






ObjectLayer 对象存储层
定义了MinIO对象存储服务针对对象操作的所有API,是混合云的重点实现,不同的云存储会有不同的基于 SDK 的实现.
这个接口定义了用于管理对象存储系统的多种操作,实现了对象存储的核心功能。不同的对象存储系统可以通过实现这个接口来提供不同的后端存储支持。
比如 : Google 提供的云存储服务Google Cloud Storage 会通过 GCS的sdk获取实际存储在gcs的桶,包装成 s3标准, 供ObjectLayer的gcs实现包装使用,再提供给 minio 的调用方使用
- ObjectLayer封装的接口,重点在于描述一个ObjectLayer必须提供的动作|操作
- 只要实现了接口函数的结构体都是ObjectLayer
// ObjectLayer implements primitives for object API layer.
type ObjectLayer interface {
// Locking operations on object.
// 对象上的空间锁
NewNSLock(bucket string, objects ...string) RWLocker
// Storage operations. 存储层面的操作
Shutdown(context.Context) error
NSScanner(ctx context.Context, updates chan<- DataUsageInfo, wantCycle uint32, scanMode madmin.HealScanMode) error
BackendInfo() madmin.BackendInfo
StorageInfo(ctx context.Context) StorageInfo
LocalStorageInfo(ctx context.Context) StorageInfo
// Bucket operations.桶操作
// 增删改查 bucket
MakeBucket(ctx context.Context, bucket string, opts MakeBucketOptions) error
GetBucketInfo(ctx context.Context, bucket string, opts BucketOptions) (bucketInfo BucketInfo, err error)
ListBuckets(ctx context.Context, opts BucketOptions) (buckets []BucketInfo, err error)
DeleteBucket(ctx context.Context, bucket string, opts DeleteBucketOptions) error
ListObjects(ctx context.Context, bucket, prefix, marker, delimiter string, maxKeys int) (result ListObjectsInfo, err error)
// 列出存储桶中的对象(版本2)
ListObjectsV2(ctx context.Context, bucket, prefix, continuationToken, delimiter string, maxKeys int, fetchOwner bool, startAfter string) (result ListObjectsV2Info, err error)
ListObjectVersions(ctx context.Context, bucket, prefix, marker, versionMarker, delimiter string, maxKeys int) (result ListObjectVersionsInfo, err error)
// Walk lists all objects including versions, delete markers.
// 对包含的版本对象遍历
Walk(ctx context.Context, bucket, prefix string, results chan<- ObjectInfo, opts ObjectOptions) error
// Object operations.对象操作
// GetObjectNInfo returns a GetObjectReader that satisfies the
// ReadCloser interface. The Close method runs any cleanup
// functions, so it must always be called after reading till EOF
//
// IMPORTANTLY, when implementations return err != nil, this
// function MUST NOT return a non-nil ReadCloser.
// GetObjectNInfo 返回一个满足 ReadCloser 接口的 GetObjectReader
GetObjectNInfo(ctx context.Context, bucket, object string, rs *HTTPRangeSpec, h http.Header, opts ObjectOptions) (reader *GetObjectReader, err error)
GetObjectInfo(ctx context.Context, bucket, object string, opts ObjectOptions) (objInfo ObjectInfo, err error)
PutObject(ctx context.Context, bucket, object string, data *PutObjReader, opts ObjectOptions) (objInfo ObjectInfo, err error)
CopyObject(ctx context.Context, srcBucket, srcObject, destBucket, destObject string, srcInfo ObjectInfo, srcOpts, dstOpts ObjectOptions) (objInfo ObjectInfo, err error)
DeleteObject(ctx context.Context, bucket, object string, opts ObjectOptions) (ObjectInfo, error)
DeleteObjects(ctx context.Context, bucket string, objects []ObjectToDelete, opts ObjectOptions) ([]DeletedObject, []error)
TransitionObject(ctx context.Context, bucket, object string, opts ObjectOptions) error
RestoreTransitionedObject(ctx context.Context, bucket, object string, opts ObjectOptions) error
// Multipart operations. 分段处理操作
// 列出所有分段上传任务
ListMultipartUploads(ctx context.Context, bucket, prefix, keyMarker, uploadIDMarker, delimiter string, maxUploads int) (result ListMultipartsInfo, err error)
// 创建一个新的分段上传任务
NewMultipartUpload(ctx context.Context, bucket, object string, opts ObjectOptions) (result *NewMultipartUploadResult, err error)
// 复制分段上传的部分
CopyObjectPart(ctx context.Context, srcBucket, srcObject, destBucket, destObject string, uploadID string, partID int,
startOffset int64, length int64, srcInfo ObjectInfo, srcOpts, dstOpts ObjectOptions) (info PartInfo, err error)
// 存储分段上传的部分
PutObjectPart(ctx context.Context, bucket, object, uploadID string, partID int, data *PutObjReader, opts ObjectOptions) (info PartInfo, err error)
// 获取分段上传任务的信息
GetMultipartInfo(ctx context.Context, bucket, object, uploadID string, opts ObjectOptions) (info MultipartInfo, err error)
// 列出对象的分段。
ListObjectParts(ctx context.Context, bucket, object, uploadID string, partNumberMarker int, maxParts int, opts ObjectOptions) (result ListPartsInfo, err error)
// 中止分段上传任务
AbortMultipartUpload(ctx context.Context, bucket, object, uploadID string, opts ObjectOptions) error
// 完成分段上传任务
CompleteMultipartUpload(ctx context.Context, bucket, object, uploadID string, uploadedParts []CompletePart, opts ObjectOptions) (objInfo ObjectInfo, err error)
// 获取属于指定池和集合的磁盘
GetDisks(poolIdx, setIdx int) ([]StorageAPI, error) // return the disks belonging to pool and set.
// 获取每个池的纠察码横跨大小列表
SetDriveCounts() []int // list of erasure stripe size for each pool in order.
// Healing operations.
