






数据下载
选择pool
- 单pool直接请求对应pool
- 多个pool
- 向所有pool发起对象查询请求,并对结果根据文件修改时间降序排列,如果时间相同则pool索引小的在前
- 遍历结果,获取正常对象所在的pool信息(对应pool获取对象信息没有失败)
选择set
与上传对象类似,对对象名进行哈希得到具体存储的set
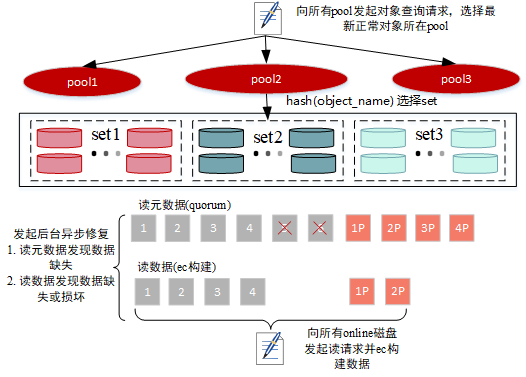
读元信息
- 向所有节点发起元数据读取请求,如果失败节点超过一半,则返回读失败
- 根据元数据信息确定对象读取readQuorum(datablocks大小,即数据块个数)
- 根据第一步返回的错误信息判断元数据是否满足quorum机制,如果不满足则会判断是否为垃圾数据,针对垃圾数据执行数据删除操作
- 如果满足quorum,则会校验第一步读到的元数据信息正确性,如果满足quorum机制,则读取元信息成功
- 如果第一步返回的信息中有磁盘掉线信息,则不会发起数据修复流程,直接返回元数据信息
- 判断对象是否有缺失的block,如果有则后台异步发起修复(文件缺失修复)
读数据
- 根据数据分布对disk进行排序
- 读取数据并进行ec重建
- 如果读取到期望数据大小但读取过程中发现有数据缺失或损坏,则会后台异步发起修复,不影响数据的正常读取
- 文件缺失:修复类型为
HealNormalScan - 数据损坏:修复类型为
HealDeepScan
- 文件缺失:修复类型为
GetObjectNInfo
func (z *erasureServerPools) GetObjectNInfo(ctx context.Context, bucket, object string, rs *HTTPRangeSpec, h http.Header, opts ObjectOptions) (gr *GetObjectReader, err error) {
// 单个SinglePool
object = encodeDirObject(object)
if z.SinglePool() {
return z.serverPools[0].GetObjectNInfo(ctx, bucket, object, rs, h, opts)
}
....
// 加读锁
lock := z.NewNSLock(bucket, object)
lkctx, err := lock.GetRLock(ctx, globalOperationTimeout)
// 获取最新的objInfo, zIdx
objInfo, zIdx, err := z.getLatestObjectInfoWithIdx(ctx, bucket, object, opts)
...
// 错误返回objInfo
return &GetObjectReader{
ObjInfo: objInfo,
}, toObjectErr(errFileNotFound, bucket, object)
// 去指定的 pool 获取对象 info
gr, err = z.serverPools[zIdx].GetObjectNInfo(ctx, bucket, object, rs, h, opts)
return gr, nil
}
// GetObjectNInfo - returns object info and locked object ReadCloser
func (s *erasureSets) GetObjectNInfo(ctx context.Context, bucket, object string, rs *HTTPRangeSpec, h http.Header, opts ObjectOptions) (gr *GetObjectReader, err error) {
set := s.getHashedSet(object)
return set.GetObjectNInfo(ctx, bucket, object, rs, h, opts)
}
// GetObjectNInfo - 返回对象信息和对象的读取器(Closer)。当 err != nil 时,返回的读取器始终为 nil。
func (er erasureObjects) GetObjectNInfo(ctx context.Context, bucket, object string, rs *HTTPRangeSpec, h http.Header, opts ObjectOptions) (gr *GetObjectReader, err error) {
// 跟踪对象的Erasure Set,用于审计。
auditObjectErasureSet(ctx, object, &er)
// 这是一个特殊的调用,首先尝试检查SOS-API调用。
gr, err = veeamSOSAPIGetObject(ctx, bucket, object, rs, opts)
...
// 获取锁
lock := er.NewNSLock(bucket, object)
lkctx, err := lock.GetRLock(ctx, globalOperationTimeout)
...
// 在元数据验证完毕且读取器准备好读取时释放锁。
//
// 这是可能的,因为:
// - 对于内联对象,xl.meta 已经将数据读取到内存中,随后对 xl.meta 的任何变异都对总体读取操作无关紧要。
// - xl.meta 元数据仍在锁()下验证冗余,但是写入响应不需要串行化并发写入者。
unlockOnDefer = true
nsUnlocker = func() { lock.RUnlock(lkctx) }
...
