










之前介绍了光流提升视频识别的速度和精度的文章,这次还是光流在视频检测和分割的应用,不过做的更完善了
Towards High Performance Video Object Detection
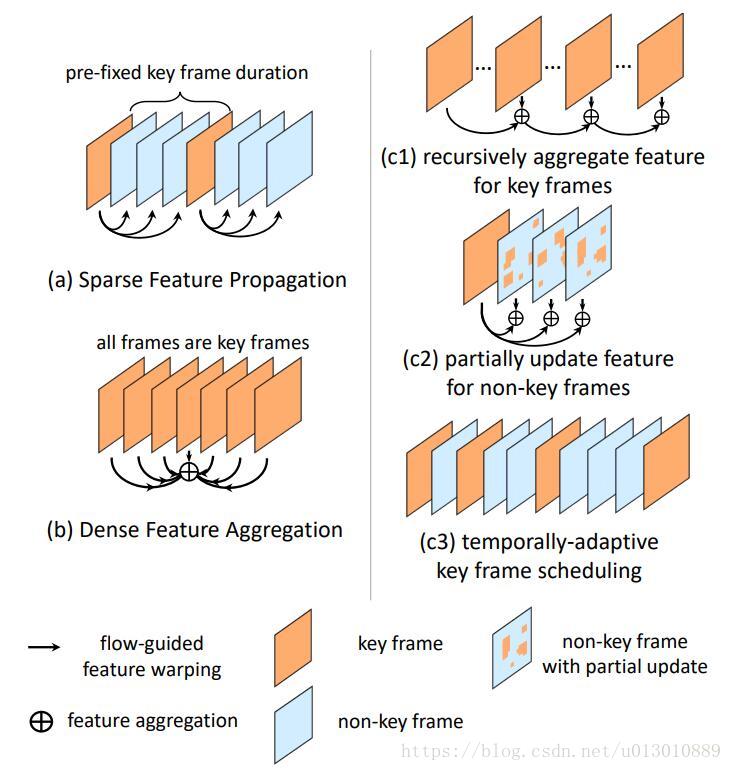
如图所示,较上一篇博客中的两篇文章主要有3个地方改进(详细请看该论文中的Ablation Study部分)
- a 是我上一篇博客介绍的一个是利用光流提升速度,通过光流将关键帧的特征propagation到非关键帧处,节省计算
- b 也是我上一篇博客中介绍的利用光流提升精度的,在对当前帧进行检测时,通过光流将前后几帧的特征warp过来进行特征增强(每一帧都是关键帧)。
- c1 Sparsely Recursive Feature Aggregation,将稀疏的关键帧进行迭代的增强,上一个关键帧增强当前帧,增强后的当前帧又去增强下一个关键帧,注意还有一种做法是分别从前10 前5 前1帧wrap过来融合,但是10和5这种太远了,光流计算误差太大,融合过来有可能帮倒忙,而这种迭代形式每次都只计算相连两帧的光流,较为准确,且保留了之前的历史
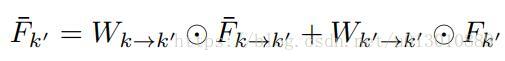
- c2 Spatially-adaptive Partial Feature Updating,出发点是相邻帧有部分区域变化太大,而利用光流propagated过来的feature太容易出错了,所以需要预测一下哪些区域可以很好的propagated,然后能过保持一致的就可以propagate,不可以就要重新算。首先送入关键帧k和非关键帧i,Flow网络计算光流M(motion)和Q(quanlity, 可以理解为光流的质量)。U是一个mask,如果feature上该位置p的Q<=τ,则说明该位置光流不ok,赋值为1,所以需要重新计算feature上该位置的值,反之赋值为0,不用重新计算直接propagate过来。
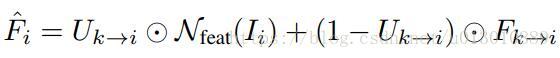
- c3 Temporally-adaptive Key Frame Scheduling 上一篇博客中介绍的关键帧是固定间隔的,但是我们可以调整成动态的。利用c2中计算的每个位置p的Q,计算一下那些光流质量不ok的位置在总共位置数中的比例,大于 γ,就证明当前帧已经和之前变化太大了,需要设置成关键帧重新计算特征了。
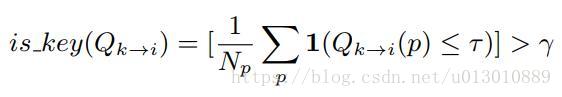
Towards High Performance Video Object Detection for Mobiles
这篇论文主要是在手机上做视频物体检测,最大的区别的手机计算能力较pc低,需要更精简的网络结构设计
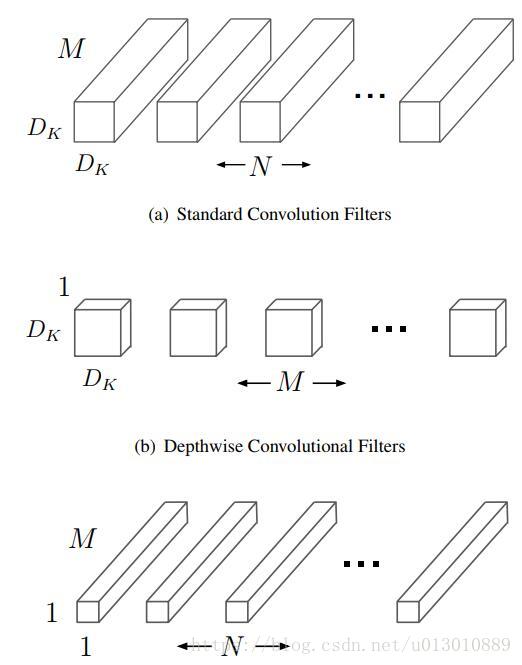