// 格式化存储系统
HealFormat(ctx context.Context, dryRun bool) (madmin.HealResultItem, error)
// 修复存储桶
HealBucket(ctx context.Context, bucket string, opts madmin.HealOpts) (madmin.HealResultItem, error)
// 修复对象
HealObject(ctx context.Context, bucket, object, versionID string, opts madmin.HealOpts) (madmin.HealResultItem, error)
// 修复多个对象
HealObjects(ctx context.Context, bucket, prefix string, opts madmin.HealOpts, fn HealObjectFn) error
// 检查废弃的分段
CheckAbandonedParts(ctx context.Context, bucket, object string, opts madmin.HealOpts) error
// Returns health of the backend
// 返回后端的健康状况
Health(ctx context.Context, opts HealthOptions) HealthResult
ReadHealth(ctx context.Context) bool
// Metadata operations
// 存储对象的元数据
PutObjectMetadata(context.Context, string, string, ObjectOptions) (ObjectInfo, error)
// 解除分层对象
DecomTieredObject(context.Context, string, string, FileInfo, ObjectOptions) error
// ObjectTagging operations
PutObjectTags(context.Context, string, string, string, ObjectOptions) (ObjectInfo, error)
GetObjectTags(context.Context, string, string, ObjectOptions) (*tags.Tags, error)
DeleteObjectTags(context.Context, string, string, ObjectOptions) (ObjectInfo, error)
}
擦除集Erasure Set
擦除集(Erasure Set):是指一组纠察码集合,最大为32个驱动器,纠察码作为一种数据冗余技术相比于多副本以较低的数据冗余度提供足够的数据可靠性。擦除集中包含数据块与校验块,并且随机均匀的分布在各个节点上
- 非通过备分完整副本来达到可靠性实现,如 hdfs
- 丢失的块通过存在的数据集和校验块计算能重新恢复出丢失块的数据, 通过位运算的奇偶校验等复杂的算法实现.
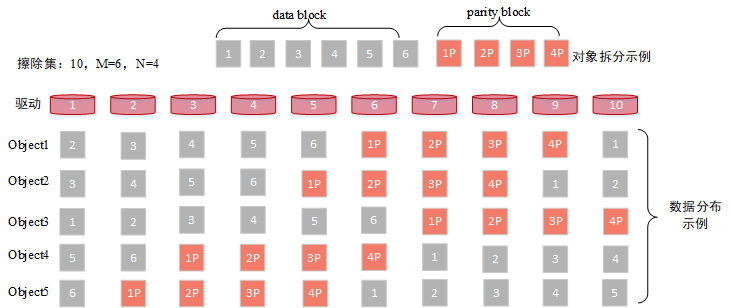
data block: 数据块 parity block: 校验块
10 个 disk driver=> 6 data block + 4 parity block
随即分布在磁盘中
服务池Server Pool
服务器池(Server Pool): 由一组MinIO节点组成一个存储池,池子中的所有节点以相同的命令启动
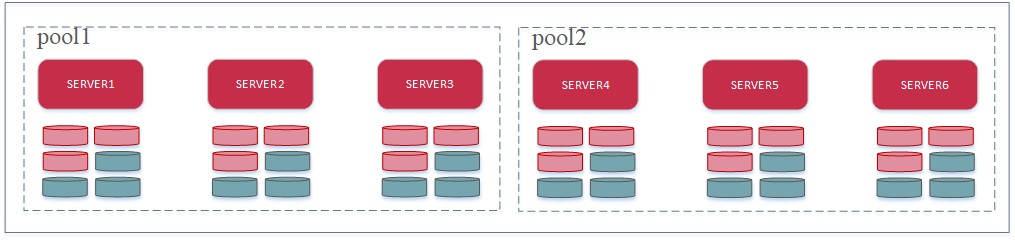
一个pool池子由3个节点和6个驱动disk driver,共18个驱动器组成9+9的擦除集;
池子中可能会包含多个擦除集
Endpoint
在Minio中,端点(endpoints)是用于指定对象存储服务的位置和访问方式的配置元素。Minio支持不同类型的端点,包括URL样式端点(URL-style endpoints)和路径样式端点(path-style endpoints)。
- URL样式端点(URL-style endpoints):这种端点的配置类似于常见的URL,例如:
https://minio.example.com。URL样式端点通常用于在生产环境中使用,支持HTTPS等安全协议。这是Minio推荐的端点配置方式。 - 路径样式端点(path-style endpoints):这种端点的配置类似于文件系统路径,例如:
minio.example.com/bucket/object。路径样式端点通常用于本地开发或测试环境中,也可以用于访问Minio服务
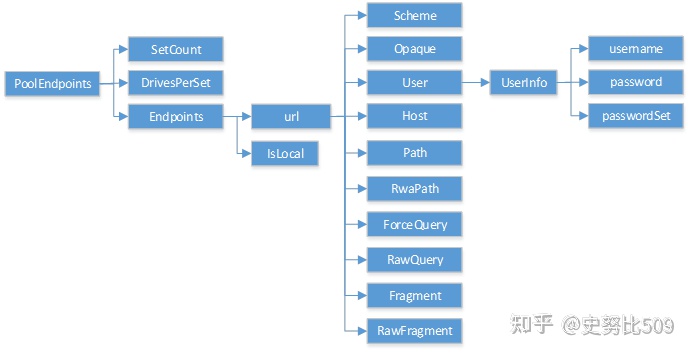
// Endpoint 表示任何类型的端点(Endpoint)。
type Endpoint struct {
// URL 包含端点的 URL 信息,包括协议、主机名、端口和路径等。
*url.URL
// IsLocal 是一个布尔值字段,用于指示端点是否是本地端点。
// 如果 IsLocal 为 true,则表示端点位于本地主机上,否则表示端点是远程的。
IsLocal bool
// PoolIdx 端点池(Pool)索引,指示端点属于哪个池
PoolIdx int
// SetIdx 表示端点所属的 擦除 set集(Set)索引,从Endpoints[idx]获取endpoint结构
SetIdx int
// DiskIdx 表示端点所属的磁盘(Disk)索引.属于哪个磁盘
// 磁盘是数据的物理存储位置。
DiskIdx int
}
// CreateEndpoints - 验证并创建给定参数的新端点。
func CreateEndpoints(serverAddr string, args ...[]string) (Endpoints, SetupType, error) {
var endpoints Endpoints
var setupType SetupType
var err error
// 检查服务器地址是否对此主机有效。
if err = CheckLocalServerAddr(serverAddr); err != nil {
return endpoints, setupType, err
}
_, serverAddrPort := mustSplitHostPort(serverAddr)
// 单点模式
// 对于单个参数,返回单个驱动器设置。
if len(args) == 1 && len(args[0]) == 1 {
var endpoint Endpoint
endpoint, err = NewEndpoint(args[0][0])
if err != nil {
return endpoints, setupType, err
}
// 设置为本地
if err := endpoint.UpdateIsLocal(); err != nil {
return endpoints, setupType, err
}
if endpoint.Type() != PathEndpointType {
return endpoints, setupType, config.ErrInvalidEndpoint(nil).Msg("使用路径样式端点进行单节点设置")
}
// 单点就一个
endpoint.SetPoolIndex(0)
endpoint.SetSetIndex(0)
endpoint.SetDiskIndex(0)
endpoints = append(endpoints, endpoint)
// ErasureSDSetupType 数据存储和冗余配置的类型
setupType = ErasureSDSetupType
// 检查是否存在跨设备挂载。
if err = checkCrossDeviceMounts(endpoints); err != nil {
return endpoints, setupType, config.ErrInvalidEndpoint(nil).Msg(err.Error())
}
return endpoints, setupType, nil
}
// 纠察码模式
// 返回Endpoints 集合
for setIdx, iargs := range args {
// 将参数转换为端点
eps, err := NewEndpoints(iargs...)