// 获取对象的文件信息、元数据数组和在线磁盘,如果出现错误则返回对象错误。
fi, metaArr, onlineDisks, err := er.getObjectFileInfo(ctx, bucket, object, opts, true)
// 如果数据分片不固定,则获取数据分片的磁盘修改时间,并检查是否需要将某些磁盘标记为离线。
if !fi.DataShardFixed() {
diskMTime := pickValidDiskTimeWithQuorum(metaArr, fi.Erasure.DataBlocks)
if !diskMTime.Equal(timeSentinel) && !diskMTime.IsZero() {
for index := range onlineDisks {
if onlineDisks[index] == OfflineDisk {
continue
}
if !metaArr[index].IsValid() {
continue
}
if !metaArr[index].AcceptableDelta(diskMTime, shardDiskTimeDelta) {
// 如果磁盘 mTime 不匹配,则被视为过时。
// https://github.com/minio/minio/pull/13803
//
// 仅当我们能够找到跨冗余中最多出现的磁盘 mtime 大致相同时,才会激活此检查。
// 允许跳过我们可能认为是错误的那些分片。
onlineDisks[index] = OfflineDisk
}
}
}
}
// 根据文件信息创建对象信息对象。
objInfo := fi.ToObjectInfo(bucket, object, opts.Versioned || opts.VersionSuspended)
// 如果对象是删除标记,则根据 `VersionID` 判断是否返回文件未找到或不允许的错误信息。
if objInfo.DeleteMarker {
if opts.VersionID == "" {
return &GetObjectReader{
ObjInfo: objInfo,
}, toObjectErr(errFileNotFound, bucket, object)
}
// 确保返回对象信息以提供额外信息。
return &GetObjectReader{
ObjInfo: objInfo,
}, toObjectErr(errMethodNotAllowed, bucket, object)
}
// 如果对象位于远程存储,则获取过渡的对象读取器。
if objInfo.IsRemote() {
gr, err := getTransitionedObjectReader(ctx, bucket, object, rs, h, objInfo, opts)
if err != nil {
return nil, err
}
unlockOnDefer = false
return gr.WithCleanupFuncs(nsUnlocker), nil
}
// 如果对象大小为0,零字节对象甚至不需要进一步初始化管道等。
if objInfo.Size == 0 {
return NewGetObjectReaderFromReader(bytes.NewReader(nil), objInfo, opts)
}
// 根据HTTP Range规范和对象信息创建对象读取器。
fn, off, length, err := NewGetObjectReader(rs, objInfo, opts)
if err != nil {
return nil, err
}
if unlockOnDefer {
unlockOnDefer = fi.InlineData()
}
// 创建等待管道。
pr, pw := xioutil.WaitPipe()
// 启动一个 goroutine 用于读取对象数据。
go func() {
// 这里执行读数据
pw.CloseWithError(er.getObjectWithFileInfo(ctx, bucket, object, off, length, pw, fi, metaArr, onlineDisks))
}()
// 用于在出现不完整读取时导致上面的 goroutine 退出的清理函数。
pipeCloser := func() {
pr.CloseWithError(nil)
}
if !unlockOnDefer {
return fn(pr, h, pipeCloser, nsUnlocker)
}
return fn(pr, h, pipeCloser)
}
func (er erasureObjects) getObjectFileInfo(ctx context.Context, bucket, object string, opts ObjectOptions, readData bool) (fi FileInfo, metaArr []FileInfo, onlineDisks []StorageAPI, err error) {
disks := er.getDisks()
var errs []error
// Read metadata associated with the object from all disks.
if opts.VersionID != "" {
// 向所有节点发起元数据读取请求,如果失败节点超过一半,则返回读失败
metaArr, errs = readAllFileInfo(ctx, disks, bucket, object, opts.VersionID, readData)
} else {
metaArr, errs = readAllXL(ctx, disks, bucket, object, readData, opts.InclFreeVersions, true)
}
// 根据元数据信息确定对象读取readQuorum(datablocks大小,即数据块个数)
readQuorum, _, err := objectQuorumFromMeta(ctx, metaArr, errs, er.defaultParityCount)
if err != nil {
// 根据错误信息判断元数据是否满足quorum机制,
if errors.Is(err, errErasureReadQuorum) && !strings.HasPrefix(bucket, minioMetaBucket) {
_, derr := er.deleteIfDangling(ctx, bucket, object, metaArr, errs, nil, opts)
if derr != nil {
err = derr
}
}
return fi, nil, nil, toObjectErr(err, bucket, object)
}
if reducedErr := reduceReadQuorumErrs(ctx, errs, objectOpIgnoredErrs, readQuorum); reducedErr != nil {
if errors.Is(reducedErr, errErasureReadQuorum) && !strings.HasPrefix(bucket, minioMetaBucket) {
// 如果不满足则会判断是否为垃圾数据 针对垃圾数据执行数据删除操作
_, derr := er.deleteIfDangling(ctx, bucket, object, metaArr, errs, nil, opts)
if derr != nil {
reducedErr = derr
}
}
return fi, nil, nil, toObjectErr(reducedErr, bucket, object)
}
// List all online disks.
onlineDisks, modTime, etag := listOnlineDisks(disks, metaArr, errs, readQuorum)
// Pick latest valid metadata.
