







Java面试题
Java集合
-
ArrayList、HashSet、HashMap是线程安全的吗?如果不是怎么获取线程安全的集合?
ArrayList、HashSet、HashMap都不是线程安全的。在集合中只有Vector和HashTable是线程安全的
-
什么是JAVA集合
java 集合既用来存放对象的容器
- 集合主要分为Collection和Map两个接口
- Collection又分别被List和Set继承
- List被AbstractList实现,又分为ArrayList、LinkList和VectorList
- Set被AbstractSet实现,又分为HashSet和TreeSet
- Map被AbstractMap实现,又分为HashMap和TreeMap
- Map被Hashtable实现
-
哈希碰撞/哈希冲突是什么,如何解决?
-
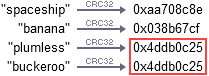
在对字符串,文件,甚至目录进行hash取值时,有可能得到的多个一样的hash值,这就是hash碰撞/hash冲突。举个众所周知的Hash函数CRC32,如果你给这个Hash函数“plumless” 和“buckeroo”这2个字符串,它会生成相同的Hash值,这是已知的Hash冲突
解决方法有:
1.开放地址法(再散列法)
开放地执法有一个公式:Hi=(H(key)+di) MOD m i=1,2,…,k(k<=m-1)
其中,m为哈希表的表长。di 是产生冲突的时候的增量序列。如果di值可能为1,2,3,…m-1,称线性探测再散列。如果di取1,则每次冲突之后,向后移动1个位置.如果di取值可能为1,-1,2,-2,4,-4,9,-9,16,-16,…kk,-kk(k<=m/2),称二次探测再散列。如果di取值可能为伪随机数列。称伪随机探测再散列。
2.再哈希法Rehash
当发生冲突时,使用第二个、第三个、哈希函数计算地址,直到无冲突时。缺点:计算时间增加。比如上面第一次按照姓首字母进行哈希,如果产生冲突可以按照姓字母首字母第二位进行哈希,再冲突,第三位,直到不冲突为止.这种方法不易产生聚集,但增加了计算时间。
3.链地址法(拉链法)
将所有关键字为同义词的记录存储在同一线性链表中.基本思想:将所有哈希地址为i的元素构成一个称为同义词链的单链表,并将单链表的头指针存在哈希表的第i个单元中,因而查找、插入和删除主要在同义词链中进行。链地址法适用于经常进行插入和删除的情况。对比JDK 1.7 hashMap的存储结构是不是很好理解。至于1.8之后链表长度大于6rehash 为树形结构不在此处讨论。
-
-
ArrayList和LinkedList的不同?
ArrayList类似于数组而LinkedList类似于链表
在ArrayList的前面或中间插入数据时,必须将其后所有的数据相应的后移,这会浪费很多时间,当然如果是只在集合后面添加元素,并随机访问其中元素时,使用ArrayList性能还是很出色的。
如果是对集合的前面或者红箭添加或删除数据时,并按照顺序访问其中的元素时,就应该使用LinkedList
总的来说ArrayList的查询效率高,增删效率差,适用于频繁查询和增删少的场景,而LinkedList的查询效率低,但增删效率高,使用与增删动作频繁和查询次数少的场景
-
ArrayList和Vector的区别?
-
同步性
Vector是线程安全的,而ArrayList不是线程安全的,如果是一个线程访问集合最好用ArrayList,因为它不考虑线程安全所以效率会高一些;如果有多个线程访问集合就用Vector,因为不需要再去考虑和编写线程安全的代码
-
数据增长
ArrayList与Vector都有一个初始的容量大小,当存储元素超过本身容量时,Vector默认增长原来的一倍,而ArrayList增加原来的0.5倍。Vector是可以设置增长的空间大小,而ArrayList没有提供设置增长空间的方法
-
-
HashMap的数据存储和实现原理你了解多少
-
存值
hashmap在存数据的时候是基于hash的原理,当我们调用put(key,value)方法的时候,其实我们会先对键key调用key.hashcode()方法,根据方法返回的hashcode来找到bucket的位置来存Entry对象。
如果出现hashcode相同的情况,这时候就会产生hash碰撞(hashmap的底层存储结构是 数组+链表),这时候根据hashcode找到对应的bucket,然后在链表逐一检查有没有存相同的key,用equals()进行比较,如果有则用新的value取代旧的value,如果没有就在链表的尾部加上这个新的Entry对象
-
取值
当使用get(key)时,会调用key的hashcode方法获得hashcode,然后根据hashcode找到bucket,优于bucket对应的链表中可能存有多个Entry,这个时候会调用key的equals()找到对应的Entry,然后把值返回
-
-
HashMap的长度为什么是2的幂次方?