...
// 检查是否存在跨设备挂载。
if err = checkCrossDeviceMounts(eps); err != nil {
return endpoints, setupType, config.ErrInvalidErasureEndpoints(nil).Msg(err.Error())
}
for diskIdx := range eps {
eps[diskIdx].SetSetIndex(setIdx)
eps[diskIdx].SetDiskIndex(diskIdx)
}
endpoints = append(endpoints, eps...)
}
...
setupType = DistErasureSetupType
return endpoints, setupType, nil
}
server 命令中初始化newObjectLayer
// Initialize object layer with the supplied disks, objectLayer is nil upon any error.
// 使用提供的磁盘初始化对象层
// endpointServerPools之前通过参数构建的 多个 endpoint终端存储点服务池
func newObjectLayer(ctx context.Context, endpointServerPools EndpointServerPools) (newObject ObjectLayer, err error) {
return newErasureServerPools(ctx, endpointServerPools)
}
erasureServerPools
serverPools: 
serverpool: 
serverpools[i] => erasureSets
// 擦除集|纠察集的 服务池
type erasureServerPools struct {
// poolMeta元数据的读写锁
poolMetaMutex sync.RWMutex
//擦除数据集服务池的元数据
poolMeta poolMeta
// 再平衡元数据
rebalMu sync.RWMutex
rebalMeta *rebalanceMeta
// 部署的唯一标识符
deploymentID [16]byte
// 存储分布式算法
distributionAlgo string
// 擦除集的集合
serverPools []*erasureSets
// Active decommission canceler
// 存储取消函数的切片,用于取消正在进行的存储节点退役操作
decommissionCancelers []context.CancelFunc
// 与其他endpoints连接通信的客户端池
s3Peer *S3PeerSys
}
// Initialize new pool of erasure sets.
// 初始化 erasure sets 纠察集组成的存储池
func newErasureServerPools(ctx context.Context, endpointServerPools EndpointServerPools) (ObjectLayer, error) {
// 定义相关的变量
var (
deploymentID string
distributionAlgo string
commonParityDrives int
err error
formats = make([]*formatErasureV3, len(endpointServerPools))
storageDisks = make([][]StorageAPI, len(endpointServerPools))
z = &erasureServerPools{
serverPools: make([]*erasureSets, len(endpointServerPools)),
s3Peer: NewS3PeerSys(endpointServerPools),
}
)
var localDrives []StorageAPI
// 第一个 endpoint 是不是本地的
local := endpointServerPools.FirstLocal()
for i, ep := range endpointServerPools {
// 遍历纠察集存储池
// If storage class is not set during startup, default values are used
// -- Default for Reduced Redundancy Storage class is, parity = 2
// -- Default for Standard Storage class is, parity = 2 - disks 4, 5
// -- Default for Standard Storage class is, parity = 3 - disks 6, 7
// -- Default for Standard Storage class is, parity = 4 - disks 8 to 16
// 0: 默认奇偶磁盘数量尚未设置
if commonParityDrives == 0 {
// 计算默认奇偶磁盘数量
commonParityDrives, err = ecDrivesNoConfig(ep.DrivesPerSet)
}
// 验证奇偶磁盘数量是否合法
if err = storageclass.ValidateParity(commonParityDrives, ep.DrivesPerSet); err != nil {
return nil, fmt.Errorf("parity validation returned an error: %w <- (%d, %d), for pool(%s)", err, commonParityDrives, ep.DrivesPerSet, humanize.Ordinal(i+1))
}
// 等待格式化
// storageDisks[i]=> 存储磁盘的信息集
// formats[i]=>存储池的格式化信息集 ,包括节点信息、部署ID、分布算法等。
storageDisks[i], formats[i], err = waitForFormatErasure(local, ep.Endpoints, i+1,
ep.SetCount, ep.DrivesPerSet, deploymentID, distributionAlgo)
for _, storageDisk := range storageDisks[i] {
// 根据storageDisk计算当前节点的本地纠察集的 driver
if storageDisk != nil && storageDisk.IsLocal() {
localDrives = append(localDrives, storageDisk)
}
}
// all pools should have same deployment ID
// 设置部署 id
deploymentID = formats[i].ID
// 分布算法
if distributionAlgo == "" {
distributionAlgo = formats[i].Erasure.DistributionAlgo
}
// Validate if users brought different DeploymentID pools.
if deploymentID != formats[i].ID {
// 验证所有存储池是否具有相同的部署ID,确保它们属于同一部署
return nil, fmt.Errorf("all pools must have same deployment ID - expected %s, got %s for pool(%s)", deploymentID, formats[i].ID, humanize.Ordinal(i+1))
}
// 对每个 纠察集存储池 初始化它持有的 纠察集ErasureSet们
z.serverPools[i], err = newErasureSets(ctx, ep, storageDisks[i], formats[i], commonParityDrives, i)
if err != nil {
return nil, err
}
if deploymentID != "" && bytes.Equal(z.deploymentID[:], []byte{}) {
z.deploymentID = uuid.MustParse(deploymentID)
}
if distributionAlgo != "" && z.distributionAlgo == "" {
z.distributionAlgo = distributionAlgo
}
}
z.decommissionCancelers = make([]context.CancelFunc, len(z.serverPools))
// initialize the object layer.
// 全局对象层(Object Layer)为z,以便后续的操作能够访问对象层的功能
setObjectLayer(z)
r := rand.New(rand.NewSource(time.Now().UnixNano()))
for {
// 初始化 all pools 直到成功为止
err := z.Init(ctx) // Initializes all pools.
if err != nil {
if !configRetriableErrors(err) {
logger.Fatal(err, "Unable to initialize backend")
}
retry := time.Duration(r.Float64() * float64(5*time.Second))
logger.LogIf(ctx, fmt.Errorf("Unable to initialize backend: %w, retrying in %s", err, retry))
time.Sleep(retry)
continue
}
break
}
globalLocalDrivesMu.Lock()
// 加锁设置全局本地 derivers 为localDrives
globalLocalDrives = localDrives
defer globalLocalDrivesMu.Unlock()
return z, nil
}
newErasureSets
- 1个纠察集ErasureSet有 N 个磁盘驱动器的dirver
- 每个 driver 操作一个存储介质
// Initialize new set of erasure coded sets.