// 如果满足quorum机制,则读取元信息成功
fi, err = pickValidFileInfo(ctx, metaArr, modTime, etag, readQuorum)
if err != nil {
return fi, nil, nil, err
}
if !fi.Deleted && len(fi.Erasure.Distribution) != len(onlineDisks) {
err := fmt.Errorf("unexpected file distribution (%v) from online disks (%v), looks like backend disks have been manually modified refusing to heal %s/%s(%s)",
fi.Erasure.Distribution, onlineDisks, bucket, object, opts.VersionID)
logger.LogOnceIf(ctx, err, "get-object-file-info-manually-modified")
return fi, nil, nil, toObjectErr(err, bucket, object, opts.VersionID)
}
filterOnlineDisksInplace(fi, metaArr, onlineDisks)
// if one of the disk is offline, return right here no need
// to attempt a heal on the object.
if countErrs(errs, errDiskNotFound) > 0 {
return fi, metaArr, onlineDisks, nil
}
// 判断对象是否有缺失的block,
var missingBlocks int
for i, err := range errs {
if err != nil && errors.Is(err, errFileNotFound) {
missingBlocks++
continue
}
// verify metadata is valid, it has similar erasure info
// as well as common modtime, if modtime is not possible
// verify if it has common "etag" atleast.
if metaArr[i].IsValid() && metaArr[i].Erasure.Equal(fi.Erasure) {
ok := metaArr[i].ModTime.Equal(modTime)
if modTime.IsZero() || modTime.Equal(timeSentinel) {
ok = etag != "" && etag == fi.Metadata["etag"]
}
if ok {
continue
}
} // in all other cases metadata is corrupt, do not read from it.
metaArr[i] = FileInfo{}
onlineDisks[i] = nil
missingBlocks++
}
// if missing metadata can be reconstructed, attempt to reconstruct.
// additionally do not heal delete markers inline, let them be
// healed upon regular heal process.
// 如果可修复 且有missingBlocks则后台异步发起修复(文件缺失修复) 不修复Deleted
if !fi.Deleted && missingBlocks > 0 && missingBlocks < readQuorum {
globalMRFState.addPartialOp(partialOperation{
bucket: bucket,
object: object,
versionID: fi.VersionID,
queued: time.Now(),
setIndex: er.setIndex,
poolIndex: er.poolIndex,
})
}
return fi, metaArr, onlineDisks, nil
}
getObjectWithFileInfo
func (er erasureObjects) getObjectWithFileInfo(ctx context.Context, bucket, object string, startOffset int64, length int64, writer io.Writer, fi FileInfo, metaArr []FileInfo, onlineDisks []StorageAPI) error {
// Reorder online disks based on erasure distribution order.
// Reorder parts metadata based on erasure distribution order.
// 根据数据分布对disk进行排序
onlineDisks, metaArr = shuffleDisksAndPartsMetadataByIndex(onlineDisks, metaArr, fi)
// For negative length read everything.
if length < 0 {
length = fi.Size - startOffset
}
// Reply back invalid range if the input offset and length fall out of range.
if startOffset > fi.Size || startOffset+length > fi.Size {
logger.LogIf(ctx, InvalidRange{startOffset, length, fi.Size}, logger.Application)
return InvalidRange{startOffset, length, fi.Size}
}
// Get start part index and offset.
// 获取开始部分索引和偏移量。
partIndex, partOffset, err := fi.ObjectToPartOffset(ctx, startOffset)
if err != nil {
return InvalidRange{startOffset, length, fi.Size}
}
// Calculate endOffset according to length
// 计算 endoffset
endOffset := startOffset
if length > 0 {
endOffset += length - 1
}
// Get last part index to read given length.