1. Flow方面,之前的光流估计完全不能在手机上实时运行,所以提出了LightFlow,将所有3*3的普通卷积换成MobileNet中的设计(先每个channel单独计算卷积,然后再用1*1的卷积在channel上融合),大大减少了计算量;第二FlowNet中decoder部分需要deconv,这里都用上采样再跟一个depthwise separable conv代替;原版的FlowNet只在最好的resolution上做预测,这里在所有scale上都做为了弥补前面造成的精度损失
2. Feature Aggregation方面,上文采用了迭代的特征增强解决之前那种直接将很远的帧warp过来导致的误差,算是一定程度上解读了long-term的依赖,但是它融合时只是一个线性的无记忆的方式(计算相似度来得到权重),会出现RNN里面出现的梯度弥散或者爆炸,不是很好训练。本文采用了GRU(一种简化的LSTMGRU)来解决long-term的依赖。主要和GRU有几点不同: 1, 将GRU中的计算门时的全连接矩阵相乘换成了卷积主要为了减少计算量提高速度(RNN训练速度问题) 2, 将GRU中的tanh换成了ReLU,更快更容易收敛(这个保留疑问,他实验出来的结果,不知道为什么就比之前的好了),还有就是之前别人都是在连续帧上做LSTM/GRU,但是本文由于只在关键帧上做特征增强,相邻的两个关键帧离得很远,所以不能直接送到GRU,需要先利用光流align一下前一个关键帧的feature,否则偏差太大了,也就是把之前的利用权重融合改成了GRU融合

3. Base Model方面,主体网络结构都改成了MobileNet的形式,RPN部分也是改成了Light RCNN的方式
Low-Latency Video Semantic Segmentation
利用光流加速视频的分割,主要提出了一个概念是延迟,前文都在说整体的时间,但是在某些实际应用中要看最大延迟而不是平均,比如自动驾驶,前文虽然整体时间降低了,但是关键帧依然和之前是一样的,但是本文的解决方案我感觉也很一般啊,就是工程的一个实现。他是先用简单的网络跑一下关键帧,然后后台在跑一个复杂的,等到后台复杂的跑好了来替代前台的。但是本文有个地方还是挺有意思的。
将关键帧帧的特征propagate到当前帧有几个方法
1. 光流,之前的方法都在这样做。但是有个问题就是光流本身是点对点的约束,在图片上还ok,但是在特征空间这样点对点太苛刻了,如果不联合训练直接用初始的光流来做效果是很差的,就是因为在特征空间已经和在原图上的位置关系不一致了,特征空间上的每个点都是一种pattern,是原图上的一片点。联合训练后这个光流其实已经不是我们平时意义上的光流了(原图上的位置变化),是特征上的一种位置变化了(有人做实验是将两个图送到这个‘光流’网络中得到的结果已不是平时意义的光流,待验证)。 ps: 如果单纯为了提高精度,为了更好利用之前光流的权重,和之前的光流含义保持一致,那么在score map上做align,然后增强当前帧的精度。参考我们的论文Surveillance Video Parsing with Single Frame Supervision,不太清楚这两种方式哪个效果好,需要在同等条件下做个实验