// 初始化一组纠察集ErasureSet
func newErasureSets(ctx context.Context, endpoints PoolEndpoints, storageDisks []StorageAPI, format *formatErasureV3, defaultParityCount, poolIdx int) (*erasureSets, error) {
// 总量
setCount := len(format.Erasure.Sets)
// deriver 数
setDriveCount := len(format.Erasure.Sets[0])
// endpoint 的字符串集合
endpointStrings := make([]string, len(endpoints.Endpoints))
for i, endpoint := range endpoints.Endpoints {
endpointStrings[i] = endpoint.String()
}
// Initialize the erasure sets instance.
// 声明变量
s := &erasureSets{
sets: make([]*erasureObjects, setCount),
erasureDisks: make([][]StorageAPI, setCount),
erasureLockers: make([][]dsync.NetLocker, setCount),
erasureLockOwner: globalLocalNodeName,// 全局本地节点的锁名
endpoints: endpoints,// 终端存储器集合
endpointStrings: endpointStrings,
setCount: setCount,
setDriveCount: setDriveCount,// 纠察集ErasureSet的驱动器种类
defaultParityCount: defaultParityCount,//默认的奇偶磁盘数量,用于配置纠察码的奇偶校验
format: format,
setReconnectEvent: make(chan int),//重连事件
distributionAlgo: format.Erasure.DistributionAlgo,
deploymentID: uuid.MustParse(format.ID),
poolIndex: poolIdx,
}
// 空间锁
mutex := newNSLock(globalIsDistErasure)
// Number of buffers, max 2GB 缓冲区大小
n := (2 * humanize.GiByte) / (blockSizeV2 * 2)
// Initialize byte pool once for all sets, bpool size is set to
// setCount * setDriveCount with each memory upto blockSizeV2.
// blockSizeV2 一次性字节池=> 直接写入内存,避免 2 次 io
// 新缓冲区
bp := bpool.NewBytePoolCap(n, blockSizeV2, blockSizeV2*2)
// Initialize byte pool for all sets, bpool size is set to
// setCount * setDriveCount with each memory upto blockSizeV1
//
// Number of buffers, max 10GiB
// blockSizeV1 blockSize
m := (10 * humanize.GiByte) / (blockSizeV1 * 2)
// 老缓冲区,可能存储生命周期不一的字节
bpOld := bpool.NewBytePoolCap(m, blockSizeV1, blockSizeV1*2)
for i := 0; i < setCount; i++ {
// 声明 当前纠察集ErasureSet 对应的存储驱动器 's的结构
// 一个纠察集ErasureSet 会有种存储驱动器
s.erasureDisks[i] = make([]StorageAPI, setDriveCount)
}
// 纠察集Erasure's总 的每个 host 的远程网络锁 => [host: lock]
erasureLockers := map[string]dsync.NetLocker{}
// 遍历终端存储器 endpoints
for _, endpoint := range endpoints.Endpoints {
if _, ok := erasureLockers[endpoint.Host]; !ok {
erasureLockers[endpoint.Host] = newLockAPI(endpoint)
}
}
// setcount: 纠察集ErasureSet的 size
for i := 0; i < setCount; i++ {
lockerEpSet := set.NewStringSet()
for j := 0; j < setDriveCount; j++ {
// 找到 当前纠察集ErasureSet的 的 当前驱动器 的 endpoint
endpoint := endpoints.Endpoints[i*setDriveCount+j]
// 每个端点和每个擦除集只能添加一个锁。
// Only add lockers only one per endpoint and per erasure set.
if locker, ok := erasureLockers[endpoint.Host]; ok && !lockerEpSet.Contains(endpoint.Host) {
// 先获取host 远程net锁[host] 再操作
// 对单个Erasure的每个 host 获取一个远程net锁
lockerEpSet.Add(endpoint.Host)
s.erasureLockers[i] = append(s.erasureLockers[i], locker)
}
}
}
// 这些锁用来在后面想要远程对其他 host 进行原子操作时上锁
// 等待一组协程执行完成
var wg sync.WaitGroup
for i := 0; i < setCount; i++ {
wg.Add(1)
// 对每个纠察集ErasureSet开启一个协程任务
go func(i int) {
defer wg.Done()
// 内部的WaitGroup
var innerWg sync.WaitGroup
// 遍历当前纠察集ErasureSet的驱动器
for j := 0; j < setDriveCount; j++ {
// 获取当前驱动操作的存储器 disk
disk := storageDisks[i*setDriveCount+j]
if disk == nil {
continue
}
innerWg.Add(1)
go func(disk StorageAPI, i, j int) {
defer innerWg.Done()
// 初始化存储器 disk
diskID, err := disk.GetDiskID()
if err != nil {
if !errors.Is(err, errUnformattedDisk) {
logger.LogIf(ctx, err)
}
return
}
if diskID == "" {
return
}
m, n, err := findDiskIndexByDiskID(format, diskID)
if err != nil {
logger.LogIf(ctx, err)
return
}
if m != i || n != j {
// 校验报错
logger.LogIf(ctx, fmt.Errorf("Detected unexpected drive ordering refusing to use the drive - poolID: %s, found drive mounted at (set=%s, drive=%s) expected mount at (set=%s, drive=%s): %s(%s)", humanize.Ordinal(poolIdx+1), humanize.Ordinal(m+1), humanize.Ordinal(n+1), humanize.Ordinal(i+1), humanize.Ordinal(j+1), disk, diskID))
s.erasureDisks[i][j] = &unrecognizedDisk{storage: disk}
return
}
// 反向设置 disk 持有当前 纠察集存储池的 index,是第几个纠察集,第几个 driver
disk.SetDiskLoc(s.poolIndex, m, n)
// 设置endpointStrings,erasureDisks对应的 disk 信息
s.endpointStrings[m*setDriveCount+n] = disk.String()
s.erasureDisks[m][n] = disk
}(disk, i, j)
}
// 直到所有并发任务结束
innerWg.Wait()
// Initialize erasure objects for a given set.
// 初始化纠察集对象的数组中 => 当前的 纠察集对象
s.sets[i] = &erasureObjects{
setIndex: i,
poolIndex: poolIdx,
setDriveCount: setDriveCount,
defaultParityCount: defaultParityCount,// 校验块数
getDisks: s.GetDisks(i),//磁盘disk数组
getLockers: s.GetLockers(i),
getEndpoints: s.GetEndpoints(i),// 终端存储器数组
nsMutex: mutex,// 空间锁
bp: bp,// 新线程池
bpOld: bpOld,// 老线程池
}
}(i)
}
wg.Wait()
// start cleanup stale uploads go-routine.