// 获取最后一部分索引来读取给定的长度。
lastPartIndex, _, err := fi.ObjectToPartOffset(ctx, endOffset)
if err != nil {
return InvalidRange{startOffset, length, fi.Size}
}
// 读取数据并进行ec重建
var totalBytesRead int64
erasure, err := NewErasure(ctx, fi.Erasure.DataBlocks, fi.Erasure.ParityBlocks, fi.Erasure.BlockSize)
if err != nil {
return toObjectErr(err, bucket, object)
}
var healOnce sync.Once
for ; partIndex <= lastPartIndex; partIndex++ {
if length == totalBytesRead {
break
}
partNumber := fi.Parts[partIndex].Number
// Save the current part name and size.
partSize := fi.Parts[partIndex].Size
partLength := partSize - partOffset
// partLength should be adjusted so that we don't write more data than what was requested.
if partLength > (length - totalBytesRead) {
partLength = length - totalBytesRead
}
tillOffset := erasure.ShardFileOffset(partOffset, partLength, partSize)
// Get the checksums of the current part.
readers := make([]io.ReaderAt, len(onlineDisks))
prefer := make([]bool, len(onlineDisks))
for index, disk := range onlineDisks {
if disk == OfflineDisk {
continue
}
if !metaArr[index].IsValid() {
continue
}
if !metaArr[index].Erasure.Equal(fi.Erasure) {
continue
}
checksumInfo := metaArr[index].Erasure.GetChecksumInfo(partNumber)
partPath := pathJoin(object, metaArr[index].DataDir, fmt.Sprintf("part.%d", partNumber))
// 直接读取内存构造 reader
readers[index] = newBitrotReader(disk, metaArr[index].Data, bucket, partPath, tillOffset,
checksumInfo.Algorithm, checksumInfo.Hash, erasure.ShardSize())
// Prefer local disks
prefer[index] = disk.Hostname() == ""
}
written, err := erasure.Decode(ctx, writer, readers, partOffset, partLength, partSize, prefer)
// Note: we should not be defer'ing the following closeBitrotReaders() call as
// we are inside a for loop i.e if we use defer, we would accumulate a lot of open files by the time
// we return from this function.
closeBitrotReaders(readers)
if err != nil {
// If we have successfully written all the content that was asked
// by the client, but we still see an error - this would mean
// that we have some parts or data blocks missing or corrupted
// - attempt a heal to successfully heal them for future calls.
if written == partLength {
var scan madmin.HealScanMode
switch {
case errors.Is(err, errFileNotFound):
// 文件缺失:修复类型为HealNormalScan
scan = madmin.HealNormalScan
case errors.Is(err, errFileCorrupt):
// 数据损坏:修复类型为HealDeepScan
scan = madmin.HealDeepScan
}
switch scan {
case madmin.HealNormalScan, madmin.HealDeepScan:
healOnce.Do(func() {
// 如果读取到期望数据大小但读取过程中发现有数据缺失或损坏,
// 则会后台异步发起修复,不影响数据的正常读取
globalMRFState.addPartialOp(partialOperation{
bucket: bucket,
object: object,
versionID: fi.VersionID,
queued: time.Now(),
setIndex: er.setIndex,
poolIndex: er.poolIndex,
})
})
// Healing is triggered and we have written
// successfully the content to client for
// the specific part, we should `nil` this error
// and proceed forward, instead of throwing errors.
err = nil
}
}
if err != nil {
return toObjectErr(err, bucket, object)
}
}
for i, r := range readers {
if r == nil {
onlineDisks[i] = OfflineDisk
}
}
// Track total bytes read from disk and written to the client.
totalBytesRead += partLength
// partOffset will be valid only for the first part, hence reset it to 0 for
// the remaining parts.
partOffset = 0
} // End of read all parts loop.
// Return success.
return nil
}
数据巡检
数据巡检主要做以下事情:
- 发现缺失的数据,并尝试将其修复,无法修复的数据(垃圾数据)则会进行清理
- 统计计量信息,如文件数、存储量、桶个数等
巡检时候会在每块磁盘上对所有bucket中的数据进行巡检,这里主要介绍下巡检是如何发现待修复数据并执行修复?