- HashMap为了存取高效,要尽量较少碰撞,就是要尽量把数据分配均匀,每个链表长度大致相同,这个实现就在把数据存到哪个链表中的算法;
这个算法实际就是取模,hash%length,计算机中直接求余效率不如位移运算,源码中做了优化hash&(length-1),
hash%length==hash&(length-1)的前提是length是2的n次方;
为什么这样能均匀分布减少碰撞呢?2的n次方实际就是1后面n个0,2的n次方-1 实际就是n个1;
- HashMap为了存取高效,要尽量较少碰撞,就是要尽量把数据分配均匀,每个链表长度大致相同,这个实现就在把数据存到哪个链表中的算法;
-
HashSet和HashMap的区别与联系
HashSet实际上为(key,null)类型的HashMap,而我们知道,HashSet的key是不能重复的,所以HashSet的值自然也是没有重复的.因为HashMap的key可以为null,所以HashSet的值可以为null
HashMap HashSet HashMap实现了Map接口 HashSet实现了Set接口 HashMap储存键值对 HashSet仅仅存储对象 使用put()方法将元素放入map中 使用add()方法将元素放入set中 HashMap中使用键对象来计算hashcode值 HashSet使用成员对象来计算hashcode值,对于两个对象来说hashcode可能相同,所以equals()方法用来判断对象的相等性,如果两个对象不同的话,那么返回false HashMap比较快,因为是使用唯一的键来获取对象 HashSet较HashMap来说比较慢
Redis
1.Redis的特点
Redis全称Remote Dictionary Server(远程字典服务),用C编写,NoSQL数据库服务器。其本质是一个key-value的内存数据库,类似于memcached,其QPS能达到数十万次,单个value的最大限制1GB,而memcahed只有1MB,其支持的数据结构有: 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)
Redis的缺点就是其是内存数据库,其上限受限于运行的物理内存的大小
2.Redis的性能问题及解决放案
- Redis做内存快照(内存中数据在某一个时刻的转态记录)是有两个命令:
save:在主线程中执行,会导致阻塞
bgsave:创建一个子进程,专门写RDB文件,避免主线程阻塞,这是Redis RDB文件生成的默认配置。但是fork 创建过程中本身会阻塞主线程,主线程内存越大阻塞时间越长
- AOF持久化会导致重启恢复速度变慢
- Redis主从复制的速度和连接的稳定性受网络的影响,Master和Slave最好在一个局域网中
3.Redis使用的场景
● 会话缓存(Session Cache)
● 全页缓存(FPC)
● 队列
● 排行榜/计数器
● 发布/订阅
4.Redis的优缺点
优点
● QPS能达到数十万
● 所有的操作都是原子性的,也就是说一个操作要么成功要么失败,就像关系型数据库中的事务
● 支持丰富的数据类型
缺点
●因为是内存数据库所以受限于机器本身的内存大小,Redis本身可以有过期策略,但内存增长过快时需要定期 删除数据
●在重启Redis时,持久化的数据越大加载越慢,在完成加载之前,Redis将不提供服务
5.Redis的持久化是什么
RDB持久化:Redis默认的持久化方案。在指定的时间间隔内将内存中的数据写入到磁盘中,这些数据写在指定目录下的dump.rdb文件,Redis重启会通过dump.rdp文件恢复数据,因为是定时备份所以会有数据丢失的情况
AOF持久化:Redis默认不开启。它是为了弥补RDB的不足(数据丢失或数据不一致),所以它采用写日志的方式记录所有的写操作,Redis重启会通过日志文件恢复数据,这种情况如果数据量比较大的话,启动就会慢
RDB和AOF同时应用时:当Redis重启的时候,它会优先使用AOF来还原数据,因为数据比较全
6.RDB和AOF优缺点
优点
RDB:RDB是定时备份的,可以随时将数据还原到不同版本,也比较适用于灾难性恢复
AOF:AOF对日志文件进行追加,在日志进行写入过程中关机了或磁盘满了,使用redis-check-aof工具也可以修复这些问题
缺点
RDB:如果对数据完整性有要求的话就不适用于RDB,因为会丢数据。
每次保存RDB时,Redis都要fork()出一个子进程,由子进程进行数据持久化的工作。数据集比较大时,fork()会比较耗时,可能会在一定毫秒内停止处理客户端的请求
AOF:AOF数据量比较大,使用fsync策略,恢复数据速度慢于RDB
7.Redis的数据类型
-
字符串(strings):String数据结构是最简单的key-value类型
用法:
192.168.1.167:6379> set name dd OK 192.168.1.167:6379> get name "dd" -
散列(hashes):类似Java中的hash,可以存放对象值,如用户:用户名、年龄等,具体通过
HMSET指令设置 hash 中的多个域,而HGET取回单个域,hgetall取得所有域用法:
192.168.1.167:6379> hset user:1000 username dd birthyear 1999 verified 11 (integer) 3 192.168.1.167:6379> hget user:1000 username "dd" 192.168.1.167:6379> hgetall user:1000 1) "username" 2) "dd" 3) "birthyear" 4) "1999" 5) "verified" 6) "11" 192.168.1.167:6379> -
列表(lists):List其实就是双向链表,rpush 设置一个列表值,lrange 获取一个列表值
用法:
192.168.1.167:6379> rpush list a (integer) 1 192.168.1.167:6379> rpush list b (integer) 2 192.168.1.167:6379> rpush list c (integer) 3 192.168.1.167:6379> lrange list 0 -1 1) "a" 2) "b" 3) "c" 192.168.1.167:6379> -
集合(sets):Set 是 String 的无序排列,就是不根据插入顺序进行排序。集合中不能出现重复数据。set是通过hash实现的,所以增删查的时间复杂度都是o(1)。
SADD指令把新的元素添加到 set 中。对 set 也可做一些其他的操作,比如测试一个给定的元素是否存在,对不同 set 取交集,并集或差,等等用法:
192.168.1.167:6379> sadd myset 2 3 1 (integer) 3 192.168.1.167:6379> smembers myset 1) "1" 2) "2" 3) "3" 192.168.1.167:6379> -
有序集合(sorted sets) :有序集合和集合一样是身体溶类型的集合,但不允许有重复元素。每个元素都有一个double类型的分数,redis通过这个分数从小到大进行排序。因为有序集合也通过hash实现,所以增删查的时间复杂度o(1)
用法:
192.168.1.167:6379> zadd mysortedset 1 b (integer) 1 192.168.1.167:6379> zadd mysortedset 2 a (integer) 1 192.168.1.167:6379> zadd mysortedset 3 c (integer) 1 192.168.1.167:6379> zadd mysortedset 2 d (integer) 1 192.168.1.167:6379> zrange mysortedset 0 10 1) "b" 2) "a" 3) "d" 4) "c" 192.168.1.167:6379> -
范围查询bitmaps:通过一个bit来标识元素对应的值
用法:
192.168.1.167:6379> setbit mybit 1 1 (integer) 0 192.168.1.167:6379> setbit mybit 2 1 (integer) 0 192.168.1.167:6379> setbit mybit 3 1 (integer) 0 192.168.1.167:6379> bitcount mybit (integer) 3 192.168.1.167:6379> -
hyperloglogs :HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素
基数既不重复元素的个数
用法:
192.168.1.167:6379> pfadd myhyperloglog a (integer) 1 192.168.1.167:6379> pfadd myhyperloglog b (integer) 1 192.168.1.167:6379> pfadd myhyperloglog c (integer) 1 192.168.1.167:6379> pfadd myhyperloglog c (integer) 0 192.168.1.167:6379> pfcount myhyperloglog (integer) 3 192.168.1.167:6379> -
地理空间(geospatial) :存储地理位置信息
用法:
192.168.1.167:6379> geoadd point1 13.123 38.133 "name1" 13.223 38.333 "name2" (integer) 2 192.168.1.167:6379> geopos point1 name1 name2 1) 1) "13.12299996614456177" 2) "38.13300034651486925" 2) 1) "13.22299808263778687" 2) "38.33299998487134985" 192.168.1.167:6379>














 4555
4555











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