// 清理过期上传的协程
go s.cleanupStaleUploads(ctx)
// start cleanup of deleted objects.
// 清理已删除对象的协程
go s.cleanupDeletedObjects(ctx)
// Start the disk monitoring and connect routine.
// 非测试环境: //启动硬盘监控并连接协程
if !globalIsTesting {
go s.monitorAndConnectEndpoints(ctx, defaultMonitorConnectEndpointInterval)
}
return s, nil
}
核心流程
数据上传
数据是如何上传到ObjectLayer
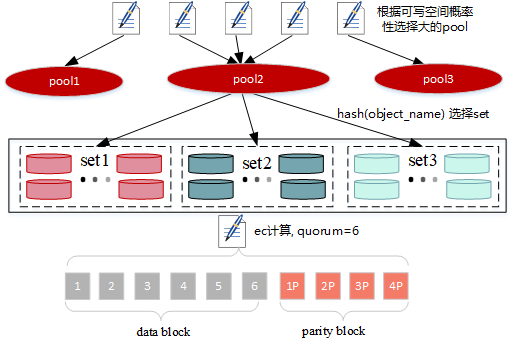
选择pool => 选择set => 上传 => 数据写入=> 元数据写入
选择pool
- pool只有一个,直接返回
- pool有多个,这里分两步:
- 第一步会去查询之前是否存在此数据(bucket+object),如果存在,则返回对应的pool,如果不存在则进入下一步;
- 第二步根据object 哈希计算落在每个pool的set单元,然后根据每个pool对应set的可用容量进行选择,会高概率选择上可用容量大的pool
// PutObject - 将对象写入最不常用的纠察码池中。
func (z *erasureServerPools) PutObject(ctx context.Context, bucket string, object string, data *PutObjReader, opts ObjectOptions) (ObjectInfo, error) {
// 验证放置对象的输入参数。
if err := checkPutObjectArgs(ctx, bucket, object, z); err != nil {
return ObjectInfo{}, err
}
// 对目录对象名称进行编码。
object = encodeDirObject(object)
// 如果只有一个纠察集池,则绕过进一步检查并直接写入。
if z.SinglePool() {
// 如果 bucket 不是 MinIO 的元数据存储桶
if !isMinioMetaBucketName(bucket) {
// 检查磁盘是否有足够的空间来容纳数据。
avail, err := hasSpaceFor(getDiskInfos(ctx, z.serverPools[0].getHashedSet(object).getDisks()...), data.Size())
if err != nil {
// 纠察集写入的投票错误
logger.LogOnceIf(ctx, err, "erasure-write-quorum")
return ObjectInfo{}, toObjectErr(errErasureWriteQuorum)
}
// // 没有足够的空间
if !avail {
return ObjectInfo{}, toObjectErr(errDiskFull)
}
}
// 将对象写入单个池
return z.serverPools[0].PutObject(ctx, bucket, object, data, opts)
}
// 如果不是单一池,且未禁用锁定(opts.NoLock 为 false),则获取一个命名空间锁。
if !opts.NoLock {
// 对 bucket 设置一个空间锁
ns := z.NewNSLock(bucket, object)
// 获取锁
lkctx, err := ns.GetLock(ctx, globalOperationTimeout)
if err != nil {
return ObjectInfo{}, err
}
ctx = lkctx.Context()
defer ns.Unlock(lkctx)
// 切换opts锁状态
opts.NoLock = true
}
// 获取应该写入对象的池的索引,选择具有最少已使用磁盘的池,以确保均衡写入。
// 是否存在此数据(bucket+object): 高概率选择上可用容量大的pool
idx, err := z.getPoolIdxNoLock(ctx, bucket, object, data.Size())
if err != nil {
return ObjectInfo{}, err
}
// idx: 已存在对象的 pool 的 idx 或者是分配到的 pool 的 idx
// 对象=> 覆盖 或 插入
return z.serverPools[idx].PutObject(ctx, bucket, object, data, opts)
}
选择纠察集 erasure set
其实在选择pool的时候已经计算过一次对应object会落在那个set中,这里会有两种哈希算法:
- crcHash,计算对象名对应的crc值 % set大小
- sipHash,计算对象名、deploymentID哈希得到 % set大小,当前版本默认为该算法
// PutObject - writes an object to hashedSet based on the object name.
func (s *erasureSets) PutObject(ctx context.Context, bucket string, object string, data *PutObjReader, opts ObjectOptions) (objInfo ObjectInfo, err error) {
set := s.getHashedSet(object)
return set.PutObject(ctx, bucket, object, data, opts)
}
上传数据
确定数据块、校验块个数及写入Quorum

-
根据用户配置的
x-amz-storage-class值确定校验块个数parityDrives-
RRS,集群初始化时如果有设置
MINIO_STORAGE_CLASS_RRS则返回对应的校验块数,否则为2 -
其他情况,如果设置了
MINIO_STORAGE_CLASS_STANDARD则返回对应的校验块数,否则返回默认值 -
Erasure Set Size Default Parity (EC:N) 5 or fewer EC:2 6-7 EC:3 8 or more EC:4
-
-
parityDrives+=统计set中掉线或者不存在的磁盘数,如果parityDrives大于set磁盘数的一半,则设置校验块个数为set的磁盘半数,也就是说校验块的个数是不定的 -
dataDrives:=set中drives个数-partyDrives -
writeQuorum := dataDrives,如果数据块与校验块的个数相等,则writeQuorum++
写入流程
-
重排set中磁盘,根据对象的key进行crc32哈希得到分布关系
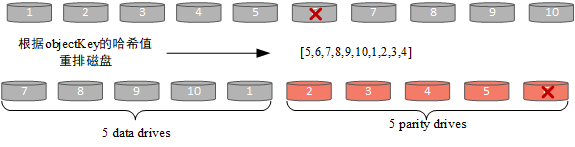
-
根据对象大小确定ec计算的buffer大小,最大为1M,即一个blockSize大小
-
ec构建数据块与校验块,即上面提到的buffer大小
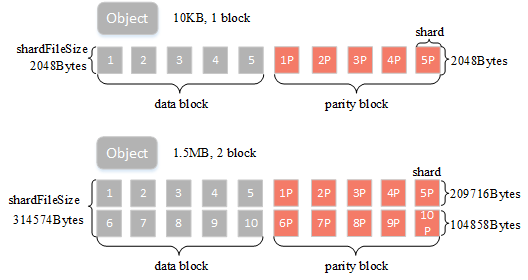
BlockSize:表示纠删码计算的数据块大小,可以简单理解有1M的用户数据则会根据纠删码规则计算得到数据块+校验块ShardSize:纠删码块的实际shard大小,比如blockSize=1M,数据块个数dataBlocks为5,那么单个shard大小为209716字节(blockSize/dataBlocks向上取整),是指ec的每个数据小块大小ShardFileSize:最终纠删码数据shard大小,比如blockSize=1M,数据块个数dataBlocks为5,用户上传一个5M的对象,那么这里会将其分五次进行纠删码计算,最终得到的单个shard的实际文件大小为5*shardSize
-
写入数据到对应节点,根据shardFileSize的大小会有不同的策略
-
小文件:以上图为例,假定对象大小为10KB,blockSize=1M,data block与parity block个数均为5,则shardFileSize=2048Bytes,满足小文件的条件,小文件的数据会存在元数据中,后面会详细介绍:
- 桶为开启多版本且shardFileSize小于128K;
- 或者shardFileSize大小小于16K。
-
大文件:如图所示,假定object大小为1.5MB,blockSize=1M,data block与parity block个数均为5,磁盘中对应文件则会分成两个block,每满1M数据会进行一次ec计算并写入数据,最后一个block大小为0.5MB,shardFileSize为209716+104858=314574(详细计算方法见附录