- 扫描对象信息时:如果发现数据缺失或数据损坏则会快速或深度修复(深度扫描会校验数据文件是否完整,而快速扫描则是检查数据是否缺失,巡检时是否发起深度巡检是在服务启动配置中设置的),不是每一次的巡检都会发起修复,通常是每巡检一定轮数会发起一次,这里的修复是立即执行的;
- 跟上一次巡检结果对比:比如上次巡检发现有文件A,这次巡检却没有找到文件A,满足一定条件则会发起修复操作,这里的巡检是先投递修补消息,异步修复。
每次巡检都会将巡检的结果缓存在本地,下次巡检与之对比
// cmd/data-scanner.go的runDataScanner方法
// runDataScanner 将启动一个数据扫描器。
// 该函数将阻塞,直到上下文被取消。
// 每个集群只能运行一个扫描器。
func runDataScanner(ctx context.Context, objAPI ObjectLayer) {
ctx, cancel := globalLeaderLock.GetLock(ctx)
defer cancel()
// 加载当前的布隆周期信息
var cycleInfo currentScannerCycle
// 读配置
buf, _ := readConfig(ctx, objAPI, dataUsageBloomNamePath)
if len(buf) == 8 {
cycleInfo.next = binary.LittleEndian.Uint64(buf)
} else if len(buf) > 8 {
cycleInfo.next = binary.LittleEndian.Uint64(buf[:8])
buf = buf[8:]
_, err := cycleInfo.UnmarshalMsg(buf)
logger.LogIf(ctx, err)
}
scannerTimer := time.NewTimer(scannerCycle.Load())
defer scannerTimer.Stop()
defer globalScannerMetrics.setCycle(nil)
for {
select {
case <-ctx.Done():
return
case <-scannerTimer.C:
// 重置计时器以进行下一个周期。
// 如果扫描器需要更长时间,我们会立即开始。
scannerTimer.Reset(scannerCycle.Load())
stopFn := globalScannerMetrics.log(scannerMetricScanCycle)
cycleInfo.current = cycleInfo.next
cycleInfo.started = time.Now()
globalScannerMetrics.setCycle(&cycleInfo)
// 读取后台修复信息
// backgroundHealInfo[
// bitrotStartTime,bitrotStartCycle,currentScanMode{
// HealNormalScan,HealDeepScan
// }]
bgHealInfo := readBackgroundHealInfo(ctx, objAPI)
// 获取当前扫描模式
scanMode := getCycleScanMode(cycleInfo.current, bgHealInfo.BitrotStartCycle, bgHealInfo.BitrotStartTime)
if bgHealInfo.CurrentScanMode != scanMode {
// 如果当前扫描模式与新的扫描模式不同,则更新后台修复信息
newHealInfo := bgHealInfo
newHealInfo.CurrentScanMode = scanMode
if scanMode == madmin.HealDeepScan {
newHealInfo.BitrotStartTime = time.Now().UTC()
newHealInfo.BitrotStartCycle = cycleInfo.current
}
// 更新健康扫描模式
saveBackgroundHealInfo(ctx, objAPI, newHealInfo)
}
// 在启动下一个周期前等待一段时间
results := make(chan DataUsageInfo, 1)
// 将存储在gui通道results上发送的所有对象,直到关闭 => saveConfig
// 每次巡检都会将巡检的结果缓存在本地,下次巡检与之对比
go storeDataUsageInBackend(ctx, objAPI, results)
// 走 objAPI 实现 ->server 启动的: erasureServerPools
// 对桶 对 disk 做扫描,并更新结果,通过 results
err := objAPI.NSScanner(ctx, results, uint32(cycleInfo.current), scanMode)
logger.LogIf(ctx, err)
res := map[string]string{"cycle": strconv.FormatUint(cycleInfo.current, 10)}
if err != nil {
res["error"] = err.Error()
}
stopFn(res)
if err == nil {
// 存储新的周期信息
cycleInfo.next++
cycleInfo.current = 0
cycleInfo.cycleCompleted = append(cycleInfo.cycleCompleted, time.Now())
if len(cycleInfo.cycleCompleted) > dataUsageUpdateDirCycles {
cycleInfo.cycleCompleted = cycleInfo.cycleCompleted[len(cycleInfo.cycleCompleted)-dataUsageUpdateDirCycles:]
}
