储器系统的硬件设计。例如,假设一个处理器总是从存储器中取出8个字节,则地址必须为8的倍数。如果我们能够保证将所有的double类型数据的地址对齐成8的倍数,那么就可以用一个存储器操作来读写值了,否则,可能需要执行两次存储器访问,因为对象可能被放在两个8字节存储块中。
可见,对齐数据可以提高存储器系统的性能。Linux沿用的对齐策略是,2字节数据类型的地址必须是2的倍数,而较大的数据类型的地址必须是4的倍数。 Microsoft 对齐的要求更加严格,任何K字节基本对象的地址都必须是K的倍数,这一点从VC或者VS编译器上的struct默认所占用的存储大小也是可以看出的。下面我们就看几个简单的例子来说明struct是如何进行内存分配的:
Struct A
{
Double d;
Char c;
Int n;
};
我们定义一个函数print打印一个结构A的对象值,并取到对应的汇编代码如下:

可以很容易的看到,结构A中各成员在结构中的偏移值分别为0,8,C。所以我们可以推测出结构的存储形式为:

即double 类型8字节,char类型成员1字节,外加3个对齐字节,int类型成员4个字节,总共16个字节。
看到这里,我有必要解释下这额外的3个字节,其实根据Microsoft的对齐要求,我们稍加推测就能明白其中的缘由。任意K字节的基本对象的地址必须是K的倍数,同样对于结构中的成员也要满足。在这个结构中:成员d的偏移为0是doubel(8字节)类型的字节倍数,成员c偏移为8同样是char(1字节)类型的字节倍数,而成员n的偏移此时如果为9(8+1)则不是int(4字节)类型的字节倍数。所以需要对其偏移值作出调整在前面增加3个字节来满足对齐的要求。即double 类型8字节,char类型成员1字节,外加3个对齐字节,int类型成员4个字节,总共16个字节。
如果我们对结构A进行调整如下:
Struct A2
{
Char c;
Double d;
Int n;
}
编译器该结构的值为24,所以我们可以想象的到其存储形式为:

我们可能对结果末尾的4个字节有些困惑,按照各成员在结构中的偏移位置来说这4个字节的确显得多余。而其实这4个字节是用来使结构的边界对齐,这要求结构的大小必须是其内部占最大空间的基本对象类型所占用字节数的整数倍。而该结构最大的基本类型为double 占8个字节,所以需要添加末尾的4字节来使整个结构满足对齐的要求。
还有一种结构,其成员包含了另一种结构,在这种情况下,其内部结构成员的偏移规定为该内部结构中最大的基础对象类型所占字节数的倍数开始的。如下:
Struct B
{
Char c;
A2 a;
Int n;
};
我们知道对于A2,其最大的基础类型为double占8个字节,所以该内部结构A2在B中的偏移位置应该为8的倍数,固结构大小应该为8+24+4=36,但其还不满足结构B的边界要求(必须为8的倍数).所以需要添加额外的4字节,所以结构的总大小应该为40字节。
到这里,本章的介绍就算完成了,当然这并不是所有的内容,还有很多基本的内容我没有多做介绍,特别对于汇编指令、以及控制语句的汇编级代码没有多做介绍,还请有兴趣的读者自行学习。至于本篇所介绍的部分,如果任何疏忽及不正之处,烦请谅解指正。














 3572
3572











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