shardFileSize计算)。 -
数据在写入时会有数据bit位保护机制,可以有效检查出磁盘静默或者比特位衰减等问题,保证读取到的数据一定是正确的,比特位保护有两种策略:
-
streaming-bitrot,这种模式每个block会计算一个哈希值并写入到对应的数据文件中;
-
whole-bitrot,这种模式下是针对driver中的一个文件进行计算的,比如上面3小结中的图所示,针对block1+block6计算一个哈希值并将其写入到元数据中。可以看到第二种方式的保护粒度要粗一些,当前默认采用了第一种策略。

-
-
对于小于128K的文件走普通IO;大文件则是采用directIO,这里根据文件大小确定写入buffer,64M以上的数据,buffer为4M;其他大文件为2M,如果是4K对齐的数据,则会走drectIO,否则普通io(数据均会调用fdatasync落盘,
cmd/xl-storage.go中的CreteFile方法)
-
// PutObject - writes an object to hashedSet based on the object name.
func (s *erasureSets) PutObject(ctx context.Context, bucket string, object string, data *PutObjReader, opts ObjectOptions) (objInfo ObjectInfo, err error) {
set := s.getHashedSet(object)
return set.PutObject(ctx, bucket, object, data, opts)
}
// Returns always a same erasure coded set for a given input.
func (s *erasureSets) getHashedSet(input string) (set *erasureObjects) {
return s.sets[s.getHashedSetIndex(input)]
}
// putObject wrapper for erasureObjects PutObject
// object 对象名
// PutObjReader 对象的读入流
// objInfo:返回的对象的信息
func (er erasureObjects) putObject(ctx context.Context, bucket string, object string, r *PutObjReader, opts ObjectOptions) (objInfo ObjectInfo, err error) {
// 审计功能: 把操作系统输出到日志中
auditObjectErasureSet(ctx, object, &er)
// 读入数据
data := r.Reader
// 如果提供了条件检查函数(opts.CheckPrecondFn),则执行条件检查。
if opts.CheckPrecondFn != nil {
if !opts.NoLock {
// 没锁就获取一个该 object 的空间锁
ns := er.NewNSLock(bucket, object)
lkctx, err := ns.GetLock(ctx, globalOperationTimeout)
if err != nil {
return ObjectInfo{}, err
}
ctx = lkctx.Context()
defer ns.Unlock(lkctx)
opts.NoLock = true
}
// 获取对象的信息,以便执行条件检查。
// ObjectInfo[bucket,name,..., DataBlocks, ParityBlocks]
obj, err := er.getObjectInfo(ctx, bucket, object, opts)
if err == nil && opts.CheckPrecondFn(obj) {
return objInfo, PreConditionFailed{}
}
if err != nil && !isErrVersionNotFound(err) && !isErrObjectNotFound(err) && !isErrReadQuorum(err) {
return objInfo, err
}
}
// Validate input data size and it can never be less than -1.
// 验证输入数据大小,不能小于 -1
if data.Size() < -1 {
logger.LogIf(ctx, errInvalidArgument, logger.Application)
return ObjectInfo{}, toObjectErr(errInvalidArgument)
}
// 复制用户定义的元数据。
userDefined := cloneMSS(opts.UserDefined)
// 获取 erasure set 的存储磁盘。
storageDisks := er.getDisks()
// 计算 校验块 的数量
parityDrives := len(storageDisks) / 2
// 用户没有设置最大的校验块数
if !opts.MaxParity {
// 根据存储类AmzStorageClass 获取奇偶校验和数据磁盘数量parityDrives
parityDrives = globalStorageClass.GetParityForSC(userDefined[xhttp.AmzStorageClass])
if parityDrives < 0 {
// 有问题设置为默认值
parityDrives = er.defaultParityCount
}
// 如果有离线磁盘,增加此对象的parityDrives
parityOrig := parityDrives
// 创建 原子变量
atomicParityDrives := uatomic.NewInt64(0)
// 计算离线 drivers
atomicOfflineDrives := uatomic.NewInt64(0)
atomicParityDrives.Store(int64(parityDrives))
var wg sync.WaitGroup
for _, disk := range storageDisks {
// 遍历 存储disk
if disk == nil {
// 为空
// 增加ParityDrives和离线磁盘数量
atomicParityDrives.Inc()
atomicOfflineDrives.Inc()
continue
}
if !disk.IsOnline() {
// disk 掉线 不可用
atomicParityDrives.Inc()
atomicOfflineDrives.Inc()
continue
}
wg.Add(1)
go func(disk StorageAPI) {
defer wg.Done()
di, err := disk.DiskInfo(ctx, false)
if err != nil || di.ID == "" {
//检查是否有别的问题
atomicOfflineDrives.Inc()
atomicParityDrives.Inc()
}
}(disk)
}
wg.Wait()
// 如果离线磁盘数量超过磁盘总数的一半,无法满足写入要求,返回 errErasureWriteQuorum 错误
if int(atomicOfflineDrives.Load()) >= (len(storageDisks)+1)/2 {
return ObjectInfo{}, toObjectErr(errErasureWriteQuorum, bucket, object)
}
// 根据计算结果更新纠删码数量
parityDrives = int(atomicParityDrives.Load())
if parityDrives >= len(storageDisks)/2 {
// 超过了存储 disk 的一般,只最多只能用存储 disk 的一半
parityDrives = len(storageDisks) / 2
}
// 如果更新了纠删码数量,将此信息记录在用户定义的元数据中
if parityOrig != parityDrives {
userDefined[minIOErasureUpgraded] = strconv.Itoa(parityOrig) + "->" + strconv.Itoa(parityDrives)
}
}
// 计算数据块 => 总的存储块 - 用于校验的块
dataDrives := len(storageDisks) - parityDrives
// we now know the number of blocks this object needs for data and parity.