globalScannerMetrics.setCycle(&cycleInfo)
tmp := make([]byte, 8, 8+cycleInfo.Msgsize())
// 为了向后兼容,存储周期信息
binary.LittleEndian.PutUint64(tmp, cycleInfo.next)
tmp, _ = cycleInfo.MarshalMsg(tmp)
err = saveConfig(ctx, objAPI, dataUsageBloomNamePath, tmp)
logger.LogIf(ctx, err)
}
}
}
}
api 层
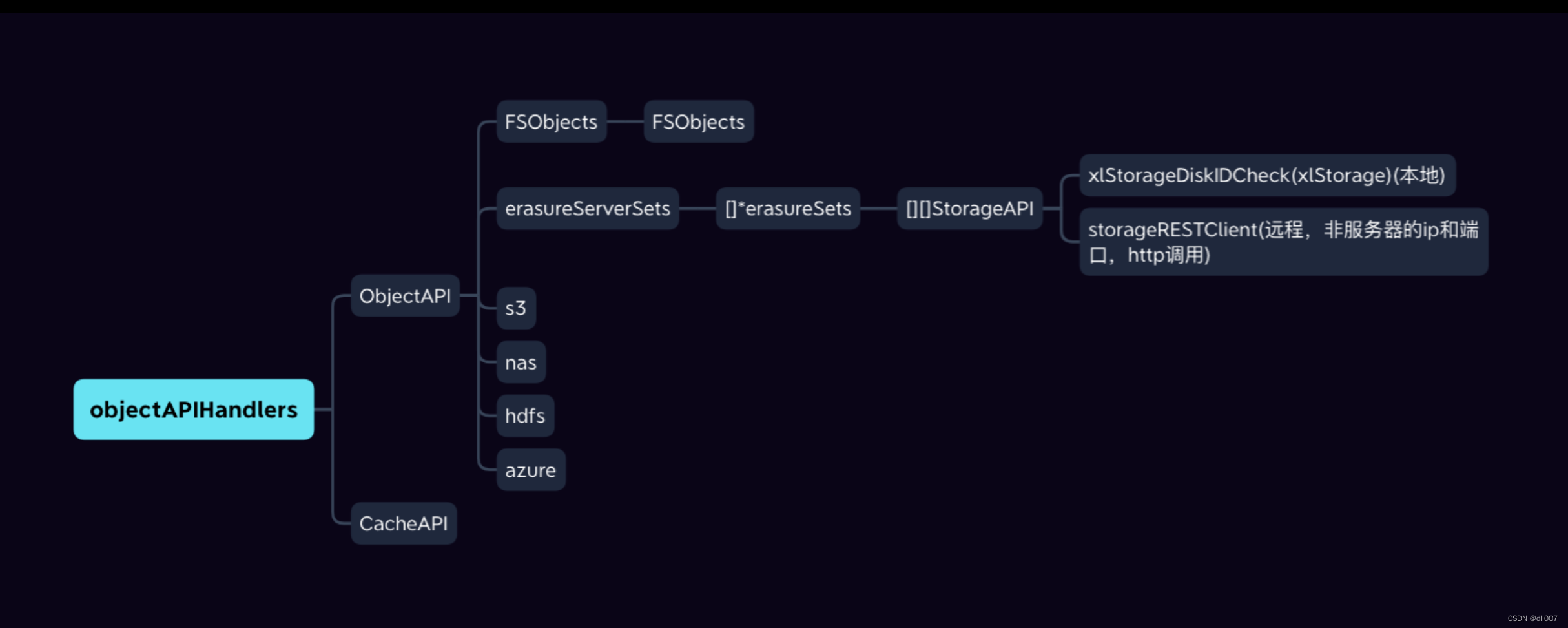
api层调用层级结构如图,从图中我们可以看出,
- 无论是
gateway还是server模式都是通过实现ObjectAPI这个interface来进行服务 - 在objectAPIHandlers这一层面,主要是做了一些检查,实际针对内容处理是放在ObjectAPI这个interface的实现层,以putObject为例,做了以下内容
- 检查
http头字段 - 验证签名
- bucket容量检查
- 检查
main->cmd->server_main -> handler, err := configureServerHandler(globalEndpoints)
-> 注册 router
// configureServer handler returns final handler for the http server.
func configureServerHandler(endpointServerPools EndpointServerPools) (http.Handler, error) {
// Initialize router. `SkipClean(true)` stops minio/mux from
// normalizing URL path minio/minio#3256
router := mux.NewRouter().SkipClean(true).UseEncodedPath()
// Initialize distributed NS lock.
if globalIsDistErasure {
registerDistErasureRouters(router, endpointServerPools)
}
// Add Admin router, all APIs are enabled in server mode.
registerAdminRouter(router, true)
// Add healthCheck router
registerHealthCheckRouter(router)
// Add server metrics router
registerMetricsRouter(router)
// Add STS router always.
registerSTSRouter(router)
// Add KMS router
registerKMSRouter(router)
// Add API router
// 注册怎么操作 object
registerAPIRouter(router)
router.Use(globalMiddlewares...)
return router, nil
}
// objectAPIHandler implements and provides http handlers for S3 API.
type objectAPIHandlers struct {
ObjectAPI func() ObjectLayer
CacheAPI func() CacheObjectLayer
}
// registerAPIRouter - registers S3 compatible APIs.
// 符合 s3 协议
func registerAPIRouter(router *mux.Router) {
// Initialize API.
// 初始化objectAPIHandler
api := objectAPIHandlers{
// 挂载实现的ObjectLayer <= 在初始化ObjectLayer后,会 setObjectLayer(o ObjectLayer)
ObjectAPI: newObjectLayerFn,
CacheAPI: newCachedObjectLayerFn,
}
// API Router
// '/' 分割 uri
apiRouter := router.PathPrefix(SlashSeparator).Subrouter()
var routers []*mux.Router
for _, domainName := range globalDomainNames {
if IsKubernetes() {
routers = append(routers, apiRouter.MatcherFunc(func(r *http.Request, match *mux.RouteMatch) bool {
host, _, err := net.SplitHostPort(getHost(r))
if err != nil {
host = r.Host
}
// Make sure to skip matching minio.<domain>` this is
// specifically meant for operator/k8s deployment
// The reason we need to skip this is for a special
// usecase where we need to make sure that
// minio.<namespace>.svc.<cluster_domain> is ignored
// by the bucketDNS style to ensure that path style
// is available and honored at this domain.