2. translation-invariant convolution,卷积都是同一个模板,但是场景中的不同部分有着不同的motion pattern,比如图片中一个人在往前走,另一个在往后走,用同一个卷积核去变换这两种motion不太妥当
3. spatially variant convolution,所以本来就提了一个每个位置都用不同的卷积核去变换,这个每个位置的卷积核如何获得呢?输入当前帧和关键帧,得到Hk*Hk*W*H,每个位置Hk*Hk个channel即Hk*Hk个值作为特征变换时的卷积核
End-to-end Flow Correlation Tracking with Spatial-temporal Attention
利用光流来增强tracking的效果的,之前的思路大致和之前的都差不多,唯一不同的是特征融合的时候。
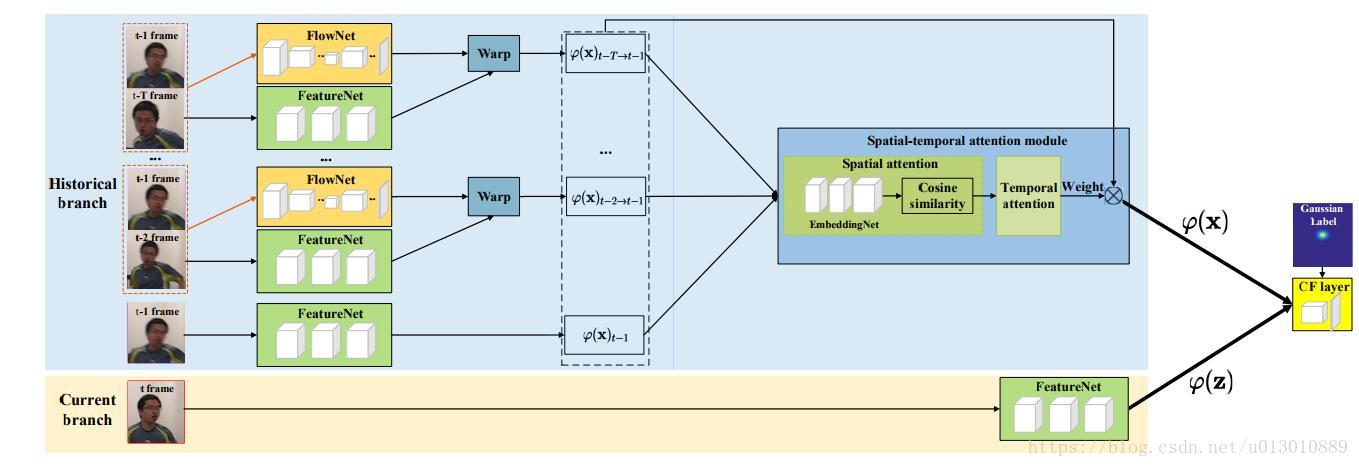
1. spatial attention,和之前一样,计算当前帧和之前各帧每个位置(C*1*1)的相似度,然后分配权重。对于某个位置,各个帧的权重和为1。最后得到T*W*H的权重图(各个channel公用这个权重)
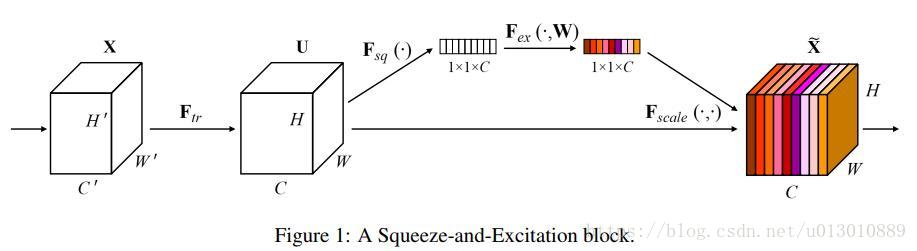
2. temporal attention,然后将上部得到的权重图做global pooling,然后接fc等得到T个权重,相当于给每个时刻赋予了一个整体权重,此处是参考SENet中的做法,只是SENet: Squeeze-and-Excitation Networks是给每个channel重新分配了权重,这里是给每帧重新分配了权重
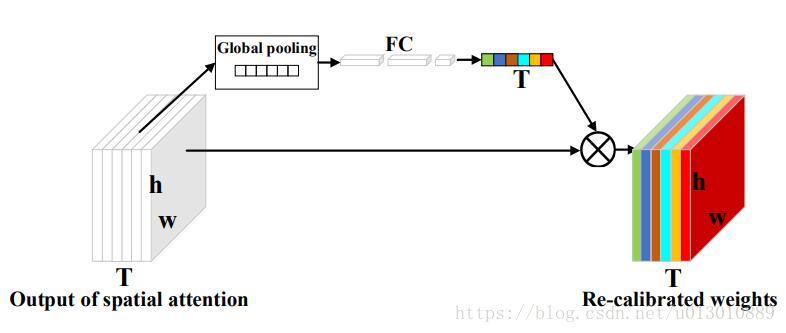
注意,这个融合它分配的权重是数据相关的,不同的数据得到的权重不同(不同的输入得到feature后global后得到的值不同),Attention机制一样也是数据相关的,不同的输入算完相似度权重不同。而我们用1*1卷积融合时,训练结束后权重就固定了,按理说这个1*1如果可以学到合适的参数,分配的权重照样能够适配不同的输入,尽管是固定的,但是这个太难学习到了,和初始化和数据量都有关
这里是个很大很大的启示,不是随便加个1*1就可以达到你理想中的融合,适当的要固定限制一些东西,利于学习到好的融合策略
特别感谢知友的评论给我的启示 Alan Huang的回答即相关评论 如何评价 Squeeze-and-Excitation Networks ?:
你名: 本质上conv 就是干的事就是各通道加权,只不过这个se 是限定每个通道的所有点的权重是一样的,即给了个全通道一样的权重,这样本质上可以用和通道数一样的group 1×1的卷积实现
Alan Huang 回复你名: 区别就是….attention 的weight 是data dependent …conv的权重是训练完之后就固定了


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