// writeQuorum is dataBlocks + 1
writeQuorum := dataDrives
if dataDrives == parityDrives {
// 必须保证 data 块多于校验块一块
writeQuorum++
}
// Initialize parts metadata
// 初始化 块元数据 数组
partsMetadata := make([]FileInfo, len(storageDisks))
// 文件块 信息
fi := newFileInfo(pathJoin(bucket, object), dataDrives, parityDrives)
fi.VersionID = opts.VersionID
if opts.Versioned && fi.VersionID == "" {
fi.VersionID = mustGetUUID()
}
// 数据 dir 编号
fi.DataDir = mustGetUUID()
// 校验和
fi.Checksum = opts.WantChecksum.AppendTo(nil, nil)
if opts.EncryptFn != nil {
fi.Checksum = opts.EncryptFn("object-checksum", fi.Checksum)
}
// 唯一 id
uniqueID := mustGetUUID()
tempObj := uniqueID
// Initialize erasure metadata.
// partsMetadata数组 都 指向同一个 FileInfo
for index := range partsMetadata {
partsMetadata[index] = fi
}
// Order disks according to erasure distribution
// 根据erasure分布对可用磁盘进行排序
var onlineDisks []StorageAPI
// 重排set中磁盘,根据对象的key进行crc32哈希得到分布关系
onlineDisks, partsMetadata = shuffleDisksAndPartsMetadata(storageDisks, partsMetadata, fi)
// 创建纠删码编解码器
erasure, err := NewErasure(ctx, fi.Erasure.DataBlocks, fi.Erasure.ParityBlocks, fi.Erasure.BlockSize)
if err != nil {
return ObjectInfo{}, toObjectErr(err, bucket, object)
}
// Fetch buffer for I/O, returns from the pool if not allocates a new one and returns.
// 获取用于 I/O 操作的缓冲区,如果没有则从池中获取,如果没有则分配一个新的缓冲区
// 根据对象大小确定ec计算的buffer大小,最大为1M,即一个blockSize大小
var buffer []byte
switch size := data.Size(); {
case size == 0:
buffer = make([]byte, 1) // 至少分配一个字节以达到 EOF
case size >= fi.Erasure.BlockSize || size == -1:
// 大于 fi.Erasure.BlockSize
// 从er.bp.Get()线程池获取缓冲区
buffer = er.bp.Get()
defer er.bp.Put(buffer)
case size < fi.Erasure.BlockSize:
// No need to allocate fully blockSizeV1 buffer if the incoming data is smaller.
// 如果传入数据较小,无需分配完整的 blockSizeV1 缓冲区
// 直接分配一个 byte 数组
buffer = make([]byte, size, 2*size+int64(fi.Erasure.ParityBlocks+fi.Erasure.DataBlocks-1))
}
if len(buffer) > int(fi.Erasure.BlockSize) {
// 截断多余 buffer 部分
buffer = buffer[:fi.Erasure.BlockSize]
}
// 设置块名字
partName := "part.1"
// fi.DataDir: 存储对象统一的uuid,作为文件夹名
// tempErasureObj: 临时纠察集对象
tempErasureObj := pathJoin(uniqueID, fi.DataDir, partName)
// 清楚 临时的minioMetaTmpBucket
defer er.deleteAll(context.Background(), minioMetaTmpBucket, tempObj)
// 计算分片文件大小
shardFileSize := erasure.ShardFileSize(data.Size())
// 创建写入器切片
writers := make([]io.Writer, len(onlineDisks))
// 创建内联缓冲区切片
var inlineBuffers []*bytes.Buffer
if shardFileSize >= 0 {
if !opts.Versioned && shardFileSize < smallFileThreshold {
inlineBuffers = make([]*bytes.Buffer, len(onlineDisks))
} else if shardFileSize < smallFileThreshold/8 {
inlineBuffers = make([]*bytes.Buffer, len(onlineDisks))
}
} else {
// 如果数据已经压缩,则使用实际大小来确定
if sz := erasure.ShardFileSize(data.ActualSize()); sz > 0 {
if !opts.Versioned && sz < smallFileThreshold {
inlineBuffers = make([]*bytes.Buffer, len(onlineDisks))
} else if sz < smallFileThreshold/8 {
inlineBuffers = make([]*bytes.Buffer, len(onlineDisks))
}
}
}
for i, disk := range onlineDisks {
if disk == nil {
continue
}
if !disk.IsOnline() {
continue
}
if len(inlineBuffers) > 0 {
// 分片大小
sz := shardFileSize
if sz < 0 {
sz = data.ActualSize()
}
//设置分片的 buffer
inlineBuffers[i] = bytes.NewBuffer(make([]byte, 0, sz))
// 流式写入器: 构造 每个分片的写入器
// 在内存中缓冲数据,然后将其写入到目标存储介质
// 直写
writers[i] = newStreamingBitrotWriterBuffer(inlineBuffers[i], DefaultBitrotAlgorithm, erasure.ShardSize())
continue
}
// 小文件的数据会存在元数据中 => minioMetaTmpBucket
// 普通 io
writers[i] = newBitrotWriter(disk, minioMetaTmpBucket, tempErasureObj, shardFileSize, DefaultBitrotAlgorithm, erasure.ShardSize())
}
// io 读对象=> toEncode
toEncode := io.Reader(data)
if data.Size() > bigFileThreshold {
// 使用2个缓冲区,以便始终有一个完整的输入缓冲区
// We use 2 buffers, so we always have a full buffer of input.