//
// All other `<bucket>.<namespace>.svc.<cluster_domain>`
// makes sure that buckets are routed through this matcher
// to match for `<bucket>`
return host != minioReservedBucket+"."+domainName
}).Host("{bucket:.+}."+domainName).Subrouter())
} else {
// 读取 path 里的匹配的数据到 bucket 参数里
// 注册新的 router,以 domainName
routers = append(routers, apiRouter.Host("{bucket:.+}."+domainName).Subrouter())
}
}
// 最后的匹配{bucket}的 router
routers = append(routers, apiRouter.PathPrefix("/{bucket}").Subrouter())
gz, err := gzhttp.NewWrapper(gzhttp.MinSize(1000), gzhttp.CompressionLevel(gzip.BestSpeed))
if err != nil {
// Static params, so this is very unlikely.
logger.Fatal(err, "Unable to initialize server")
}
for _, router := range routers {
// Register all rejected object APIs
for _, r := range rejectedObjAPIs {
t := router.Methods(r.methods...).
HandlerFunc(collectAPIStats(r.api, httpTraceAll(notImplementedHandler))).
Queries(r.queries...)
t.Path(r.path)
}
// Object operations
....
// GetObject
// 如果判断出 apistats 是 getobject => 请求走该处理链
// path匹配到的参数到object变量里
router.Methods(http.MethodGet).Path("/{object:.+}").HandlerFunc(
collectAPIStats("getobject", maxClients(gz(httpTraceHdrs(api.GetObjectHandler)))))
// PutObject
router.Methods(http.MethodPut).Path("/{object:.+}").HandlerFunc(
collectAPIStats("putobject", maxClients(gz(httpTraceHdrs(api.PutObjectHandler)))))
....
}
http中间件
这里的请求 middleware 是采用一层套一层来实现的
func middleware1(f http.HandlerFunc) http.HandlerFunc {
// 返回一个包装后的中间件HandlerFunc函数
return func(w http.ResponseWriter, r *http.Request) {
... 自己的逻辑
f(w,r)
...
}
}
maxclients
// maxClients throttles the S3 API calls
func maxClients(f http.HandlerFunc) http.HandlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
// 记录全局的HTTP统计信息,增加S3请求的计数
globalHTTPStats.incS3RequestsIncoming()
// 检查HTTP请求头中是否包含名为globalObjectPerfUserMetadata的字段
if r.Header.Get(globalObjectPerfUserMetadata) == "" {
// 如果不包含该字段,检查全局服务是否被冻结
if val := globalServiceFreeze.Load(); val != nil {
if unlock, ok := val.(chan struct{}); ok && unlock != nil {
// 等待解冻,直到服务解冻为止
select {
case <-unlock:
case <-r.Context().Done():
// 如果客户端取消了请求,就不需要一直等待
return
}
}
}
}
// 获取用于请求的池和请求的截止时间
pool, deadline := globalAPIConfig.getRequestsPool()
if pool == nil {
// 说明没有最大客户端限制
// 如果请求池为空,直接调用处理函数并返回
f.ServeHTTP(w, r)
return
}
// 增加等待队列中的请求数
globalHTTPStats.addRequestsInQueue(1)
// 设置请求跟踪信息
if tc, ok := r.Context().Value(mcontext.ContextTraceKey).(*mcontext.TraceCtxt); ok {
tc.FuncName = "s3.MaxClients"
}
// 创建一个截止时间计时器
deadlineTimer := time.NewTimer(deadline)
defer deadlineTimer.Stop()
select {
// 等待 pool 中 的 chan <- 令牌桶
case pool <- struct{}{}:
// 如果成功从池中获取了令牌,释放令牌并处理请求
defer func() { <-pool }()
globalHTTPStats.addRequestsInQueue(-1)
f.ServeHTTP(w, r)
case <-deadlineTimer.C:
// 如果在截止时间内没有获取到令牌,返回HTTP请求超时错误响应
writeErrorResponse(r.Context(), w,
errorCodes.ToAPIErr(ErrTooManyRequests),
r.URL)
globalHTTPStats.addRequestsInQueue(-1)
return
case <-r.Context().Done():
// 当客户端在获取S3处理程序状态码响应之前断开连接时,将状态码设置为499
// 这样可以正确记录和跟踪此请求
w.WriteHeader(499)
globalHTTPStats.addRequestsInQueue(-1)
return
}
}
}
api.GetObjectHandler
猜测:肯定会去调真正的存储层实现: ObjectLayer 或者ObjectCacheLayer
// GetObjectHandler - GET Object
// ----------
// This implementation of the GET operation retrieves object. To use GET,
// you must have READ access to the object.