bufA := er.bp.Get()
bufB := er.bp.Get()
defer er.bp.Put(bufA)
defer er.bp.Put(bufB)
ra, err := readahead.NewReaderBuffer(data, [][]byte{bufA[:fi.Erasure.BlockSize], bufB[:fi.Erasure.BlockSize]})
if err == nil {
// 读取大的完整对象
toEncode = ra
defer ra.Close()
}
logger.LogIf(ctx, err)
}
// 对读取器的数据toEncode进行编码,对数据进行 擦除集编码 并写入 写入器writers。
n, erasureErr := erasure.Encode(ctx, toEncode, writers, buffer, writeQuorum)
// 关闭writers写入器
closeBitrotWriters(writers)
if erasureErr != nil {
return ObjectInfo{}, toObjectErr(erasureErr, minioMetaTmpBucket, tempErasureObj)
}
// 如果读取的字节数小于请求头中指定的字节数,则返回 IncompleteBody 错误
if n < data.Size() {
return ObjectInfo{}, IncompleteBody{Bucket: bucket, Object: object}
}
var compIndex []byte
if opts.IndexCB != nil {
compIndex = opts.IndexCB()
}
if !opts.NoLock {
lk := er.NewNSLock(bucket, object)
lkctx, err := lk.GetLock(ctx, globalOperationTimeout)
if err != nil {
return ObjectInfo{}, err
}
ctx = lkctx.Context()
defer lk.Unlock(lkctx)
}
modTime := opts.MTime
if opts.MTime.IsZero() {
modTime = UTCNow()
}
for i, w := range writers {
if w == nil {
onlineDisks[i] = nil
continue
}
if len(inlineBuffers) > 0 && inlineBuffers[i] != nil {
partsMetadata[i].Data = inlineBuffers[i].Bytes()
} else {
partsMetadata[i].Data = nil
}
// 无需在分片上添加校验和,对象已包含校验和
partsMetadata[i].AddObjectPart(1, "", n, data.ActualSize(), modTime, compIndex, nil)
partsMetadata[i].Versioned = opts.Versioned || opts.VersionSuspended
}
userDefined["etag"] = r.MD5CurrentHexString()
kind, _ := crypto.IsEncrypted(userDefined)
if opts.PreserveETag != "" {
if !opts.ReplicationRequest {
userDefined["etag"] = opts.PreserveETag
} else if kind != crypto.S3 {
// 如果是复制请求并且指定了 SSE-S3,则不保留传入的 ETag
userDefined["etag"] = opts.PreserveETag
}
}
// 如果未指定 content-type,则尝试从文件扩展名猜测内容类型
if userDefined["content-type"] == "" {
userDefined["content-type"] = mimedb.TypeByExtension(path.Ext(object))
}
// 填充所有必要的元数据,更新每个磁盘上的 `xl.meta` 内容
for index := range partsMetadata {
partsMetadata[index].Metadata = userDefined
partsMetadata[index].Size = n
partsMetadata[index].ModTime = modTime
}
if len(inlineBuffers) > 0 {
// 当数据内联时设置额外的标头
for index := range partsMetadata {
partsMetadata[index].SetInlineData()
}
}
// 将成功写入的临时对象重命名为最终位置
onlineDisks, versionsDisparity, err := renameData(ctx, onlineDisks, minioMetaTmpBucket, tempObj, partsMetadata, bucket, object, writeQuorum)
if err != nil {
if errors.Is(err, errFileNotFound) {
return ObjectInfo{}, toObjectErr(errErasureWriteQuorum, bucket, object)
}
logger.LogOnceIf(ctx, err, "erasure-object-rename-"+bucket+"-"+object)
return ObjectInfo{}, toObjectErr(err, bucket, object)
}
for i := 0; i < len(onlineDisks); i++ {
if onlineDisks[i] != nil && onlineDisks[i].IsOnline() {
// 所有磁盘中的对象信息相同,因此我们可以从在线磁盘中选择第一个元数据
fi = partsMetadata[i]
break
}
}
// 对于速度测试对象,不尝试修复它们
if !opts.Speedtest {
// 无论初始还是在上传过程中,如果磁盘离线,都将其添加到 MRF 列表
for i := 0; i < len(onlineDisks); i++ {
if onlineDisks[i] != nil && onlineDisks[i].IsOnline() {
continue
}
er.addPartial(bucket, object, fi.VersionID)
break
}
if versionsDisparity {
// 如果版本不一致,则将对象添加到 MRF 列表
globalMRFState.addPartialOp(partialOperation{
bucket: bucket,
object: object,
queued: time.Now(),
allVersions: true,
setIndex: er.setIndex,
poolIndex: er.poolIndex,
})
}
}
// 设置对象信息,标记为最新版本
fi.ReplicationState = opts.PutReplicationState()
fi.IsLatest = true
return fi.ToObjectInfo(bucket, object, opts.Versioned || opts.VersionSuspended), nil
元数据写入
元数据主要包含以下内容(详细定义见附录对象元数据信息)
- Volume:桶名
- Name:文件名
- VersionID:版本号
- Erasure:对象的ec信息,包括ec算法,数据块个数,校验块个数,block大小、数据分布状态、以及校验值(whole-bitrot方式的校验值存在这里)
- DataDir:对象存储目录,UUID
- Data:用于存储小对象数据
- Parts:分片信息,包含分片号,etag,大小以及实际大小信息,根据分片号排序
- Metadata:用户定义的元数据,如果是小文件则会添加一条
x-minio-internal-inline-data: true元数据 - Size:数据存储大小,会大于等于真实数据大小
- ModTime:数据更新时间
{
"volume":"lemon",
"name":"temp.2M",
"data_dir":"8366601f-8d64-40e8-90ac-121864c79a45",
"mod_time":"2021-08-12T01:46:45.320343158Z",
"size":2097152,
"metadata":{
"content-type":"application/octet-stream",
"etag":"b2d1236c286a3c0704224fe4105eca49"
},
"parts":[
{
"number":1,
"size":2097152,
"actualSize":2097152
}
],
"erasure":{
"algorithm":"reedsolomon",
"data":2,
"parity":2,
"blockSize":1048576,
"index":4,
"distribution":[
4,
1,
2,
3
],
"checksum":[
{
"PartNumber":1,
"Algorithm":3,
"Hash":""
}
]
},
...
}
数据在机器的组织结构
.
├── GitKrakenSetup.exe #文件名
│ ├── 449e2259-fb0d-48db-97ed-0d71416c33a3 #datadir,存放数据,分片上传的话会有多个part
│ │ ├── part.1
│ │ ├── part.2
│ │ ├── part.3
│ │ ├── part.4
│ │ ├── part.5
│ │ ├── part.6
│ │ ├── part.7
│ │ └── part.8
│ └── xl.meta #存放对象的元数据信息
├── java_error_in_GOLAND_28748.log #可以看到这个文件没有datadir,因为其为小文件将数据存放到了xl.meta中
│ └── xl.meta
├── temp.1M
│ ├── bc58f35c-d62e-42e8-bd79-8e4a404f61d8
│ │ └── part.1
│ └── xl.meta
├── tmp.8M
│ ├── 1eca8474-2739-4316-9307-12fac3a3ccd9
│ │ └── part.1
│ └── xl.meta
└── worker.conf
└── xl.meta














 227
227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