func (api objectAPIHandlers) GetObjectHandler(w http.ResponseWriter, r *http.Request) {
ctx := newContext(r, w, "GetObject")
defer logger.AuditLog(ctx, w, r, mustGetClaimsFromToken(r))
bucket := vars["bucket"]
object, err := unescapePath(vars["object"])
objectAPI := api.ObjectAPI()
getObjectNInfo := objectAPI.GetObjectNInfo
if api.CacheAPI() != nil {
getObjectNInfo = api.CacheAPI().GetObjectNInfo
}
// 对读取到的对象返回的响应,做层层封装处理
}
Minio的Java服务中间件
通过MinIO整合SpringBoot实现OSS服务器组件搭建和功能实现
-
Minio是Apache License v2.0下发布的对象存储服务器。它与Amazon S3云存储服务兼容。它最适合存储非结构化数据,如照片,视频,日志文件,备份和容器/ VM映像。对象的大小可以从几KB到最大5TB。
-
Minio服务器足够轻,可以与应用程序堆栈捆绑在一起,类似于NodeJS,Redis和MySQL。
-
github 地址: https://github.com/dll02/assemble-platform/tree/main/assemble-platform-minioClient
//使用了 client 包
<dependency>
<groupId>com.jvm123</groupId>
<artifactId>minio-spring-boot-starter</artifactId>
<version>1.2.1</version>
<exclusions>
<exclusion>
<artifactId>guava</artifactId>
<groupId>com.google.guava</groupId>
</exclusion>
</exclusions>
</dependency>
// 其他代码很简单
@Slf4j
@Service
public class MinioHttpOssService {
@Autowired
MinioFileService fileStoreService;
/**
* bucket
* @param bucketName
* @return
*/
public ResultResponse create(@RequestParam("bucketName") String bucketName){
return fileStoreService.createBucket(bucketName)? ResultResponse.success(): ResultResponse.failure("创建oss bucket失败!");
}
/**
* 存储文件
* @param file
* @param bucketName
* @return
*/
public ResultResponse upload(@RequestParam("file") MultipartFile file, @RequestParam("bucketName") String bucketName){
try {
fileStoreService.save(bucketName,file.getInputStream(),file.getOriginalFilename());
} catch (IOException e) {
log.error("upload the file is error",e);
return ResultResponse.failure("upload the file is error");
}
return ResultResponse.success();
}
/**
* 删除文件
* @param bucketName
* @param bucketName
* @return
*/
public ResultResponse delete(@RequestParam("bucketName") String bucketName, @RequestParam("fileName") String fileName){
return fileStoreService.delete(bucketName,fileName)? ResultResponse.success(): ResultResponse.failure("删除oss bucket文件失败!");
}
/**
* 下载文件
* @param bucketName
* @param bucketName
* @return
*/
public void download(HttpServletResponse httpServletResponse, @RequestParam("bucketName") String bucketName, @RequestParam("fileName") String fileName){
try (InputStream inputStream = fileStoreService.getStream(bucketName, fileName)){
httpServletResponse.addHeader("Content-Disposition","attachment;filename="+fileName);
ServletOutputStream os = httpServletResponse.getOutputStream();
fileStoreService.writeTo(bucketName, fileName, os);
} catch (IOException e) {
log.error("download file is failure!",e);
}
}
}
// 走到 client 包
public String save(String bucket, InputStream is, String destFileName) {
if (bucket != null && bucket.length() > 0) {
try {
// 获取一个MinioClient链接
MinioClient minioClient = this.connect();
this.checkBucket(minioClient, bucket);
minioClient.putObject(bucket, destFileName, is, (Long)null, (Map)null, (ServerSideEncryption)null, (String)null);
return destFileName;
} catch (NoSuchAlgorithmException | IOException | XmlPullParserException | InvalidKeyException | MinioException var5) {
LOGGER.error("error: {}", var5.getMessage());
return null;
}
} else {
LOGGER.error("Bucket name cannot be blank.");
return null;
}
}
// minioClient.putObject 最后一定会发起一个 tcp 请求到 minio 服务
// 封装为符合 s3 协议的请求
HttpResponse response = execute(Method.PUT, region, bucketName, objectName,
headerMap, queryParamMap,
data, length);
Response response = this.httpClient.newCall(request).execute();
感言&&参考资料:
minio 的项目是很庞大复杂的,尤其是关于对给类云的协议的兼容解析封装,对Erasure Code擦除码底层存储的实现,都非常的晦涩难懂,功力有限,暂时更新到这里,后面有时间精力和兴趣再更新,有缘再见.














 439
439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









